Recognition: unknown
A Comparative Analysis on the Performance of Upper Confidence Bound Algorithms in Adaptive Deep Neural Networks
Pith reviewed 2026-05-08 04:20 UTC · model grok-4.3
The pith
Multiple Upper Confidence Bound strategies achieve sub-linear regret in Adaptive Deep Neural Networks and improve accuracy-energy and accuracy-latency trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
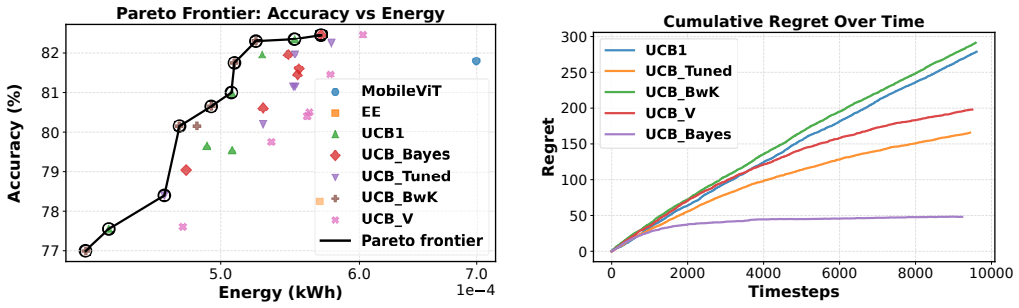
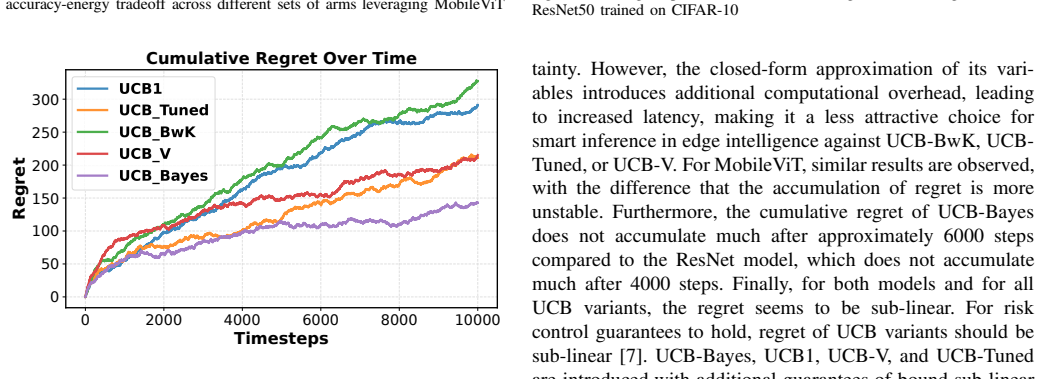
We introduce UCB-V, UCB-Tuned, UCB-Bayes, and UCB-BwK to ADNNs that use multi-armed bandits to pick confidence thresholds for early exits. Evaluated on ResNet and MobileViT across CIFAR-10, CIFAR-10.1 and CIFAR-100, all strategies produce sub-linear cumulative regret, with UCB-Bayes converging fastest, followed by UCB-Tuned and UCB-V. UCB-V and UCB-Tuned dominate the Pareto frontiers of accuracy versus latency and accuracy versus energy.
What carries the argument
Upper Confidence Bound variants applied as multi-armed bandit policies to select the confidence threshold for early exiting in Adaptive Deep Neural Networks at each inference step.
Load-bearing premise
The reward distributions of the bandit arms remain stationary from one inference to the next, and the benchmark datasets and models capture typical edge-device operating conditions.
What would settle it
A sequence of inferences on a dataset with non-stationary input statistics where cumulative regret grows linearly would disprove the sub-linear regret result for these strategies.
