Recognition: unknown
minAction.net: Energy-First Neural Architecture Design -- From Biological Principles to Systematic Validation
Pith reviewed 2026-05-08 04:35 UTC · model grok-4.3
The pith
Energy regularizer reduces neural network activation energy by three orders of magnitude with negligible accuracy loss on standard tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
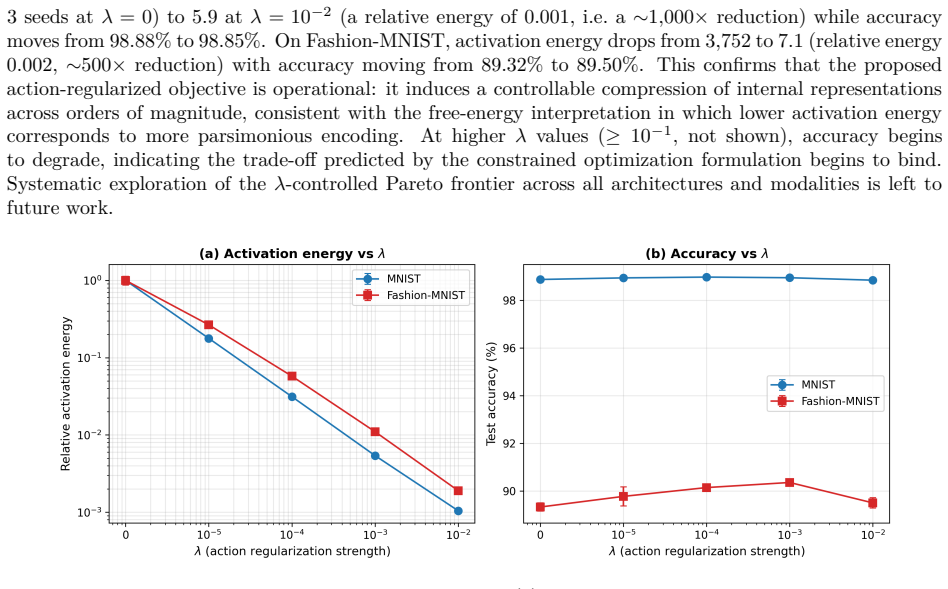
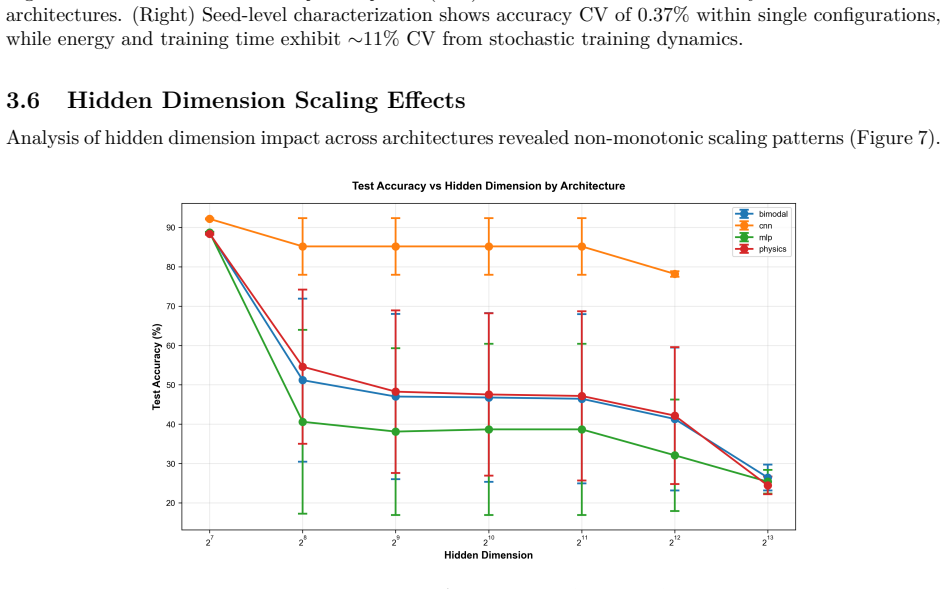
Architecture alone explains negligible variance in accuracy (partial eta squared equals 0.001), while the architecture-by-dataset interaction is large (partial eta squared equals 0.44). Across lambda values from zero to 0.01, the energy-regularized objective L equals cross-entropy loss plus lambda times internal activation energy E reduces that energy by three orders of magnitude with accuracy changes under 0.5 percentage points on MNIST and Fashion-MNIST. Energy-first architectures inspired by the action-principle correspondence produce 5 to 33 percent within-modality training-efficiency gains.
