Recognition: unknown
ResetEdit: Precise Text-guided Editing of Generated Image via Resettable Starting Latent
Pith reviewed 2026-05-07 16:58 UTC · model grok-4.3
The pith
ResetEdit reconstructs original generation latents by embedding discrepancy signals during diffusion, allowing precise text-guided edits without per-image storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
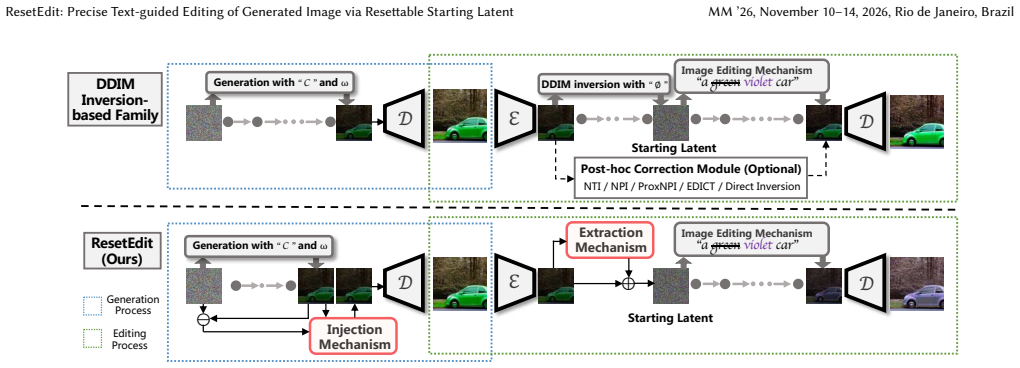
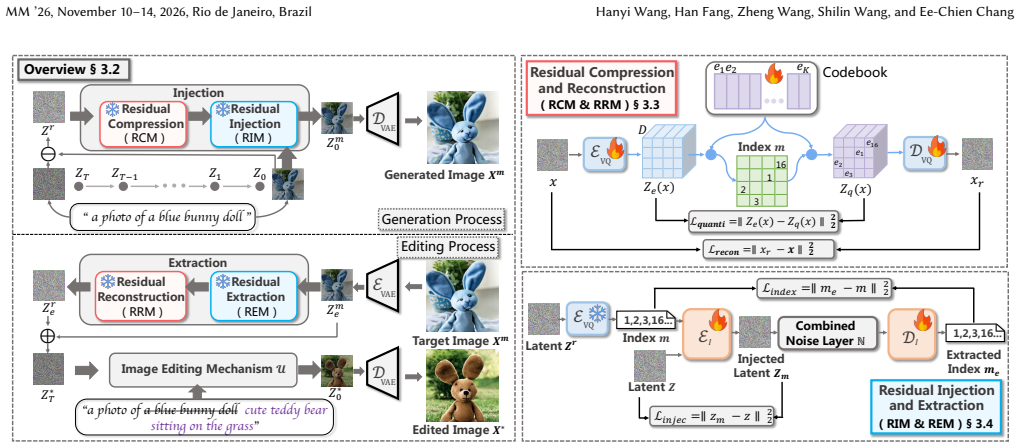
ResetEdit is a proactive diffusion editing framework that embeds recoverable latent information directly into the generation process. By injecting the discrepancy between the clean and diffused latents into the diffusion trajectory and extracting it during inversion, ResetEdit reconstructs a resettable latent that closely approximates the true starting state. Additionally, a lightweight latent optimization module compensates for reconstruction bias caused by VAE asymmetry. Built upon Stable Diffusion, it integrates seamlessly with existing tuning-free editing methods and consistently outperforms state-of-the-art baselines in both controllability and visual fidelity.
What carries the argument
Discrepancy injection into the diffusion trajectory for later extraction of a resettable starting latent during inversion.
If this is right
- Supplies a high-quality starting latent that supports both diverse modifications and fine-grained region-specific control.
- Delivers improved edit fidelity and structural consistency compared to DDIM inversion.
- Outperforms state-of-the-art baselines in controllability and visual fidelity.
- Integrates directly with existing tuning-free editing methods without per-image tuning or extra storage.
- Reduces storage overhead by eliminating the need to retain original generation latents.
