Recognition: unknown
Efficient Multivariate Kelly Optimization Reveals Sigmoidal Scaling Laws
Pith reviewed 2026-05-07 16:50 UTC · model grok-4.3
The pith
The shortfall between bounds on optimal Kelly growth rate follows a sigmoid scaling law in relative subproblem size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When multivariate Kelly problems are decomposed into subproblems, the shortfall ratio between the resulting lower and upper bounds on the optimal growth rate is well approximated by a sigmoid function of the relative subproblem size, and the parameters of that sigmoid can be predicted from low-dimensional summary statistics of the problem.
What carries the argument
Decomposition into subproblems that generate feasible lower bounds and infeasible upper bounds on the growth rate, paired with an integral transform that reduces objective evaluation from O(2^N) to O(N) for independent bets.
Load-bearing premise
The synthetic data modeled after prediction markets captures the statistical structure that controls how solution quality scales with subproblem size in real multivariate Kelly problems.
What would settle it
Apply the same decomposition procedure to historical prediction-market odds or actual multi-asset portfolio returns and test whether the observed shortfall ratios still lie close to the predicted sigmoid curve for the corresponding relative subproblem sizes.
Figures



read the original abstract
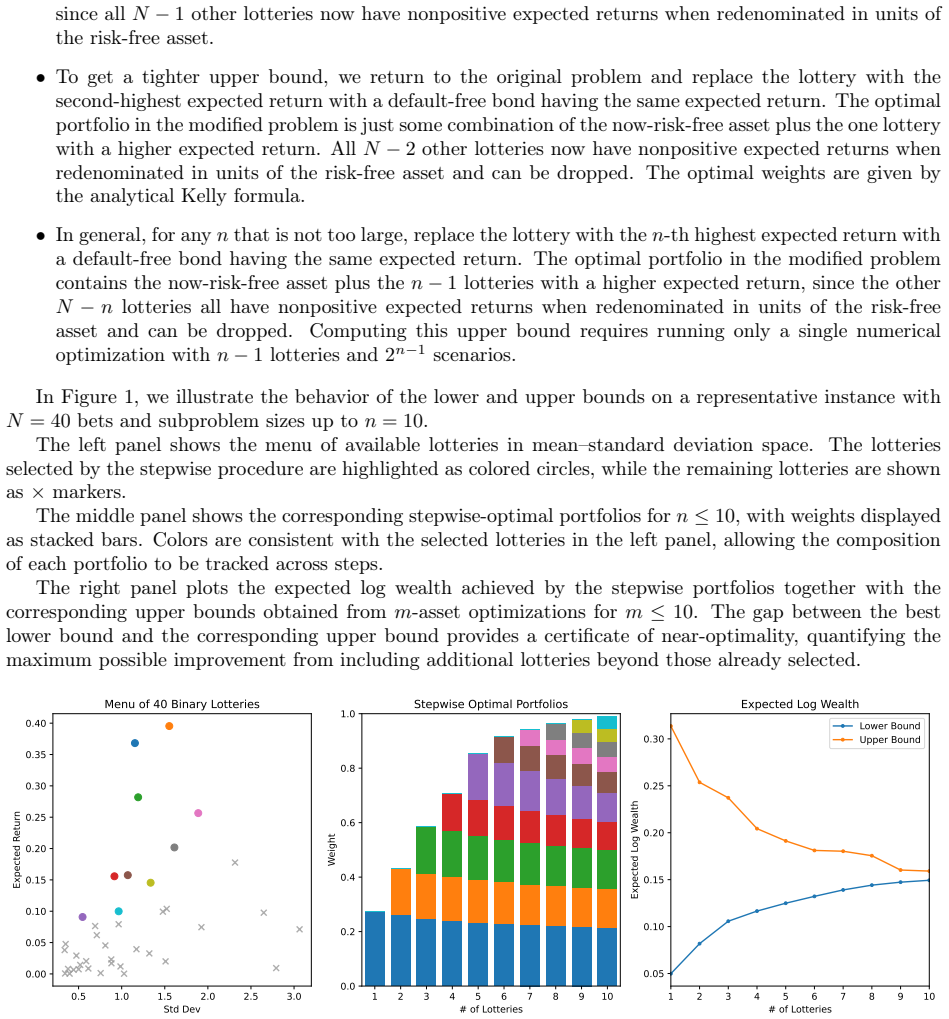
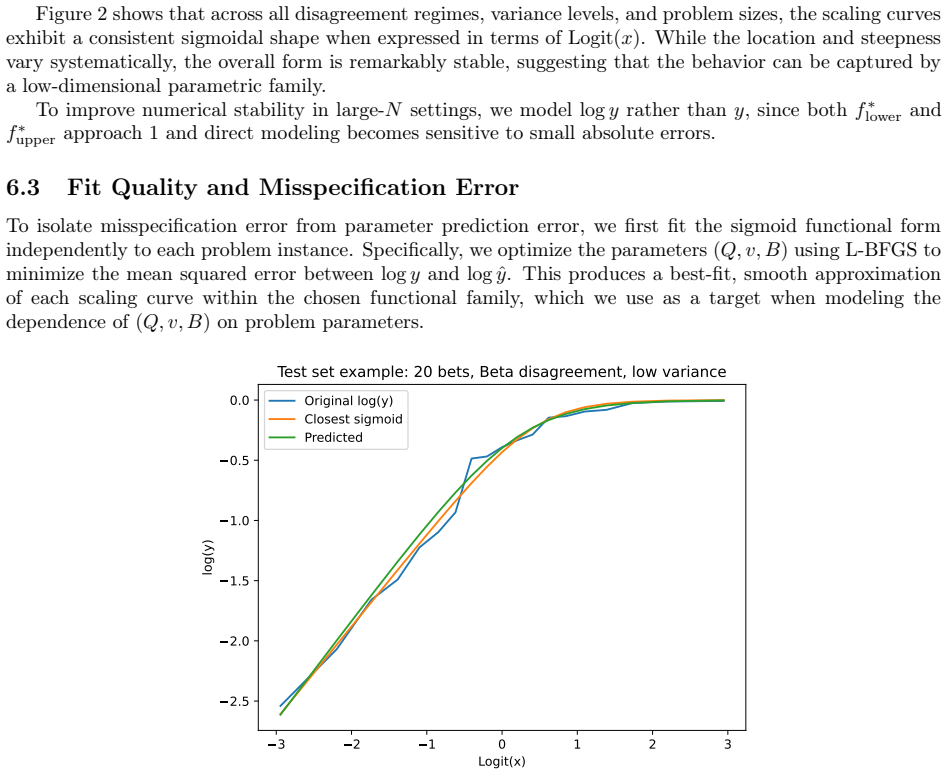
For a sequence of binary bets, the Kelly criterion provides a closed-form solution that maximizes the expected growth rate of wealth. In contrast, when multiple bets are placed simultaneously (e.g., in portfolio allocation or prediction markets), the optimal Kelly strategy generally requires numerical optimization over a joint outcome space. A naive formulation scales exponentially in the number of bets, requiring $O(2^N)$ time and memory for $N$ simultaneous wagers, which restricts existing methods to small problem sizes. We present two complementary methods that dramatically extend the scale of multivariate Kelly problems that can be solved. First, in the case of independent bets, we introduce an integral transform formulation that eliminates explicit enumeration of outcomes, reducing the computational complexity of evaluating the objective from $O(2^N)$ to $O(N)$. Combined with numerically stable