Recognition: unknown
Encoded Forward Backward Stochastic Neural Network for High-Dimensional Backward Stochastic Differential Equations and Parabolic Partial Differential Equations
Pith reviewed 2026-05-07 15:54 UTC · model grok-4.3
The pith
Encoding BSDE input coordinates as multi-channel tensors enables convolutional networks to approximate high-dimensional parabolic PDEs more efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The encoded FBSNN algorithm encodes the input coordinates as tensors treated as images with multiple channels which can be processed efficiently by convolutional neural networks. The encoding mechanism enriches the input features such that the spatial and temporal features can be balanced, providing a simple yet effective extension of the vanilla FBSNN algorithm for more efficient approximation of BSDEs.
What carries the argument
The encoding of input coordinates into multi-channel image tensors for processing by convolutional neural networks, which enriches features to balance spatial and temporal information in high-dimensional settings.
If this is right
- High-dimensional Black-Scholes-Barenblatt equations can be approximated with greater efficiency and accuracy.
- Hamilton-Jacobi-Bellman equations in high dimensions become more tractable using this neural network extension.
- The approach extends vanilla FBSNN without requiring extensive problem-specific tuning.
- Deep learning methods for BSDEs gain a mechanism to handle spatial-temporal balance better than standard fully-connected networks.
- Overall computational efficiency improves for solving parabolic PDEs through their BSDE representations.
Where Pith is reading between the lines
- This encoding trick might apply to other deep learning solvers for PDEs or stochastic equations by representing time-space data in image formats.
- Applications in quantitative finance could see faster computations for option pricing in many assets.
- Future work could test if the same encoding improves performance on even higher dimensions or different network architectures.
- Connecting to image processing techniques may open hybrid methods for scientific computing problems involving grids or continuous domains.
Load-bearing premise
That representing the input coordinates as multi-channel image tensors and processing them with convolutional networks will enrich features and balance spatial and temporal information enough to improve approximation quality and efficiency without adding new biases or needing extra tuning.
What would settle it
Running the encoded FBSNN and the vanilla FBSNN on the same high-dimensional Black-Scholes-Barenblatt or Hamilton-Jacobi-Bellman problem and finding no reduction in approximation error or computation time for the encoded version would show the extension does not improve efficiency.
Figures



read the original abstract
Backward stochastic differential equation (BSDE) provides probabilistic solutions for a class of parabolic partial differential equations (PDEs). DeepBSDE and FBSNN are two deep learning approaches for solving high-dimensional PDEs through approximating the solution of BSDEs. The conventional approach for learning functions defined on continuous domains is via fully-connected networks (FCNs) such that each input dimension is represented by a single neuron. In the current study, a new encoded FBSNN algorithm is proposed to enhance the efficiency and accuracy of approximating BSDEs using encoding and convolution. The input coordinates are encoded as tensors treated as images with multiple channels which can be processed efficiently by convolutional neural networks. The encoding mechanism enriches the input features such that the spatial and temporal features can be balanced. The encoded FBSNN algorithm provides a simple yet effective extension of the vanilla FBSNN algorithm such that BSDEs can be approximated more efficiently. The new algorithm is validated using the essentially high-dimensional Black-Scholes-Barenblatt and Hamilton-Jacobi-Bellman benchmark cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an 'encoded FBSNN' algorithm as a simple extension of the vanilla forward-backward stochastic neural network (FBSNN) method for high-dimensional BSDEs and associated parabolic PDEs. Inputs (t, x) are encoded as multi-channel image tensors and processed via convolutional neural networks rather than fully-connected layers, with the claim that this enriches features and balances spatial-temporal information to improve efficiency and accuracy. Validation is asserted on the high-dimensional Black-Scholes-Barenblatt and Hamilton-Jacobi-Bellman benchmark problems.
Significance. A well-supported demonstration that CNN-based encoding yields measurable gains in accuracy or runtime over standard FBSNN without problem-specific tuning would constitute a useful algorithmic contribution to deep-learning solvers for high-dimensional PDEs. At present the absence of quantitative error metrics, convergence studies, or direct comparisons leaves the practical significance unclear.
