Recognition: 2 theorem links
· Lean TheoremArchitecture Determines Observability of Transformers
Pith reviewed 2026-05-13 07:28 UTC · model grok-4.3
The pith
Transformer architecture determines whether a residual decision-quality signal survives in hidden activations beyond what output confidence reveals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
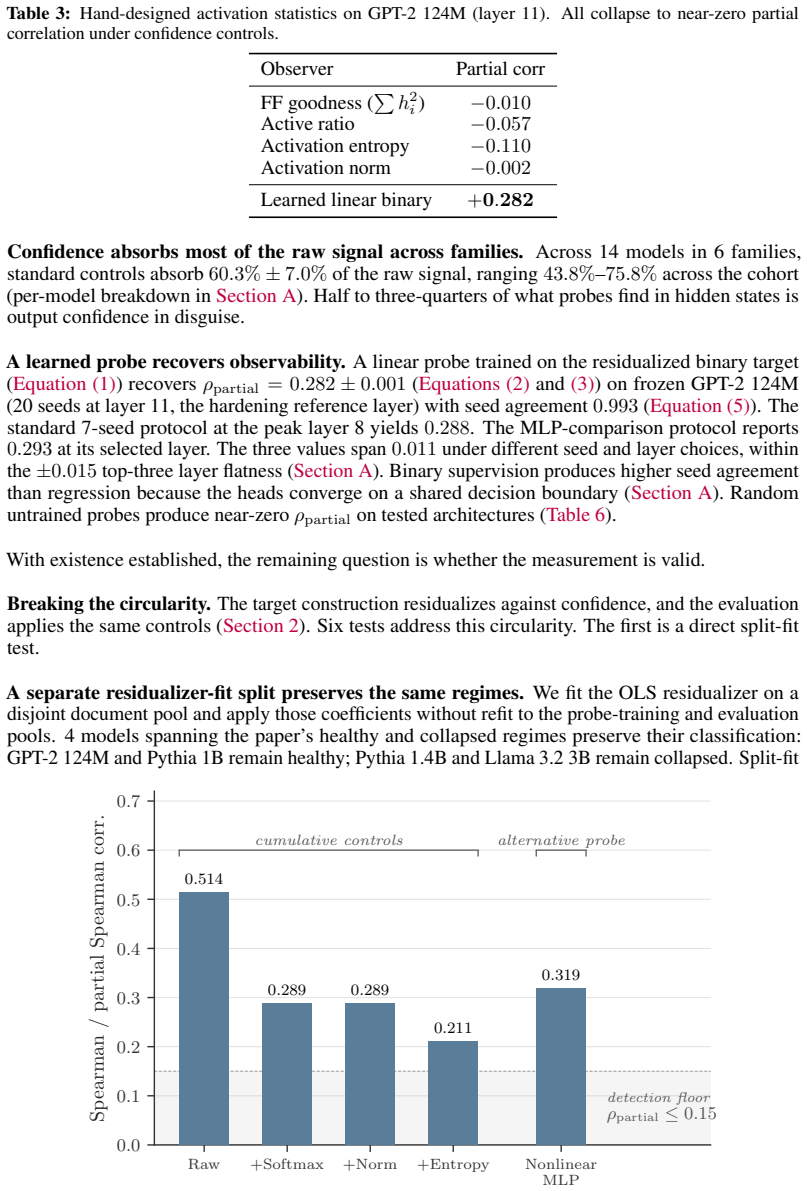
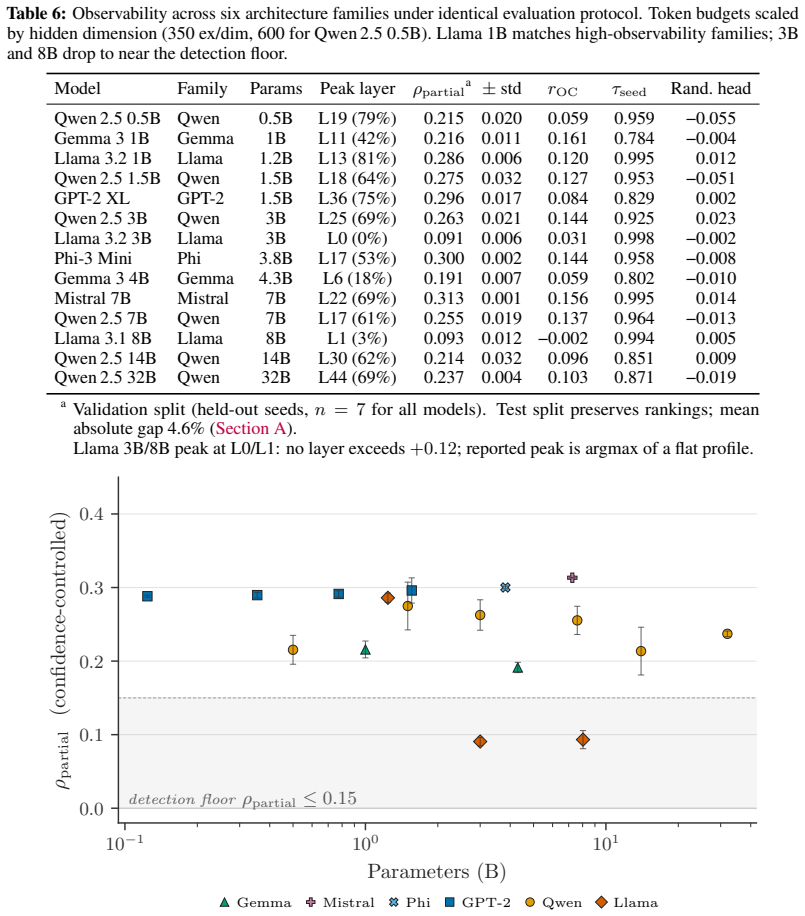
Autoregressive transformers make confident errors that output-confidence monitoring cannot catch. Activation monitors catch them only when training leaves a decision-quality signal beyond what the output already exposes. This signal is an architectural property of the trained model, fixed upstream of any monitor. Controlling for output confidence removes 60.3 percent of the raw activation-probe signal on average across 14 models. Raw probe signal is mostly output confidence, and output-side readouts cannot recover the residual. What remains depends on architecture and training. In Pythia's controlled training, both matched-width configurations form the signal early. One preserves it through
What carries the argument
The residual activation signal in hidden states after regressing out output confidence, which carries information about decision quality that architecture and training can preserve or erase.
If this is right
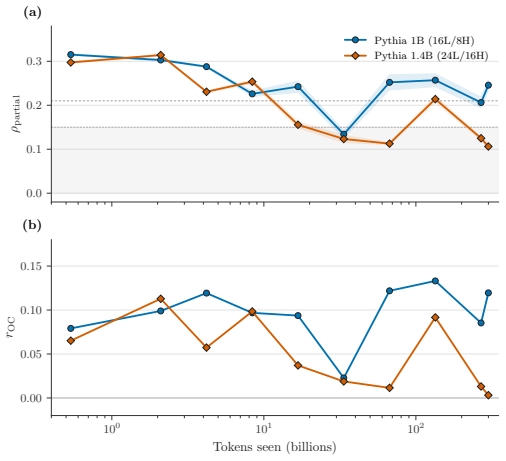
- In Pythia's controlled training, matched-width configurations form the residual signal early but one preserves it through convergence while the other erases it as perplexity improves.
- Across independently trained model families the pattern of partial survival persists even as the collapse point shifts.
- Where the residual signal survives, activation monitoring catches confident errors that output-confidence checks miss.
- A WikiText-trained probe with no task-specific tuning catches about one in eight such errors on downstream QA at a 20 percent flag rate.
- Signal engineering can be treated as a training-time design axis alongside loss and capability.
Where Pith is reading between the lines
- Architectures that preserve the residual signal could be selected deliberately to improve monitorability without sacrificing capability.
- Training schedules might be adjusted to retain the signal even after perplexity has stabilized.
- The separation of architecture from training effects suggests observability can be engineered as an independent objective.
- Similar residual-signal analysis could be applied to other monitoring methods to test whether they also depend on architectural choices.
Load-bearing premise
The residual activation signal after removing output confidence genuinely reflects the quality of the model's internal decision rather than some other correlated but non-causal feature of the hidden states.
What would settle it
An experiment in which the residual activation probe's error-detection accuracy falls to chance levels on held-out data after output confidence is controlled for, or in which the signal can be removed without changing actual error rates.