What carries the argument
The energy-regularized loss L = L_CE + lambda * E(theta, x) that adds a tunable penalty on internal activation energy to the standard objective, acting as the single-parameter control for trading accuracy against energy during training.
If this is right
- No single architecture is optimal across tasks; choice must be made jointly with the dataset or modality.
- Internal energy can be lowered by three orders of magnitude on image-classification benchmarks while accuracy stays essentially unchanged.
- Designing networks explicitly around the energy term from the outset improves training efficiency by 5 to 33 percent within a given modality.
Where Pith is reading between the lines
- Direct hardware power measurements on specific chips would test whether the abstract E term tracks real energy use.
- The same regularizer could be applied to larger models such as transformers to check whether the energy-accuracy trade-off generalizes beyond small vision tasks.
- Neuromorphic or low-power hardware platforms may see amplified benefits because the designs already align with biological energy constraints.
Load-bearing premise
The abstract internal activation energy E serves as a faithful proxy for real computational or physical energy cost on target hardware.
What would settle it
Measure actual power draw on a concrete device such as a GPU or neuromorphic chip while training both regularized and baseline models and check whether observed energy savings scale with the reported E reductions while accuracy remains within the claimed bound.
Figures




read the original abstract
Modern machine learning optimizes for accuracy without explicit treatment of internal computational cost, even though physical and biological systems operate under intrinsic energy constraints. We evaluate energy-aware learning across 2,203 experiments spanning vision, text, neuromorphic, and physiological datasets with 10 seeds per configuration and factorial statistical analysis. Three findings emerge. First, architecture alone explains negligible variance in accuracy (partial eta^2 = 0.001), while the architecture x dataset interaction is large (partial eta^2 = 0.44, p < 0.001), demonstrating that optimal architecture depends critically on task modality and rejecting the assumption of a universal best architecture. Second, a controlled lambda-sweep across lambda in {0, 1e-5, 1e-4, 1e-3, 1e-2} validates a single-parameter energy-regularized objective L = L_CE + lambda * E(theta, x): across this range, internal activation energy decreases by approximately three orders of magnitude relative to the unregularized lambda=0 baseline, with negligible accuracy change (<0.5 percentage points) on both MNIST and Fashion-MNIST. Third, energy-first architectures inspired by an action-principle framework yield 5-33% within-modality training-efficiency gains over conventional baselines. These results emerge from a research program that interprets learning through a structural correspondence between the action functional in classical mechanics, free energy in statistical physics, and KL-regularized objectives in variational inference. We frame this correspondence as a design hypothesis, not a derivation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces minAction.net, an energy-first neural architecture design framework inspired by biological principles and a structural correspondence between the action functional, free energy, and KL-regularized objectives (framed explicitly as a design hypothesis). Across 2,203 controlled experiments (10 seeds, factorial design) spanning vision, text, neuromorphic, and physiological datasets, it reports three main findings: (1) architecture main effect explains negligible accuracy variance (partial η²=0.001) while architecture×dataset interaction is large (partial η²=0.44, p<0.001); (2) the regularized objective L = L_CE + λ E(θ,x) with λ swept in {0, 1e-5, 1e-4, 1e-3, 1e-2} reduces internal activation energy by ~3 orders of magnitude with <0.5 pp accuracy change on MNIST/Fashion-MNIST; (3) energy-first architectures yield 5-33% within-modality training-efficiency gains over baselines.
