Recognition: unknown
Combating Visual Neglect and Semantic Drift in Large Multimodal Models for Enhanced Cross-Modal Retrieval
Pith reviewed 2026-05-07 16:52 UTC · model grok-4.3
The pith
Large multimodal models can fix visual neglect by guiding attention to salient subjects in images for better retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
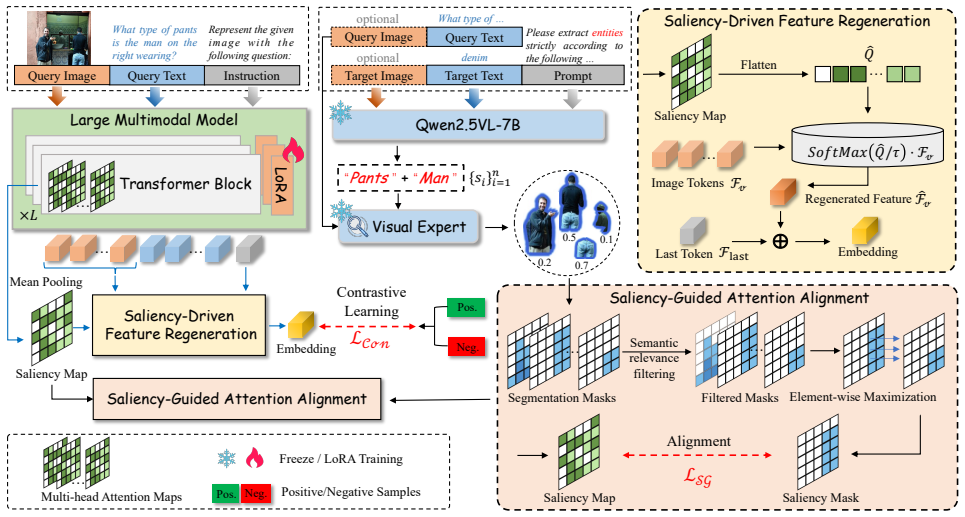
The paper claims that subject-level saliency modeling overcomes semantic alignment deviation and visual modality neglect in large multimodal models. SSA-ME uses LMMs together with visual experts to produce saliency maps over image-text pairs, applies a saliency-guided objective that forces cross-modal attention to match semantically meaningful regions, and adds a feature regeneration module that recalibrates visual features according to the maps. This produces embeddings that integrate modalities more coherently and yields state-of-the-art results on the MMEB benchmark.
What carries the argument
The SSA-ME framework's saliency-guided objective and feature regeneration module, which derive and apply saliency maps to enforce alignment between text and specific visual subjects rather than whole samples.
If this is right
- Models localize text-referred regions in images more accurately during retrieval.
- Visual knowledge is utilized more fully without defaulting to textual shortcuts.
- Retrieval performance reaches state-of-the-art levels on the MMEB benchmark.
- Model decisions become more interpretable through explicit saliency visualizations.
Where Pith is reading between the lines
- The same saliency mechanism could be tested on visual question answering to see whether focusing on relevant subjects reduces irrelevant answers.
- Balancing modalities through regeneration may help limit hallucinations when models generate descriptions of complex scenes.
- Extending the approach to video would require adapting saliency maps to track subjects across frames to address temporal drift.
Load-bearing premise
Saliency maps produced by large multimodal models and visual experts reliably mark semantically coherent subjects without missing key elements or adding new biases.
What would settle it
Running the method on a held-out set of multi-subject images with explicit text references and finding no measurable gain in region localization accuracy or retrieval metrics compared with standard contrastive baselines would show the claim is incorrect.
