Recognition: unknown
Can Current Agents Close the Discovery-to-Application Gap? A Case Study in Minecraft
Pith reviewed 2026-05-08 03:30 UTC · model grok-4.3
The pith
Frontier AI agents plateau at 26% success when required to discover causal rules in Minecraft and apply them to build working systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
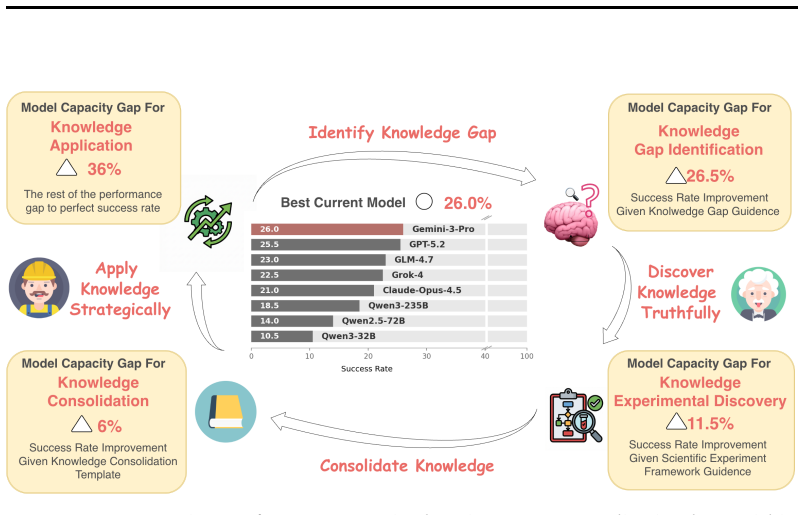
Evaluating frontier models including GPT-5.2, Gemini-3-Pro, and Claude-Opus-4.5 under a general-purpose code agent scaffold, all models plateau at approximately 26% success rate on SciCrafter tasks. To diagnose these failures, the loop is decomposed into four capacities—knowledge gap identification, experimental discovery, knowledge consolidation, and knowledge application—and targeted interventions measure their marginal contributions. The results indicate that general knowledge application remains the biggest gap across all models, yet for frontier models knowledge gap identification is becoming a major additional hurdle, showing that the bottleneck is shifting from solving problems right,
What carries the argument
SciCrafter, a Minecraft benchmark built from parameterized redstone circuit tasks in which agents must discover causal regularities about circuits and apply them to construct functional lamp-igniting systems.
If this is right
- The observed 26% ceiling demonstrates that existing agent scaffolds cannot reliably complete the full discovery-to-application loop even inside a controlled game environment.
- The decomposition into four capacities supplies measurable proxies that future work can use to track progress on each part of the loop.
- The rising importance of knowledge gap identification for frontier models implies that gains will require better mechanisms for spotting what is missing rather than only executing known steps.
- Releasing the benchmark provides a standardized probe for testing whether new agent designs can move beyond the current limits.
Where Pith is reading between the lines
- Similar parameter-scaling logic could be applied to other simulated domains to check whether the same capacity gaps appear outside Minecraft.
- Agents may need explicit internal loops that prompt them to test unknowns before attempting full construction.
- The shift in bottlenecks suggests that training regimes focused solely on execution accuracy will yield diminishing returns without added emphasis on problem formulation.
Load-bearing premise
Increasing the parameters of the lamp-lighting targets raises construction complexity and required knowledge enough to force genuine discovery rather than recall of memorized solutions.
What would settle it
A consistent success rate well above 26% on the highest-parameter SciCrafter tasks by any current frontier model under the same scaffold would show that the reported plateau does not hold.
