Recognition: unknown
Agentic AI for Remote Sensing: Technical Challenges and Research Directions
Pith reviewed 2026-05-14 20:52 UTC · model grok-4.3
The pith
Earth Observation workflows impose structural challenges on generic agentic AI, necessitating new design principles for geospatial agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
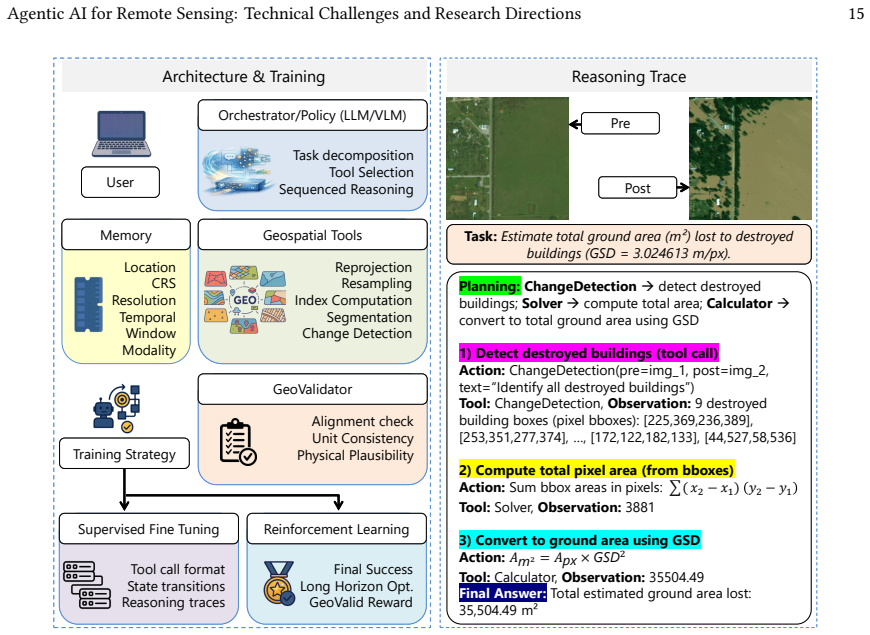
The paper claims that the challenges in applying agentic AI to Earth Observation are structural, arising from the georeferenced, temporally structured, and physically constrained nature of EO data and workflows. Operations such as resampling and aggregation transform the underlying state, making errors propagate across steps in ways that generic systems do not handle. Therefore, EO-native agents must be designed with structured geospatial state, tool-aware reasoning, verifier-guided execution, and validity-aware learning to ensure correctness.
What carries the argument
EO-native agent design principles centered on structured geospatial state, tool-aware reasoning that respects data transformations, verifier-guided execution for consistency checks, and validity-aware learning and evaluation.
If this is right
- Multi-step EO pipelines require explicit tracking of how operations transform geospatial properties to avoid undetected inconsistencies.
- Verification must extend beyond logical coherence to include physical validity and temporal consistency across workflow steps.
- Agent evaluation in EO settings needs metrics that capture geospatial accuracy and error propagation in addition to task completion.
- New agent architectures tailored to physical and geospatial constraints will be essential rather than adaptations of general frameworks.
- Reliable long-horizon reasoning becomes possible for applications such as data compositing and change detection once these principles are adopted.
Where Pith is reading between the lines
- The same structural mismatch between generic agents and domain-specific state transformations may appear in other fields that involve coordinate systems or physical simulations.
- Embedding domain verifiers as core components could become standard practice for agentic systems in scientific data analysis.
- Empirical tests on public EO benchmark datasets could quantify how much the proposed design principles reduce silent failure rates compared with unmodified agents.
Load-bearing premise
That the identified failure modes and constraints in EO workflows cannot be adequately addressed through incremental extensions of existing generic agentic AI frameworks and instead require fundamentally new design principles.