Where Pith is reading between the lines
- The embedding technique could extend to other diffusion-based tasks such as video generation or sequential editing where starting-state recovery is valuable.
- Large-scale image pipelines might achieve lower memory use by replacing latent storage with on-demand reconstruction.
- Similar proactive signal injection could be tested in non-diffusion generators to improve downstream controllability.
- Empirical checks on reconstruction error across varied prompts would show how far the resettable latent generalizes.
Load-bearing premise
The injected discrepancy signal between clean and diffused latents survives the full diffusion and inversion process accurately enough to reconstruct a usable starting latent, and the lightweight optimization reliably corrects VAE asymmetry without new distortions.
What would settle it
Generate a set of images from known starting latents, run ResetEdit's injection and inversion to produce reconstructed latents, then perform identical text-guided edits from both the true and reconstructed latents; large gaps in edit precision, structural consistency, or visual quality would falsify the approximation claim.
Figures






read the original abstract
Recent advances in diffusion models have enabled high-quality image generation, leading to increasing demand for post-generation editing that modifies local regions while preserving global structure. Achieving such flexible and precise editing requires a high-quality starting point, a latent representation that provides both the freedom needed for diverse modifications and the precision required for fine-grained, region-specific control. However, existing inversion-based approaches such as DDIM inversion often yield unsatisfactory starting latents, resulting in degraded edit fidelity and structural inconsistency. Ideally, the most suitable editing anchor should be the original latent used during the generation process, as it inherently captures the scene's structure and semantics. Yet, storing this latent for every generated image is impractical due to massive storage and retrieval costs. To address this challenge, we propose ResetEdit, a proactive diffusion editing framework that embeds recoverable latent information directly into the generation process. By injecting the discrepancy between the clean and diffused latents into the diffusion trajectory and extracting it during inversion, ResetEdit reconstructs a resettable latent that closely approximates the true starting state. Additionally, a lightweight latent optimization module compensates for reconstruction bias caused by VAE asymmetry. Built upon Stable Diffusion, ResetEdit integrates seamlessly with existing tuning-free editing methods and consistently outperforms state-of-the-art baselines in both controllability and visual fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ResetEdit, a proactive diffusion editing framework for text-guided image editing. It embeds the discrepancy between clean and diffused latents into the generation trajectory to allow reconstruction of a resettable starting latent during inversion, approximating the original generation latent without storage. A lightweight latent optimization module is introduced to correct for VAE asymmetry bias. The method is built on Stable Diffusion and integrates with tuning-free editing methods, claiming superior controllability and visual fidelity over baselines.
Significance. If the reconstruction of the resettable latent holds with sufficient accuracy, the work addresses a practical bottleneck in diffusion-based editing by eliminating per-image latent storage while preserving edit precision. The proactive discrepancy injection is a direct engineering contribution that could improve adoption of tuning-free methods. Credit is due for the focus on VAE asymmetry compensation and seamless integration with Stable Diffusion pipelines.
major comments (2)
- [§3.2] §3.2 (discrepancy injection and extraction): the claim that the injected signal survives the full diffusion-inversion cycle to yield a usable starting latent lacks supporting analysis or bounds; this is load-bearing for the central reconstruction claim and the 'closely approximates' assertion.
- [§4] §4 (experimental validation): the abstract asserts consistent outperformance in controllability and visual fidelity, yet no quantitative metrics, ablation results on the latent optimization module, or error analysis of reconstruction bias are referenced; without these the magnitude of improvement over DDIM inversion cannot be assessed.
minor comments (2)
- [§3] Notation for the resettable latent and discrepancy term should be introduced with explicit equations early in §3 to improve readability.
- [Figures] Figure captions for the overall pipeline and editing examples should include parameter settings and baseline methods shown for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of ResetEdit in addressing latent storage issues in diffusion-based editing. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (discrepancy injection and extraction): the claim that the injected signal survives the full diffusion-inversion cycle to yield a usable starting latent lacks supporting analysis or bounds; this is load-bearing for the central reconstruction claim and the 'closely approximates' assertion.
