Recognition: unknown
WildLIFT: Lifting monocular drone video to 3D for species-agnostic wildlife monitoring
Pith reviewed 2026-05-08 04:23 UTC · model grok-4.3
The pith
WildLIFT lifts monocular drone videos to 3D for species-agnostic wildlife detection and tracking
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces WildLIFT as a computational framework that integrates three-dimensional scene geometry from monocular drone video with open-vocabulary 2D instance segmentation. This enables species-agnostic 3D detection and tracking of wildlife. Oriented 3D bounding box labels with semantic face information are generated to assess viewpoint coverage and inter-animal occlusion. These outputs yield structured metadata for ecological analyses. Validation occurred on 2,581 manually curated frames with over 6,700 3D detections across four large mammal species, showing high identity consistency and reduced annotation effort via keyframe refinement.
What carries the argument
Integration of monocular 3D scene geometry reconstruction and open-vocabulary 2D instance segmentation for producing species-agnostic 3D detections and oriented bounding boxes.
If this is right
- Produces oriented 3D bounding boxes with semantic face information for analysis.
- Supports quantitative assessment of viewpoint coverage and inter-animal occlusion.
- Reduces manual 3D annotation effort through keyframe-based refinement.
- Maintains high identity consistency in multi-animal scenes.
- Generates structured metadata suitable for behavioral research and population monitoring.
Where Pith is reading between the lines
- Existing archives of drone footage could be reprocessed for new 3D insights into animal interactions.
- The approach may extend to other aerial monitoring tasks involving moving targets in natural environments.
- Combining the 3D outputs with machine learning could automate more complex ecological metrics.
- Improved handling of occlusions might lead to more accurate population density calculations from aerial surveys.
Load-bearing premise
That accurate three-dimensional geometry can be recovered from monocular videos of moving animals in complex natural outdoor environments.
What would settle it
Running the system on drone videos where ground-truth 3D positions of animals are known from multi-camera setups or GPS collars, and checking if the lifted 3D boxes match within acceptable error margins.
Figures


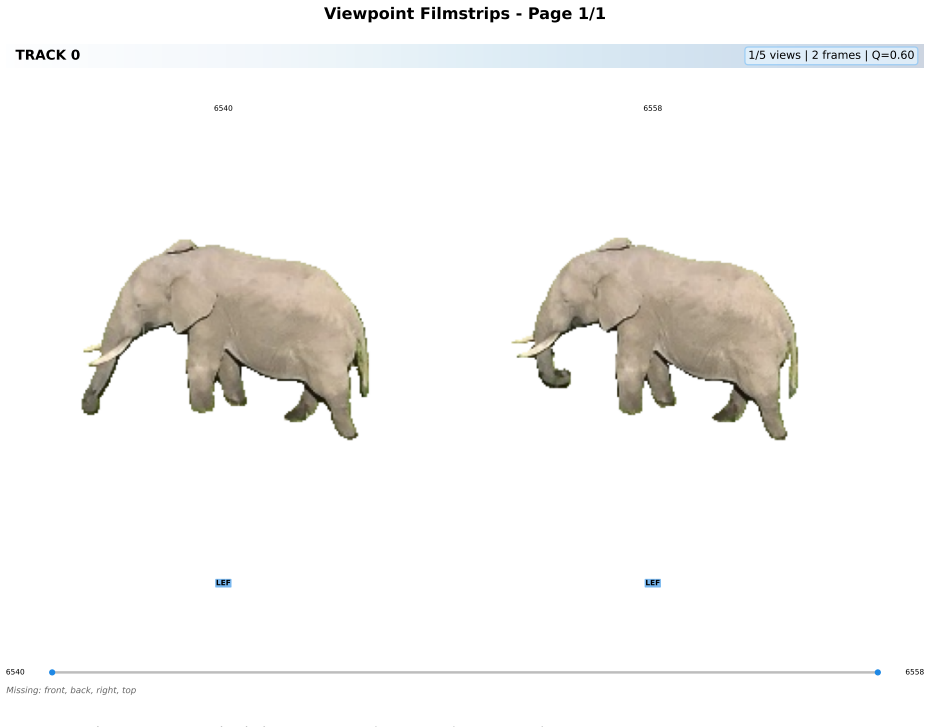


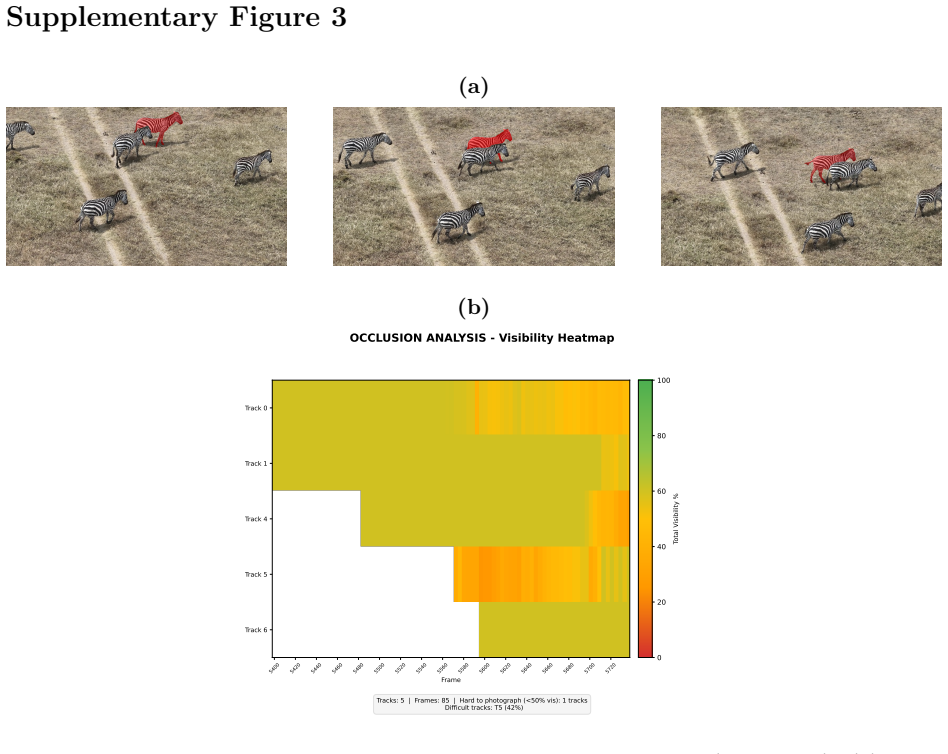
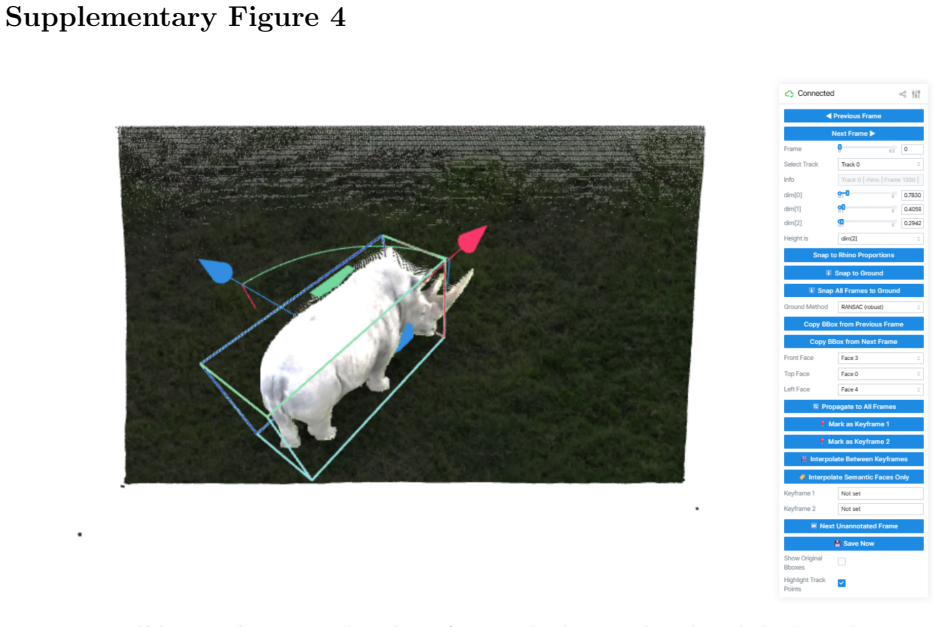
read the original abstract