What would settle it
A demonstration that a generic agentic system can complete a complex multi-step EO workflow such as time-series change detection involving reprojection, resampling, and aggregation while preserving physical validity and geospatial consistency without custom EO-specific modules.
Figures






read the original abstract
Earth Observation (EO) is moving beyond static prediction toward multi-step analytical workflows that require coordinated reasoning over data, tools, and geospatial state. While foundation models and vision-language models have advanced representation learning and language-grounded interaction in remote sensing, and agentic AI has shown strong potential for long-horizon reasoning and tool use, EO is not a straightforward extension of generic agentic AI. EO workflows operate on georeferenced, multi-modal, and temporally structured data, where operations such as reprojection, resampling, compositing, and aggregation transform the underlying state and can constrain later analysis. As a result, errors may propagate silently across steps, and correctness depends not only on internal coherence but also on geospatial consistency, temporally valid comparisons, and physical validity. This position paper argues that these challenges are structural rather than incidental. We examine the assumptions commonly made in generic agentic systems, analyze how they break in geospatial workflows, and characterize failure modes in multi-step EO pipelines. We then outline design principles for EO-native agents centered on structured geospatial state, tool-aware reasoning, verifier-guided execution, and validity-aware learning and evaluation. Building reliable geospatial agents, therefore, requires rethinking agent design around the physical, geospatial, and workflow constraints that govern EO analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper claims that Earth Observation (EO) workflows introduce structural challenges for generic agentic AI systems because operations like reprojection, resampling, compositing, and aggregation transform geospatial state and can cause silent error propagation, requiring not only internal coherence but also geospatial and physical validity. It examines breakdowns of standard agent assumptions in multi-step EO pipelines and outlines four design principles for EO-native agents: structured geospatial state, tool-aware reasoning, verifier-guided execution, and validity-aware learning and evaluation.
Significance. If the structural nature of the challenges and the necessity of the proposed principles hold, the paper could meaningfully guide research at the intersection of agentic AI and remote sensing by highlighting domain-specific constraints that generic frameworks may not address through simple extensions. As a position paper it contributes by framing failure modes and research directions rather than presenting new empirical results.
major comments (2)
- [§3] §3 (failure modes in multi-step EO pipelines): the central assertion that the identified challenges are structural and cannot be adequately addressed by incremental extensions to generic agentic frameworks (e.g., adding georeferenced state graphs or precondition checkers) is not supported by a concrete counter-example or case where such an augmentation still produces unrecoverable geospatial inconsistency or silent error propagation.
- [§4] §4 (design principles): the four proposed principles are described at a high conceptual level without formal definitions, pseudocode, or a worked example showing how 'structured geospatial state' or 'verifier-guided execution' would be realized in an agent architecture and would demonstrably mitigate the failure modes from §3.
minor comments (2)
- [Abstract and §4] The abstract and §4 refer to 'validity-aware learning and evaluation' but the text provides no detail on the learning mechanism, loss functions, or evaluation protocol that would implement this principle.
- [§2] A small number of citations to recent agentic AI surveys or EO workflow papers could be added to strengthen the grounding of the assumptions examined in §2.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. As a position paper, our goal is to frame structural challenges and research directions rather than provide empirical benchmarks. We address the major comments below and will revise the manuscript to incorporate concrete illustrations and more formal elements where feasible.
read point-by-point responses
-
Referee: [§3] §3 (failure modes in multi-step EO pipelines): the central assertion that the identified challenges are structural and cannot be adequately addressed by incremental extensions to generic agentic frameworks (e.g., adding georeferenced state graphs or precondition checkers) is not supported by a concrete counter-example or case where such an augmentation still produces unrecoverable geospatial inconsistency or silent error propagation.
