Recognition: unknown
INJEQT: Improved Magic-State Injection Protocol for Fault-Tolerant Quantum Extractor Architectures
Pith reviewed 2026-05-07 17:01 UTC · model grok-4.3
The pith
A two-factory injection protocol using auxiliary Rz synthesis cuts error rates by up to 22 times in extractor architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
INJEQT is a 2-factory design that uses an auxiliary code capable of synthesizing Rz(theta) states with lower error rates. These states are then injected into the extractor modules using only a constant number of inter-module measurements. This approach reduces overall error rates by up to 22 times. A pre-fetching strategy that prepares the Rz states and their correction states in parallel improves the wall-clock time by up to 13 times and reduces the space-time cost by up to 7.2 times, for an optimal choice of the number of INJEQT factories. The gains hold across distillation, cultivation, and STAR preparation methods and for both lattice-surgery and transversal-CNOT injection models.
What carries the argument
The INJEQT 2-factory protocol that synthesizes Rz(theta) states in an auxiliary code and injects them using a constant number of inter-module measurements together with parallel pre-fetching of states and corrections.
If this is right
- Overall program error rates drop by up to 22 times, extending the length of reliable quantum circuits.
- Wall-clock time improves by up to 13 times through parallel preparation of Rz states and corrections.
- Space-time cost falls by up to 7.2 times when the number of INJEQT factories is chosen optimally for each metric.
- The error and cost reductions remain consistent across distillation, cultivation, and STAR state-preparation techniques.
- Results are robust for both lattice-surgery-based and transversal-CNOT-based injection models.
Where Pith is reading between the lines
- The reduction in inter-module measurements could allow larger modular quantum systems to operate before routing and communication errors become the new bottleneck.
- Parallel pre-fetching of magic states may generalize to other sequential non-Clifford operations in fault-tolerant architectures.
- Hybrid use of auxiliary codes for state preparation could become a standard way to trade local error rates against global communication costs.
- If the gains scale with code distance, INJEQT-style injection might lower the overhead needed to reach chemical accuracy or other practical thresholds.
Load-bearing premise
The auxiliary code must reliably synthesize Rz(theta) states at lower error rates than standard synthillation, and the modeled execution times for lattice-surgery and transversal-CNOT injections must match real hardware without hidden calibration or routing costs.
What would settle it
A direct comparison on hardware or a high-fidelity simulator showing that the total program error rate after INJEQT is not lower by a factor of roughly 22 relative to standard sequential T-state injection.
