Recognition: unknown
Application of a Mixture of Experts-based Foundation Model to the GlueX DIRC Detector
Pith reviewed 2026-05-10 07:35 UTC · model grok-4.3
The pith
A single Mixture-of-Experts foundation model performs fast simulation, particle identification, and noise filtering for the GlueX DIRC detector using one shared backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
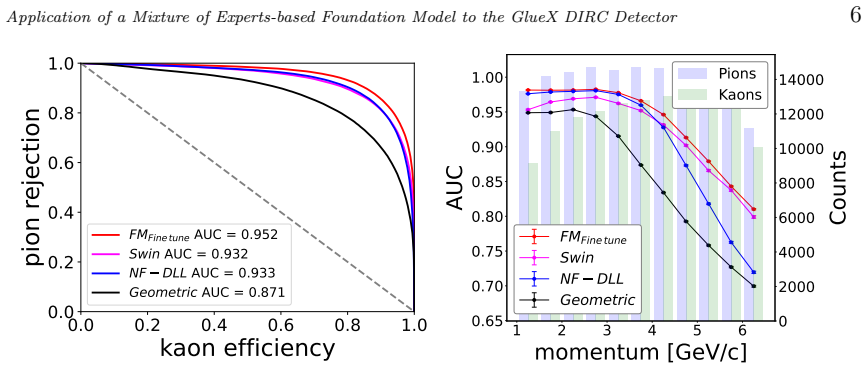
The authors apply a Mixture-of-Experts-based foundation model to the GlueX DIRC detector, showing that a single shared transformer backbone with autoregressive generation over split spatial and temporal vocabularies and continuous kinematic conditioning can perform fast simulation, particle identification, and hit-level noise filtering of Cherenkov photons for pions and kaons without any architectural modifications or post-training adjustments, achieving performance competitive with or superior to standard geometrical reconstruction and prior deep learning methods across the full kinematic phase space.
What carries the argument
The Mixture-of-Experts routing within a shared transformer backbone that enables class-conditional autoregressive generation of hits conditioned on continuous kinematics.
If this is right
- The model replaces separate pipelines for simulation, identification, and filtering with one architecture.
- It operates directly on low-level hit data without intermediate feature engineering.
- Class-conditional generation produces targeted pion and kaon samples from the same backbone.
- Performance holds across the detector's full kinematic phase space without retraining adjustments.
Where Pith is reading between the lines
- The same backbone could be tested on data from other Cherenkov-based detectors to check transfer without redesign.
- Consolidating tasks might reduce the total compute and code maintenance needed for large detector collaborations.
- Extensions could combine DIRC outputs with other subsystems to perform partial event reconstruction in one pass.
- Scaling to higher event rates in future runs would test whether the autoregressive generation remains efficient.
Load-bearing premise
That a single shared transformer backbone with Mixture-of-Experts routing and autoregressive generation over split spatial-temporal vocabularies plus continuous kinematic conditioning can maintain competitive performance on all three tasks without task-specific architectural changes or post-training adjustments.
What would settle it
Direct benchmarks on GlueX DIRC data showing the model underperforms standard geometrical reconstruction on particle identification accuracy for kaons over a substantial fraction of the kinematic phase space, or requires added task-specific layers to reach parity on any of the three tasks.
Figures





read the original abstract
We present a Mixture-of-Experts-based foundation model applied to the GlueX DIRC detector at Jefferson Lab, demonstrating its utility as a unified framework for fast simulation, particle identification, and hit-level noise filtering of Cherenkov photons. By leveraging a single shared transformer backbone across all tasks, the approach eliminates the fragmentation of task-specific pipelines while maintaining competitive-and in several cases superior-performance relative to established methods. The model operates directly on low-level detector inputs, performing hit-by-hit autoregressive generation over split spatial and temporal vocabularies with continuous kinematic conditioning, and supports class-conditional generation of pions and kaons through its Mixture-of-Experts architecture. We benchmark against the standard geometrical reconstruction and prior deep learning methods across the full kinematic phase space of the GlueX DIRC, demonstrating that the foundation model framework transfers effectively to this detector without architectural modification. This work positions the foundation model as a practical and scalable alternative to the suite of task-specific models currently proposed for GlueX DIRC analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Mixture-of-Experts (MoE) foundation model applied to the GlueX DIRC detector for three tasks: fast simulation of Cherenkov photons, particle identification (PID), and hit-level noise filtering. It employs a single shared transformer backbone performing autoregressive generation over split spatial-temporal vocabularies with continuous kinematic conditioning, and uses the MoE architecture for class-conditional generation of pions and kaons. The central claim is that this unified framework transfers effectively to the GlueX DIRC without architectural modification or post-training adjustments, achieving competitive or superior performance relative to standard geometrical reconstruction and prior deep-learning methods across the full kinematic phase space.