Monocular RGB cameras mounted on drones are widely used for wildlife monitoring, yet most analytical pipelines remain confined to two-dimensional image space, leaving geometric information in video underexploited. We present WildLIFT, a computational framework that integrates three-dimensional scene geometry from monocular drone video with open-vocabulary 2D instance segmentation to enable species-agnostic 3D detection and tracking. Oriented 3D bounding box labels with semantic face information enable quantitative assessment of viewpoint coverage and inter-animal occlusion, producing structured metadata for downstream ecological analyses. We validate the framework on 2,581 manually curated frames comprising over 6,700 3D detections across four large mammal species. WildLIFT maintains high identity consistency in multi-animal scenes and substantially reduces manual 3D annotation effort through keyframe-based refinement. By transforming standard drone footage into structured 3D and viewpoint-aware representations, WildLIFT extends the analytical utility of aerial wildlife datasets for behavioural research and population monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents WildLIFT, a framework that extracts 3D scene geometry from monocular drone video and combines it with open-vocabulary 2D instance segmentation to produce species-agnostic 3D detection and tracking of wildlife. Oriented 3D bounding boxes with semantic face information are generated to quantify viewpoint coverage and inter-animal occlusion, yielding structured metadata for ecological analyses. The method is validated on 2,581 manually curated frames containing over 6,700 3D detections across four large mammal species, with claims of high identity consistency in multi-animal scenes and reduced manual 3D annotation effort via keyframe refinement.
Significance. If the monocular 3D lifting step produces usable geometry, the framework could substantially increase the analytical value of standard drone footage for wildlife research by enabling quantitative 3D studies of behavior and population dynamics without specialized sensors. The species-agnostic design via open-vocabulary segmentation is a practical contribution that avoids per-species retraining. The scale of the reported validation (multiple species, thousands of detections) provides ecological grounding, though the absence of 3D accuracy numbers limits the strength of this assessment.
major comments (2)
- [Validation / Results] The validation paragraph (and corresponding results section) states that the framework was tested on 2,581 frames and over 6,700 detections but supplies no 3D-specific quantitative error metrics such as mean centroid error (in meters), 3D IoU, or reprojection error against independent ground truth (multi-view stereo, LiDAR, or GPS-tagged positions). Without these numbers it is impossible to determine whether the oriented boxes are accurate enough to support the central claims of quantitative occlusion and viewpoint analysis.