Figures










read the original abstract
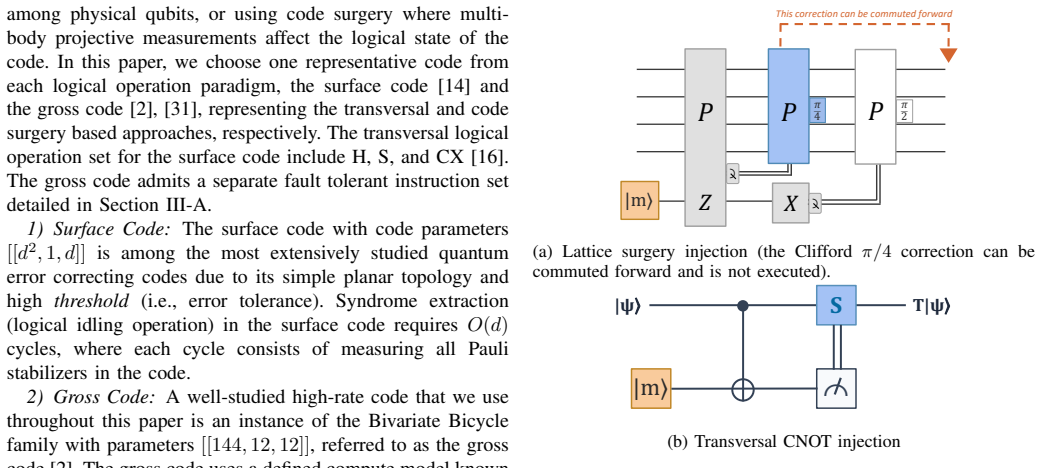
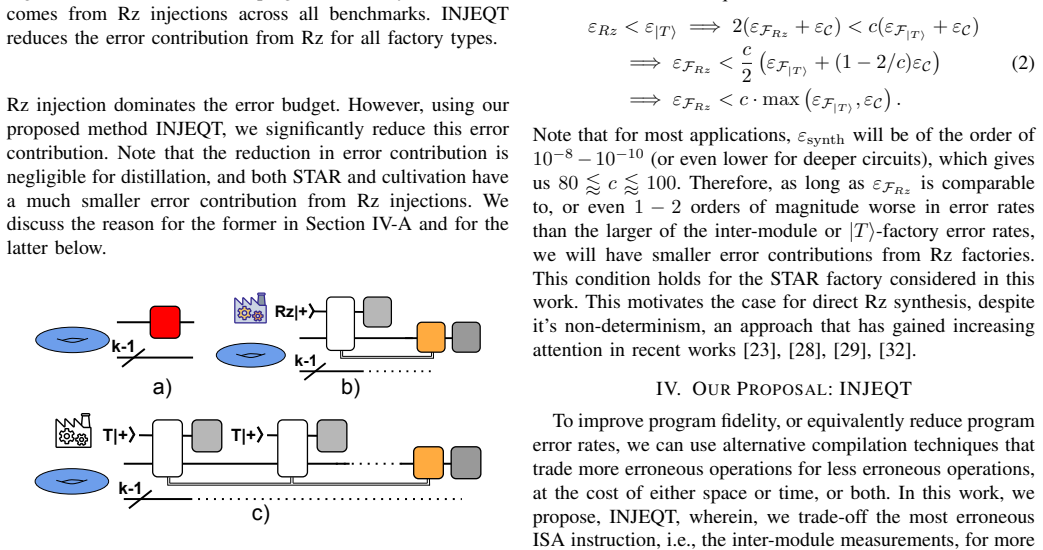
Near-term FTQC system designs are constrained by limited error budgets and largely sequential execution of non-Clifford gates. As a result, reducing the number of the most-error prone instructions becomes critical for successful program execution. In this work, we study the extractor architecture, a recently proposed FTQC design that enables universal quantum computation on spatially-efficient QEC codes such as the BB code family. In these architectures, over $90\%$ of the total program error arises from the synthillation process, which involves $\lvert T\rangle$-state preparation and injection to implement non-Clifford gates. We observe that standard Rz synthillation requires multiple sequential $\lvert T\rangle$-state injections, each incurring an inter-module measurements, the most expensive instruction in the architecture, which cumulatively dominate the overall error budget. To address this bottleneck, we propose INJEQT, a $2$-factory design that uses an auxiliary code capable of synthesizing $Rz(\theta)$ states with lower error rates. These states are then injected into the extractor modules using only a constant number of inter-module measurements. This approach reduces overall error rates by up to $22\times$. We further reduce the time overhead by a pre-fetching strategy that prepares the Rz states and their correction states in parallel. This approach improves the wall-clock time by up to $13\times$ and reduces the space-time cost by up to $7.2\times$, for an optimal choice of the number of INJEQT factories for each metric. We evaluate INJEQT for multiple state preparation techniques such as distillation, cultivation and STAR, and model the execution times for both lattice surgery-based and transversal CNOT based injections. Our results demonstrate that INJEQT is robust across factory choices and device technologies, enabling more efficient architectural designs for FTQC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes INJEQT, a two-factory architectural modification to the extractor design for fault-tolerant quantum computation on codes such as the BB family. It replaces the dominant sequential |T⟩-state synthillation (which accounts for >90% of program error via repeated inter-module measurements) with an auxiliary code that prepares Rz(θ) states at lower error, injected using only a constant number of such measurements. A pre-fetching schedule prepares Rz states and corrections in parallel. The work reports up to 22× error-rate reduction, 13× wall-clock time improvement, and 7.2× space-time cost reduction when the number of INJEQT factories is optimized per metric; results are shown for distillation, cultivation, and STAR preparation methods under both lattice-surgery and transversal-CNOT injection models.
