Recognition: unknown
The Effects of Population Size on the Performance of BEAGLE GPU-Based Genetic Programming Runs
Pith reviewed 2026-05-07 17:07 UTC · model grok-4.3
The pith
GPU genetic programming succeeds with problem-dependent population sizes from 1000 to 10 million.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that constant population sizes in BEAGLE GPU genetic programming for symbolic regression yield benefits from narrow deep searches with as few as 1000 individuals for some problems and from broad shallow searches with as many as 10 million individuals for others, while stepped population sizes starting large and decreasing offer a means to balance breadth and depth of search.
What carries the argument
Varying constant and stepped population sizes within the BEAGLE GPU framework for genetic programming, which enables testing extreme scales of population dynamics previously unattainable on CPUs.
Load-bearing premise
The performance differences across population sizes result primarily from the population size and associated search breadth or depth rather than from confounding factors like GPU implementation details or other hyperparameters.
What would settle it
Re-running the symbolic regression experiments with the same population size variations but on a CPU-based genetic programming system to check whether the benefits of narrow versus broad searches hold without GPU-specific factors.
Figures
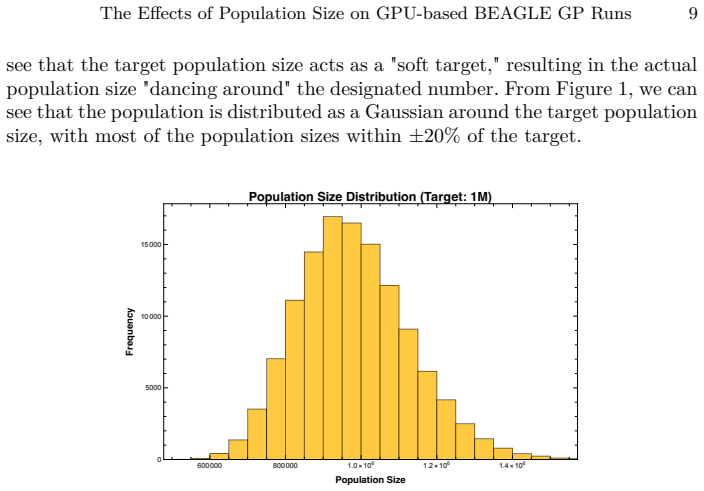

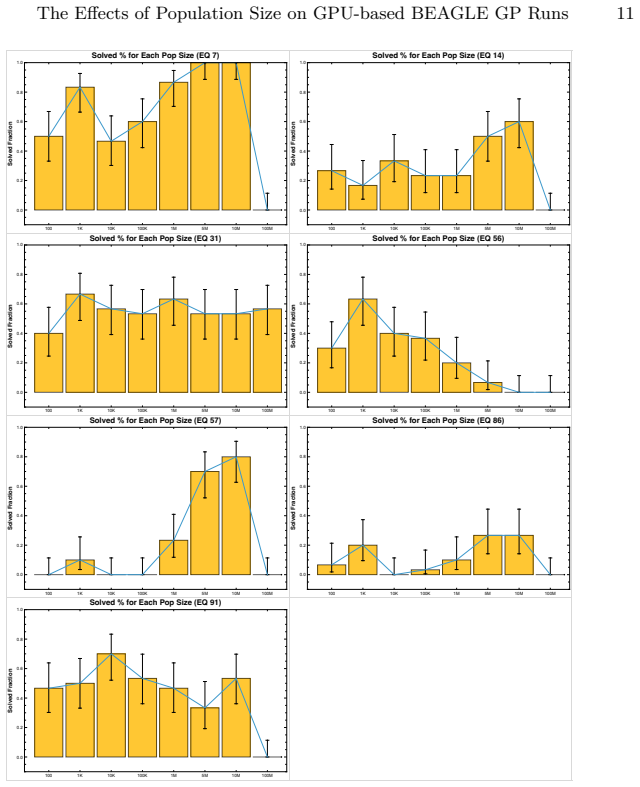


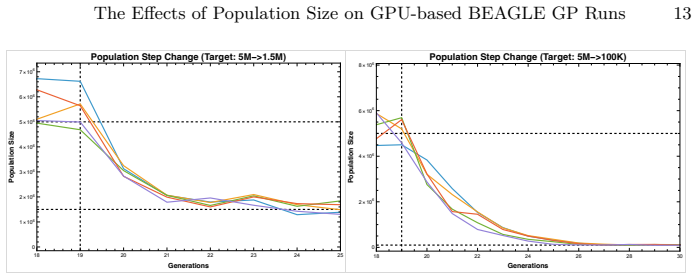

read the original abstract
The Beagle framework, through GPU-based Genetic Programming, enables population dynamics previously unattainable (within practical time frames) by CPU-constrained Genetic Programming systems. This work explores how GPU-enabled population sizes impact the success of training for symbolic regression problems. Specifically, when using constant population sizes, we see benefits of using very narrow and deep searches (as narrow as 1000 individuals) for some problems, while other problems benefit from very broad and shallow searches (as broad as 10 million individuals). We also explore stepped population sizes that start with large populations and drop to small populations to balance the breadth and depth of search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study using the BEAGLE GPU-based Genetic Programming framework to examine how population size affects training success on symbolic regression problems. It reports that constant population sizes produce problem-dependent outcomes, with some problems favoring narrow and deep searches (down to 1000 individuals) and others favoring broad and shallow searches (up to 10 million individuals). The work additionally explores stepped population size schedules that begin large and decrease over time to balance search breadth and depth.
Significance. If the performance differences can be shown to arise specifically from population size after isolating total computational budget, the findings would offer practical guidance for configuring large-scale GP runs on GPUs. This could inform problem-specific choices between deep versus wide search and the utility of dynamic population schedules, potentially improving efficiency in evolutionary computation applications.