Figures






read the original abstract
Autoregressive transformers make confident errors that output-confidence monitoring cannot catch. Activation monitors catch them only when training leaves a decision-quality signal beyond what the output already exposes. This signal is an architectural property of the trained model, fixed upstream of any monitor. Controlling for output confidence removes 60.3% of the raw activation-probe signal on average across 14 models. Raw probe signal is mostly output confidence, and output-side readouts cannot recover the residual. What remains depends on architecture and training. In Pythia's controlled training, both matched-width configurations form the signal early. One preserves it through convergence while another erases it as perplexity continues to improve. Capability and observability are not inherently in tension. Across independently trained families this pattern persists, even as the collapse point shifts. Where the signal survives, monitoring catches what confidence cannot. On downstream QA, a WikiText-trained probe with no task-specific tuning catches about one in eight confident errors that output-confidence monitoring misses, at a 20% flag rate. These results establish signal engineering as a training-time design axis alongside loss and capability. Architecture sets the conditions for observability, and training determines what remains readable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive transformers produce confident errors undetectable by output-confidence monitoring, but activation probes can recover a residual decision-quality signal after regressing out confidence. This residual is presented as an architectural property fixed upstream of any monitor, with experiments showing that controlling for output confidence removes 60.3% of the raw probe signal on average across 14 models. In controlled Pythia runs, the signal forms early and is preserved or erased depending on architecture and training dynamics; a WikiText-trained probe catches roughly one in eight confident errors missed by confidence monitoring at a 20% flag rate on downstream QA.
Significance. If the central empirical claims hold after addressing controls, the work establishes signal engineering as a distinct training-time design axis alongside loss and capability. It shows that architecture sets observability conditions while training determines what remains readable, offering a concrete route to improve monitorability without inherent capability trade-offs.
major comments (3)
- [Abstract] Abstract: the reported 60.3% average removal of raw activation-probe signal by regressing output confidence lacks any description of the probe architecture, the precise regression procedure (e.g., linear vs. other), or statistical controls such as error bars, cross-validation, or significance testing, rendering the quantitative claim difficult to evaluate.
- [Abstract] Abstract and results sections: the claim that the residual signal after confidence regression indexes decision quality (rather than correlated but non-causal features such as token frequency, position, or input entropy) is load-bearing for the architectural-property conclusion; the manuscript provides no controls that regress out these additional confounders to isolate the decision-quality component.
- [Pythia experiments] Pythia controlled-training experiments: the assertion that one matched-width configuration preserves the residual while another erases it as perplexity improves requires explicit specification of the architectural differences (e.g., layer widths, attention variants) and quantitative evidence that the erasure is not an artifact of the regression step itself.
minor comments (1)
- The abstract states results across 14 models but does not enumerate them or reference a table; adding an explicit model list or summary table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to incorporate additional methodological details and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 60.3% average removal of raw activation-probe signal by regressing output confidence lacks any description of the probe architecture, the precise regression procedure (e.g., linear vs. other), or statistical controls such as error bars, cross-validation, or significance testing, rendering the quantitative claim difficult to evaluate.
Authors: We agree that the abstract omitted these details. The revised manuscript now specifies that linear probes were used throughout, that the regression is ordinary least squares, and that the 60.3% figure is reported with standard errors from 5-fold cross-validation together with p-values from paired t-tests. revision: yes
-
Referee: [Abstract] Abstract and results sections: the claim that the residual signal after confidence regression indexes decision quality (rather than correlated but non-causal features such as token frequency, position, or input entropy) is load-bearing for the architectural-property conclusion; the manuscript provides no controls that regress out these additional confounders to isolate the decision-quality component.
Authors: We acknowledge the absence of these controls. In the revision we add regressions that partial out token frequency, absolute position, and input entropy; the residual signal remains statistically significant after these controls, supporting the decision-quality interpretation. revision: yes
-
Referee: [Pythia experiments] Pythia controlled-training experiments: the assertion that one matched-width configuration preserves the residual while another erases it as perplexity improves requires explicit specification of the architectural differences (e.g., layer widths, attention variants) and quantitative evidence that the erasure is not an artifact of the regression step itself.