Figures



read the original abstract
Edge computing environments impose strict constraints on energy consumption and latency, making the deployment of deep neural networks a significant challenge. Therefore, smart and adaptive inference strategies that dynamically balance computational cost or latency with predictive accuracy are critical in edge computing scenarios. In this work, we build on Adaptive Deep Neural Networks (ADNNs) that employ the Multi-Armed Bandit (MAB) framework. Current literature leverages the first version of the Upper Confidence Bound (UCB1) strategy to dynamically select the optimal confidence threshold, enabling efficient early exits without sacrificing accuracy. However, we introduce four additional Upper Confidence Bound strategies in ADNNs, namely UCB-V, UCB-Tuned, UCB-Bayes, and UCB-BwK, and perform, for the first time, a comparative study of these strategies with respect to trade-offs between accuracy, energy consumption, and latency. The proposed UCB strategies are employed on the ResNet and MobileViT neural networks, and are evaluated on the benchmark datasets of CIFAR-10, CIFAR-10.1, and CIFAR-100. Experimental results demonstrate that all strategies achieve sub-linear cumulative regret, with UCB-Bayes converging the fastest, followed by UCB-Tuned and UCB-V. Finally, UCB-V and UCB-Tuned dominate the Pareto Frontiers of accuracy-latency and accuracy-energy trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes applying four additional UCB variants (UCB-V, UCB-Tuned, UCB-Bayes, UCB-BwK) alongside UCB1 to Adaptive Deep Neural Networks for dynamic early-exit threshold selection. Experiments on ResNet and MobileViT architectures across CIFAR-10, CIFAR-10.1, and CIFAR-100 demonstrate that all five strategies achieve sub-linear cumulative regret (with UCB-Bayes converging fastest), and that UCB-V and UCB-Tuned dominate the accuracy-latency and accuracy-energy Pareto fronts.
Significance. If the reported regret curves and Pareto dominance hold under more rigorous validation, the work supplies a useful empirical benchmark for choosing UCB policies in resource-constrained adaptive inference. The explicit comparison of convergence speed and multi-objective trade-offs on standard vision benchmarks provides practitioners with concrete guidance for edge-device DNN deployment.
major comments (2)
- [Abstract and Experimental Results] Abstract and Experimental Results: the headline claims of sub-linear regret and Pareto dominance rest on runs over fixed, stationary dataset splits. No experiments test non-stationary reward distributions (e.g., gradual or abrupt input shifts during the inference sequence), which directly contradicts the edge-computing motivation stated in the introduction and leaves the applicability of the dominance results to real deployments unverified.
- [Abstract and Experimental Details] Abstract and Experimental Details: the manuscript provides no information on the number of independent runs, statistical significance testing, variance across seeds, or the precise hyperparameter settings (learning rates, UCB exploration constants, exit thresholds) used for each variant and architecture. Without these, the robustness of the reported ordering (UCB-Bayes fastest, UCB-V/UCB-Tuned Pareto-dominant) cannot be assessed.
minor comments (1)
- [Figures] Figure captions and axis labels should explicitly state the number of runs and any error bars or confidence intervals used to generate the regret and Pareto plots.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] the headline claims of sub-linear regret and Pareto dominance rest on runs over fixed, stationary dataset splits. No experiments test non-stationary reward distributions (e.g., gradual or abrupt input shifts during the inference sequence), which directly contradicts the edge-computing motivation stated in the introduction and leaves the applicability of the dominance results to real deployments unverified.
Authors: We agree that our experiments are conducted on fixed, stationary dataset splits, which is the standard setting for evaluating UCB algorithms in MAB literature and for the CIFAR benchmarks used. The edge-computing motivation in the introduction highlights the need for adaptive inference under resource constraints, but our work focuses on establishing the comparative performance in controlled stationary environments as a foundational step. We did not perform non-stationary experiments, as that would require simulating input shifts (e.g., via data augmentation or sequential dataset changes), which is beyond the current scope. In the revision, we will add a paragraph in the discussion section acknowledging this limitation and outlining how the sub-linear regret property of UCB variants could extend to non-stationary cases with appropriate modifications like sliding windows or change detection. revision: partial
-
Referee: [Abstract and Experimental Details] the manuscript provides no information on the number of independent runs, statistical significance testing, variance across seeds, or the precise hyperparameter settings (learning rates, UCB exploration constants, exit thresholds) used for each variant and architecture. Without these, the robustness of the reported ordering (UCB-Bayes fastest, UCB-V/UCB-Tuned Pareto-dominant) cannot be assessed.