Figures



read the original abstract
Discovering causal regularities and applying them to build functional systems--the discovery-to-application loop--is a hallmark of general intelligence, yet evaluating this capacity has been hindered by the vast complexity gap between scientific discovery and real-world engineering. We introduce SciCrafter, a Minecraft-based benchmark that operationalizes this loop through parameterized redstone circuit tasks. Agents must ignite lamps in specified patterns (e.g., simultaneously or in timed sequences); scaling target parameters substantially increases construction complexity and required knowledge, forcing genuine discovery rather than reliance on memorized solutions. Evaluating frontier models including GPT-5.2, Gemini-3-Pro, and Claude-Opus-4.5 under a general-purpose code agent scaffold, we find that all plateau at approximately 26% success rate. To diagnose these failures, we decompose the loop into four capacities--knowledge gap identification, experimental discovery, knowledge consolidation, and knowledge application--and design targeted interventions whose marginal contributions serve as proxies for corresponding gaps. Our analysis reveals that although the general knowledge application capability still remains as the biggest gap across all models, for frontier models the knowledge gap identification starts to become a major hurdle--indicating the bottleneck is shifting from solving problems right to raising the right problems for current AI. We release SciCrafter as a diagnostic probe for future research on AI systems that navigate the full discovery-to-application loop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SciCrafter, a Minecraft-based benchmark using parameterized redstone circuit tasks (e.g., igniting lamps in specified patterns or timed sequences) to evaluate the discovery-to-application loop in AI agents. Frontier models including GPT-5.2, Gemini-3-Pro, and Claude-Opus-4.5 are evaluated under a general-purpose code agent scaffold and all plateau at approximately 26% success rate. The authors decompose the loop into four capacities (knowledge gap identification, experimental discovery, knowledge consolidation, and knowledge application), design targeted interventions, and use their marginal contributions as proxies to conclude that knowledge application remains the largest gap across models while knowledge gap identification is emerging as a major hurdle for frontier models.
Significance. If the empirical results and capacity analysis hold, the work supplies a concrete, scalable diagnostic benchmark for a core aspect of general intelligence that current evaluations often bypass. The four-capacity decomposition and intervention-based gap measurement provide a reusable framework for isolating bottlenecks, and the public release of SciCrafter enables reproducible follow-up studies on whether future agents can close the identified gaps.
major comments (3)
- [§3] §3 (Benchmark Design): The central claim that scaling target parameters (more lamps, complex timings) forces genuine discovery rather than recall of memorized redstone primitives is load-bearing for interpreting the 26% plateau as a discovery-to-application gap. Redstone circuits are composed from a small fixed set of elements (gates, repeaters, observers); the manuscript should include direct-prompting experiments on high-parameter tasks to demonstrate that models cannot produce correct component choices and wiring even without the agent scaffold, otherwise failures may reflect long-horizon planning or state-tracking limits instead.
- [§4.2] §4.2 (Intervention Design): The marginal contributions of the four targeted interventions are treated as independent proxies for the respective capacities, yet the manuscript does not report controls or ablations showing that an intervention on knowledge gap identification does not also improve application (or vice versa). Without such evidence the conclusion that the bottleneck is shifting for frontier models rests on an unverified separability assumption.
- [§5] §5 (Results): The reported 26% plateau and gap rankings are presented without the number of tasks, number of independent trials per model, statistical tests for significance of differences, or variance measures. These details are required to evaluate whether the plateau is robust and whether the shift in bottleneck identification is statistically supported rather than an artifact of small sample size or task selection.
minor comments (2)
- [Figures 2-4] Figure captions and axis labels in the results section should explicitly state the number of runs and error bars used; current presentation makes it hard to judge variability.
- [§2] The manuscript should cite prior Minecraft agent benchmarks (e.g., MineDojo, Voyager) when positioning SciCrafter to clarify the incremental contribution of the parameterized redstone tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for strengthening the manuscript's claims and reporting. We address each major comment below and will incorporate revisions to improve rigor and clarity.
read point-by-point responses
-
Referee: [§3] The central claim that scaling target parameters (more lamps, complex timings) forces genuine discovery rather than recall of memorized redstone primitives is load-bearing for interpreting the 26% plateau as a discovery-to-application gap. The manuscript should include direct-prompting experiments on high-parameter tasks to demonstrate that models cannot produce correct component choices and wiring even without the agent scaffold, otherwise failures may reflect long-horizon planning or state-tracking limits instead.