Significance. If the modeled gains hold under realistic error rates and overheads, INJEQT would materially relax the error budget and latency constraints that currently limit near-term FTQC on spatially efficient codes. The explicit modeling across multiple state-preparation techniques and two injection primitives, together with the pre-fetching optimization, supplies a concrete, reusable design pattern that could be adopted in extractor-based compilers and hardware schedulers.
major comments (3)
- [Abstract and §4] Abstract and §4 (evaluation): the headline factors (22× error, 13× time, 7.2× space-time) are obtained by optimizing the number of INJEQT factories, yet the manuscript supplies neither the explicit error model (physical error rates, measurement error probabilities, or the auxiliary-code distance) nor the baseline comparison tables that would allow reproduction or sensitivity checking of these multipliers.
- [§3.2] §3.2 (auxiliary Rz synthesis): the claim that the auxiliary code delivers materially lower error than standard synthillation is load-bearing for the 22× error reduction, but no numerical error-rate comparison, threshold calculation, or Monte-Carlo verification is provided; without this, the net improvement cannot be confirmed to survive realistic calibration or routing overheads.
- [§4.3] §4.3 (pre-fetching schedule): the 13× time and 7.2× space-time gains assume that parallel preparation of Rz states and correction states incurs no additional inter-module measurement or routing cost; the paper does not quantify the scheduling overhead or show that the assumed parallelism remains feasible when the extractor modules are already occupied by data qubits.
minor comments (2)
- [§2] Notation for the two-factory layout and the distinction between “INJEQT factories” and the auxiliary code is introduced without a diagram or consistent acronym expansion on first use.
- [Figures 4–6] Figure captions for the timing diagrams do not list the numerical parameters (distillation rounds, measurement times, etc.) used to generate the plotted schedules.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity, reproducibility, and completeness.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (evaluation): the headline factors (22× error, 13× time, 7.2× space-time) are obtained by optimizing the number of INJEQT factories, yet the manuscript supplies neither the explicit error model (physical error rates, measurement error probabilities, or the auxiliary-code distance) nor the baseline comparison tables that would allow reproduction or sensitivity checking of these multipliers.
Authors: We agree that explicit parameters and baseline tables are needed for full reproducibility. In the revised manuscript we will add a dedicated error-model subsection in §4 that specifies the physical error rates (depolarizing noise at 10^{-3}), measurement error probabilities, and code distances for both the extractor and auxiliary codes. We will also insert comparison tables showing error, wall-clock time, and space-time cost for the baseline extractor versus INJEQT across a range of factory counts (1 to the optimum). These tables will document how the headline multipliers are obtained by independently optimizing each metric over factory count. revision: yes
-
Referee: [§3.2] §3.2 (auxiliary Rz synthesis): the claim that the auxiliary code delivers materially lower error than standard synthillation is load-bearing for the 22× error reduction, but no numerical error-rate comparison, threshold calculation, or Monte-Carlo verification is provided; without this, the net improvement cannot be confirmed to survive realistic calibration or routing overheads.
Authors: The error advantage follows from replacing multiple sequential inter-module measurements with a constant number; this scaling is derived analytically in §3.2 via standard error propagation on the BB code family. In revision we will add a table of numerical error-rate comparisons for representative parameters together with threshold estimates based on code distance. Full Monte-Carlo verification under detailed noise models was not performed, as the work focuses on architectural modeling; we will explicitly note this limitation and cite consistency with prior analytical results in the literature. A short discussion of calibration and routing overheads will also be included. revision: partial
-
Referee: [§4.3] §4.3 (pre-fetching schedule): the 13× time and 7.2× space-time gains assume that parallel preparation of Rz states and correction states incurs no additional inter-module measurement or routing cost; the paper does not quantify the scheduling overhead or show that the assumed parallelism remains feasible when the extractor modules are already occupied by data qubits.