Authors: We agree that a concrete counter-example would make the structural claim more compelling. Section 3 analyzes how operations such as reprojection, resampling, and aggregation transform geospatial state and enable silent error propagation, but does not include an end-to-end case demonstrating failure of incremental extensions. In the revision we will add a worked illustrative pipeline (e.g., temporal compositing followed by change detection) showing that simply augmenting an agent with georeferenced state graphs and precondition checkers still permits unrecoverable inconsistency when physical validity constraints are not explicitly enforced. revision: yes
-
Referee: [§4] §4 (design principles): the four proposed principles are described at a high conceptual level without formal definitions, pseudocode, or a worked example showing how 'structured geospatial state' or 'verifier-guided execution' would be realized in an agent architecture and would demonstrably mitigate the failure modes from §3.
Authors: The principles are presented at a conceptual level because the paper is a position piece outlining research directions rather than an architectural specification. We acknowledge that formal definitions, pseudocode, and a mitigation example would improve clarity. In the revision we will introduce concise formal definitions for each principle, provide pseudocode for the structured geospatial state representation and verifier-guided execution loop, and include a worked example that directly maps back to the failure modes in §3 to illustrate mitigation. revision: yes
Circularity Check
Position paper identifies EO-specific agentic challenges without circular derivation
full rationale
The paper is a conceptual position piece that examines standard assumptions in generic agentic systems (stateless tool calls, internal coherence only) and describes how they break under EO operations such as reprojection and temporal compositing. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The claim that challenges are structural and require new design principles is advanced by direct analysis of workflow constraints rather than by reducing to a prior self-citation or definitional loop. The absence of any load-bearing self-referential step keeps the derivation self-contained against external benchmarks of agent limitations and geospatial data properties.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption EO workflows operate on georeferenced, multi-modal, and temporally structured data where operations such as reprojection and compositing transform the underlying state and constrain later analysis
- domain assumption Errors may propagate silently across steps in multi-step EO pipelines, with correctness depending on geospatial consistency and physical validity
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. 2024. Omnisat: Self-supervised modality fusion for earth observation. In European Conference on Computer Vision . Springer, 409–427
work page 2024
-
[3]
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. 2025. AnySat: One Earth Observation Model for Many Resolutions, Scales, and Modalities. In Proceedings of the Computer Vision and Pattern Recognition Conference . 19530–19540
work page 2025
-
[4]
Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. 2017. Segnet: A deep convolutional encoder-decoder architecture for image segmenta- tion. IEEE transactions on pattern analysis and machine intelligence 39, 12 (2017), 2481–2495
work page 2017
-
[5]
Wele Gedara Chaminda Bandara and Vishal M Patel. 2022. A transformer-based siamese network for change detection. In IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium . IEEE, 207–210
work page 2022
- [6]
-
[7]
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kembhavi. 2023. Satlaspretrain: A large-scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 16772–16782
work page 2023
-
[8]
Yakoub Bazi, Laila Bashmal, Mohamad Mahmoud Al Rahhal, Riccardo Ricci, and Farid Melgani. 2024. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery. Remote Sensing 16, 9 (2024), 1477
work page 2024
-
[9]
