Recognition: unknown
The effects of image augmentations when training machine learning models in astronomy
Pith reviewed 2026-05-07 17:31 UTC · model grok-4.3
The pith
Image augmentations generally improve neural network performance on galaxy morphology classification, but benefits decrease sharply with larger training datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We find that generally, the addition of image augmentations does improve a deep neural network's performance, however, this improvement is significantly diminished as the training dataset size increases. The choice of specific augmentations (provided they are sensible) does not seem to be as important as simply having augmentations as different augmentations result in similar increases in performances. We find that for a model of a given size, there exists a saturation point (when the model's capacity has been filled with data) that cannot be surpassed with data augmentations. We find that more complex augmentations result in longer training times and might not lead to improved performance.
What carries the argument
Retraining the Zoobot deep neural network on Galaxy Zoo DECaLS images under controlled variations in image augmentation schemes and training set sizes up to 230,000 examples, then measuring changes in classification accuracy.
If this is right
- Simpler augmentations often deliver nearly the same accuracy gains as complex ones while requiring less training time.
- Astronomers can skip or limit augmentations once their training set reaches the size that saturates the chosen model's capacity.
- Default inclusion of augmentations without checking dataset size risks wasting compute with no added accuracy.
- For a fixed model size, adding more real training images eventually outperforms any augmentation strategy.
Where Pith is reading between the lines
- The same saturation pattern may appear in other astronomical image tasks such as source detection or photometric redshift estimation.
- Researchers could test whether increasing model size in step with data volume restores the value of augmentations at larger scales.
- Survey teams might allocate effort toward acquiring more real observations instead of engineering additional augmentations once datasets exceed certain thresholds.
Load-bearing premise
The observed accuracy differences result primarily from the chosen image augmentations rather than from differences in training hyperparameters, random seeds, or limits of the particular model architecture.
What would settle it
Re-running the full set of training experiments with the same augmentation choices but with multiple random seeds and a grid of hyperparameter values to check whether the reported performance gaps stay consistent or shrink to noise levels.
Figures





read the original abstract
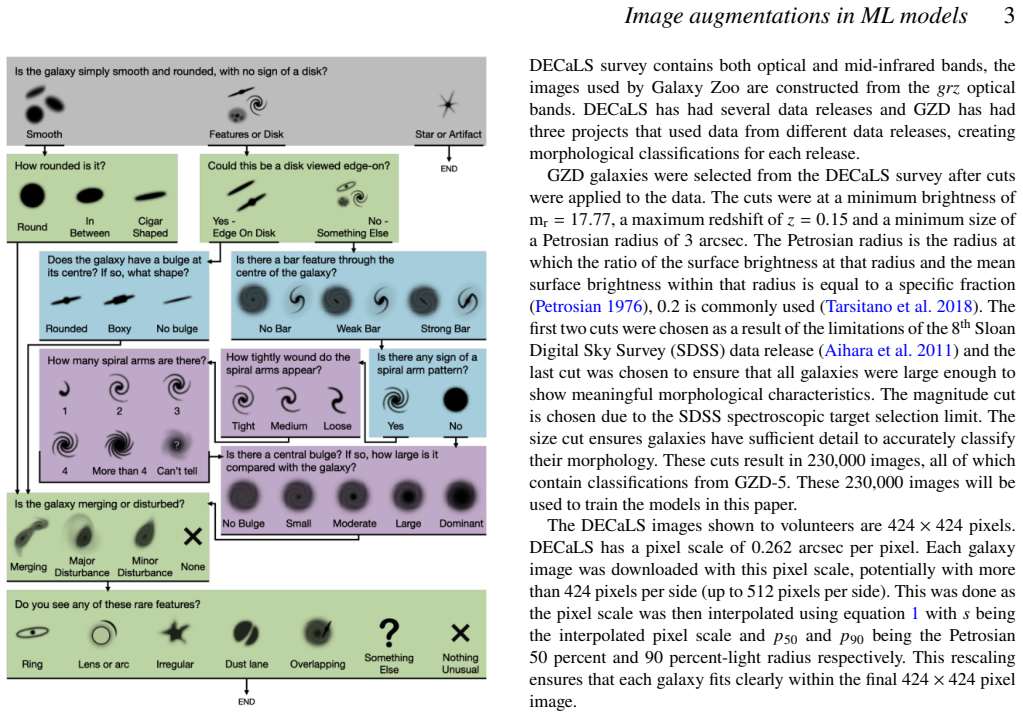
We measure the influence of image augmentations and training dataset size when training a deep neural network to classify galaxy morphology. Data augmentation is an integral step when training machine learning models and often astronomers add augmentations assuming they will always improve the performance of their models. We train multiple versions of the same pre-existing Zoobot model using different image augmentations and different dataset sizes from 230,000 galaxy images from Galaxy Zoo DECaLS to determine whether this assumption is necessarily true. We find that generally, the addition of image augmentations does improve a deep neural network's performance, however, this improvement is significantly diminished as the training dataset size increases. The choice of specific augmentations (provided they are sensible) does not seem to be as important as simply having augmentations as different augmentations result in similar increases in performances. We find that for a model of a given size, there exists a saturation point (when the model's capacity has been filled with data) that cannot be surpassed with data augmentations. We find that more complex augmentations result in longer training times and might not lead to improved performance. If augmentations are added to the training process (which is recommended), simpler augmentations might be sufficient, depending on the size of the dataset and model. We therefore encourage astronomers to carefully consider their use of image augmentations in an effort to reduce wasted time and computational resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study examining the impact of various image augmentations and training dataset sizes on the performance of the Zoobot deep neural network for galaxy morphology classification. Using subsets drawn from 230,000 DECaLS galaxy images, the authors train multiple versions of the model under different augmentation regimes and conclude that augmentations generally improve performance, but the gains diminish substantially with larger training sets; that the specific choice among sensible augmentations matters less than including any; that a model-capacity saturation point exists beyond which augmentations cannot help; and that more complex augmentations increase training time without commensurate benefits.