- [Method / Pipeline Overview] The core technical assumption—that reliable 3D geometry can be recovered from monocular drone video of moving, non-rigid animals in unstructured outdoor scenes—is load-bearing for the entire pipeline yet is not tested against standard monocular baselines or failure-mode analysis (e.g., SfM drift, depth estimation on vegetation, scale ambiguity).
minor comments (1)
- [Abstract] The abstract claims the method 'substantially reduces manual 3D annotation effort' but provides no quantitative comparison (e.g., annotation time or number of keyframes required versus full manual labeling).
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the detailed feedback and have carefully considered each point. Below we provide point-by-point responses and indicate the revisions we intend to make to the manuscript.
read point-by-point responses
-
Referee: The validation paragraph (and corresponding results section) states that the framework was tested on 2,581 frames and over 6,700 detections but supplies no 3D-specific quantitative error metrics such as mean centroid error (in meters), 3D IoU, or reprojection error against independent ground truth (multi-view stereo, LiDAR, or GPS-tagged positions). Without these numbers it is impossible to determine whether the oriented boxes are accurate enough to support the central claims of quantitative occlusion and viewpoint analysis.
Authors: We agree that absolute 3D error metrics would provide stronger evidence for the accuracy of the lifted geometry. However, as noted in the manuscript, the data consists of monocular drone videos from natural field settings where independent 3D ground truth (e.g., from LiDAR or GPS) is not available. The validation emphasizes the framework's ability to produce consistent 3D tracks and reduce annotation effort, which supports its utility for the ecological analyses described. In the revised manuscript, we will expand the results section to include available quantitative measures from the reconstruction pipeline, such as reprojection errors, and add a discussion of the limitations regarding absolute scale and accuracy. This will better contextualize the claims regarding occlusion and viewpoint analysis, which rely on relative 3D relationships rather than metric accuracy. revision: yes
-
Referee: The core technical assumption—that reliable 3D geometry can be recovered from monocular drone video of moving, non-rigid animals in unstructured outdoor scenes—is load-bearing for the entire pipeline yet is not tested against standard monocular baselines or failure-mode analysis (e.g., SfM drift, depth estimation on vegetation, scale ambiguity).
