Recognition: unknown
Interactive Episodic Memory with User Feedback
Pith reviewed 2026-05-08 04:29 UTC · model grok-4.3
The pith
A plug-and-play module turns one-shot episodic memory models interactive by incorporating user feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
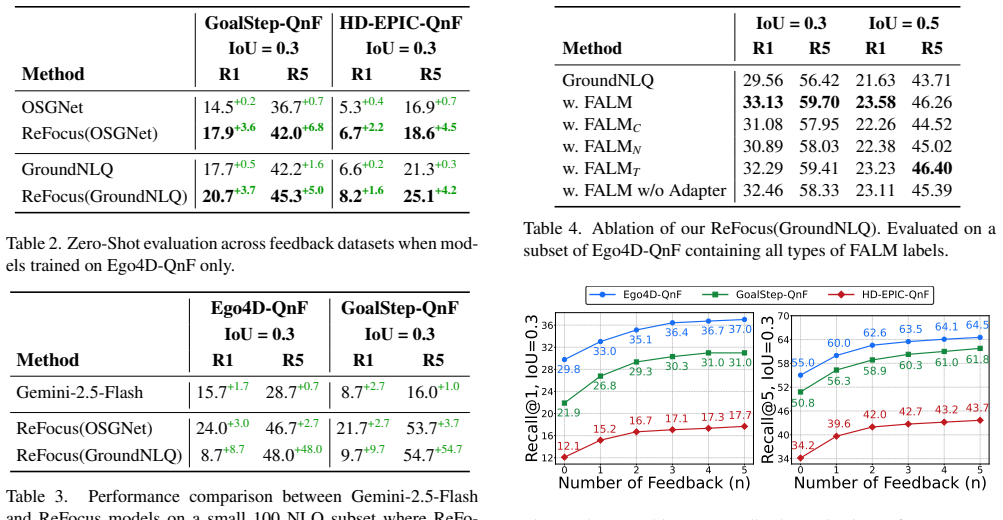
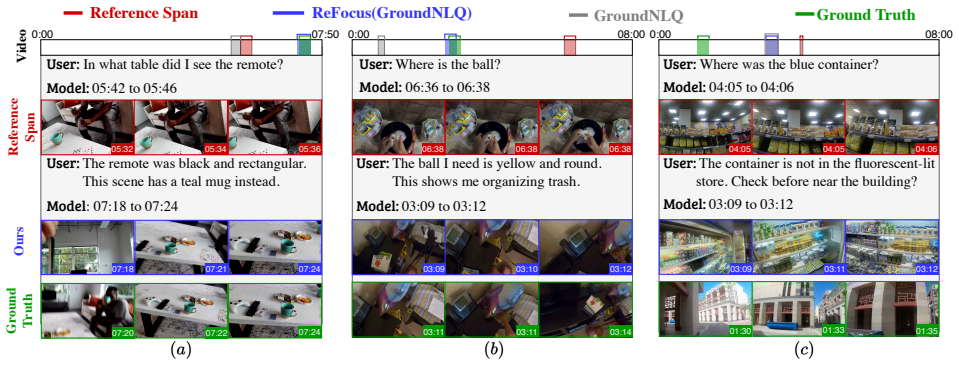
The central claim is that the Episodic Memory with Questions and Feedback task, supported by newly collected feedback datasets, allows a lightweight plug-and-play Feedback Alignment Module to let existing EM-NLQ models incorporate user corrections and additional information effectively. This is achieved through a training scheme that avoids expensive sequential optimization or per-interaction retraining, yielding significant gains over state-of-the-art one-shot approaches on three challenging benchmarks, performance that matches or exceeds commercial large vision-language models in efficiency, and strong generalization when tested with human-generated feedback in realistic scenarios.