Figures



read the original abstract
Despite significant progress in Unified Multimodal Retrieval (UMR) powered by Large Multimodal Models (LMMs), existing embedding methods primarily focus on sample-level objectives via contrastive learning while overlooking the crucial subject-level semantics. This limitation hinders the model's ability to group semantically coherent subjects in complex multimodal queries, manifesting as semantic alignment deviation--where models fail to accurately localize salient text-referred regions in visual content. Moreover, without explicit guidance to model salient visual subjects, LMMs tend to over-rely on textual cues, resulting in visual modality neglect and suboptimal utilization of visual knowledge. To this end, we propose Salient Subject-Aware Multimodal Embedding (SSA-ME), a novel framework designed to enhance fine-grained representation learning through saliency-aware modeling. SSA-ME leverages LMMs and visual experts to identify and emphasize salient visual concepts in image-text pairs, and introduces a saliency-guided objective to better align cross-modal attention with semantically meaningful regions. Additionally, a feature regeneration module recalibrates visual features based on the derived saliency maps, ensuring a balanced and semantically coherent integration across modalities. Extensive experiments show that our method achieves state-of-the-art performance on the MMEB benchmark, demonstrating that incorporating subject-level modeling substantially improves multimodal retrieval. Comprehensive qualitative analyses further illustrate the interpretability and effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Salient Subject-Aware Multimodal Embedding (SSA-ME) to address visual modality neglect and semantic alignment deviation in large multimodal models (LMMs) for unified multimodal retrieval. It generates saliency maps for salient visual subjects in image-text pairs using LMMs plus visual experts, introduces a saliency-guided objective to align cross-modal attention with semantically meaningful regions, and adds a feature regeneration module to recalibrate visual features for balanced integration. Extensive experiments are reported to achieve state-of-the-art performance on the MMEB benchmark, with qualitative analyses supporting interpretability.
Significance. If the gains hold after addressing validation concerns, the work could meaningfully advance fine-grained multimodal retrieval by shifting focus from sample-level contrastive objectives to explicit subject-level semantics. This has potential to reduce text over-reliance in LMMs and improve localization in complex queries, with the saliency-based approach offering a practical path to better visual knowledge utilization.
major comments (2)
- Abstract and §3 (Method description): The saliency maps are produced by the same class of LMMs that the paper premises suffer from visual neglect and text over-reliance. This introduces a bootstrap/circularity risk where the corrective saliency-guided objective and feature regeneration module may propagate the very biases they target. The manuscript must provide independent validation (e.g., overlap metrics with human-annotated salient regions or comparisons to non-LMM experts) to show the maps reliably isolate semantically coherent subjects; without this, MMEB gains cannot be confidently attributed to subject-level modeling rather than regularization or capacity.
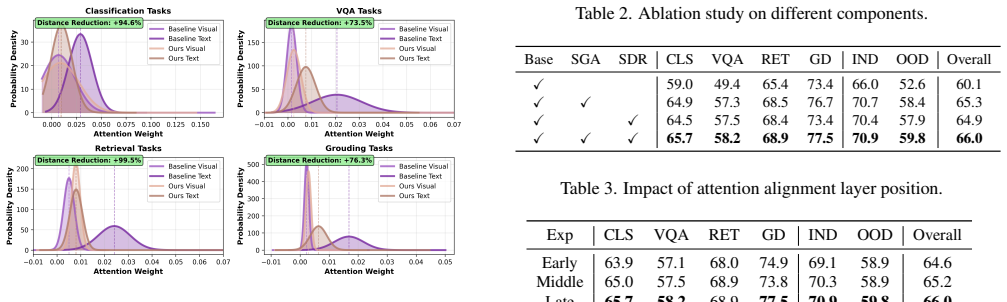
- §4 (Experiments): The SOTA claim on MMEB requires supporting evidence including full baseline comparisons, ablation results isolating the saliency-guided objective and feature regeneration module, dataset statistics, and error bars or significance tests. The abstract provides none of these, so the central empirical claim remains unverified and load-bearing for the paper's contribution.
minor comments (1)
- Abstract: The phrase 'semantic alignment deviation' is used without a formal definition or reference to a specific metric/equation; adding a precise characterization would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We will revise the manuscript to address the concerns about saliency map validation and to better highlight the supporting evidence for our empirical claims.
read point-by-point responses
-
Referee: Abstract and §3 (Method description): The saliency maps are produced by the same class of LMMs that the paper premises suffer from visual neglect and text over-reliance. This introduces a bootstrap/circularity risk where the corrective saliency-guided objective and feature regeneration module may propagate the very biases they target. The manuscript must provide independent validation (e.g., overlap metrics with human-annotated salient regions or comparisons to non-LMM experts) to show the maps reliably isolate semantically coherent subjects; without this, MMEB gains cannot be confidently attributed to subject-level modeling rather than regularization or capacity.