Authors: The 3D lifting component of WildLIFT leverages standard structure-from-motion (SfM) methods applied to drone video, with adaptations for the wildlife monitoring context. We did not perform an exhaustive comparison to alternative monocular depth estimation baselines or a comprehensive failure-mode study in the initial submission, as the primary contribution lies in the integration with open-vocabulary segmentation and the generation of viewpoint-aware 3D metadata. Nevertheless, we recognize the value of such analysis. In the revision, we will add a new paragraph in the Methods section describing the SfM implementation details, including how scale ambiguity is resolved using drone metadata and how keyframe selection helps mitigate drift. We will also include qualitative failure case examples in the supplementary material to illustrate performance on scenes with dense vegetation or rapid animal movement. revision: yes
Circularity Check
No significant circularity in claimed derivation
full rationale
The paper presents WildLIFT as a framework that combines monocular 3D geometry extraction with open-vocabulary segmentation for 3D wildlife detection and tracking. No equations, mathematical derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or description. The central claims rest on empirical application of existing CV techniques to a new domain, with validation described via manual curation of frames and detections rather than any tautological reduction of outputs to inputs. This is a standard non-circular presentation of an applied system.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Li, Z.et al.MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos
-
[2]
Wang*, Q., Zhang*, Y., Holynski, A., Efros, A. A. & Kanazawa, A.Continuous 3d perception model with persistent state(2025)
2025
-
[3]
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K. & Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer (2020). arXiv:1907.01341
-
[4]
(eds Globerson, A.et al.) Advances in Neural Information Processing Systems, Vol
Yang, L.et al.Globerson, A.et al.(eds)Depth anything v2. (eds Globerson, A.et al.) Advances in Neural Information Processing Systems, Vol. 37, 21875–21911 (Curran Asso- ciates, Inc., 2024). URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ file/26cfdcd8fe6fd75cc53e92963a656c58-Paper-Conference.pdf
2024
-
[5]
Video depth anything: Consistent depth estimation for super-long videos(2025)
Chen, S.et al. Video depth anything: Consistent depth estimation for super-long videos(2025)
2025
-
[6]
& Huang, J.-B.Robust consistent video depth estimation, 1611–1621 (2021)
Kopf, J., Rong, X. & Huang, J.-B.Robust consistent video depth estimation, 1611–1621 (2021)
2021
-
[7]
& Revaud, J.Dust3r: Geometric 3d vision made easy, 20697–20709 (2024)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B. & Revaud, J.Dust3r: Geometric 3d vision made easy, 20697–20709 (2024)
2024
-
[8]
Zhang, J.et al.MONST3R: A SIMPLE APPROACH FOR ESTIMATING GEOMETRY IN THE PRESENCE OF MOTION (2025)
2025
-
[9]
Vggt: Visual geometry grounded transformer(2025)
Wang, J.et al. Vggt: Visual geometry grounded transformer(2025)
2025
-
[10]
Chen, S.et al.Video Depth Anything: Consistent Depth Estimation for Super-Long Videos (2025). arXiv:2501.12375
-
[11]
Kopf, J., Rong, X. & Huang, J.-B. Robust Consistent Video Depth Estimation (2021). arXiv:2012.05901
-
[12]
Zhang, Z.et al.inStructure and Motion from Casual Videos(eds Avidan, S., Brostow, G., Ciss´ e, M., Farinella, G. M. & Hassner, T.)Computer Vision – ECCV 2022, Vol. 13693 20–37 (Springer Nature Switzerland, Cham, 2022)
2022
-
[13]
& Revaud, J
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B. & Revaud, J. DUSt3R: Geometric 3D Vision Made Easy
-
[14]
Any4D: Unified feed-forward metric 4D reconstruction.arXiv preprint arXiv:2512.10935, 2025