major comments (2)
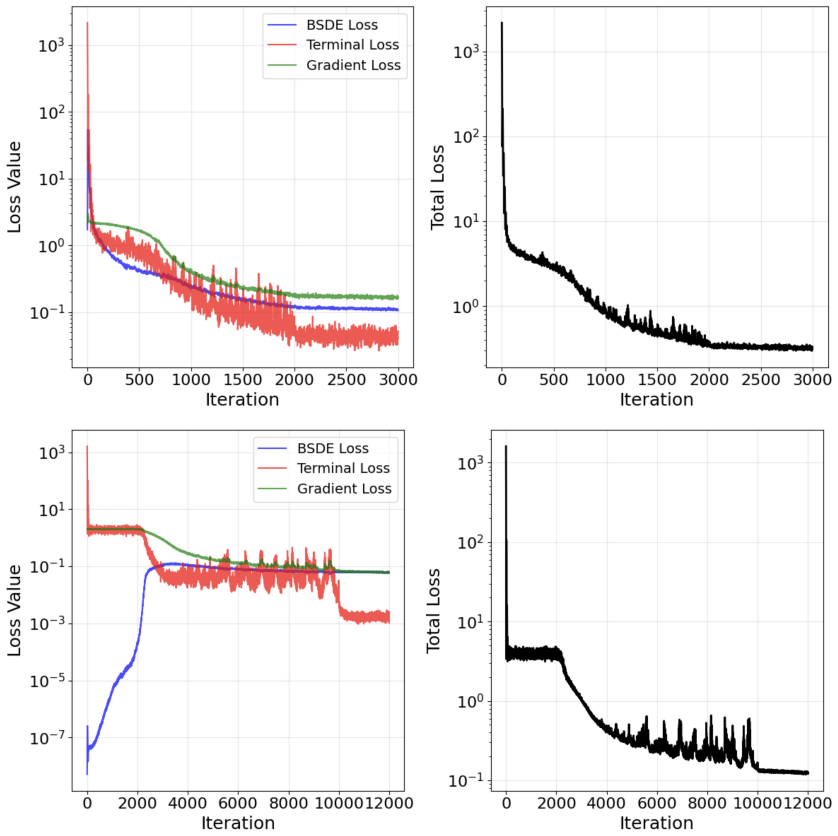
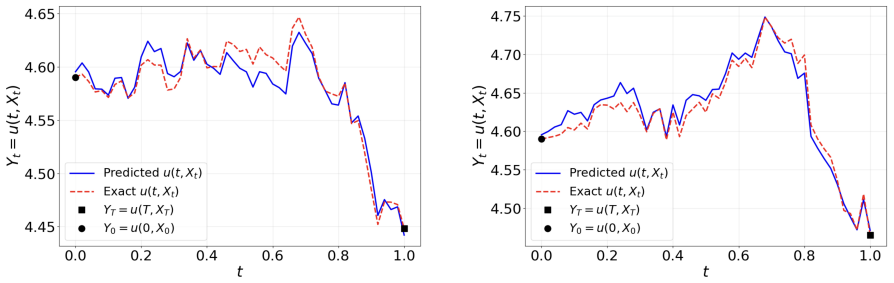
- [Abstract] Abstract: the assertion that the encoded FBSNN 'provides a simple yet effective extension' and 'approximates BSDEs more efficiently' is unsupported by any error tables, convergence rates, runtime figures, or implementation details for the two benchmark cases.
- [Abstract] Abstract: the encoding of points in R^{d+1} (d ≫ 1) as 2-D image tensors with multi-channel stacking necessarily imposes an artificial grid structure and local receptive fields; no invariance argument, approximation analysis, or ablation study is supplied to show that this inductive bias aligns with the generator of the BSDE rather than introducing bias.
minor comments (1)
- The abstract would be strengthened by a single sentence indicating the concrete reshaping or padding rule used to map (t, x) to the image tensor.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We address the two major comments point by point below. Where the manuscript can be strengthened by additional quantitative evidence or discussion, we commit to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the encoded FBSNN 'provides a simple yet effective extension' and 'approximates BSDEs more efficiently' is unsupported by any error tables, convergence rates, runtime figures, or implementation details for the two benchmark cases.
Authors: The full manuscript contains numerical experiments on the high-dimensional Black-Scholes-Barenblatt and Hamilton-Jacobi-Bellman equations that illustrate the performance of the encoded FBSNN relative to the vanilla FBSNN. To make these claims fully supported in the abstract and to facilitate direct comparison, we will add explicit error tables, convergence plots, and runtime figures in a revised version, including implementation details such as network architectures and training hyperparameters. revision: yes
-
Referee: [Abstract] Abstract: the encoding of points in R^{d+1} (d ≫ 1) as 2-D image tensors with multi-channel stacking necessarily imposes an artificial grid structure and local receptive fields; no invariance argument, approximation analysis, or ablation study is supplied to show that this inductive bias aligns with the generator of the BSDE rather than introducing bias.
