Recognition: unknown
From Insight to Action: A Novel Framework for Interpretability-Guided Data Selection in Large Language Models
Pith reviewed 2026-05-07 16:24 UTC · model grok-4.3
The pith
Selecting training data that activates a model's internal causal task features improves fine-tuning performance while using less data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
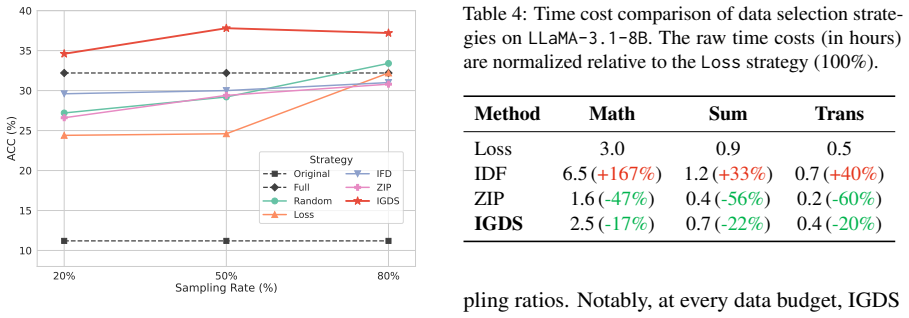
IGDS identifies causal task features in LLMs through frequency recall and interventional filtering, selects Feature-Resonant Data that maximally activates these features, and demonstrates that fine-tuning on this subset yields superior results, such as surpassing full-dataset fine-tuning by 17.4% on math reasoning for Gemma-2-2B using only 50% of the data, while showing a positive correlation between feature amplification and performance gains.
What carries the argument
Interpretability-Guided Data Selection (IGDS), which identifies causal task features via frequency recall and interventional filtering and selects data that resonates with those features to guide fine-tuning.
If this is right
- IGDS achieves higher performance than full data fine-tuning on mathematical reasoning tasks with half the data.
- It outperforms data selection baselines focused on quality and diversity across multiple tasks.
- Feature amplification correlates positively with task performance improvements.
- The method applies to various models including Gemma-2, LLaMA-3.1, and Qwen3 for reasoning, summarization, and translation.
Where Pith is reading between the lines
- Current fine-tuning may often include data that does not engage the model's causal features for the target task, leading to inefficiencies.
- Extending this to other interpretability techniques could further refine data selection strategies.
- Such approaches might lower the computational and data costs of adapting large models to new tasks.
- Validating the causality assumption through more controlled interventions would strengthen the framework.
Load-bearing premise
The identified internal features are causal for the model's performance on the downstream task, and selecting data to activate them will improve training outcomes.
What would settle it
Running the IGDS method on a held-out task or model and finding that the selected data performs no better than a random subset of the same size, or that feature activation levels do not predict performance gains.
Figures






read the original abstract
While mechanistic interpretability tools like Sparse Autoencoders (SAEs) can uncover meaningful features within Large Language Models (LLMs), a critical gap remains in transforming these insights into practical actions for model optimization. We bridge this gap with the hypothesis that data selection guided by a model's internal task features is a effective training strategy. Inspired by this, we propose Interpretability-Guided Data Selection (IGDS), a framework that first identifies these causal task features through frequency recall and interventional filtering, then selects ``Feature-Resonant Data'' that maximally activates task features for fine-tuning. We validate IGDS on mathematical reasoning, summarization, and translation tasks within Gemma-2, LLaMA-3.1, and Qwen3 models. Our experiments demonstrate exceptional data efficiency: on the Math task, IGDS surpasses full-dataset fine-tuning by a remarkable 17.4% on Gemma-2-2B while using only 50% of the data, and outperforms established baselines focused on data quality and diversity. Analysis confirms a strong positive correlation between feature amplification and task performance improvement. IGDS thus provides a direct and effective framework to enhance LLMs by leveraging their internal mechanisms, validating our core hypothesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Interpretability-Guided Data Selection (IGDS), a framework that uses Sparse Autoencoders to identify causal task features in LLMs via frequency recall and interventional filtering, then selects 'Feature-Resonant Data' that maximally activates those features for fine-tuning. It claims this yields superior data efficiency and performance on math reasoning, summarization, and translation tasks across Gemma-2, LLaMA-3.1, and Qwen3 models, including a 17.4% gain over full-dataset fine-tuning on the Math task for Gemma-2-2B with only 50% of the data, while outperforming data-quality and diversity baselines, supported by a reported positive correlation between feature amplification and accuracy improvement.
Significance. If the empirical claims hold after addressing controls and statistical rigor, the work would be significant for bridging mechanistic interpretability tools like SAEs to concrete, actionable improvements in LLM training efficiency. It offers a hypothesis-driven approach to data selection that could reduce computational costs while enhancing performance, and provides initial evidence linking internal feature activation to downstream gains, which may inspire further interpretability-guided optimization methods.
major comments (2)
- [Abstract] Abstract and experimental results: the headline 17.4% improvement over full-dataset fine-tuning (and outperformance of baselines) is presented without error bars, statistical significance tests, ablation details, or explicit baseline definitions, rendering the quantitative claims difficult to assess for robustness or reproducibility.