What carries the argument
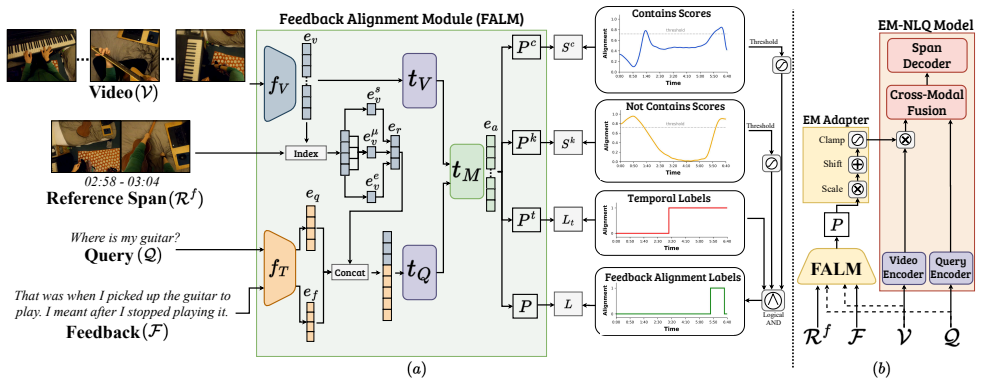
The Feedback Alignment Module (FALM), a lightweight plug-and-play component that aligns user feedback with an existing model's initial output to refine predictions for natural language queries on egocentric video.
If this is right
- Existing one-shot episodic memory models can be upgraded to handle interactive refinement without starting training over each time.
- Retrieval accuracy rises substantially on three established egocentric video benchmarks.
- The system stays efficient enough to remain competitive with or beat commercial large vision-language models.
- Performance holds when the feedback comes from real humans rather than simulated data.
- The approach directly addresses ambiguity in natural language queries by allowing iterative clarification.
Where Pith is reading between the lines
- The same lightweight alignment idea could transfer to other vision-language tasks such as interactive image search or conversational video QA.
- Widespread adoption might lower the compute barrier for building personalized, continuously adapting memory assistants.
- Multi-turn feedback loops could emerge as a natural next extension for handling complex or evolving user needs.
- The method hints that plug-and-play adaptation may reduce reliance on ever-larger pretrained models for domain-specific refinement.
Load-bearing premise
User feedback can be effectively aligned and incorporated via a lightweight plug-and-play module without requiring expensive sequential optimization or full model retraining for each interaction.
What would settle it
An experiment in which attaching the FALM to a current top EM-NLQ model produces no accuracy gain on a held-out set of human-corrected feedback queries, or where the gains require retraining the full base model from scratch.
Figures












read the original abstract
In episodic memory with natural language queries (EM-NLQ), a user may ask a question (e.g., "Where did I place the mug?") that requires searching a long egocentric video, captured from the user's perspective, to find the moment that answers it. However, queries can be ambiguous or incomplete, leading to incorrect responses. Current methods ignore this key aspect and address EM-NLQ in a one-shot setup, limiting their applicability in real-world scenarios. In this work, we address this gap and introduce the Episodic Memory with Questions and Feedback task (EM-QnF). Here, the user can provide feedback on the model's initial prediction or add more information (e.g., "Before this. I'm looking for the big blue mug not the white one"), helping the model refine its predictions interactively. To this end, we collect datasets for feedback-based interaction and propose a lightweight training scheme that avoids expensive sequential optimization. We also introduce a plug-and-play Feedback ALignment Module (FALM) that enables existing EM-NLQ models to incorporate user feedback effectively. Our approach significantly improves over the state of the art on three challenging benchmarks and is better than or competitive with commercial large vision-language models while remaining efficient. Evaluation with human-generated feedback shows that it generalizes well to real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Episodic Memory with Questions and Feedback (EM-QnF) task, extending one-shot EM-NLQ to support iterative natural-language user feedback (e.g., clarifications like 'the big blue mug') on egocentric video queries. It proposes a lightweight training scheme that avoids expensive sequential optimization and a plug-and-play Feedback Alignment Module (FALM) that can be added to existing EM-NLQ models. The central claims are significant improvements over the state of the art on three benchmarks, competitiveness with commercial large vision-language models, and effective generalization when evaluated with human-generated feedback.
Significance. If the performance and efficiency claims hold, the work would advance practical interactive systems for personal memory retrieval by enabling natural, iterative refinement without full model retraining. The modular, lightweight design addresses a key deployment barrier in real-world assistive vision-language applications.
major comments (2)
- [Abstract and experimental results section] Abstract and experimental results section: The manuscript asserts 'significant improvements over the state of the art' and 'better than or competitive with commercial large vision-language models' but supplies no details on baselines, data splits, error bars, training procedures, or the identity of the three benchmarks. This absence prevents verification of the central performance claims.