quadrature, this enables accurate solutions for problems involving hundreds of bets. Second, we develop a decomposition-based approach that constructs and solves carefully chosen subproblems, yielding feasible lower bounds and infeasible upper bounds on the optimal growth rate. This provides a practical mechanism for quantifying worst-case suboptimality as a function of subproblem size. Together, these methods make it possible to study the large-$N$ regime of the multivariate Kelly problem. Using synthetic data inspired by prediction markets, we show that the relationship between subproblem size and solution accuracy follows a simple and highly regular scaling law. In particular, the shortfall ratio between the lower and upper bounds is well-approximated by a sigmoid function of the relative subproblem size, with parameters that can be predicted from low-dimensional summary statistics of the problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for sequences of binary bets, an integral transform formulation for independent cases reduces objective evaluation from O(2^N) to O(N) complexity, enabling accurate solutions for hundreds of bets via stable quadrature. A complementary decomposition constructs subproblems to yield feasible lower bounds and infeasible upper bounds on the optimal growth rate. On synthetic data inspired by prediction markets, the shortfall ratio between bounds is shown to follow a sigmoidal function of relative subproblem size, with parameters predictable from low-dimensional summary statistics of the problem.
Significance. If the accuracy claims hold and the scaling generalizes, the methods would substantially extend the solvable scale of multivariate Kelly problems in portfolio allocation and prediction markets, moving beyond the exponential barrier of naive formulations. The empirical identification of a regular sigmoidal shortfall law, even if limited to synthetics, offers a practical tool for quantifying approximation quality as a function of subproblem size. The work provides reproducible synthetic experiments demonstrating these behaviors.
major comments (3)
- Abstract and §3 (integral transform and quadrature): the claim of accurate solutions for hundreds of bets is not supported by error analysis, convergence rates, or direct comparisons against exact optima obtained for small N; without these, the central algorithmic efficiency claim cannot be fully assessed.