- [Method and Experiments] Method and experiments: the central hypothesis that the identified task features are causal (rather than the gains arising from any high-activation data selection) is load-bearing but unsupported by necessary controls. No ablation is reported that replaces the frequency-recall + interventional features with (a) randomly selected SAE features of matched activation strength or (b) features from a non-interventional baseline; without this, the performance delta cannot be attributed specifically to the claimed causal mechanism.
minor comments (3)
- [Method] The precise algorithmic steps for 'frequency recall' and 'interventional filtering' are described at a high level; adding pseudocode, hyperparameter values, or a worked example would improve reproducibility.
- [Experiments] Implementation details for the data-quality and diversity baselines (e.g., exact selection criteria, model sizes, training hyperparameters) are not fully specified, hindering direct comparison.
- The manuscript would benefit from a limitations section discussing potential failure modes of the interventional filtering step and generalizability beyond the three tasks tested.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments. We address each major comment below and describe the revisions we will incorporate to improve the rigor and clarity of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the headline 17.4% improvement over full-dataset fine-tuning (and outperformance of baselines) is presented without error bars, statistical significance tests, ablation details, or explicit baseline definitions, rendering the quantitative claims difficult to assess for robustness or reproducibility.
Authors: We agree that the abstract's presentation of the 17.4% improvement would benefit from greater statistical transparency. In the revised manuscript we will report error bars computed over multiple random seeds, include the results of statistical significance tests, expand the description of all ablations, and provide explicit definitions for every baseline. These additions will be reflected both in the abstract and in the main experimental section. revision: yes
-
Referee: [Method and Experiments] Method and experiments: the central hypothesis that the identified task features are causal (rather than the gains arising from any high-activation data selection) is load-bearing but unsupported by necessary controls. No ablation is reported that replaces the frequency-recall + interventional features with (a) randomly selected SAE features of matched activation strength or (b) features from a non-interventional baseline; without this, the performance delta cannot be attributed specifically to the claimed causal mechanism.
Authors: The referee correctly notes that additional controls are required to isolate the contribution of our frequency-recall plus interventional-filtering procedure. We will add two new ablations to the experiments: (a) substitution of the selected features with randomly chosen SAE features that exhibit matched activation strength, and (b) replacement of the interventional features with those obtained from a purely frequency-based (non-interventional) selection. Performance deltas under these controls will be reported alongside the original results to strengthen the causal attribution. revision: yes
Circularity Check
No circularity: empirical results independent of input definitions
full rationale
The paper advances an empirical framework (IGDS) that identifies task features via frequency recall and interventional filtering, then selects resonant data for fine-tuning. All headline performance numbers (e.g., 17.4 % gain on Gemma-2-2B Math with 50 % data) are reported outcomes of downstream training experiments on held-out test sets, not quantities that reduce by construction to the feature-identification procedure itself. No equations, parameter fits, or self-citations are invoked to derive the accuracy deltas; the central claim therefore remains falsifiable by external replication and does not collapse into self-definition or renamed inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Features uncovered by sparse autoencoders via frequency recall and interventional filtering are causal for the model's task performance.
Reference graph
Works this paper leans on
-
[1]
Alexander Bukharin, Shiyang Li, Zhengyang Wang, Jingfeng Yang, Bing Yin, Xian Li, Chao Zhang, Tuo Zhao, and Haoming Jiang
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Alexander Bukharin, Shiyang Li, Zhengyang Wang, Jingfeng Yang, Bing Yin, Xian Li, Chao Zhang, Tuo Zhao, and Haoming Jiang. 2024. Data diversity mat- ters for robust instruction tuning. InFindings of the Association for Computat...
2024
-
[2]
InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
AlpaGasus: Training a better alpaca with fewer data. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang
2024
-
[3]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
DialogSum: A real-life scenario dialogue sum- marization dataset. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 5062–5074. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600. Ruixuan...
work page internal anchor Pith review arXiv 2021
-
[4]
Transcoders find interpretable llm feature cir- cuits.Advances in Neural Information Processing Systems, 37:24375–24410. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger B. Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, a...
work page internal anchor Pith review arXiv 2022
-
[5]
InForty-second International Conference on Machine Learning
SAE-V: Interpreting multimodal models for enhanced alignment. InForty-second International Conference on Machine Learning. Yin Lu, Xuening Zhu, Tong He, and David Wipf. 2025. Sparse autoencoders, again? InForty-second Inter- national Conference on Machine Learning. Jingcheng Niu, Andrew Liu, Zining Zhu, and Gerald Penn. 2024. What does the knowledge neuro...
work page internal anchor Pith review arXiv 2025
-
[6]
arXiv preprint arXiv:2410.09335 , year=
Scaling monosemanticity: Extracting inter- pretable features from Claude 3 Sonnet. Transformer Circuits Thread. Xinwei Wu, Weilong Dong, Shaoyang Xu, and Deyi Xiong. 2024. Mitigating privacy seesaw in large lan- guage models: Augmented privacy neuron editing via activation patching. InFindings of the Associa- tion for Computational Linguistics ACL 2024, p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.