Authors: We will add an explicit table listing the differing hyperparameters (attention head dimension, MLP expansion ratio, and rotary embedding base) between the two matched-width Pythia runs. We also include a control analysis in which we apply the identical regression pipeline to synthetic activation vectors that contain only the confidence component; the differential preservation pattern is absent in the synthetic case, indicating the observed erasure is not an artifact of the regression. revision: yes
Circularity Check
No significant circularity; empirical results are self-contained
full rationale
The paper presents an empirical study of activation probes on trained transformers, measuring the residual signal after linear regression on output confidence across 14 models and controlled Pythia families. No equations are provided that define the residual signal in terms of itself, rename fitted parameters as predictions, or import uniqueness via self-citation. The central claim that architecture sets observability conditions is supported by direct experimental comparisons of signal survival under different training regimes, without reducing to inputs by construction. All reported percentages and downstream QA results are computed from held-out data and independent model families, rendering the derivation chain non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearControlling for output confidence removes 60.3% of the raw activation-probe signal... ρ_partial (partial Spearman correlation controlling for these two covariates)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearboth matched-width configurations form the signal at the earliest measured checkpoint, and training erases it in the 1.4B
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024. URL https://arxiv.org/abs/2404.14219
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Anum Afzal, Florian Matthes, Gal Chechik, and Yftah Ziser. Knowing before saying: LLM representations encode information about chain-of-thought success before completion. In Findings of ACL, pp.\ 12791--12806, 2025. doi:10.18653/v1/2025.findings-acl.662. URL https://doi.org/10.18653/v1/2025.findings-acl.662
-
[3]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. In International Conference on Learning Representations, Workshop Track, 2017. URL https://openreview.net/forum?id=HJ4-rAVtl
work page 2017
-
[4]
The internal state of an LLM knows when it ' s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it's lying. In Findings of EMNLP, pp.\ 967--976, 2023. doi:10.18653/v1/2023.findings-emnlp.68. URL https://doi.org/10.18653/v1/2023.findings-emnlp.68
-
[5]
Probing Classifiers: Promises, Shortcomings, and Advances
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 0 (1): 0 207--219, 2022. doi:10.1162/coli_a_00422. URL https://doi.org/10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[6]
Pythia : A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia : A suite for analyzing large language models across training and scaling. In International Conference on Machine ...
work page 2023
-
[7]
Towards monosemanticity: Decomposing language models with dictionary learning
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023. URL https://transformer-circuits.pub/2023/monosemantic-features
work page 2023
-
[8]
Lennart B\" u rger, Fred A. Hamprecht, and Boaz Nadler. Truth is universal: Robust detection of lies in LLMs . In Advances in Neural Information Processing Systems (NeurIPS), 2024. URL https://openreview.net/forum?id=1Fc2Xa2cDK
work page 2024
-
[9]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In International Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=ETKGuby0hcs
work page 2023
-
[10]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile : An 800 GB dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2021. URL https://arxiv.org/abs/2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Gemma Team . Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025. URL https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Aaron Gokaslan and Vanya Cohen. OpenWebText corpus, 2019. URL https://skylion007.github.io/OpenWebTextCorpus/
work page 2019
-
[13]
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Kobi, and Neel Nanda. Detecting strategic deception using linear probes. In International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/abs/2502.03407
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y
Melody Y. Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y. Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, Jakub Pachocki, and Bowen Baker. Monitoring monitorability. arXiv preprint arXiv:2512.18311, 2025. URL https://arxiv.org/abs/2512.18311
-
[16]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning (ICML), pp.\ 1321--1330, 2017. URL https://proceedings.mlr.press/v70/guo17a.html
work page 2017
-
[17]
Jiatong Han, Neil Band, Muhammed Razzak, Jannik Kossen, Tim G. J. Rudner, and Yarin Gal. Simple factuality probes detect hallucinations in long-form natural language generation. In Findings of EMNLP, 2025. URL https://aclanthology.org/2025.findings-emnlp.880/
work page 2025
-
[18]
Designing and Interpreting Probes with Control Tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Proceedings of EMNLP-IJCNLP, pp.\ 2733--2743, 2019. doi:10.18653/v1/D19-1275. URL https://doi.org/10.18653/v1/D19-1275
-
[19]
TRUE : Re-evaluating factual consistency evaluation
Or Honovich, Roee Aharoni, Jonathan Herzig, Hagai Taitelbaum, Doron Kukliansy, Vered Cohen, Thomas Scialom, Idan Szpektor, Avinatan Hassidim, and Yossi Matias. TRUE : Re-evaluating factual consistency evaluation. In Proceedings of NAACL, pp.\ 3905--3920, 2022. doi:10.18653/v1/2022.naacl-main.287. URL https://doi.org/10.18653/v1/2022.naacl-main.287
-
[20]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet challenge: Evaluating the state of semantic code search. arXiv preprint arXiv:1909.09436, 2019. URL https://arxiv.org/abs/1909.09436
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[21]