Authors: The encoding step is introduced precisely to enrich features and balance spatial-temporal information through convolutional processing, which empirically improves accuracy on the tested benchmarks. We agree that an ablation study isolating the contribution of the tensor encoding and CNN layers would strengthen the paper and will include such a study in the revision. A complete theoretical invariance or approximation analysis of the induced bias is beyond the scope of the current algorithmic contribution, but we will expand the discussion section to address the alignment of the inductive bias with the BSDE generator based on the observed numerical behavior. revision: partial
Circularity Check
No significant circularity; algorithmic extension is self-contained
full rationale
The paper presents the encoded FBSNN as a direct algorithmic modification of vanilla FBSNN: input coordinates are reshaped into multi-channel tensors and fed to CNNs to balance spatial-temporal features. No derivation chain is claimed that reduces a target result to fitted parameters by construction, nor does any load-bearing premise rest on self-citation of an unverified uniqueness theorem or ansatz. Validation occurs on independent benchmark PDEs (Black-Scholes-Barenblatt, Hamilton-Jacobi-Bellman) whose solutions are known externally. The central claim therefore remains an empirical proposal rather than a tautological re-expression of its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pardoux, S
E. Pardoux, S. Peng, Adapted solution of a backward stochastic differential equation, Systems & control letters 14 (1) (1990) 55–61
1990
-
[2]
Peng, Backward stochastic differential equations and applications to optimal control, Applied Mathematics and Optimization 27 (2) (1993) 125–144
S. Peng, Backward stochastic differential equations and applications to optimal control, Applied Mathematics and Optimization 27 (2) (1993) 125–144
1993
-
[3]
El Karoui, S
N. El Karoui, S. Peng, M. C. Quenez, Backward stochastic differential equations in finance, Mathematical finance 7 (1) (1997) 1–71
1997
-
[4]
El Karoui, S
N. El Karoui, S. Hamadène, A. Matoussi, Backward stochastic differential equations and applications (2008)
2008
-
[5]
Pardoux, S
E. Pardoux, S. Tang, Forward-backward stochastic differential equations and quasilinear parabolic pdes, Probability theory and related fields 114 (2) (1999) 123–150
1999
-
[6]
Cheridito, H
P. Cheridito, H. M. Soner, N. Touzi, N. Victoir, Second-order backward stochastic dif- ferential equations and fully nonlinear parabolic pdes, Communications on Pure and Applied Mathematics 60 (7) (2007) 1081–1110
2007
-
[7]
LeCun, Y
Y. LeCun, Y. Bengio, G. Hinton, Deep learning, nature 521 (7553) (2015) 436–444
2015
-
[8]
J. Han, A. Jentzen, et al., Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations, Communications in mathematics and statistics 5 (4) (2017) 349–380
2017
-
[9]
J. Han, A. Jentzen, W. E, Solving high-dimensional partial differential equations using deep learning, Proceedings of the National Academy of Sciences 115 (34) (2018) 8505– 8510. 18
2018
-
[10]
C. Beck, W. E, A. Jentzen, Machine learning approximation algorithms for high- dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations, Journal of Nonlinear Science 29 (4) (2019) 1563–1619
2019
-
[11]
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations, arXiv preprint arXiv:1711.10561
-
[12]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics informed deep learning (part ii): Data-driven discovery of nonlinear partial differential equations, ArXiv
-
[13]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707
2019
-
[14]
M. Raissi, Forward–backward stochastic neural networks: deep learning of high- dimensional partial differential equations, in: Peter Carr Gedenkschrift: Research Ad- vances in Mathematical Finance, World Scientific, 2024, pp. 637–655
2024
-
[15]
J. Han, J. Long, Convergence of the deep bsde method for coupled fbsdes, Probability, Uncertainty and Quantitative Risk 5 (1) (2020) 5
2020
-
[16]
W. Wang, J. Wang, J. Li, F. Gao, Y. Fu, Z. Ye, Deep learning numerical methods for high-dimensional quasilinear pides and coupled fbsdes with jumps, SIAM Journal on Scientific Computing 47 (3) (2025) C706–C737
2025
-
[17]
W. Cai, S. Fang, T. Zhou, Soc-martnet: A martingale neural network for the hamilton– jacobi–bellman equation without explicit in stochastic optimal controls, SIAM Journal on Scientific Computing 47 (4) (2025) C795–C819
2025
- [18]
-
[19]
Peng, et al., A nonlinear feynman-kac formula and applications, in: Proceedings of Symposium of System Sciences and Control Theory, World Scientific, 1992, pp
S. Peng, et al., A nonlinear feynman-kac formula and applications, in: Proceedings of Symposium of System Sciences and Control Theory, World Scientific, 1992, pp. 173–184. 19
1992
-
[20]
K. D. B. J. Adam, et al., A method for stochastic optimization, arXiv preprint arXiv:1412.6980 1412 (6)
work page internal anchor Pith review arXiv
-
[21]
VOLATILITIES, Pricing and hedging derivative securities in markets with uncertain volatilities
U. VOLATILITIES, Pricing and hedging derivative securities in markets with uncertain volatilities
-
[22]
G. H. Meyer, The black scholes barenblatt equation for options with uncertain volatility and its application to static hedging, International Journal of Theoretical and Applied Finance 9 (05) (2006) 673–703
2006
-
[23]
J. Yong, X. Y. Zhou, Stochastic controls: Hamiltonian systems and HJB equations, Vol. 43, Springer Science & Business Media, 1999. Appendix A. Neural Network Structures Fig.A.6 illustrates the network architecture for for the case where the encoding dimension is set to20×20. First, the initial convolutional layer expands the input image of two channels to...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.