Significance. If the reported benchmarks are substantiated with quantitative details, the work is significant for demonstrating practical transfer of a foundation-model approach to a specific high-energy physics detector system. It offers a scalable alternative to fragmented task-specific pipelines, with strengths in operating directly on low-level inputs and supporting multiple tasks via a shared backbone and MoE routing. This could influence analysis strategies for similar Cherenkov detectors if the performance holds without hidden task-specific tuning.
major comments (1)
- Results section (benchmarks against geometrical reconstruction and prior DL methods): The abstract and summary assert competitive or superior performance across tasks and the full kinematic phase space, but the provided text supplies no quantitative metrics, tables, error bars, data-split descriptions, or statistical tests. This information is load-bearing for the central claim of effective transfer without modification; its absence prevents verification that the single shared backbone maintains the required performance levels on all three tasks.
minor comments (2)
- The description of the split spatial-temporal vocabularies and continuous kinematic conditioning would benefit from an explicit equation or diagram in the methods section to clarify how autoregressive generation is implemented over these components.
- Clarify in the introduction or methods whether any task-specific post-processing or fine-tuning steps were applied despite the claim of no architectural modification or post-training adjustments.
Simulated Author's Rebuttal
We thank the referee for their careful reading and positive recommendation for minor revision. We appreciate the emphasis on the need for quantitative substantiation of the performance claims and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Results section (benchmarks against geometrical reconstruction and prior DL methods): The abstract and summary assert competitive or superior performance across tasks and the full kinematic phase space, but the provided text supplies no quantitative metrics, tables, error bars, data-split descriptions, or statistical tests. This information is load-bearing for the central claim of effective transfer without modification; its absence prevents verification that the single shared backbone maintains the required performance levels on all three tasks.
Authors: We agree that the original submission did not include sufficient quantitative metrics, tables, error bars, data-split details, or statistical tests in the Results section, which are necessary to support the central claims. In the revised manuscript we have expanded the Results section with comprehensive benchmarks for all three tasks. These now include tables reporting quantitative metrics (e.g., Cherenkov photon generation fidelity, PID efficiency and purity versus momentum and polar angle, noise rejection rates) with direct comparisons to geometrical reconstruction and prior deep-learning methods. Error bars derived from bootstrap or binomial statistics are provided, data splits are explicitly described (80/10/10 train/validation/test with uniform coverage of the full kinematic phase space), and statistical tests (e.g., paired t-tests or chi-squared goodness-of-fit) are reported to establish significance. The added material confirms that the single shared transformer backbone with MoE routing achieves competitive or superior performance on simulation, PID, and noise filtering without any architectural modification or task-specific post-training adjustments. revision: yes
Circularity Check
No significant circularity; empirical benchmarks against external methods
full rationale
The paper applies a pre-existing MoE foundation model architecture to GlueX DIRC data for three tasks, reporting empirical performance benchmarks against standard geometrical reconstruction and prior deep learning methods across the full kinematic phase space. No equations, derivations, or first-principles predictions are presented that reduce claimed results to inputs by construction. The central claim of effective transfer without architectural modification rests on external comparisons rather than self-referential fitting or self-citation chains. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A shared transformer backbone with Mixture-of-Experts routing can perform autoregressive generation on split spatial-temporal vocabularies while conditioned on continuous kinematics for multiple detector tasks
Reference graph
Works this paper leans on
-
[1]
The GlueX beamline and detector 2021 Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment987164807
Adhikari S et al. The GlueX beamline and detector 2021 Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment987164807
2021
-
[2]
Stevens J et al. The GlueX DIRC project 2016 J. Instrum.11C07010 (arXiv:1606.05645)
-
[3]
Status of the GlueX DIRC 2018 Nucl
Patsyuk M et al. Status of the GlueX DIRC 2018 Nucl. Instrum. Methods Phys. Res. A
2018
-
[4]