Nikolaos Ioannis Bountos, Arthur Ouaknine, Ioannis Papoutsis, and David Rolnick. 2025. Fomo: Multi-modal, multi-scale and multi-task remote sensing foundation models for forest monitoring. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 39. 27858–27868
work page 2025
-
[10]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. 2025. Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data. arXiv preprint arXiv:2507.22291 (2025)
-
[11]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision . 9650–9660. 26 Munir et al
work page 2021
- [12]
-
[13]
Hao Chen, Zipeng Qi, and Zhenwei Shi. 2021. Remote sensing image change detection with transformers. IEEE Transactions on Geoscience and Remote Sensing 60 (2021), 1–14
work page 2021
-
[14]
Hongruixuan Chen, Chen Wu, Bo Du, Liangpei Zhang, and Le Wang. 2019. Change detection in multisource VHR images via deep Siamese convolutional multiple-layers recurrent neural network. IEEE Transactions on Geoscience and Remote Sensing 58, 4 (2019), 2848–2864
work page 2019
-
[15]
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. 2018. Encoder-Decoder with Atrous Separable Convo- lution for Semantic Image Segmentation. In Computer Vision – ECCV 2018 . Lecture Notes in Computer Science, Vol. 11211. Springer, 833–851
work page 2018
- [16]
- [17]
-
[18]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. arXiv preprint arXiv:2312.14238 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Gong Cheng, Junwei Han, Peicheng Zhou, and Lei Guo. 2014. Multi-class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS Journal of Photogrammetry and Remote Sensing 98 (2014), 119–132
work page 2014
-
[20]
Guangliang Cheng, Yunmeng Huang, Xiangtai Li, Shuchang Lyu, Zhaoyang Xu, Hongbo Zhao, Qi Zhao, and Shiming Xiang. 2024. Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sensing 16, 13 (2024), 2355
work page 2024
-
[21]
Gong Cheng, Peicheng Zhou, and Junwei Han. 2016. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE transactions on geoscience and remote sensing 54, 12 (2016), 7405–7415
work page 2016
-
[22]
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. 2018. Functional map of the world. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . 6172–6180
work page 2018
-
[23]
Meng Chu, Zhedong Zheng, Wei Ji, Tingyu Wang, and Tat-Seng Chua. 2024. Towards natural language-guided drones: GeoText-1652 benchmark with spatial relation matching. In European Conference on Computer Vision . Springer, 213–231
work page 2024
-
[24]
Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Begüm Demir, and Volker Markl. 2025. reben: Refined bigearthnet dataset for remote sensing image analysis. In IGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium . IEEE, 1264–1268
work page 2025
-
[25]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. 2022. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery. Advances in Neural Information Processing Systems 35 (2022), 197–211
work page 2022
-
[26]
Muhammad Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Kartik Kuckreja, Fahad Shahbaz Khan, Paolo Fraccaro, Alexandre Lacoste, and Salman Khan. 2025. Geobench-vlm: Benchmarking vision-language models for geospatial tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 7132–7142
work page 2025
-
[27]
Muhammad Sohail Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Muhammad Haris Khan, Rao Muhammad Anwer, Jorma Laak- sonen, Fahad Shahbaz Khan, and Salman Khan. 2025. TerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation. arXiv preprint arXiv:2506.06281 (2025)
-
[28]
Jian Ding, Nan Xue, Yang Long, Gui-Song Xia, and Qikai Lu. 2019. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 2849–2858
work page 2019
- [29]
-
[30]
European Union and European Space Agency. 2026. Sentinel Online - Explore Copernicus satellite missions. https://sentinels.copernicus.eu/
work page 2026
-
[31]
Jie Feng, Shengyuan Wang, Tianhui Liu, Yanxin Xi, and Yong Li. 2025. UrbanLLaV A: A Multi-modal Large Language Model for Urban Intelligence. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 6209–6219
work page 2025
-
[32]
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, et al. 2025. Onethinker: All-in-one reasoning model for image and video. arXiv preprint arXiv:2512.03043 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