- [Method section describing FALM and training scheme] Method section describing FALM and training scheme: The description does not demonstrate that the module and training operate without any per-interaction optimization or hidden fine-tuning. Because the efficiency and 'plug-and-play' advantages rest on this property, explicit ablations or measurements confirming zero per-query cost are required to support the claim that the approach avoids 'expensive sequential optimization'.
minor comments (2)
- [Abstract] The abstract should name the three benchmarks explicitly instead of referring to them generically.
- [Method] A figure or pseudocode illustrating the FALM integration and feedback loop would improve clarity of the proposed architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major comments below and plan revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: The manuscript asserts 'significant improvements over the state of the art' and 'better than or competitive with commercial large vision-language models' but supplies no details on baselines, data splits, error bars, training procedures, or the identity of the three benchmarks. This absence prevents verification of the central performance claims.
Authors: We agree with the referee that the abstract is high-level and that the experimental results section would benefit from a clearer summary of the experimental setup. In the revised version, we will modify the abstract to include the names of the three benchmarks and add explicit details at the beginning of the experimental results section regarding the baselines, data splits, error bars, and training procedures to facilitate verification of the performance claims. revision: yes
-
Referee: [Method section describing FALM and training scheme] Method section describing FALM and training scheme: The description does not demonstrate that the module and training operate without any per-interaction optimization or hidden fine-tuning. Because the efficiency and 'plug-and-play' advantages rest on this property, explicit ablations or measurements confirming zero per-query cost are required to support the claim that the approach avoids 'expensive sequential optimization'.
Authors: We appreciate this point. Our lightweight training scheme is performed once upfront, and the FALM module is plug-and-play without requiring per-interaction optimization or fine-tuning. To better demonstrate this, we will include in the revised method section explicit ablations comparing our approach to sequential optimization methods and measurements of per-query inference costs to confirm they remain zero beyond the initial setup. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines a new task (EM-QnF), collects dedicated datasets, introduces an additive plug-and-play FALM module, and reports empirical gains on three benchmarks plus human feedback. No equations or claims reduce a prediction to a fitted input by construction, no self-citation is load-bearing for the core result, and the lightweight-training claim is presented as an empirical engineering choice rather than a derived necessity. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing EM-NLQ models can be extended with user feedback via a plug-and-play alignment module without full retraining.
invented entities (1)
-
Feedback Alignment Module (FALM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Shimin Chen, Xiaohan Lan, Yitian Yuan, Zequn Jie, and Lin Ma. Timemarker: A versatile video-llm for long and short video understanding with superior temporal localiza- tion ability.arXiv preprint arXiv:2411.18211, 2024
-
[3]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[4]
Temporal sentence grounding with relevance feedback in videos.Advances in Neural Information Processing Systems, 37:43107–43132, 2024
Jianfeng Dong, Xiaoman Peng, Daizong Liu, Xiaoye Qu, Xun Yang, Cuizhu Bao, and Meng Wang. Temporal sentence grounding with relevance feedback in videos.Advances in Neural Information Processing Systems, 37:43107–43132, 2024
2024
-
[5]
Object-shot enhanced grounding network for egocentric video
Yisen Feng, Haoyu Zhang, Meng Liu, Weili Guan, and Liqiang Nie. Object-shot enhanced grounding network for egocentric video. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24190–24200, 2025
2025
-
[6]
Saliency-guided detr for mo- ment retrieval and highlight detection
Aleksandr Gordeev, Vladimir Dokholyan, Irina Tolstykh, and Maksim Kuprashevich. Saliency-guided detr for mo- ment retrieval and highlight detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 907–916, 2026
2026
-
[7]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022
2022
-
[8]
Dialog-based interactive image retrieval.Advances in neural information processing sys- tems, 31, 2018
Xiaoxiao Guo, Hui Wu, Yu Cheng, Steven Rennie, Gerald Tesauro, and Rogerio Feris. Dialog-based interactive image retrieval.Advances in neural information processing sys- tems, 31, 2018
2018
-
[9]
Where are you? lo- calization from embodied dialog
Meera Hahn, Jacob Krantz, Dhruv Batra, Devi Parikh, James Rehg, Stefan Lee, and Peter Anderson. Where are you? lo- calization from embodied dialog. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP), pages 806–822, 2020
2020
-
[10]
Rgnet: A unified clip retrieval and ground- ing network for long videos
Tanveer Hannan, Md Mohaiminul Islam, Thomas Seidl, and Gedas Bertasius. Rgnet: A unified clip retrieval and ground- ing network for long videos. InEuropean Conference on Computer Vision, pages 352–369. Springer, 2024
2024
-
[11]
Groundnlq@ ego4d natural language queries challenge 2023.arXiv preprint arXiv:2306.15255, 2023
Zhijian Hou, Lei Ji, Difei Gao, Wanjun Zhong, Kun Yan, Chao Li, Wing-Kwong Chan, Chong-Wah Ngo, Nan Duan, and Mike Zheng Shou. Groundnlq@ ego4d natural language queries challenge 2023.arXiv preprint arXiv:2306.15255, 2023
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[13]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024
2024
-
[14]
Lita: Language instructed temporal-localization assistant
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. In European Conference on Computer Vision, pages 202–218. Springer, 2024
2024
-
[15]
Chatting makes perfect: Chat-based image retrieval
Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischin- ski. Chatting makes perfect: Chat-based image retrieval. Advances in Neural Information Processing Systems, 36: 61437–61449, 2023
2023
-
[16]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[17]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023
2023
-
[18]
VLFeedback: A large-scale AI feedback dataset for large vision-language models alignment
Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, Lingpeng Kong, and Qi Liu. VLFeedback: A large-scale AI feedback dataset for large vision-language models alignment. InProceed- ings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 6227–6246, Miami, Florida, USA, 2024. Associa...