Karhade, J.et al.Any4D: Unified Feed-Forward Metric 4D Reconstruction (2025). arXiv:2512.10935
-
[15]
Fischler, M. A. & Bolles, R. C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM24, 381–395 (1981). URLhttps://dl.acm.org/doi/10.1145/358669.358692. 19
-
[16]
Kay, T. L. & Kajiya, J. T. Ray tracing complex scenes.SIGGRAPH Comput. Graph.20, 269–278 (1986)
1986
-
[17]
Bot-sort: R obust associations multi-pedestrian tracking
Aharon, N., Orfaig, R. & Bobrovsky, B.-Z. BoT-SORT: Robust Associations Multi-Pedestrian Tracking (2022). arXiv:2206.14651
- [18]
-
[19]
In the Wild
Zuffi, S., Kanazawa, A., Berger-Wolf, T. & Black, M.Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture From Images “In the Wild”, 5358–5367 (IEEE, Seoul, Korea (South), 2019)
2019
-
[20]
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape, 9065–9075 (IEEE, Paris, France, 2023)
Xu, J.et al. Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape, 9065–9075 (IEEE, Paris, France, 2023). URLhttps://ieeexplore.ieee.org/document/10377182/
-
[21]
N., Wu, J
Zhao, B. N., Wu, J. & Wu, S.Web-scale collection of video data for 4d animal reconstruction (2025). URLhttps://neurips.cc/virtual/2025/loc/san-diego/poster/121712
2025
-
[22]
Kulits, P., Black, M. J. & Zuffi, S.Reconstructing animals and the wild, 16565–16577 (2025)
2025
-
[23]
W.et al.Geometric deep learning enables 3D kinematic profiling across species and environments.Nature Methods18, 564–573 (2021)
Dunn, T. W.et al.Geometric deep learning enables 3D kinematic profiling across species and environments.Nature Methods18, 564–573 (2021)
2021
-
[24]
Acinoset: A 3d pose estimation dataset and baseline models for cheetahs in the wild, 13901–13908 (2021)
Joska, D.et al. Acinoset: A 3d pose estimation dataset and baseline models for cheetahs in the wild, 13901–13908 (2021)
2021
-
[25]
& Patel, A
Muramatsu, N., Shin, S., Deng, Q., Markham, A. & Patel, A. WildPose: A long-range 3D wildlife motion capture system.Journal of Experimental Biology228, JEB249987 (2025)
2025
-
[26]
Christiansen, F.et al.Estimating body mass of free-living whales using aerial photogrammetry and 3D volumetrics.Methods in Ecology and Evolution10, 2034–2044 (2019)
2034
-
[27]
C., Holman, D., Terauds, A., Koh, L
Hodgson, J. C., Holman, D., Terauds, A., Koh, L. P. & Goldsworthy, S. D. Rapid condition monitoring of an endangered marine vertebrate using precise, non-invasive morphometrics.Bi- ological Conservation242, 108402 (2020). URLhttps://www.sciencedirect.com/science/ article/pii/S0006320719317975
2020
-
[28]
Stone, T. C. & Davis, K. J. Using unmanned aerial vehicles to estimate body volume at scale for ecological monitoring.Methods in Ecology and Evolution16, 317–331 (2025). URLhttps://onlinelibrary.wiley.com/doi/abs/10.1111/2041-210X.14457. eprint: https://besjournals.onlinelibrary.wiley.com/doi/pdf/10.1111/2041-210X.14457
-
[29]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T.et al.Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks (2024). URLhttp://arxiv.org/abs/2401.14159. ArXiv:2401.14159 [cs]
work page internal anchor Pith review arXiv 2024
-
[30]
Segment anything, 4015–4026 (2023)
Kirillov, A.et al. Segment anything, 4015–4026 (2023)
2023
-
[31]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, S.et al.Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (2024). URLhttp://arxiv.org/abs/2303.05499. ArXiv:2303.05499 [cs]
work page internal anchor Pith review arXiv 2024
-
[32]
SAM 2: Segment Anything in Images and Videos
Ravi, N.et al.SAM 2: Segment Anything in Images and Videos (2024). URLhttp://arxiv. org/abs/2408.00714. ArXiv:2408.00714 [cs]. 20
work page internal anchor Pith review arXiv 2024
-
[33]
BioCLIP: A vision foundation model for the tree of life, 19412–19424 (2024)
Stevens, S.et al. BioCLIP: A vision foundation model for the tree of life, 19412–19424 (2024). 21
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.