Authors: We agree that explicit direct-prompting baselines on high-parameter tasks would provide stronger evidence against memorization and better isolate the discovery-to-application gap from planning or state-tracking limitations. Our current design uses parameterization and a general-purpose code agent scaffold to argue that scaling forces discovery, but we acknowledge this could be more directly validated. In the revised manuscript, we will add these experiments, reporting success rates for direct prompting on complex tasks to show that models fail to generate correct circuits even without the scaffold. revision: yes
-
Referee: [§4.2] The marginal contributions of the four targeted interventions are treated as independent proxies for the respective capacities, yet the manuscript does not report controls or ablations showing that an intervention on knowledge gap identification does not also improve application (or vice versa). Without such evidence the conclusion that the bottleneck is shifting for frontier models rests on an unverified separability assumption.
Authors: The interventions were designed to target distinct capacities (e.g., gap identification via uncertainty-focused prompts versus application via template aids), with the intent of minimizing overlap. However, we did not include explicit cross-effect ablations in the reported results. We will add these controls in the revision, such as applying each intervention in isolation and measuring impacts on all capacities, to empirically support the separability assumption and the observed bottleneck shift for frontier models. revision: yes
-
Referee: [§5] The reported 26% plateau and gap rankings are presented without the number of tasks, number of independent trials per model, statistical tests for significance of differences, or variance measures. These details are required to evaluate whether the plateau is robust and whether the shift in bottleneck identification is statistically supported rather than an artifact of small sample size or task selection.
Authors: We thank the referee for noting this reporting gap. The revised §5 will include the full details: 48 parameterized tasks, 5 independent trials per model (with different seeds), standard deviations for success rates, and statistical tests (e.g., paired t-tests for model comparisons and ANOVA for intervention effects) to establish the robustness of the 26% plateau and the statistical support for the bottleneck rankings and shift. revision: yes
Circularity Check
No significant circularity: empirical benchmark with independent experimental results
full rationale
The paper introduces SciCrafter as a parameterized redstone circuit benchmark to evaluate the discovery-to-application loop in AI agents. It reports empirical success rates (plateau at ~26% for frontier models) and decomposes performance into four capacities with marginal intervention proxies. No equations, fitted parameters, or derivations are present that reduce by construction to inputs. The scaling assumption (more parameters force discovery over recall) is stated as a design rationale but is not used as a load-bearing mathematical step or self-citation chain; results stand on direct evaluations against the benchmark. This is a self-contained empirical study without self-definitional, fitted-prediction, or uniqueness-imported circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The parameterized redstone circuit tasks in Minecraft require genuine causal discovery and cannot be solved through memorization when parameters are scaled.
- domain assumption The four capacities (knowledge gap identification, experimental discovery, knowledge consolidation, and knowledge application) provide a valid decomposition of the discovery-to-application loop.
Reference graph
Works this paper leans on
-
[1]
URLhttps://psycnet.apa.org/doi/10.1037/a0028044
doi: 10.1037/a0028044. URLhttps://psycnet.apa.org/doi/10.1037/a0028044. Jonathan Gray, Kavya Srinet, Yacine Jernite, Haonan Yu, Zhuoyuan Chen, Demi Guo, Siddharth Goyal, C. Lawrence Zitnick, and Arthur Szlam. Craftassist: A framework for dialogue-enabled interactive agents.arXiv preprint arXiv:1907.08584, 2019. doi: 10.48550/ arXiv.1907.08584. 10 Tarun Gu...