(GEANT4) GEANT4 GEANT4–a simulation toolkit 2003 Nucl
Agostinelli S et al. (GEANT4) GEANT4 GEANT4–a simulation toolkit 2003 Nucl. Instrum. Methods Phys. Res. A: Accel. Spectrom. Detect. Assoc. Equip.506250–303
2003
-
[5]
Fanelli C and Pomponi J DeepRICH: learning deeply Cherenkov detectors 2020 Machine Learning: Science and Technology1015010
2020
-
[6]
Fanelli C, Giroux J and Stevens J Deep (er) reconstruction of imaging Cherenkov detectors with swin transformers and normalizing flow models 2025 Machine Learning: Science and Technology6015028
2025
-
[7]
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S and Guo B 2021 Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) pp 10012–10022
2021
- [8]
- [9]
-
[10]
Giroux J and Fanelli C Towards foundation models for experimental readout systems combining discrete and continuous data 2026 Machine Learning: Science and Technology7015031
2026
-
[11]
Birk J, Hallin A and Kasieczka G OmniJet-α: the first cross-task foundation model for particle physics 2024 Machine Learning: Science and Technology5035031
2024
-
[12]
Mikuni V and Nachman B Method to simultaneously facilitate all jet physics tasks 2025 Physical Review D111ISSN 2470-0029
2025
-
[13]
Birk J, Gaede F, Hallin A, Kasieczka G, Mozzanica M and Rose H OmniJet-α C: learning point cloud calorimeter simulations using generative transformers 2025 Journal of Instrumentation 20P07007
2025
-
[14]
Hsu T H, Zhou B H, Liu Q, Xu Y, Li S, Hou G W S, Nachman B, Hsu S C, Mikuni V, Chou Y T and Zhang Y 2026 EveNet: A Foundation Model for Particle Collision Data Analysis (arXiv:2601.17126) URLhttps://arxiv.org/abs/2601.17126 Application of a Mixture of Experts-based Foundation Model to the GlueX DIRC Detector13
-
[15]
Elsharkawy I, Mikuni V, Bhimji W and Nachman B 2026 OmniMol: Transferring Particle Physics Knowledge to Molecular Dynamics with Point-Edge Transformers (arXiv:2601.10791) URLhttps://arxiv.org/abs/2601.10791
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
- [17]
-
[18]
Finke T, Kr¨ amer M, M¨ uck A and T¨ onshoff J Learning the language of QCD jets with transformers 2023 Journal of High Energy Physics20231–18
2023
-
[19]
Bardhan J, Agrawal R, Tilak A, Neeraj C and Mitra S Hep-jepa: A foundation model for collider physics ICLR 2025 Workshop on World Models: Understanding, Modelling and Scaling
2025
-
[20]
Leigh M, Klein S, Charton F, Golling T, Heinrich L, Kagan M, Ochoa I and Osadchy M Is tokenization needed for masked particle modelling? 2025 Machine Learning: Science and Technology
2025
-
[21]
Vigl M, Hartman N and Heinrich L Finetuning foundation models for joint analysis optimization in High Energy Physics 2024 Machine Learning: Science and Technology5 025075
2024
-
[22]
Golling T, Heinrich L, Kagan M, Klein S, Leigh M, Osadchy M and Andrew Raine J Masked particle modeling on sets: towards self-supervised high energy physics foundation models 2024 Machine Learning: Science and Technology5035074
2024
-
[23]
Bumblebee: Foundation Model for Particle Physics Discovery 2024 arXiv preprint arXiv:2412.07867
Wildridge A J, Rodgers J P, Colbert E M, Jung A W, Liu M et al. Bumblebee: Foundation Model for Particle Physics Discovery 2024 arXiv preprint arXiv:2412.07867
- [24]
-
[25]
Core8026
Butter A, Huetsch N, Schweitzer S P, Plehn T, Sorrenson P and Spinner J Jet diffusion versus JetGPT – Modern networks for the LHC 2025 SciPost Phys. Core8026
2025
-
[26]
Shazeer N, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G and Dean J Outrageously large neural networks: The sparsely-gated mixture-of-experts layer 2017 arXiv preprint arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Kalicy G The high-performance DIRC for the ePIC detector at the EIC 2024 Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment 169168
2024
-
[28]
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L and Polosukhin I Attention is all you need 2017 Advances in neural information processing systems30
2017
-
[29]
Hendrycks D and Gimpel K Gaussian error linear units (GeLUs) 2016 (arXiv:1606.08415)
work page Pith review arXiv 2016
-
[30]
Ba J L, Kiros J R and Hinton G E Layer normalization 2016 arXiv preprint arXiv:1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Xiong R, Yang Y, He D, Zheng K, Zheng S, Xing C, Zhang H, Lan Y, Wang L and Liu T 2020 On layer normalization in the transformer architecture International conference on machine learning (PMLR) pp 10524–10533
2020
- [32]
-
[33]
Lin T Y, Goyal P, Girshick R, He K and Doll´ ar P 2017 Focal loss for dense object detection Proceedings of the IEEE international conference on computer vision pp 2980–2988
2017
-
[34]
Scaling Laws for Neural Language Models
Kaplan J, McCandlish S, Henighan T, Brown T B, Chess B, Child R, Gray S, Radford A, Wu J and Amodei D 2020 Scaling Laws for Neural Language Models (arXiv:2001.08361) URL Application of a Mixture of Experts-based Foundation Model to the GlueX DIRC Detector14 https://arxiv.org/abs/2001.08361 Application of a Mixture of Experts-based Foundation Model to the ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.