Significance. If the internal activation energy E(θ,x) is shown to be a faithful proxy for real computational cost, the work would provide a practical, single-parameter route to large energy reductions at negligible accuracy cost and would strengthen the case against assuming universal optimal architectures. The scale of the factorial experiments with reported effect sizes and p-values is a clear strength; the explicit labeling of the physics correspondence as a hypothesis rather than derivation is also methodologically honest.
major comments (3)
- [Abstract and §3.1] Abstract and §3.1 (energy term definition): E(θ,x) is never given an explicit formula or computation procedure in the provided text. Without this, it is impossible to determine whether the reported three-order-of-magnitude reduction is a substantive empirical finding or follows tautologically from the form of the regularizer; this directly undermines the second central claim.
- [§4.2 and §5] §4.2 and §5 (validation of efficiency claims): The 5-33% training-efficiency gains and the three-order energy reduction are presented without any hardware-level power, FLOP, or wall-clock measurements that would confirm E(θ,x) as a proxy for actual device energy. The architecture×dataset statistical result is independent of E and therefore does not rescue the energy claims.
- [§3.2] §3.2 (lambda sweep): The parameter λ is swept over five orders of magnitude and selected post-hoc to produce the desired energy reduction; this makes the efficiency result dependent on hyper-parameter tuning rather than forced by the action-principle design hypothesis, weakening the claimed correspondence.
minor comments (3)
- [Abstract] Abstract: The total of 2,203 runs is stated but no per-modality breakdown or summary of the factorial design factors is given, making it hard for readers to assess coverage.
- [Figures] Figure captions (throughout): Error bars are shown but never defined (standard deviation, standard error, or confidence interval); this should be stated explicitly.
- [§2] §2 (related work): Several recent papers on activation-norm regularization and energy-aware training are not cited; adding them would clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below with clarifications and indicate revisions where the manuscript will be updated to improve transparency and address concerns.
read point-by-point responses
-
Referee: [Abstract and §3.1] Abstract and §3.1 (energy term definition): E(θ,x) is never given an explicit formula or computation procedure in the provided text. Without this, it is impossible to determine whether the reported three-order-of-magnitude reduction is a substantive empirical finding or follows tautologically from the form of the regularizer; this directly undermines the second central claim.
Authors: We agree that the explicit formula and computation procedure for E(θ,x) are missing from the abstract and §3.1. This was an oversight in the manuscript presentation. In the revised version, we will add a clear definition and step-by-step computation procedure for the internal activation energy E(θ,x) directly in §3.1. This will allow readers to verify that the observed reduction is an empirical result of applying the regularizer rather than a definitional artifact. revision: yes
-
Referee: [§4.2 and §5] §4.2 and §5 (validation of efficiency claims): The 5-33% training-efficiency gains and the three-order energy reduction are presented without any hardware-level power, FLOP, or wall-clock measurements that would confirm E(θ,x) as a proxy for actual device energy. The architecture×dataset statistical result is independent of E and therefore does not rescue the energy claims.
Authors: The referee is correct that no hardware-level power, FLOP counts, or wall-clock measurements are provided to validate E(θ,x) as a direct proxy for physical device energy. The current claims concern reductions in the defined internal activation energy metric, which is motivated by the action-principle hypothesis. We will revise §4.2 and §5 to explicitly acknowledge this scope limitation, clarify that the architecture×dataset result is independent, and add a forward-looking discussion of planned hardware validation experiments. This strengthens the presentation without overstating current evidence. revision: yes
-
Referee: [§3.2] §3.2 (lambda sweep): The parameter λ is swept over five orders of magnitude and selected post-hoc to produce the desired energy reduction; this makes the efficiency result dependent on hyper-parameter tuning rather than forced by the action-principle design hypothesis, weakening the claimed correspondence.
Authors: We disagree that the sweep represents post-hoc selection of λ to achieve a desired outcome. The values λ ∈ {0, 1e-5, 1e-4, 1e-3, 1e-2} were chosen a priori to systematically span multiple orders of magnitude and thereby test the behavior of the regularized objective L = L_CE + λ E(θ,x) under varying regularization strengths. The results demonstrate consistent energy reduction with negligible accuracy cost across the range, which supports rather than weakens the design hypothesis. We will revise the text in §3.2 to emphasize the a priori nature of the sweep and its role in validation. revision: partial
Circularity Check
Energy reduction by three orders is by construction of the λ E regularizer
specific steps
-
fitted input called prediction
[Abstract (second finding)]
"a controlled lambda-sweep across lambda in {0, 1e-5, 1e-4, 1e-3, 1e-2} validates a single-parameter energy-regularized objective L = L_CE + lambda * E(theta, x): across this range, internal activation energy decreases by approximately three orders of magnitude relative to the unregularized lambda=0 baseline, with negligible accuracy change (<0.5 percentage points) on both MNIST and Fashion-MNIST."