major comments (2)
- [Abstract] Abstract: the reported benefits of narrow/deep (1000) versus broad/shallow (10M) searches cannot be cleanly attributed to population size. If generations are held fixed while population size varies, total fitness evaluations scale linearly with population size; the manuscript gives no indication that generations were adjusted, that results were normalized by total evaluations, or that fixed-budget controls were performed. This confound is load-bearing for the central claim that search shape (breadth vs depth) drives the problem-specific differences.
- [Experimental description] Experimental description: the abstract and summary provide no details on the number of independent runs, the specific symbolic regression benchmarks, statistical tests employed, or error bars/variance measures. Without these, it is impossible to assess whether the observed preferences for narrow versus broad searches are statistically reliable or reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped clarify key aspects of our experimental design and presentation. We have revised the manuscript to address the concerns about computational budget controls and methodological details, strengthening the attribution of results to population size effects in GPU-based GP.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benefits of narrow/deep (1000) versus broad/shallow (10M) searches cannot be cleanly attributed to population size. If generations are held fixed while population size varies, total fitness evaluations scale linearly with population size; the manuscript gives no indication that generations were adjusted, that results were normalized by total evaluations, or that fixed-budget controls were performed. This confound is load-bearing for the central claim that search shape (breadth vs depth) drives the problem-specific differences.
Authors: We agree that isolating the effect of search shape from total computational budget is essential. Our original experiments fixed the number of generations (detailed in Section 3) to examine how GPU-enabled population sizes affect parallel search breadth versus depth in practical runtimes. To directly address the potential confound, we have added fixed-budget experiments in a new subsection of the results, where generations are scaled inversely with population size to hold total fitness evaluations constant. These controls confirm that problem-specific preferences for narrow/deep versus broad/shallow searches persist, supporting our claims while ruling out simple evaluation-count explanations. revision: yes
-
Referee: [Experimental description] Experimental description: the abstract and summary provide no details on the number of independent runs, the specific symbolic regression benchmarks, statistical tests employed, or error bars/variance measures. Without these, it is impossible to assess whether the observed preferences for narrow versus broad searches are statistically reliable or reproducible.