Authors: We agree that the survival of the injected discrepancy through the full cycle is central and would benefit from additional formal support. The method relies on the deterministic nature of DDIM inversion to extract the pre-injected discrepancy signal, with the formulation in §3.2 ensuring the signal is added in a recoverable manner at each step. While the current version demonstrates this through the reconstruction equations and downstream editing performance, we will revise §3.2 to include a step-by-step derivation of signal preservation and a simple error bound based on the Lipschitz continuity of the diffusion process under standard assumptions. We will also report quantitative reconstruction error metrics (e.g., L2 distance to the original latent) in the revised experiments. revision: yes
-
Referee: [§4] §4 (experimental validation): the abstract asserts consistent outperformance in controllability and visual fidelity, yet no quantitative metrics, ablation results on the latent optimization module, or error analysis of reconstruction bias are referenced; without these the magnitude of improvement over DDIM inversion cannot be assessed.
Authors: The experimental section does contain quantitative evaluations (CLIP-based controllability scores and perceptual fidelity metrics) and comparisons against DDIM inversion, along with an ablation on the latent optimization module. However, we acknowledge that direct referencing from the abstract and a dedicated error analysis of reconstruction bias are insufficiently prominent. In the revision we will (1) add explicit cross-references in the abstract to the relevant tables/figures in §4, (2) expand the ablation study with numerical results isolating the contribution of the latent optimization module, and (3) include a new analysis quantifying reconstruction bias (original vs. resettable latent) across multiple prompts and timesteps. These additions will make the magnitude of improvement over baselines clearer. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes ResetEdit as a proactive framework that injects the discrepancy between clean and diffused latents into the diffusion trajectory during generation, then extracts it on inversion to reconstruct an approximate starting latent, supplemented by a lightweight optimization module to address VAE asymmetry. These steps are presented as direct engineering additions to existing diffusion pipelines without any equations or claims that reduce the resettable latent reconstruction to a fitted parameter, self-defined quantity, or self-citation chain from the same work. No load-bearing uniqueness theorems, ansatzes, or renamings of known results are invoked in the provided description; the central claim rests on the mechanics of discrepancy embedding and compensation, which are independent of the target editing fidelity metrics and do not tautologically presuppose their own success.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VAE asymmetry introduces reconstruction bias that can be compensated by a lightweight optimization module
invented entities (1)
-
resettable latent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. 2023. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international confer- ence on computer vision. 22560–22570
2023
-
[2]
Gustavosta. 2024. Stable-Diffusion-Prompts Dataset. Hugging Face. https: //huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts Accessed: 2- April-2025
2024
- [3]
-
[4]
Ligong Han, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Anastasis Stathopoulos, Xiaoxiao He, Yuxiao Chen, et al . 2024. Proxedit: Improving tuning-free real image editing with proximal guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 4291–4301
2024
-
[5]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626(2022)
work page internal anchor Pith review arXiv 2022
-
[6]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[7]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review arXiv 2022
-
[8]
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. 2024. An edit friendly ddpm noise space: Inversion and manipulations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12469–12478
2024
-
[9]
Zhaoyang Jia, Han Fang, and Weiming Zhang. 2021. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. InProceedings of the 29th ACM international conference on multimedia. 41–49
2021
- [10]
-
[11]
Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. 2024. To- wards understanding cross and self-attention in stable diffusion for text-guided image editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7817–7826
2024
-
[12]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2021. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073(2021)
work page internal anchor Pith review arXiv 2021
-
[13]
Daiki Miyake, Akihiro Iohara, Yu Saito, and Toshiyuki Tanaka. 2025. Negative- prompt inversion: Fast image inversion for editing with text-guided diffusion models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 2063–2072
2025
-
[14]
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2023. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6038–6047
2023
-
[15]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[16]
Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.061251, 2 (2022), 3
work page internal anchor Pith review arXiv 2022
-
[17]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[18]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems35 (2022), 36479–36494
2022
-
[19]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review arXiv 2020
-
[20]
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. 2023. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1921–1930
2023
-
[21]
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning.Advances in neural information processing systems30 (2017)
2017
-
[22]
Bram Wallace, Akash Gokul, and Nikhil Naik. 2023. Edict: Exact diffusion inver- sion via coupled transformations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22532–22541
2023
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.