2024
-
[19]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Universal video temporal grounding with generative multi-modal large language mod- els
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, and Weidi Xie. Universal video temporal grounding with generative multi-modal large language mod- els. InAdvances in Neural Information Processing Systems, 2025
2025
-
[21]
Egocentric video-language pretraining.Advances in Neural Information Processing Sys- tems, 35:7575–7586, 2022
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z Xu, Difei Gao, Rong-Cheng Tu, Wen- zhe Zhao, Weijie Kong, et al. Egocentric video-language pretraining.Advances in Neural Information Processing Sys- tems, 35:7575–7586, 2022
2022
-
[22]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[23]
Decafnet: Delegate and conquer for efficient temporal grounding in long videos
Zijia Lu, ASM Iftekhar, Gaurav Mittal, Tianjian Meng, Xi- awei Wang, Cheng Zhao, Rohith Kukkala, Ehsan Elhamifar, and Mei Chen. Decafnet: Delegate and conquer for efficient temporal grounding in long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24066–24076, 2025
2025
-
[24]
Llavilo: Boosting video moment retrieval via adapter-based multimodal modeling
Kaijing Ma, Xianghao Zang, Zerun Feng, Han Fang, Chao Ban, Yuhan Wei, Zhongjiang He, Yongxiang Li, and Hao Sun. Llavilo: Boosting video moment retrieval via adapter-based multimodal modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2798–2803, 2023
2023
-
[25]
Self-refine: It- erative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hal- linan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: It- erative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023
2023
-
[26]
Interactive video retrieval with dialog
Sho Maeoki, Kohei Uehara, and Tatsuya Harada. Interactive video retrieval with dialog. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 952–953, 2020
2020
-
[27]
Snag: Scal- able and accurate video grounding
Fangzhou Mu, Sicheng Mo, and Yin Li. Snag: Scal- able and accurate video grounding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18930–18940, 2024
2024
-
[28]
Baoqi Pei, Guo Chen, Jilan Xu, Yuping He, Yicheng Liu, Kanghua Pan, Yifei Huang, Yali Wang, Tong Lu, Limin Wang, et al. Egovideo: Exploring egocentric founda- tion model and downstream adaptation.arXiv preprint arXiv:2406.18070, 2024
-
[29]
Hd-epic: A highly-detailed egocentric video dataset
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Kumar Parida, Kaiting Liu, Pra- jwal Gatti, Siddhant Bansal, Kevin Flanagan, et al. Hd-epic: A highly-detailed egocentric video dataset. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23901–23913, 2025
2025
-
[30]
Chatvtg: Video temporal grounding via chat with video dialogue large language models
Mengxue Qu, Xiaodong Chen, Wu Liu, Alicia Li, and Yao Zhao. Chatvtg: Video temporal grounding via chat with video dialogue large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1847–1856, 2024
2024
-
[31]
Naq: Leveraging narrations as queries to su- pervise episodic memory
Santhosh Kumar Ramakrishnan, Ziad Al-Halah, and Kris- ten Grauman. Naq: Leveraging narrations as queries to su- pervise episodic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6694–6703, 2023
2023
-
[32]
Spotem: Efficient video search for episodic memory
Santhosh Kumar Ramakrishnan, Ziad Al-Halah, and Kris- ten Grauman. Spotem: Efficient video search for episodic memory. InInternational Conference on Machine Learning, pages 28618–28636. PMLR, 2023
2023
-
[33]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024
2024
-
[34]
Ego4d goal-step: Toward hierarchical understanding of procedural activities
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Torresani. Ego4d goal-step: Toward hierarchical understanding of procedural activities. Advances in Neural Information Processing Systems, 36: 38863–38886, 2023
2023
-
[35]
Qwq-32b: Embracing the power of reinforce- ment learning, 2025
Qwen Team. Qwq-32b: Embracing the power of reinforce- ment learning, 2025
2025
-
[36]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[37]
Vision-and-dialog navigation
Jesse Thomason, Michael Murray, Maya Cakmak, and Luke Zettlemoyer. Vision-and-dialog navigation. InConference on Robot Learning, pages 394–406. PMLR, 2020
2020
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review arXiv 2023
-
[39]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