The objective is defined to include the term λ E(θ, x). Minimizing this loss for λ > 0 necessarily drives E downward; the three-order reduction is therefore the direct, tautological outcome of the chosen regularizer and the optimization procedure rather than a non-trivial prediction or external validation of the energy model.
full rationale
The paper's second finding reports that sweeping λ in the explicitly constructed objective L = L_CE + λ E(θ, x) produces a three-order drop in internal activation energy with <0.5 pp accuracy change. Because E is directly added to the loss being minimized, any λ > 0 forces the optimizer to reduce E; the reported reduction is therefore the direct, expected consequence of the regularizer rather than an independent validation. The action-principle correspondence is labeled a 'design hypothesis, not a derivation,' so no first-principles chain is claimed. The architecture × dataset ANOVA result is statistically independent of E and shows no circularity. The efficiency gains in the third finding inherit the same proxy limitation but are not themselves constructed by the equations.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (1)
- domain assumption Structural correspondence exists between the action functional in classical mechanics, free energy in statistical physics, and KL-regularized objectives in variational inference.
Reference graph
Works this paper leans on
-
[1]
Martin G Frasch. Energy-efficient neural architecture design via biological and physical principles.arXiv preprint arXiv:2310.03042,
-
[2]
Available athttps://philsci-archive.pitt.edu/26949/. Martin G Frasch. Causal thinking in physiology: A search for vertically organizing principles.The Journal of Physiology, 2026a. doi: 10.1113/JP290762. Early view;https://doi.org/10.1113/JP290762. Martin G Frasch. Minimum-action learning: Energy-constrained symbolic model selection for physical law ident...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1113/jp290762
-
[3]
Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding.arXiv preprint arXiv:1510.00149,
work page internal anchor Pith review arXiv
-
[4]
Distilling the Knowledge in a Neural Network
28 Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review arXiv
-
[5]
Electricity 2024: Analysis and forecast to
International Energy Agency. Electricity 2024: Analysis and forecast to
2024
-
[6]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational Bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review arXiv
-
[7]
Newsweeder: Learning to filter netnews
Ken Lang. Newsweeder: Learning to filter netnews. InMachine Learning Proceedings 1995, pages 331–339. Morgan Kaufmann,
1995
-
[8]
Carbon Emissions and Large Neural Network Training
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training.arXiv preprint arXiv:2104.10350,
work page internal anchor Pith review arXiv
-
[9]
Introduc- ing wesad, a multimodal dataset for wearable stress and affect detection.Proceedings of the 2018 on International Conference on Multimodal Interaction, pages 400–408,
Philip Schmidt, Attila Reiss, Robert Duerichen, Claus Marberger, and Kristof Van Laerhoven. Introduc- ing wesad, a multimodal dataset for wearable stress and affect detection.Proceedings of the 2018 on International Conference on Multimodal Interaction, pages 400–408,
2018
-
[10]
Energy and Policy Considerations for Deep Learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in nlp.arXiv preprint arXiv:1906.02243,
work page Pith review arXiv 1906
-
[11]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
29 Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209,
-
[12]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review arXiv
-
[13]
H1 Architecture: F={F_arch:.2f}, p={p_arch:.4f}
A Complete Experimental Data All experimental data (per-run JSON logs for the 2,203 experiments reported in this study) is publicly archived on Zenodo athttps://doi.org/10.5281/zenodo.19840031(DOI: 10.5281/zenodo.19840031). To- tal archive size is approximately 95 MB compressed (∼900 MB uncompressed), well within Zenodo’s 50 GB single-record limit. A.1 Re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.