Authors: Pre-fetching overlaps auxiliary-factory preparation with extractor-module operations under the assumption of independent hardware resources. In the revision we will augment §4.3 with a quantitative contention model that estimates additional routing and measurement overhead under worst-case module occupancy by data qubits. A schedule diagram and pseudocode will be added to illustrate the parallel timeline and demonstrate feasibility. The reported gains will be qualified with bounds on these overheads. revision: yes
- Monte-Carlo verification of auxiliary-code error rates under realistic noise models (no such simulations were performed)
Circularity Check
No significant circularity; improvements from explicit architectural modeling
full rationale
The paper's derivation consists of proposing the INJEQT 2-factory architecture with auxiliary Rz(θ) synthesis plus pre-fetching, then computing error/time/space-time factors from modeled injection counts and timings for lattice-surgery and transversal-CNOT under distillation/cultivation/STAR. No equations, fitted parameters, or self-citations reduce the headline multipliers (22×, 13×, 7.2×) to the inputs by construction; the quantitative claims are direct consequences of the stated assumptions about auxiliary error rates and per-injection overheads, which remain external and falsifiable. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Akahoshi, K. Maruyama, H. Oshima, S. Sato, and K. Fujii, “Partially Fault-tolerant Quantum Computing Architecture with Error-corrected Clifford Gates and Space-time Efficient Analog Rotations,” Mar. 2023. [Online]. Available: https://arxiv.org/abs/2303.13181v1
-
[2]
S. Bravyi, A. W. Cross, J. M. Gambetta, D. Maslov, P. Rall, and T. J. Yoder, “High-threshold and low-overhead fault-tolerant quantum memory,”Nature, vol. 627, no. 8005, pp. 778–782, Mar. 2024, arXiv:2308.07915 [quant-ph]. [Online]. Available: http: //arxiv.org/abs/2308.07915
-
[3]
Correlated decoding of logical algorithms with transversal gates,
M. Cain, C. Zhao, H. Zhou, N. Meister, J. P. B. Ataides, A. Jaffe, D. Bluvstein, and M. D. Lukin, “Correlated decoding of logical algorithms with transversal gates,” Mar. 2024. [Online]. Available: https://arxiv.org/abs/2403.03272v2
-
[4]
Unifying gate-synthesis and magic state distillation,
E. T. Campbell and M. Howard, “Unifying gate-synthesis and magic state distillation,”Physical Review Letters, vol. 118, no. 6, p. 060501, Feb. 2017, arXiv:1606.01906 [quant-ph]. [Online]. Available: http://arxiv.org/abs/1606.01906
-
[5]
Toward the first quantum simulation with quantum speedup,
A. M. Childs, D. Maslov, Y . Nam, N. J. Ross, and Y . Su, “Toward the first quantum simulation with quantum speedup,”Proceedings of the National Academy of Sciences, vol. 115, no. 38, pp. 9456–9461, sep
-
[6]
Childs, Dmitri Maslov, Yunseong Nam, Neil J
[Online]. Available: https://doi.org/10.1073/pnas.1801723115
-
[7]
Restrictions on Transversal Encoded Quantum Gate Sets
B. Eastin and E. Knill, “Restrictions on Transversal Encoded Quantum Gate Sets,”Physical Review Letters, vol. 102, no. 11, p. 110502, Mar. 2009, arXiv:0811.4262 [quant-ph]. [Online]. Available: http://arxiv.org/abs/0811.4262
-
[8]
Magic state cultivation: growing T states as cheap as CNOT gates
C. Gidney, N. Shutty, and C. Jones, “Magic state cultivation: growing T states as cheap as CNOT gates,” Sep. 2024, arXiv:2409.17595 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2409.17595
work page internal anchor Pith review arXiv 2024
-
[9]
Quantum algorithm for linear systems of equations,
A. W. Harrow, A. Hassidim, and S. Lloyd, “Quantum algorithm for linear systems of equations,”Physical Review Letters, vol. 103, no. 15, oct 2009. [Online]. Available: https://doi.org/10.1103/physrevlett.103. 150502
-
[10]