Focused and collaborative feedback integration for interactive image seg- mentation
Qiaoqiao Wei, Hui Zhang, and Jun-Hai Yong. Focused and collaborative feedback integration for interactive image seg- mentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18643– 18652, 2023
2023
-
[41]
Fashion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11307– 11317, 2021
2021
-
[42]
Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033, 2023
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033, 2023
2023
-
[43]
Self-chained image-language model for video localization and question answering.Advances in Neural Information Processing Systems, 36:76749–76771, 2023
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering.Advances in Neural Information Processing Systems, 36:76749–76771, 2023
2023
-
[44]
Span-based localizing network for natural language video lo- calization
Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. Span-based localizing network for natural language video lo- calization. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 6543–6554, 2020
2020
-
[45]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pages 543–553, 2023
2023
-
[46]
Learning 2d temporal adjacent networks for moment local- ization with natural language
Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. Learning 2d temporal adjacent networks for moment local- ization with natural language. InProceedings of the AAAI conference on artificial intelligence, pages 12870–12877, 2020
2020
-
[47]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review arXiv 1909
-
[48]
Detrs with col- laborative hybrid assignments training
Zhuofan Zong, Guanglu Song, and Yu Liu. Detrs with col- laborative hybrid assignments training. InProceedings of the IEEE/CVF international conference on computer vision, pages 6748–6758, 2023
2023
-
[49]
What oil did I add to the pasta in the pot?
Supplementary Material In this supplementary material, we provide further informa- tion about dataset generation, model evaluation, and limi- tations of our work. All code and datasets can be found on our project page:https://nsubedi11.github. io/refocus. The supplementary material is sectioned as follows: • Sec 6.1: Supplementary Video with qualitative r...
1913
-
[50]
The query is primarily asking for action of placing some object inside location X
Do not Answer the Query Directly. The query is primarily asking for action of placing some object inside location X. Do not provide any information about the object that was placed in the given location
-
[51]
Feedback should be either questions or first person focused statements unless the query focuses on someone else
Give Feedback as if You are Asking the Query. Feedback should be either questions or first person focused statements unless the query focuses on someone else. You should give feedback as if you are the person who is asking the query and is looking for the correct video clip
-
[52]
Attributes of the Given Location. Since the query is asking for what kind of object was placed in given location X, you can provide any information about the given location, from its attribute to its surrounding objects
-
[53]
Use memorable contrastive information about object or action that are present/absent in the incorrect video clip but absent/present in correct video clip or the query
Contrast between the Video Clips. Use memorable contrastive information about object or action that are present/absent in the incorrect video clip but absent/present in correct video clip or the query
-
[54]
feedback
Relative Time. You can use the relative time of the video clips to provide time related feedback but do not be too specific. ... Now, I will provide some examples of good and bad feedback for given query and the video descriptions. [IN-CONTEXT EXAMPLES] [RESPONSE SPAN DESCRIPTION] [RESPONSE SPAN EXPLANATION] [REFERENCE SPAN DESCRIPTION] Query: What oil di...
-
[55]
Some information related to the query action or object to be searched
-
[56]
Some information that should not be searched for
-
[57]
contains
Temporal information regarding where the query action/object is located in the video timeline (either before or after or null if not specified) Your job is to extract these 3 potential types of information from the feedback. Some feedback may not have all 3 types of information. Here are some examples to help you understand the task: [IN-CONTEXT EXAMPLES]...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.