Zhengpeng Feng, Clement Atzberger, Sadiq Jaffer, Jovana Knezevic, Silja Sormunen, Robin Young, Madeline C Lisaius, Markus Immitzer, Toby Jackson, James Ball, et al. 2025. Tessera: Temporal embeddings of surface spectra for earth representation and analysis. arXiv preprint arXiv:2506.20380 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Alistair Francis and Mikolaj Czerkawski. 2024. Major tom: Expandable datasets for earth observation. In IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium . IEEE, 2935–2940
work page 2024
-
[36]
Yingchun Fu, Zhe Zhu, Liangyun Liu, Wenfeng Zhan, Tao He, Huanfeng Shen, Jun Zhao, Yongxue Liu, Hongsheng Zhang, Zihan Liu, et al. 2024. Remote sensing time series analysis: A review of data and applications. Journal of Remote Sensing 4 (2024), 0285
work page 2024
-
[37]
Anthony Fuller, Koreen Millard, and James Green. 2023. CROMA: Remote sensing representations with contrastive radar-optical masked autoen- coders. Advances in Neural Information Processing Systems 36 (2023), 5506–5538. Agentic AI for Remote Sensing: Technical Challenges and Research Directions 27
work page 2023
-
[38]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, et al. 2024. Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 27672–27683
work page 2024
- [39]
-
[40]
Boran Han, Shuai Zhang, Xingjian Shi, and Markus Reichstein. 2024. Bridging remote sensors with multisensor geospatial foundation models. In Proceedings of the ieee/cvf conference on computer vision and pattern recognition . 27852–27862
work page 2024
-
[41]
Jiaming Han, Jian Ding, Jie Li, and Gui-Song Xia. 2021. Align deep features for oriented object detection. IEEE transactions on geoscience and remote sensing 60 (2021), 1–11
work page 2021
- [42]
-
[43]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 16000–16009
work page 2022
- [44]
-
[45]
Danfeng Hong, Bing Zhang, Xuyang Li, Yuxuan Li, Chenyu Li, Jing Yao, Naoto Yokoya, Hao Li, Pedram Ghamisi, Xiuping Jia, et al. 2024. Spec- tralGPT: Spectral remote sensing foundation model. IEEE transactions on pattern analysis and machine intelligence 46, 8 (2024), 5227–5244
work page 2024
-
[46]
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. 2025. Rsgpt: A remote sensing vision language model and benchmark. ISPRS Journal of Photogrammetry and Remote Sensing 224 (2025), 272–286
work page 2025
-
[47]
Yangyu Huang, Tianyi Gao, Haoran Xu, Qihao Zhao, Yang Song, Zhipeng Gui, Tengchao Lv, Hao Chen, Lei Cui, Scarlett Li, et al. 2025. Peace: Empowering geologic map holistic understanding with mllms. In Proceedings of the Computer Vision and Pattern Recognition Conference . 3899– 3908
work page 2025
-
[48]
Jeremy Andrew Irvin, Emily Ruoyu Liu, Joyce C Chen, Ines Dormoy, Jinyoung Kim, Samar Khanna, Zhuo Zheng, and Stefano Ermon. [n. d.]. TEOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data. In The Thirteenth International Conference on Learning Rep- resentations
-
[49]
Pallavi Jain, Bianca Schoen-Phelan, and Robert Ross. 2022. Self-supervised learning for invariant representations from multi-spectral and SAR images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 15 (2022), 7797–7808
work page 2022
-
[50]
Johannes Jakubik, Felix Yang, Benedikt Blumenstiel, Erik Scheurer, Rocco Sedona, Stefano Maurogiovanni, Jente Bosmans, Nikolaos Dionelis, Valerio Marsocci, Niklas Kopp, et al. 2025. Terramind: Large-scale generative multimodality for earth observation. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 7383–7394
work page 2025
- [51]
- [52]
- [53]
-
[54]
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. 2024. Geochat: Grounded large vision-language model for remote sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 27831– 27840
work page 2024
-
[55]
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan David Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Andrew Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, Mehmet Gunturkun, Gabriel Huang, David Vazquez, Dava Newman, Yoshua Bengio, Stefano Ermon, and Xiao Xiang Zhu. 2023. GEO-Bench: Toward Foundation Models for Earth Monitoring. arXiv preprint ...