Authors: We appreciate the need for these details to support reproducibility. The full paper's Experimental Setup section specifies 30 independent runs per configuration, the exact symbolic regression benchmarks (Nguyen, Keijzer, and Vladislavleva suites), Wilcoxon rank-sum tests for significance, and results with mean ± standard deviation. To make this immediately accessible, we have updated the abstract and added a concise methods summary table in the introduction. revision: yes
Circularity Check
No circularity: purely empirical reporting of experimental observations
full rationale
The paper conducts and reports GPU-based genetic programming experiments varying population size (constant and stepped) on symbolic regression problems. No mathematical derivations, first-principles predictions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. All claims reduce directly to measured run outcomes rather than to any internal definition or prior author result by construction. The skeptic concern about evaluation budget confounding is a potential experimental-design issue but does not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- population_size
axioms (1)
- domain assumption The BEAGLE framework correctly implements standard genetic programming operators and GPU-accelerated evaluation
Reference graph
Works this paper leans on
-
[1]
Arora, R
R. Arora, R. Tulshyan, and K. Deb. Parallelization of binary and real-coded genetic algorithms on gpu using cuda. In IEEE Congress on Evolutionary Computation , pages 1–8. IEEE, 2010
2010
-
[2]
Baeta, J
F. Baeta, J. Correia, T. Martins, and P. Machado. Tensorgp–genetic programming engine in tensorflow. In International Conference on the Applications of Evolu- tionary Computation (Part of EvoStar) , pages 763–778. Springer, 2021
2021
-
[3]
D. M. Chitty. Fast parallel genetic programming: Multi-core CPU versus many- core GPU. Soft Computing , 16(10):1795–1814, 2012
2012
-
[4]
L. Fan, Z. Su, and X. Liu. An asynchronous parallel symbolic regression approach based on multiobjective genetic programming with GPU acceleration. Applied Soft Computing, page 115010, 2026
2026
-
[5]
Farinati and L
D. Farinati and L. Vanneschi. A survey on dynamic populations in bio-inspired algorithms. Genetic Programming and Evolvable Machines , 25(2):19, 2024
2024
-
[6]
Ferigo and G
A. Ferigo and G. Iacca. A gpu-enabled compact genetic algorithm for very large- scale optimization problems. Mathematics, 8(5):758, 2020
2020
-
[7]
Fok, T.-T
K.-L. Fok, T.-T. Wong, and M.-L. Wong. Evolutionary computing on consumer graphics hardware. IEEE Intelligent Systems , 22(2):69–78, 2007
2007
-
[8]
Gagné, M
C. Gagné, M. Parizeau, and M. Dubreuil. Distributed beagle: An environment for parallel and distributed evolutionary computations. In Proc. of the 17th Annual International Symposium on High Performance Computing Systems and Applica- tions (HPCS) , volume 2003, pages 201–208, 2003
2003
-
[9]
Harding and W
S. Harding and W. Banzhaf. Fast Genetic Programming on GPUs. In Euro- pean Conference on Genetic Programming (EuroGP 2007) , pages 90–101. Springer, 2007
2007
-
[10]
Harding and W
S. Harding and W. Banzhaf. Genetic programming on gpus for image processing. International Journal of High Performance Systems Architecture , 1(4):231–240, 2008
2008
-
[11]
N. Haut, W. Banzhaf, and B. Punch. Correlation Versus RMSE Loss Functions in Symbolic Regression Tasks, pages 31–55. Springer Nature Singapore, Singapore, 2023
2023
- [12]
-
[13]
Hu and W
T. Hu and W. Banzhaf. The role of population size in rate of evolution in genetic programming. In European Conference on Genetic Programming (EuroGP 2009) , pages 85–96. Springer, 2009
2009
-
[14]
T. Hu, S. Harding, and W. Banzhaf. Variable population size and evolution accel- eration: A case study with a parallel evolutionary algorithm. Genetic Programming and Evolvable Machines , 11(2):205–225, 2010