Authors: This is a valid point, and we apologize for the lack of these details in the original submission. We will revise the manuscript to include a comprehensive 'Experimental Setup' subsection detailing the number of independent runs, mean and standard deviation of regret and performance metrics across seeds, the precise hyperparameter values for each UCB variant and architecture (including exploration constants and exit thresholds), and results of statistical significance testing. This will allow readers to assess the robustness of our findings. revision: yes
Circularity Check
No circularity: purely empirical comparison of existing UCB variants
full rationale
The paper conducts an experimental study applying four UCB strategies (UCB-V, UCB-Tuned, UCB-Bayes, UCB-BwK) plus UCB1 baseline to ADNN early-exit selection on fixed CIFAR-10/10.1/100 splits with ResNet and MobileViT. All reported results (sub-linear cumulative regret, convergence ordering, Pareto dominance on accuracy-latency/energy) are direct measurements from simulation runs. No equations derive new quantities from fitted parameters, no predictions are made from the same data used to tune, and no self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is absent; the work is a standard benchmark comparison.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward distributions in the bandit formulation of early-exit threshold selection are stationary across inference steps.
Reference graph
Works this paper leans on
-
[1]
Perfor- mance analysis of filter pruning methods for edge classificat ion tasks,
A. Stefanidou, I. Kontopoulos, K. Tserpes, and I. V arlam is, “Perfor- mance analysis of filter pruning methods for edge classificat ion tasks,” in 2025 IEEE Intelligent Mobile Computing (MobileCloud) , 2025, pp. 51–58
2025
-
[2]
Conditional computation in neural networks: P rinciples and research trends,
S. Scardapane, A. Baiocchi, A. Devoto, V . Marsocci, P . Mi nervini, and J. Pomponi, “Conditional computation in neural networks: P rinciples and research trends,” Intelligenza Artificiale , vol. 18, no. 1, pp. 175– 190, 2024
2024
-
[3]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savar y, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand et al. , “Mixtral of experts,” arXiv preprint arXiv:2401.04088 , 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Early-exi t deep neural networks for distorted images: providing an efficient edge o ffloading,
R. G. Pacheco, F. D. Oliveira, and R. S. Couto, “Early-exi t deep neural networks for distorted images: providing an efficient edge o ffloading,” in 2021 IEEE Global Communications Conference (GLOBECOM) , 2021, pp. 1–6
2021
-
[5]
Dynexit: A dynam ic early- exit strategy for deep residual networks,
M. Wang, J. Mo, J. Lin, Z. Wang, and L. Du, “Dynexit: A dynam ic early- exit strategy for deep residual networks,” in 2019 IEEE International W orkshop on Signal Processing Systems (SiPS) , 2019, pp. 178–183
2019
-
[6]
CeeBERT: Cross-Domain In ference in Early Exit BERT,
D. J. Bajpai and M. K. Hanawal, “CeeBERT: Cross-Domain In ference in Early Exit BERT,” in Findings of the Association for Computational Linguistics: ACL 2024 , L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguis tics, Dec. 2024, pp. 1736–1748
2024
-
[7]
Beyond greedy exits: Improved early exit decisions for risk control and reliability,
——, “Beyond greedy exits: Improved early exit decisions for risk control and reliability,” arXiv preprint arXiv:2509.23666 , 2025