Calibrating verbal uncertainty as a linear feature to reduce hallucinations
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung, and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations. In Proceedings of EMNLP, pp.\ 3769--3793, 2025. doi:10.18653/v1/2025.emnlp-main.187. URL https://doi.org/10.18653/v1/2025.emnlp-main.187
-
[22]
arXiv preprint arXiv:2505.13763 , year=
Li Ji-An, Hua-Dong Xiong, Robert C. Wilson, Marcelo G. Mattar, and Marcus K. Benna. Language models are capable of metacognitive monitoring and control of their internal activations. arXiv preprint arXiv:2505.13763, 2025. URL https://arxiv.org/abs/2505.13763
-
[23]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, et al. Mistral 7B . arXiv preprint arXiv:2310.06825, 2023. URL https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Applied Sciences, 11 0 (14): 0 6421, 2021. doi:10.3390/app11146421. URL https://doi.org/10.3390/app11146421
-
[25]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022. URL https://arxiv.org/abs/2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Chain of thought monitorability: A new and fragile opportunity for ai safety, 2025
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, et al. Chain of thought monitorability: A new and fragile opportunity for AI safety. arXiv preprint arXiv:2507.11473, 2025. URL https://arxiv.org/abs/2507.11473
-
[27]
Semantic entropy probes: Robust and cheap hallucination detection in LLMs
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in LLMs . In International Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id=YQvvJjLWX0
work page 2025
-
[28]
Building production-ready probes for Gemini
J\' a nos Kram\' a r, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for Gemini . arXiv preprint arXiv:2601.11516, 2026. URL https://arxiv.org/abs/2601.11516
-
[29]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In International Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=VD-AYtP0dve
work page 2023
-
[30]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. In Advances in Neural Information Processing Systems (NeurIPS), 2023. URL https://openreview.net/forum?id=aLLuYpn83y
work page 2023
-
[31]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA : Measuring how models mimic human falsehoods. In Proceedings of ACL, pp.\ 3214--3252, 2022. doi:10.18653/v1/2022.acl-long.229. URL https://doi.org/10.18653/v1/2022.acl-long.229
-
[32]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models. In Proceedings of EMNLP, pp.\ 9004--9017, 2023. doi:10.18653/v1/2023.emnlp-main.557. URL https://doi.org/10.18653/v1/2023.emnlp-main.557
-
[33]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of True/False datasets. In Conference on Language Modeling (COLM), 2024. URL https://openreview.net/forum?id=aajyHYjjsk
work page 2024
-
[34]
Neural chameleons: Language models can learn to hide their thoughts from unseen activation monitors
Max McGuinness, Alex Serrano, Luke Bailey, and Scott Emmons. Neural chameleons: Language models can learn to hide their thoughts from unseen activation monitors. arXiv preprint arXiv:2512.11949, 2025. URL https://arxiv.org/abs/2512.11949
-
[35]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations (ICLR), 2017. URL https://openreview.net/forum?id=Byj72udxe
work page 2017
-
[36]
Meta . Llama 3.2 3 B model card. https://huggingface.co/meta-llama/Llama-3.2-3B, 2024. Accessed 2026-04-26
work page 2024
-
[37]
doi: 10.18653/v1/2023.emnlp-main.741
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore : Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of EMNLP, pp.\ 12076--12100, 2023. doi:10.18653/v1/2023.emnlp-main.741. URL https://doi.org/10.18653/v1/2023.emnlp...
-
[38]
Beyond linear probes: Dynamic safety monitoring for language models
James Oldfield, Philip Torr, Ioannis Patras, Adel Bibi, and Fazl Barez. Beyond linear probes: Dynamic safety monitoring for language models. In International Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=AGWa8whf92
work page 2026
-
[39]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019. URL https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
work page 2019
-
[40]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21 0 (140): 0 1--67, 2020. URL https://jmlr.org/papers/v21/20-074.html
work page 2020
-
[41]
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don't know: Unanswerable questions for SQuAD . In Proceedings of ACL, pp.\ 784--789, 2018. doi:10.18653/v1/P18-2124. URL https://doi.org/10.18653/v1/P18-2124
-
[42]
GAVEL : Towards rule-based safety through activation monitoring
Shir Rozenfeld, Rahul Pankajakshan, Itay Zloczower, Eyal Lenga, Gilad Gressel, and Yisroel Mirsky. GAVEL : Towards rule-based safety through activation monitoring. In International Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=duntROHZ5R
work page 2026
-
[43]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://openreview.net/forum?id=uLYc4L3C81A
work page 2022
-
[44]
Open problems in mechanistic interpretability
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, et al. Open problems in mechanistic interpretability. Transactions on Machine Learning Research, 2025. URL https://openreview.net/forum?id=91H76m9Z94
work page 2025
-
[45]
Know your limits: A survey of abstention in large language models
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models. Transactions of the Association for Computational Linguistics (TACL), 13: 0 529--556, 2025. doi:10.1162/tacl_a_00754. URL https://doi.org/10.1162/tacl_a_00754
-
[46]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024. URL https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Reasoning models know when they're right: Probing hidden states for self-verification
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they're right: Probing hidden states for self-verification. In Conference on Language Modeling (COLM), 2025. URL https://openreview.net/forum?id=O6I0Av7683
work page 2025
-
[48]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.