2010
-
[15]
Kouchakpour, A
P. Kouchakpour, A. Zaknich, and T. Bräunl. Dynamic population variation in genetic programming. Information Sciences , 179(8):1078–1091, 2009
2009
-
[16]
J. R. Koza. Genetic Programming: On the Programming of Computers by Means of Natural Selection . MIT Press, Cambridge, MA, USA, 1992
1992
-
[17]
W. B. Langdon. Graphics processing units and genetic programming: an overview. Soft computing , 15(8):1657–1669, 2011
2011
-
[18]
W. B. Langdon and W. Banzhaf. A simd interpreter for genetic programming on gpu graphics cards. In European Conference on Genetic Programming (EuroGP 2008), pages 73–85. Springer, 2008. 16 N. Haut et al
2008
-
[19]
Lange, Y
R. Lange, Y. Tang, and Y. Tian. Neuroevobench: Benchmarking evolutionary op- timizers for deep learning applications. Advances in Neural Information Processing Systems, 36:32160–32172, 2023
2023
-
[20]
Noblis. Beagle. https://github.com/Noblis/beagle-v1.x, 2026
2026
-
[21]
Oh and K
K.-S. Oh and K. Jung. Gpu implementation of neural networks. Pattern Recogni- tion, 37(6):1311–1314, 2004
2004
-
[22]
Pandey, M
M. Pandey, M. Fernandez, F. Gentile, O. Isayev, A. Tropsha, A. C. Stern, and A. Cherkasov. The transformational role of gpu computing and deep learning in drug discovery. Nature Machine Intelligence , 4(3):211–221, 2022
2022
-
[23]
Robilliard, V
D. Robilliard, V. Marion, and C. Fonlupt. High-performance Genetic Programming on GPU. In Proceedings of the 2009 Workshop on Bio-inspired Algorithms for Distributed Systems , pages 85–94, 2009
2009
- [24]
-
[25]
Staats, E
K. Staats, E. Pantridge, M. Cavaglia, I. Milovanov, and A. Aniyan. Tensorflow enabled genetic programming. In Proceedings of the genetic and evolutionary com- putation conference companion, pages 1872–1879, 2017
2017
-
[26]
Steinkrau, P
D. Steinkrau, P. Y. Simard, and I. Buck. Using gpus for machine learning al- gorithms. In Proceedings of the Eighth International Conference on Document Analysis and Recognition, pages 1115–1119, 2005
2005
-
[27]
Y. Tao, M. Li, and J. Cao. A new dynamic population variation in genetic pro- gramming. Computing and Informatics , 32(1):63–87, 2013
2013
-
[28]
M. Tegmark. Welcome to the Feynman Symbolic Regression Database!
-
[29]
Tomassini, L
M. Tomassini, L. Vanneschi, J. Cuendet, and F. Fernández. A new technique for dynamic size populations in genetic programming. In Proceedings of the 2004 Congress on Evolutionary Computation , volume 1, pages 486–493. IEEE, 2004
2004
-
[30]
Trujillo, J
L. Trujillo, J. M. M. Contreras, D. E. Hernandez, M. Castelli, and J. J. Tapia. GSGP-CUDA A CUDA Framework for Geometric Semantic Genetic Program- ming. SoftwareX, 18:101085, 2022
2022
-
[31]
L. Wang, Z. Wu, K. Sun, Z. Li, and R. Cheng. EvoGP: A GPU-accelerated Frame- work for Tree-based Genetic Programming. arXiv e-prints , pages arXiv–2501, 2025
2025
-
[32]
Wong, T.-T
M.-L. Wong, T.-T. Wong, and K.-L. Fok. Parallel evolutionary algorithms on graphics processing unit. In 2005 IEEE Congress on Evolutionary Computation , volume 3, pages 2286–2293. IEEE, 2005
2005
-
[33]
Z. Wu, L. Wang, K. Sun, Z. Li, and R. Cheng. Enabling population-level parallelism in tree-based genetic programming for gpu acceleration. IEEE Transactions on Evolutionary Computation , 2026
2026
-
[34]
Zhang, A
R. Zhang, A. Lensen, and Y. Sun. Speeding up genetic programming based sym- bolic regression using gpus. In Pacific Rim International Conference on Artificial Intelligence, pages 519–533. Springer, 2022
2022
-
[35]
Zhang, Y
R. Zhang, Y. Sun, and M. Zhang. GPU-Based Genetic Programming for Faster Feature Extraction in Binary Image Classification. IEEE Transactions on Evolu- tionary Computation , 28(6):1590–1604, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.