-
[2]
doi: 10.48550/arXiv.2205.00445. Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. Building machines that learn and think like people.Behavioral and Brain Sciences, 40:e253,
work page internal anchor Pith review doi:10.48550/arxiv.2205.00445
-
[3]
doi: 10.1017/S0140525X16001837. Guohao Li et al. Camel: Communicative agents for “mind” exploration of large scale language model society.arXiv preprint arXiv:2303.17760, 2023. doi: 10.48550/arXiv.2303. 17760. Shalev Lifshitz, Keiran Paster, Harris Chan, Jimmy Ba, and Sheila McIlraith. Steve-1: A generative model for text-to-behavior in minecraft.arXiv pr...
-
[4]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
doi: 10.48550/arXiv.2307.16789. Bernardino Romera-Paredes et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024. doi: 10.1038/s41586-023-06924-6. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language m...
-
[5]
URL https://mitpress.mit.edu/9780262691914/ the-sciences-of-the-artificial-3rd-edition/
ISBN 0262691914. URL https://mitpress.mit.edu/9780262691914/ the-sciences-of-the-artificial-3rd-edition/. Zhangde Song et al. Evaluating large language models in scientific discovery, 2025. URL https://arxiv.org/abs/2512.15567. Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, and Graham Neubig. Cod- ing agents with multimodal browsing are genera...
-
[6]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
URLhttps://arxiv.org/abs/2305.16291. Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InInternational Conference on Machine Learning (ICML), 2024. URLhttps://arxiv.org/abs/2402.01030. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiao...
-
[7]
Knowledge Identification Gap (δid): Measured as the gain achieved by providing oracle identification guidance over the baseline: δid =P(S=1|M,{h id})−P(S=1|M,∅)(1) 14
-
[8]
Knowledge Discovery Gap (δds): The gain from further introducing the scientific sub-agent that specializes at doing scientific control experiments. Since it must use one consolidation method or another, and the consolidation method is not adding any new information, the most optimized consolidation method (hopt kc ) reflects the capacity brought by it: δd...
-
[9]
Consolidation Optimization Gap (δkc): The performance difference between the default consolidation and anoptimizedtemplate (h opt kc ): δkc =P(S=1|M,{h id,h ds,h opt kc })−P(S=1|M,{h id,h ds,h base kc })(3)
-
[10]
more blocks
Application Gap ( δapp ): The residual gap under the most optimized discovery- consolidation pipeline, representing the fundamental execution bottleneck. Note that this application capacity—the ability to reason and plan with acquired knowledge—underlies every stage of the loop, from identification to discovery to consolidation. Therefore it can be regard...
2025
-
[11]
________ ### Testing Process **Step 1**: ________ -> Observation: ________ **Step 2**: ________ -> Observation: ________ **Step 3**: ________ -> Observation: ________ (Add more steps as needed) --- ## 5. Experiment Record ### Data Recording Table | Trial # | Changed Condition | Observed Result | Matches Prediction? | Notes | |---------|------------------|...
-
[12]
We present three formats, each with its generation prompt and an example output
________ --- ## Quick Checklist - [ ] Research question is clear - [ ] Only changing one variable at a time - [ ] Set up control group - [ ] Recorded all observations - [ ] Repeated test at least 3 times 29 - [ ] Documented unexpected situations - [ ] Summarized patterns or conclusions --- **Experiment Notes** (Free recording area): _[Any additional thoug...
-
[13]
Extract the core truth from experiences
**Distill:** Do not just copy text. Extract the core truth from experiences
-
[14]
**Structure:** Maintain the Finding/Explanation/Example structure for *every* entry
-
[15]
**Coverage:** Ensure all technical details needed for reuse are captured
-
[16]
Manhattan
**Clarity:** Use clear, professional technical language. H.2.2 Example Output ### Finding Diagonal placement allows for compact star topologies. ### Explanation Redstone dust strictly connects to the four cardinal neighbors (North, South, East, West). It does not connect diagonally. * **Observation:** Placing dust at`(x, z)`and`(x+1, z+1)`results in two i...