-
[8]
Adaee: Adaptive early-exit dnn inference through multi-armed bandits,
R. G. Pacheco, M. Shifrin, R. S. Couto, D. S. Menasch´ e, M. K. Hanawal, and M. E. M. Campista, “Adaee: Adaptive early-exit dnn inference through multi-armed bandits,” in ICC 2023-IEEE International Conference on Communications . IEEE, 2023, pp. 3726–3731
2023
-
[9]
Learning earl y exit for deep neural network inference on mobile devices through mul ti-armed bandits,
W. Ju, W. Bao, D. Y uan, L. Ge, and B. B. Zhou, “Learning earl y exit for deep neural network inference on mobile devices through mul ti-armed bandits,” in 2021 IEEE/ACM 21st International Symposium on Cluster , Cloud and Internet Computing (CCGrid) , 2021, pp. 11–20
2021
-
[10]
Dynamic early exit sche duling for deep neural network inference through contextual bandi ts,
W. Ju, W. Bao, L. Ge, and D. Y uan, “Dynamic early exit sche duling for deep neural network inference through contextual bandi ts,” in Proceedings of the 30th ACM International Conference on Inf ormation & Knowledge Management , 2021, pp. 823–832
2021
-
[11]
Unsupervised early exit in dnns with multiple exits,
M. K. Hanawal, A. Bhardwaj et al. , “Unsupervised early exit in dnns with multiple exits,” arXiv preprint arXiv:2209.09480 , 2022
-
[12]
SplitEE: Early Exit in Deep Neural Networks with Split Computing
D. J. Bajpai, V . K. Trivedi, S. L. Y adav, and M. K. Hanawal , “SplitEE: Early Exit in Deep Neural Networks with Split Computing.” [O nline]. Available: https://dl.acm.org/doi/epdf/10.1145/3639856.3639873
-
[13]
Branch yNet: Fast Inference via Early Exiting from Deep Neural Networks,
S. Teerapittayanon, B. McDanel, and H. T. Kung, “Branch yNet: Fast Inference via Early Exiting from Deep Neural Networks,” arXiv.org, Sep. 2017
2017
-
[14]
Early-Exit Deep Neural Network - A Comprehensive Survey,
R. PHaseena, SrivastavaVishal, ChaurasiaKuldeep, P . G, and C. S, “Early-Exit Deep Neural Network - A Comprehensive Survey,” ACM Computing Surveys , Nov. 2024, publisher: ACMPUB27New Y ork, NY
2024
-
[15]
LECO: Improving Ear ly Exiting via Learned Exits and Comparison-based Exiting Mec hanism,
J. Zhang, M. Tan, P . Dai, and W. Zhu, “LECO: Improving Ear ly Exiting via Learned Exits and Comparison-based Exiting Mec hanism,” in Proceedings of the 61st Annual Meeting of the Association fo r Computational Linguistics (V olume 4: Student Research W or kshop), V . Padmakumar, G. V allejo, and Y . Fu, Eds. Toronto, Canada: Association for Computational...
2023
-
[16]
BERT L oses Patience: Fast and Robust Inference with Early Exit,
W. Zhou, C. Xu, T. Ge, J. McAuley, K. Xu, and F. Wei, “BERT L oses Patience: Fast and Robust Inference with Early Exit,” in Advances in Neural Information Processing Systems , vol. 33. Curran Associates, Inc., 2020, pp. 18 330–18 341
2020
-
[17]
Distillation-Based Trainin g for Multi-Exit Architectures,
M. Phuong and C. Lampert, “Distillation-Based Trainin g for Multi-Exit Architectures,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV) . Seoul, Korea (South): IEEE, Oct. 2019, pp. 1355–1364. [Online]. Availab le: https://ieeexplore.ieee.org/document/9009834/
-
[18]
Fast BERT: a Self-distilling BERT with Adaptive Inference Time,
W. Liu, P . Zhou, Z. Wang, Z. Zhao, H. Deng, and Q. Ju, “Fast BERT: a Self-distilling BERT with Adaptive Inference Time,” in Proceedings of the 58th Annual Meeting of the Association for Computatio nal Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, A pr. 2020, pp. 6035–6044. [Onlin...