Significance. If the central empirical trends hold after proper statistical controls, the work supplies actionable guidance for the astronomy ML community on efficient use of augmentations, potentially reducing wasted compute when datasets are already large. The controlled design across multiple dataset sizes and augmentation types is a clear strength and directly addresses a common practical question in the field.
major comments (3)
- [Methods] Methods section: the experimental protocol does not describe repeated training runs with different random seeds or report standard deviations on any performance metric. Because the central claim is that augmentation-induced gains shrink with dataset size, the absence of these controls leaves open the possibility that the reported trends are dominated by single-run stochasticity rather than the augmentations themselves.
- [Results] Results section (and associated figures/tables): no error bars, confidence intervals, or statistical tests are provided for the accuracy or loss differences across augmentation choices and dataset sizes. Without these, it is impossible to assess whether the observed diminishing returns exceed run-to-run variance, especially at the largest dataset sizes where variance is typically smaller.
- [Discussion] Discussion: the assertion of a hard 'saturation point' determined by model capacity is stated qualitatively but is not supported by any quantitative analysis of learning curves, effective capacity metrics, or ablation of model size; this claim is load-bearing for the recommendation that augmentations become irrelevant beyond a certain data volume.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from explicit citation of prior work on augmentation strategies in astronomical image classification to better situate the novelty of the controlled dataset-size sweep.
- Figure captions and axis labels should clearly indicate which specific augmentations correspond to each curve and whether the plotted metric is accuracy, F1, or another quantity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us identify areas where the manuscript can be strengthened with additional statistical context and clarifications. We address each major comment point by point below, outlining the revisions we plan to make.
read point-by-point responses
-
Referee: [Methods] Methods section: the experimental protocol does not describe repeated training runs with different random seeds or report standard deviations on any performance metric. Because the central claim is that augmentation-induced gains shrink with dataset size, the absence of these controls leaves open the possibility that the reported trends are dominated by single-run stochasticity rather than the augmentations themselves.
Authors: We agree that repeated runs with varied random seeds would provide stronger evidence against stochastic effects. The original experiments used single training runs per configuration due to the high computational cost of retraining Zoobot across the full grid of dataset sizes and augmentations. However, the reported trends are consistent and monotonic across independent dataset sizes, which would be unlikely if dominated by random seed effects. In the revised manuscript, we will expand the Methods section to explicitly state that single runs were performed, discuss the implications for interpreting variance, and note that the diminishing-returns pattern aligns with prior scaling studies in the literature. revision: partial
-
Referee: [Results] Results section (and associated figures/tables): no error bars, confidence intervals, or statistical tests are provided for the accuracy or loss differences across augmentation choices and dataset sizes. Without these, it is impossible to assess whether the observed diminishing returns exceed run-to-run variance, especially at the largest dataset sizes where variance is typically smaller.
Authors: We acknowledge that the absence of error bars and formal statistical comparisons limits the ability to quantify whether differences exceed typical run-to-run variance. Because the study relied on single runs, we cannot retroactively compute standard deviations. We will revise the Results section and figure captions to include a clear statement of this limitation and to emphasize that the central trend (diminishing augmentation gains with increasing data volume) is observed consistently across multiple independent dataset sizes. Where feasible, we will also add a small number of repeated runs for the largest dataset sizes to provide indicative variability estimates in the revised version. revision: partial
-
Referee: [Discussion] Discussion: the assertion of a hard 'saturation point' determined by model capacity is stated qualitatively but is not supported by any quantitative analysis of learning curves, effective capacity metrics, or ablation of model size; this claim is load-bearing for the recommendation that augmentations become irrelevant beyond a certain data volume.
Authors: The saturation point is presented as an empirical observation: performance gains from augmentations plateau once dataset size is large enough that the fixed-capacity Zoobot model is effectively data-saturated. This is visible in the flattening of the accuracy curves in our figures. We will strengthen the Discussion by adding references to scaling-law literature (e.g., on model capacity and data requirements), by providing a more quantitative description of the observed learning-curve plateaus, and by clarifying that the claim is specific to the Zoobot architecture and dataset rather than a universal theoretical limit. We will also soften the language from 'hard saturation point' to 'empirically observed saturation regime' to better reflect the evidence. revision: yes
Circularity Check
No significant circularity; empirical study with direct experimental results
full rationale
This is an empirical machine-learning paper that trains variants of the Zoobot model on DECaLS galaxy images and reports observed accuracy changes under different augmentation policies and training-set sizes. No equations, fitted parameters, or derivations are present that could reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. All performance claims rest on the training runs themselves rather than on any algebraic identity or prior self-referential result, satisfying the criteria for a self-contained empirical finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aihara H., et al., 2011, The Astrophysical Journal Supplement, 193, 29 Almeida A., et al., 2023, The Astrophysical Journal Supplement Series, 267, 44 Astropy Collaboration et al., 2013, A&A, 558, A33 Astropy Collaboration et al., 2018, AJ, 156, 123 Astropy Collaboration et al., 2022, ApJ, 935, 167 Bait O., Barway S., Wadadekar Y., 2017, Monthly Notices of...
-
[2]
Smooth Or Featured
The differencebetweenthetwosetsoffiguresisthatalloftheindividual subplots in figures A1 and A2 share the sameyaxis range. allowing for easier comparison between questions. Figure A1 shows that the accuracies between questions can vary by large amounts, for instance, the ‘Has Spiral Arms’ question has accuracies over 90% while the ‘Spiral Arm Count’ questi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.