-
[17]
Calculate $Delay_{inherent}$ for every path (ticks from mandatory repeaters needed for distance)
-
[18]
Find $Max(Delay_{inherent})$
-
[19]
* **Slack:** Sometimes you intentionally increase the delay of *all* paths to a higher common multiple to make the math easier (e.g., synchronize everything to 10 ticks)
For every other path $i$, add compensation repeaters: $\delta_{add} = Max(Delay) - Delay_i$. * **Slack:** Sometimes you intentionally increase the delay of *all* paths to a higher common multiple to make the math easier (e.g., synchronize everything to 10 ticks). ### Example **Equal-Delay Distribution Logic** * Path A (20 blocks): Needs 1 Repeater (min 1 ...
-
[20]
**Input Normalization:** First, convert the button press into a standardized 1-tick pulse using a **Rising Edge Detector**
-
[21]
32 * *Small $\tau$ (1-4):* Use a repeater set to $\tau$ merging with the original signal? No, simpler: The 1-tick pulse powers a repeater chain that "holds" the line
**Pulse Shaping:** Extend that 1-tick pulse to exactly $\tau$ ticks. 32 * *Small $\tau$ (1-4):* Use a repeater set to $\tau$ merging with the original signal? No, simpler: The 1-tick pulse powers a repeater chain that "holds" the line. * *Medium $\tau$ (4-10):* Use a **Pulse Extender**. A parallel bank of repeaters is precise. * *Analog Method:* A Compara...
-
[22]
vec3(x+1,y,z) [Torch] -> vec3(x+2,y,z) [Wire]
-
[23]
Timeline
vec3(x,y,z+1) [Repeater-2] -> vec3(x+1,y,z+1) [Wire] -> vec3(x+2,y,z+1) [Connect to 1] Output at vec3(x+3,y,z) through Inverter. ``` **Step 2: Pulse Extension Bank (The "Timeline" method)** To output exactly 4 ticks from a 1-tick trigger: Input splits into 4 parallel lines of delay 1, 2, 3, 4, all merging into Output. ```text Parallel Array: Input: vec3(0...
-
[24]
**Block Cutting:** Place a solid block between parallel wires
-
[25]
**Repeater Tunneling:** Use repeaters to push signal *through* a block, allowing a perpendicular wire to run on top of that block without connecting
-
[26]
Tick Counting
**Vertical Stacking:** Run one bus line at Y=64 and another at Y=66. * **Slabs/Glowstone:** Use transparent blocks to run wire vertically up without cutting the signal. ### Example **High-Density Bus Routing** Running 3 parallel signals in a 3-wide space: ```text Grid Configuration: Column 0: vec3(0, y, z) -> Signal 1 Column 1: vec3(1, y, z) -> Insulator ...
-
[27]
Remember: Dust = 0, Torch = 1, Comparator = 1, Repeater = Configured (1-4)
**Tick Counting:** Manually trace the path from Source to Lamp, summing the delays of every repeater. Remember: Dust = 0, Torch = 1, Comparator = 1, Repeater = Configured (1-4)
-
[28]
Sometimes lamps turn ON simultaneously but turn OFF at different times
**Edge Observation:** Watch the *activation* (Rising Edge). Sometimes lamps turn ON simultaneously but turn OFF at different times. The contract usually specifies activation time $|t_i - t_j|$
-
[29]
quasi-powered
**Ghost Power:** Ensure blocks aren't being "quasi-powered" or powered indirectly by adjacent strong-powered blocks, which can bypass intended delays. 33 ### Example **Debugging Table Construction** ```text Log Data: Target: vec3(10,10,10) [L1], Delta=6, Actual=6 (OK) Target: vec3(20,10,10) [L2], Delta=6, Actual=7 (FAIL) -> Components at vec3(25,10,10) [R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.