Recognition: unknown
Exploring Time Conditioning in Diffusion Generative Models from Disjoint Noisy Data Manifolds
Pith reviewed 2026-05-07 16:45 UTC · model grok-4.3
The pith
DDIM can generate high-quality samples without time conditioning once its forward process aligns noisy manifolds with flow-matching trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Successful generation in deterministic samplers arises from the disentanglement of disjoint noisy data manifolds in high-dimensional space. Modifying the forward process of DDIM to make the noisy manifold evolve according to the flow-matching method enables high-quality generation without time conditioning. Class-conditioned synthesis is possible with a class-unconditional denoising model by decoupling classes into distinct time spaces.
What carries the argument
The geometric concentration of noisy data on hyper-cylinder-like manifolds, combined with the alignment of their evolution under a modified DDIM forward process to match flow-matching trajectories.
If this is right
- DDIM achieves high-quality deterministic sampling without time embeddings after the manifold alignment modification.
- Class-conditioned outputs can be produced from an unconditional model by assigning separate time intervals to each class.
- The primary function of time conditioning is to resolve overlaps between noisy manifolds rather than to steer the denoising trajectory.
- High-dimensional geometry explains performance gaps between standard DDIM and flow matching.
- Manifold disentanglement becomes the decisive factor for quality in deterministic generative sampling.
Where Pith is reading between the lines
- Model architectures could drop time-embedding layers entirely if the forward process is adjusted accordingly.
- The same manifold-alignment idea might simplify conditioning requirements in other deterministic generative methods.
- Experiments on higher-resolution or multimodal data would test whether the hyper-cylinder structure generalizes.
- Hybrid samplers could be designed that inherit the efficiency of both DDIM and flow matching without added conditioning overhead.
Load-bearing premise
That a simple change to DDIM's forward process can make its noisy data manifolds evolve exactly like those in flow matching, and that this change alone is enough to allow successful generation without time conditioning.
What would settle it
Implement the modified DDIM forward process, train on CIFAR-10 or ImageNet, and measure FID or sample quality against both standard time-conditioned DDIM and flow matching; substantially worse results would indicate that manifold alignment does not suffice for conditioning-free generation.
Figures


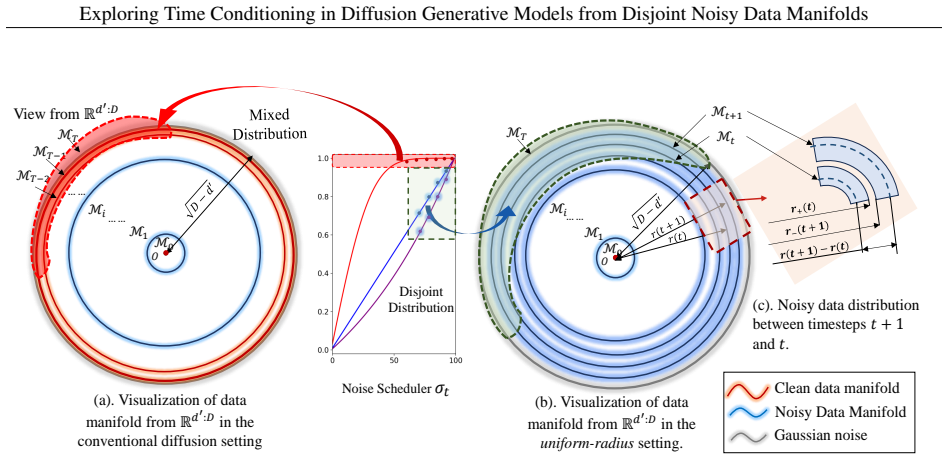

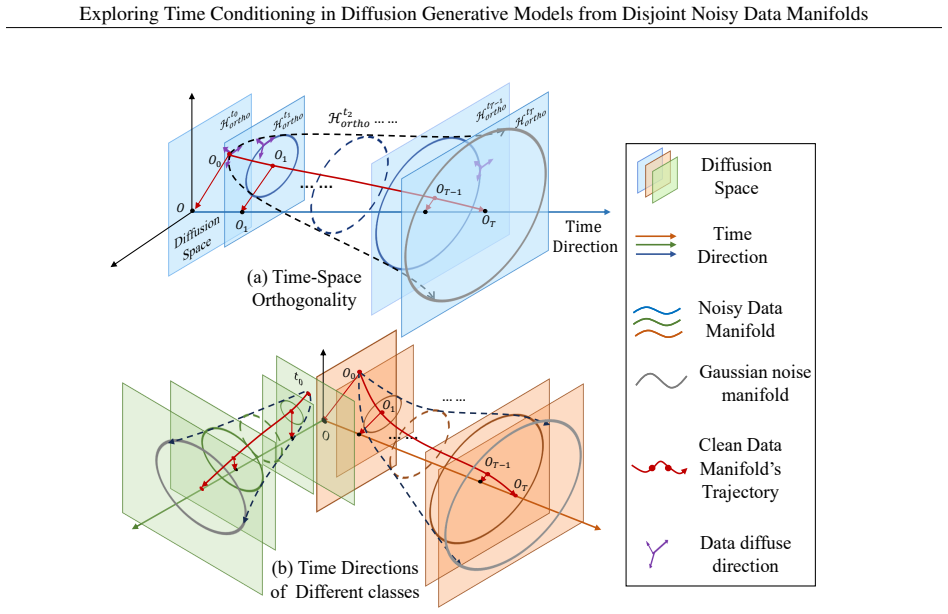



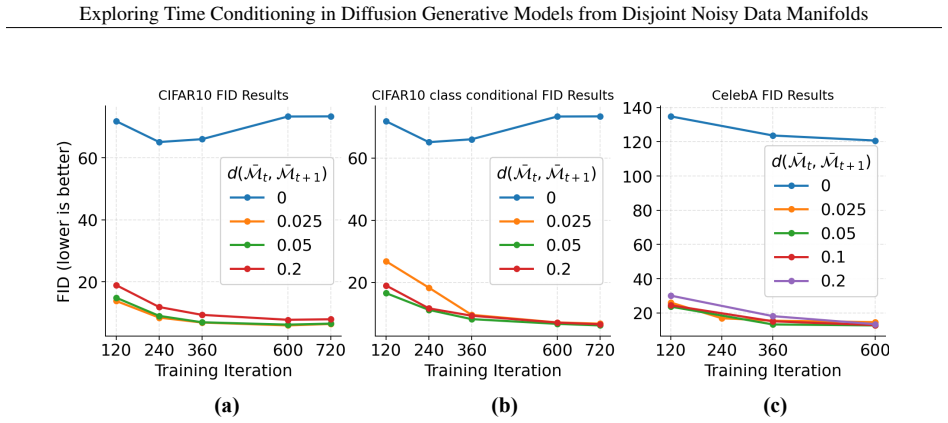
read the original abstract