Extractors: QLDPC Architectures for Efficient Pauli-Based Computation,
Z. He, A. Cowtan, D. J. Williamson, and T. J. Yoder, “Extractors: QLDPC Architectures for Efficient Pauli-Based Computation,” Oct. 2025, arXiv:2503.10390 [quant-ph]. [Online]. Available: http://arxiv. org/abs/2503.10390
-
[11]
H. Jacinto, E. Gouzien, and N. Sangouard, “Network requirements for distributed quantum computation,”Physical Review Research, vol. 8, no. 1, p. 013205, Feb. 2026. [Online]. Available: https: //link.aps.org/doi/10.1103/v9ln-c4v2
-
[12]
Architecting Early Fault Tolerant Neutral Atoms Systems with Quantum Advantage
S. Khan, S. Sethi, K. Sahay, Y . Lin, J. Alnas, S. Kurapati, A. Anand, J. M. Baker, and K. R. Brown, “Architecting Early Fault Tolerant Neutral Atoms Systems with Quantum Advantage,” Apr. 2026, arXiv:2604.19735 [quant-ph]. [Online]. Available: http: //arxiv.org/abs/2604.19735
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Improved fault-tolerant quantum simulation of condensed- phase correlated electrons via trotterization,
I. D. Kivlichan, C. Gidney, D. W. Berry, N. Wiebe, J. McClean, W. Sun, Z. Jiang, N. Rubin, A. Fowler, A. Aspuru-Guzik, H. Neven, and R. Babbush, “Improved fault-tolerant quantum simulation of condensed- phase correlated electrons via trotterization,”Quantum, vol. 4, p. 296, jul
-
[14]
Kivlichan, Craig Gidney, Dominic W
[Online]. Available: https://doi.org/10.22331/q-2020-07-16-296
-
[15]
Qasmbench: A low- level quantum benchmark suite for nisq evaluation and simulation,
A. Li, S. Stein, S. Krishnamoorthy, and J. Ang, “QASMBench: A Low-level QASM Benchmark Suite for NISQ Evaluation and Simulation,” May 2022, arXiv:2005.13018 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2005.13018
-
[16]
A Game of Surface Codes: Large-Scale Quantum Computing with Lattice Surgery
D. Litinski, “A Game of Surface Codes: Large-Scale Quantum Computing with Lattice Surgery,”Quantum, vol. 3, Aug. 2018. [Online]. Available: http://arxiv.org/abs/1808.02892
work page Pith review arXiv 2018
-
[17]
Magic State Distillation: Not as Costly as You Think,
——, “Magic State Distillation: Not as Costly as You Think,”Quantum, vol. 3, p. 205, Dec. 2019, arXiv:1905.06903 [quant-ph]. [Online]. Available: http://arxiv.org/abs/1905.06903
-
[18]
Lattice Surgery with a Twist: Simplifying Clifford Gates of Surface Codes,
D. Litinski and F. von Oppen, “Lattice Surgery with a Twist: Simplifying Clifford Gates of Surface Codes,”Quantum, vol. 2, p. 62, May 2018, arXiv:1709.02318 [cond-mat, physics:quant-ph]. [Online]. Available: http://arxiv.org/abs/1709.02318
-
[19]
Assessing System Capabilities and Bottlenecks of an Early Fault-Tolerant Bicycle Architecture
K. Liu, B. Foxman, G.-L. R. Anselmetti, and Y . Ding, “Assessing System Capabilities and Bottlenecks of an Early Fault-Tolerant Bicycle Architecture,” Apr. 2026, arXiv:2604.20013 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2604.20013
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Remote Entanglement in Lattice Surgery: To Distill, or Not to Distill,
S. Liu, J. Stack, K. Sun, R. V . Beeumen, I. Monga, K. Klymko, K. R. Brown, and E. Saglamyurek, “Remote Entanglement in Lattice Surgery: To Distill, or Not to Distill,” Mar. 2026, arXiv:2603.06513 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2603.06513
-
[21]
Elucidating reaction mechanisms on quantum computers,
M. Reiher, N. Wiebe, K. M. Svore, D. Wecker, and M. Troyer, “Elucidating reaction mechanisms on quantum computers,”Proceedings of the National Academy of Sciences, vol. 114, no. 29, pp. 7555–7560,
-
[22]
Proceedings of the National Academy of Sciences120(33) (2023) https://doi.org/10.1073/pnas
[Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas. 1619152114
-
[23]
Optimal ancilla-free Clifford+T approximation of z-rotations