2020
-
[19]
DeeBERT: dynamic early exiting for accelerating BERT inference.arXiv preprint arXiv:2004.12993, 2020
J. Xin, R. Tang, J. Lee, Y . Y u, and J. Lin, “DeeBERT: Dynam ic Early Exiting for Accelerating BERT Inference,” Apr. 2020. [Online]. Available: https://arxiv.org/abs/2004.12993v1
-
[20]
L gvit: Dynamic early exiting for accelerating vision transformer ,
G. Xu, J. Hao, L. Shen, H. Hu, Y . Luo, H. Lin, and J. Shen, “L gvit: Dynamic early exiting for accelerating vision transformer ,” in Proceed- ings of the 31st ACM International Conference on Multimedia , 2023, pp. 9103–9114
2023
-
[21]
How to Train Y our Multi-Exi t Model? Analyzing the Impact of Training Strategies,
P . Kubaty, B. W´ ojcik, B. Krzepkowski, M. Michaluk, T. T rzci´ nski, J. Pomponi, and K. Adamczewski, “How to Train Y our Multi-Exi t Model? Analyzing the Impact of Training Strategies,” Jul. 2 024
-
[22]
Fast yet Safe: Early-Exiting w ith Risk Control,
M. Jazbec, A. Timans, T. H. V eljkovi´ c, K. Sakmann, D. Zh ang, C. A. Naesseth, and E. Nalisnick, “Fast yet Safe: Early-Exiting w ith Risk Control,” Advances in Neural Information Processing Systems , vol. 37, pp. 129 825–129 854, Dec. 2024
2024
-
[23]
F ixing overconfidence in dynamic neural networks,
L. Meronen, M. Trapp, A. Pilzer, L. Y ang, and A. Solin, “F ixing overconfidence in dynamic neural networks,” in Proceedings of the IEEE/CVF winter conference on applications of computer vis ion, 2024, pp. 2680–2690
2024
-
[24]
On bayesian upp er confidence bounds for bandit problems,
E. Kaufmann, O. Cappe, and A. Garivier, “On bayesian upp er confidence bounds for bandit problems,” in Proceedings of the Fifteenth Interna- tional Conference on Artificial Intelligence and Statistic s, ser. Proceed- ings of Machine Learning Research, N. D. Lawrence and M. Giro lami, Eds., vol. 22. La Palma, Canary Islands: PMLR, 21–23 Apr 2012 , pp. 592–600
2012
-
[25]
Finite-time Analysis of the Multiarmed Bandit Problem,
P . Auer, N. Cesa-Bianchi, and P . Fischer, “Finite-time Analysis of the Multiarmed Bandit Problem,” Machine Learning, vol. 47, no. 2, pp. 235– 256, May 2002, company: Springer Distributor: Springer Ins titution: Springer Label: Springer Publisher: Kluwer Academic Publi shers
2002
-
[26]
Bandi ts with knap- sacks,
A. Badanidiyuru, R. Kleinberg, and A. Slivkins, “Bandi ts with knap- sacks,” Journal of the ACM (JACM) , vol. 65, no. 3, pp. 1–55, 2018
2018
-
[27]
Resour ceful contextual bandits,
A. Badanidiyuru, J. Langford, and A. Slivkins, “Resour ceful contextual bandits,” in Conference on Learning Theory . PMLR, 2014, pp. 1109– 1134
2014
-
[28]
Mobilevit: Light- weight, general-purpose, and mobile-friendly vision trans- former
S. Mehta and M. Rastegari, “Mobilevit: light-weight, g eneral- purpose, and mobile-friendly vision transformer,” arXiv preprint arXiv:2110.02178, 2021
-
[29]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hinton et al. , “Learning multiple layers of features from tiny images,” 2009
2009
-
[30]
arXiv preprint arXiv:1806.00451 , year=
B. Recht, R. Roelofs, L. Schmidt, and V . Shankar, “Do cif ar-10 classi- fiers generalize to cifar-10?” 2018, https://arxiv.org/ab s/1806.00451
-
[31]
Deep residual learni ng for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learni ng for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.