Practically, training diffusion models typically requires explicit time conditioning to guide the network through the denoising sampling process. Especially in deterministic methods like DDIM, the absence of time conditioning leads to significant performance degradation. However, other deterministic sampling approaches, such as flow matching, can generate high-quality content without this conditioning, raising the question of its necessity. In this work, we revisit the role of time conditioning from a geometric perspective. We analyze the evolution of noisy data distributions under the forward diffusion process and demonstrate that, in high-dimensional spaces, these distributions concentrate on low-dimensional hyper-cylinder-like manifolds embedded within the input space. Successful generation, we argue, stems from the disentanglement of these manifolds in high-dimensional space. Based on this insight, we modify the forward process of DDIM to align the noisy data manifold with the flow-matching approach, proving that DDIM can generate high-quality content without time conditioning, provided the noisy manifold evolves according to the flow-matching method. Additionally, we extend our framework to class-conditioned generation by decoupling classes into distinct time spaces, enabling class-conditioned synthesis with a class-unconditional denoising model. Extensive experiments validate our theoretical analysis and show that high-quality generation is achievable without explicit conditional embeddings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that noisy data distributions under the forward diffusion process concentrate on low-dimensional hyper-cylinder manifolds in high dimensions, and that successful generation requires disentanglement of these manifolds. By modifying the DDIM forward process to align the noisy manifold evolution with flow-matching trajectories, the authors prove that DDIM can achieve high-quality generation without explicit time conditioning. They further extend the framework to class-conditional synthesis by decoupling classes into distinct time spaces, allowing a class-unconditional denoiser to perform conditional generation. The claims are supported by geometric analysis and extensive experiments.
Significance. If the geometric alignment argument holds and the modification enables time-unconditional DDIM without implicit recovery of noise levels, the result would clarify the necessity of time embeddings in deterministic samplers and could simplify model architectures by removing conditioning inputs. The class-decoupling extension offers a novel way to achieve conditional generation with unconditional networks. The work builds on the contrast between DDIM and flow matching but would benefit from stronger separation between the alignment construction and the claimed performance gains.
major comments (3)
- [theoretical analysis of noisy manifold evolution] The central sufficiency claim—that manifold alignment with flow-matching trajectories is enough for a time-independent network to learn the reverse process—lacks a quantitative bound on the rate of concentration onto hyper-cylinders in finite dimensions. Without such a bound (e.g., in the geometric analysis section), it remains possible that the denoiser still requires implicit time information recovered from the data distribution itself.