N. J. Ross and P. Selinger, “Optimal ancilla-free Clifford+T approximation of z-rotations,” Jun. 2016, arXiv:1403.2975 [quant-ph]. [Online]. Available: http://arxiv.org/abs/1403.2975
work page Pith review arXiv 2016
-
[24]
Error correction of transversal cnot gates for scalable surface-code computation,
K. Sahay, Y . Lin, S. Huang, K. R. Brown, and S. Puri, “Error correction of transversal cnot gates for scalable surface-code computation,” PRX Quantum, vol. 6, no. 2, May 2025. [Online]. Available: http://dx.doi.org/10.1103/PRXQuantum.6.020326
-
[25]
Fold- transversal surface code cultivation
K. Sahay, P.-K. Tsai, K. Chang, Q. Su, T. B. Smith, S. Singh, and S. Puri, “Fold-transversal surface code cultivation,” Mar. 2026, arXiv:2509.05212 [quant-ph]. [Online]. Available: http://arxiv.org/abs/ 2509.05212
-
[26]
RESCQ: Realtime Scheduling for Continuous Angle Quantum Error Correction Architectures,
S. Sethi and J. M. Baker, “RESCQ: Realtime Scheduling for Continuous Angle Quantum Error Correction Architectures,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, Mar. 2025, pp. 1028–1043, arXiv:2408.14708 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2408.14708
-
[27]
Optimizing Logical Mappings for Quantum Low-Density Parity Check Codes,
S. Sethi, S. Khan, M. Poster, A. Anand, and J. M. Baker, “Optimizing Logical Mappings for Quantum Low-Density Parity Check Codes,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.17167v1
-
[28]
Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,
P. W. Shor, “Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,”SIAM review, 1999
1999
-
[29]
Fault-tolerant optical interconnects for neutral-atom arrays,
J. Sinclair, J. Ramette, B. Grinkemeyer, D. Bluvstein, M. D. Lukin, and V . Vuleti´c, “Fault-tolerant optical interconnects for neutral-atom arrays,” Physical Review Research, vol. 7, no. 1, p. 013313, Mar. 2025. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevResearch.7.013313
-
[30]
Universal adapters between quantum LDPC codes,
E. Swaroop, T. Jochym-O’Connor, and T. J. Yoder, “Universal adapters between quantum LDPC codes,” Oct. 2024. [Online]. Available: https://arxiv.org/abs/2410.03628v4
-
[31]
Practical quantum advantage on partially fault-tolerant quantum computer,
R. Toshio, Y . Akahoshi, J. Fujisaki, H. Oshima, S. Sato, and K. Fujii, “Practical quantum advantage on partially fault-tolerant quantum computer,” Aug. 2024. [Online]. Available: https://arxiv.org/abs/2408. 14848v1
2024
-
[32]
R. Toshio, S. Kanasugi, J. Fujisaki, H. Oshima, S. Sato, and K. Fujii, “STAR-Magic Mutation: Even More Efficient Analog Rotation Gates for Early Fault-Tolerant Quantum Computer,” Mar. 2026, arXiv:2603.22891 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2603.22891
-
[33]
Distilling magic states in the bicycle architecture,
S. Xu, K. Liu, P. Rall, Z. He, and Y . Ding, “Distilling Magic States in the Bicycle Architecture,” Feb. 2026, arXiv:2602.20546 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2602.20546
-
[34]
Tour de gross: A modular quantum computer based on bivariate bicycle codes
T. J. Yoder, E. Schoute, P. Rall, E. Pritchett, J. M. Gambetta, A. W. Cross, M. Carroll, and M. E. Beverland, “Tour de gross: A modular quantum computer based on bivariate bicycle codes,” Jun. 2025, arXiv:2506.03094 [quant-ph]. [Online]. Available: http://arxiv.org/abs/2506.03094
work page internal anchor Pith review arXiv 2025
-
[35]
Transversal gates for probabilistic implementation of multi-qubit Pauli rotations,
N. Yoshioka, A. Seif, A. Cross, and A. Javadi-Abhari, “Transversal gates for probabilistic implementation of multi-qubit Pauli rotations,” Oct. 2025, arXiv:2510.08290 [quant-ph]. [Online]. Available: http: //arxiv.org/abs/2510.08290
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.