-
[56]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava- onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning . PMLR, 19730–19742
work page 2023
-
[58]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. 2020. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS journal of photogrammetry and remote sensing 159 (2020), 296–307
work page 2020
-
[59]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. 2020. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark. ISPRS Journal of Photogrammetry and Remote Sensing 159 (2020), 296–307
work page 2020
- [60]
-
[61]
Xuyang Li, Danfeng Hong, and Jocelyn Chanussot. 2024. S2mae: A spatial-spectral pretraining foundation model for spectral remote sensing data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 24088–24097
work page 2024
-
[62]
Xuyang Li, Chenyu Li, Pedram Ghamisi, Danfeng Hong, Jon Atli Benediktsson, and Jocelyn Chanussot. 2026. Fleximo: A flexible remote sensing foundation model. IEEE Transactions on Geoscience and Remote Sensing (2026). 28 Munir et al
work page 2026
-
[63]
Zhihao Li, Biao Hou, Siteng Ma, Zitong Wu, Xianpeng Guo, Bo Ren, and Licheng Jiao. 2024. Masked angle-aware autoencoder for remote sensing images. In European Conference on Computer Vision . Springer, 260–278
work page 2024
-
[64]
Zhenshi Li, Dilxat Muhtar, Feng Gu, Yanglangxing He, Xueliang Zhang, Pengfeng Xiao, Guangjun He, and Xiaoxiang Zhu. 2025. Lhrs-bot-nova: Improved multimodal large language model for remote sensing vision-language interpretation. ISPRS Journal of Photogrammetry and Remote Sensing 227 (2025), 539–550
work page 2025
-
[65]
Chenyang Liu, Keyan Chen, Haotian Zhang, Zipeng Qi, Zhengxia Zou, and Zhenwei Shi. 2024. Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis. IEEE Transactions on Geoscience and Remote Sensing 62 (2024), 1–16
work page 2024
-
[66]
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. 2024. Remoteclip: A vision language foundation model for remote sensing. IEEE Transactions on Geoscience and Remote Sensing 62 (2024), 1–16
work page 2024
- [67]
-
[68]
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Jiayi Ji, Xiaoshuai Sun, and Rongrong Ji. 2024. Rotated multi-scale interaction network for referring remote sensing image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26658–26668
work page 2024
- [69]
-
[70]
Meng Lu, Ran Xu, Yi Fang, Wenxuan Zhang, Yue Yu, Gaurav Srivastava, Yuchen Zhuang, Mohamed Elhoseiny, Charles Fleming, Carl Yang, et al
-
[71]
arXiv preprint arXiv:2511.19773 (2025)
Scaling Agentic Reinforcement Learning for Tool-Integrated Reasoning in VLMs. arXiv preprint arXiv:2511.19773 (2025)
-
[72]
Pan Lu, Bowen Chen, Sheng Liu, Rahul Thapa, Joseph Boen, and James Zou. 2025. Octotools: An agentic framework with extensible tools for complex reasoning. arXiv preprint arXiv:2502.11271 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Xiaoqiang Lu, Binqiang Wang, Xiangtao Zheng, and Xuelong Li. 2017. Exploring Models and Data for Remote Sensing Image Caption Generation. arXiv preprint arXiv:1712.07835 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
Junwei Luo, Zhen Pang, Yongjun Zhang, Tingzhu Wang, Linlin Wang, Bo Dang, Jiangwei Lao, Jian Wang, Jingdong Chen, Yihua Tan, et al
-
[75]
Skysensegpt: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding. arXiv preprint arXiv:2406.10100 (2024)
-
[76]
Junwei Luo, Yingying Zhang, Xue Yang, Kang Wu, Qi Zhu, Lei Liang, Jingdong Chen, and Yansheng Li. 2025. When large vision-language model meets large remote sensing imagery: Coarse-to-fine text-guided token pruning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9206–9217
work page 2025
-
[77]
Lei Ma, Yu Liu, Xueliang Zhang, Yuanxin Ye, Gaofei Yin, and Brian Alan Johnson. 2019. Deep learning in remote sensing applications: A meta- analysis and review. ISPRS journal of photogrammetry and remote sensing 152 (2019), 166–177
work page 2019
- [78]
-
[79]
Oscar Manas, Alexandre Lacoste, Xavier Giró-i Nieto, David Vazquez, and Pau Rodriguez. 2021. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the IEEE/CVF international conference on computer vision . 9414–9423
work page 2021
-
[80]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. Gaia: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.