Authors: We acknowledge the referee's valid concern regarding potential circularity. Our framework combines LMMs with independent visual experts specifically for saliency map generation to reduce reliance on LMMs alone. In the revised manuscript, we will add explicit independent validation by comparing the generated saliency maps against outputs from non-LMM visual saliency models and reporting quantitative overlap metrics (e.g., IoU or F1 scores) with human-annotated regions where such annotations exist in the datasets. This will strengthen the attribution of gains to subject-level semantics. revision: yes
-
Referee: §4 (Experiments): The SOTA claim on MMEB requires supporting evidence including full baseline comparisons, ablation results isolating the saliency-guided objective and feature regeneration module, dataset statistics, and error bars or significance tests. The abstract provides none of these, so the central empirical claim remains unverified and load-bearing for the paper's contribution.
Authors: The full experimental section (§4) already contains comprehensive baseline comparisons on MMEB, ablation studies that isolate the saliency-guided objective and feature regeneration module, dataset statistics, and results with error bars from multiple runs for significance. To improve clarity and directly address the abstract's brevity, we will revise the abstract to reference these supporting elements and ensure all tables explicitly include error bars and ablation breakdowns. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and available text describe a proposed SSA-ME framework that generates saliency maps via LMMs plus visual experts, then applies a saliency-guided objective and feature regeneration module. No equations, derivations, fitted parameters presented as predictions, or self-citations appear in the provided content. The central claim is an empirical SOTA result on MMEB, which does not reduce to its inputs by construction. The bootstrap concern (LMMs with neglect producing corrective maps) is a potential modeling assumption flaw but does not match any enumerated circularity pattern with a specific reduction to self-inputs. The derivation chain is self-contained as a novel empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do more negative samples necessarily hurt in contrastive learn- ing? InInternational conference on machine learning, pages 1101–1116
Pranjal Awasthi, Nishanth Dikkala, and Pritish Kamath. Do more negative samples necessarily hurt in contrastive learn- ing? InInternational conference on machine learning, pages 1101–1116. PMLR, 2022. 1
2022
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[3]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Al- berto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InICCV, 2023. 2
2023
-
[4]
Gaussian blur and relative edge response.arXiv preprint arXiv:2301.00856, 2023
Austin C Bergstrom, David Conran, and David W Messinger. Gaussian blur and relative edge response.arXiv preprint arXiv:2301.00856, 2023. 4
-
[5]
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. Can pre-trained vision and language models answer visual information-seeking questions? InProceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, pages 14948–14968, 2023. 2
2023
-
[6]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023. 6
2023
-
[7]
Mitigating Hallucination in Large Vision-Language Models via Adaptive Attention Calibration
Mehrdad Fazli, Bowen Wei, Ahmet Sari, and Ziwei Zhu. Mitigating hallucination in large vision-language models via adaptive attention calibration.arXiv preprint arXiv:2505.21472, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19520–19529, 2025. 3
2025
-
[9]
Simcse: Sim- ple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Sim- ple contrastive learning of sentence embeddings. InProceed- ings of the 2021 conference on empirical methods in natural language processing, pages 6894–6910, 2021. 2
2021
-
[10]
Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Wei- dong Cai, and Jiankang Deng. Breaking the modality barrier: Universal embedding learning with multimodal llms.arXiv preprint arXiv:2504.17432, 2025. 6
-
[11]
Pengyue Hou and Xingyu Li. Improving contrastive learning of sentence embeddings with focal-infonce.arXiv preprint arXiv:2310.06918, 2023. 1
-
[12]
Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities
Hexiang Hu, Yi Luan, Yang Chen, Urvashi Khandelwal, Mandar Joshi, Kenton Lee, Kristina Toutanova, and Ming- Wei Chang. Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities. InICCV, 2023. 2
2023
-
[13]
Scaling sentence embeddings with large language models.arXiv preprint arXiv:2307.16645, 2023
Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang. Scaling sentence embeddings with large language models.arXiv preprint arXiv:2307.16645, 2023. 3
-
[14]
arXiv preprint arXiv:2407.12580 , year=
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-v: Universal embeddings with multimodal large language models.arXiv preprint arXiv:2407.12580, 2024. 1, 2, 3, 6
-
[15]
arXiv preprint arXiv:2410.05160 , year=
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160, 2024. 1, 2, 5, 6
-
[16]