- §4 (decomposition bounds and scaling experiments): the sigmoidal shortfall law and its parameter predictability from summary statistics are reported only on synthetic instances; no validation against real prediction-market odds, historical returns, or empirical correlations is provided, which is load-bearing for claims of practical utility in multivariate Kelly settings.
- §5 (scaling law results): the relationship is presented as an empirical observation without derivation or proof that the sigmoid form is not an artifact of the synthetic generator (e.g., independence or marginal choices); the risk of circularity in fitting parameters on the same data used to compute the summary statistics needs explicit checks.
minor comments (2)
- Notation for the integral transform could be made more explicit by defining the measure and kernel in a dedicated subsection to aid reproducibility.
- Figure captions for the scaling plots should include the exact synthetic data parameters (e.g., number of instances, bet probabilities) for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. We address each major comment point by point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Abstract and §3 (integral transform and quadrature): the claim of accurate solutions for hundreds of bets is not supported by error analysis, convergence rates, or direct comparisons against exact optima obtained for small N; without these, the central algorithmic efficiency claim cannot be fully assessed.
Authors: We agree that stronger supporting evidence is required for the accuracy claims. In the revised manuscript we will add a dedicated error analysis subsection in §3, including convergence rates of the quadrature approximation as a function of the number of nodes, and direct numerical comparisons against exact enumeration for all N ≤ 12 (where 2^N remains computationally feasible). These results will be used to quantify the error for larger N and the abstract will be updated to reflect the supported accuracy statements. revision: yes
-
Referee: §4 (decomposition bounds and scaling experiments): the sigmoidal shortfall law and its parameter predictability from summary statistics are reported only on synthetic instances; no validation against real prediction-market odds, historical returns, or empirical correlations is provided, which is load-bearing for claims of practical utility in multivariate Kelly settings.
Authors: The current experiments deliberately use synthetic instances to isolate scaling behavior under controlled conditions. We acknowledge that direct validation on real prediction-market data would strengthen practical-utility claims. In revision we will expand the discussion in §4 to (i) clarify the synthetic generator’s design choices, (ii) provide explicit guidance on estimating the required low-dimensional summary statistics from empirical odds or returns, and (iii) moderate language regarding immediate applicability to real markets. We cannot add new real-data experiments in this revision cycle. revision: partial
-
Referee: §5 (scaling law results): the relationship is presented as an empirical observation without derivation or proof that the sigmoid form is not an artifact of the synthetic generator (e.g., independence or marginal choices); the risk of circularity in fitting parameters on the same data used to compute the summary statistics needs explicit checks.
Authors: We present the sigmoidal scaling as an empirical regularity observed across a large suite of synthetic instances. To address the referee’s concerns we will add, in the revised §5: (a) sensitivity experiments that vary the synthetic generator (including controlled introduction of dependence), (b) a cross-validation protocol that fits sigmoid parameters on one subset of instances and evaluates on held-out instances, and (c) a short discussion of why a sigmoid shape is plausible given the structure of the decomposition bounds. The text will explicitly label the relation as an observed scaling law rather than a derived theorem. revision: yes
Circularity Check
No circularity: scaling law is empirical observation from synthetic experiments
full rationale
The paper's core contribution consists of two algorithmic methods (integral transform for independent bets reducing complexity to O(N), and decomposition yielding bounds on suboptimality). These are used to generate numerical results on synthetic instances, from which the sigmoidal relationship between subproblem size and shortfall ratio is reported as an observed pattern. The abstract states that parameters 'can be predicted from low-dimensional summary statistics' but presents this as a post-hoc empirical regularity rather than a derivation or fitted input renamed as prediction. No equations, self-citations, or uniqueness theorems are invoked that reduce the reported scaling law to the inputs by construction. The finding is therefore self-contained against external benchmarks and receives the default non-circularity score.
Axiom & Free-Parameter Ledger
free parameters (1)
- sigmoid parameters (location, scale, etc.)
axioms (2)
- standard math The growth-rate objective is the expectation of log(1 + return) over the joint outcome distribution.
- domain assumption Bets are either fully independent or can be decomposed into independent subproblems.
Reference graph
Works this paper leans on
-
[1]
Investment policies for expanding businesses optimal in a long-run sense
[Bre60] Leo Breiman. “Investment policies for expanding businesses optimal in a long-run sense”. In:Naval Research Logistics Quarterly7.4 (1960), pp. 647–651. [Kel56] John L Kelly. “A new interpretation of information rate”. In:Bell System Technical Journal35.4 (1956), pp. 917–926. 15 [Mer69] Robert C Merton. “Lifetime portfolio selection under uncertaint...
1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.