Mingi Jung, Saehyung Lee, Eunji Kim, and Sungroh Yoon. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large language models.arXiv preprint arXiv:2502.01419,
-
[17]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025. 3
-
[18]
Fanheng Kong, Jingyuan Zhang, Yahui Liu, Hongzhi Zhang, Shi Feng, Xiaocui Yang, Daling Wang, Yu Tian, Fuzheng Zhang, Guorui Zhou, et al. Modality curation: Building uni- versal embeddings for advanced multimodal information re- trieval.arXiv preprint arXiv:2505.19650, 2025. 6
-
[19]
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jinsong Su. Llave: Large language and vision embedding models with hardness-weighted contrastive learning.arXiv preprint arXiv:2503.04812, 2025. 1, 2, 6
-
[20]
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding
Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9098–9108, 2025. 2, 3
2025
-
[21]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 2
2022
-
[22]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 6
2023
-
[23]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4015–4025, 2025. 1, 3, 5
2025
-
[24]
Image retrieval on real-life images with pre- trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre- trained vision-and-language models. InICCV, 2021. 2
2021
-
[25]
Zhenghao Liu, Chenyan Xiong, Yuanhuiyi Lv, Zhiyuan Liu, and Ge Yu. Universal vision-language dense retrieval: Learning a unified representation space for multi-modal re- trieval.arXiv preprint arXiv:2209.00179, 2022. 2
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 6 9
2021
-
[27]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[28]
Contrastive learning with hard negative samples,
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Ste- fanie Jegelka. Contrastive learning with hard negative sam- ples.arXiv preprint arXiv:2010.04592, 2020. 1
-
[29]
Genecis: A benchmark for general conditional image similarity
Sagar Vaze, Nicolas Carion, and Ishan Misra. Genecis: A benchmark for general conditional image similarity. In CVPR, 2023. 2
2023
-
[30]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[31]
Uniir: Training and benchmarking universal multimodal information retriev- ers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Training and benchmarking universal multimodal information retriev- ers. InECCV, 2024. 6
2024
-
[32]
Uniir: Train- ing and benchmarking universal multimodal information re- trievers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Train- ing and benchmarking universal multimodal information re- trievers. InEuropean Conference on Computer Vision, pages 387–404. Springer, 2024. 2
2024
-
[33]
Fashion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. InCVPR, 2021. 2
2021
-
[34]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023. 6
2023
-
[35]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. InEuropean Conference on Computer Vision, 2024. 2
2024
-
[36]
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magi- clens: Self-supervised image retrieval with open-ended in- structions.arXiv preprint arXiv:2403.19651, 2024. 6
-
[37]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Gme: Improving universal multimodal retrieval by multimodal llms.arXiv preprint arXiv:2412.16855, 2024. 1, 2
-
[38]
Junjie Zhou, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, Defu Lian, and Yongping Xiong. Megapairs: Massive data synthesis for universal mul- timodal retrieval.arXiv preprint arXiv:2412.14475, 2024. 6 10 Combating Visual Neglect and Semantic Drift in Large Multimodal Models for Enhanced Cross-Modal Retrieval Supplementary Materia...
-
[39]
Find a day-to-day image that looks similar to the provided im- age
Prompting for Salient Subjects Figure A1 illustrates the prompt engineering pipeline for salient subject extraction in our SSA-ME framework. The process begins by constructing a structured input con- taining the query pair(T q, Iq)and positive sample pairs (Tt, It), formatted as a unified sequence following the template:QUERY:<Image q><Text q>; POSITIVE S...
-
[40]
person”,“car
Statistics on Salient Subjects The spatial analysis of salient subject distribution reveals a significant central concentration bias in attention patterns. As shown in the mean attention heatmap, attention intensity peaks around the central coordinates with values reaching 0.9 (bright yellow), gradually decreasing toward the image boundaries to approximat...
-
[41]
The results demonstrate that the superior and robust perfor- mance of our proposed SSA-ME framework
Overall Performance Comparison Table A1 presents a comprehensive performance com- parison across 36 diverse vision-language tasks, where VLM2Vec employs LLaV A-1.6-7B as its base model, while our proposed SSA-ME method is evaluated in two con- figurations: SSA-ME (2B) using Qwen2VL-2B and SSA- ME (7B) using Qwen2VL-7B as base models respectively. The resu...
-
[42]
Impact of the Number of Regenerated Vi- sual Tokens Table A2 presents an ablation study on the impact of the number of regenerated visual tokens, selected based on saliency scores, on multimodal performance. The results reveal a clear positive correlation: performance across all metrics (CLS, VQA, RET, GD, IND, OOD, and Overall) improves substantially as ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.