- [DDIM forward-process modification] The modification to the DDIM forward process is defined precisely by the requirement that the noisy manifold follows flow-matching trajectories. This construction makes it difficult to assess whether the reported performance gains are independent of the flow-matching prior or whether the alignment simply transfers the conditioning burden; a clearer separation between the geometric condition and the learned vector field is needed.
- [class-conditioned synthesis framework] The extension to class-conditional generation via distinct time spaces for each class assumes that the class manifolds remain sufficiently separated under the modified dynamics. No analysis is provided on the required separation margin or on whether the unconditional denoiser can reliably disambiguate classes without explicit class embeddings during sampling.
minor comments (2)
- [abstract and experimental validation] The abstract states that 'extensive experiments validate our theoretical analysis' but does not specify the datasets, baselines, or controls used to isolate the effect of removing time conditioning; adding these details would strengthen the experimental section.
- [method] Notation for the modified forward process and the resulting reverse vector field should be introduced with explicit equations early in the method section to avoid ambiguity when comparing to standard DDIM and flow matching.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our paper. We have carefully considered each major comment and provide point-by-point responses below, along with indications of revisions to the manuscript.
read point-by-point responses
-
Referee: The central sufficiency claim—that manifold alignment with flow-matching trajectories is enough for a time-independent network to learn the reverse process—lacks a quantitative bound on the rate of concentration onto hyper-cylinders in finite dimensions. Without such a bound (e.g., in the geometric analysis section), it remains possible that the denoiser still requires implicit time information recovered from the data distribution itself.
Authors: We thank the referee for this observation. Our geometric analysis establishes that noisy data distributions concentrate on low-dimensional hyper-cylinder manifolds in high dimensions, with the DDIM modification ensuring alignment to flow-matching trajectories. This alignment enables the time-independent network to learn the reverse process, as supported by our theoretical construction and ablation studies demonstrating performance degradation without alignment. While an explicit quantitative bound on concentration rates for finite dimensions is not derived, the argument relies on the asymptotic high-dimensional regime, which is standard for such analyses. We have added a clarifying discussion in the revised geometric analysis section and a note in the conclusions identifying finite-dimensional bounds as future work. The experiments indicate that implicit time recovery is not occurring, as the unconditional model matches conditioned baselines only under the aligned dynamics. revision: partial
-
Referee: The modification to the DDIM forward process is defined precisely by the requirement that the noisy manifold follows flow-matching trajectories. This construction makes it difficult to assess whether the reported performance gains are independent of the flow-matching prior or whether the alignment simply transfers the conditioning burden; a clearer separation between the geometric condition and the learned vector field is needed.
Authors: The DDIM modification is introduced precisely to enforce the noisy manifold to evolve along flow-matching trajectories, thereby removing the necessity for explicit time conditioning in the denoiser. The performance improvements arise directly from this geometric alignment rather than from inheriting flow-matching properties wholesale. To clarify the separation, we have revised the relevant sections to distinguish the geometric alignment condition (which dictates the forward process) from the learned vector field (produced by the time-independent network). Additional ablations in the experiments section compare the aligned DDIM against unmodified flow matching and standard DDIM, confirming that the gains stem from enabling unconditional training under the modified dynamics and are not a mere transfer of conditioning burden. revision: yes
-
Referee: The extension to class-conditional generation via distinct time spaces for each class assumes that the class manifolds remain sufficiently separated under the modified dynamics. No analysis is provided on the required separation margin or on whether the unconditional denoiser can reliably disambiguate classes without explicit class embeddings during sampling.
Authors: By mapping each class to a distinct time space under the modified forward process, the class manifolds evolve separately, allowing the class-unconditional denoiser to perform conditional generation by leveraging the time parameter as an implicit class indicator during sampling. We validate this through extensive class-conditional experiments showing high-quality synthesis without class embeddings. We agree that a formal analysis of the separation margin would strengthen the theoretical foundation. In the revised manuscript, we have expanded the discussion of the class-conditional framework to include empirical observations of manifold separation in the learned representations and have noted the derivation of explicit margins as an avenue for future work. revision: partial
Circularity Check
Modification aligning DDIM forward process to flow-matching makes time-unconditional generation hold by construction
specific steps
-
self definitional
[Abstract]
"we modify the forward process of DDIM to align the noisy data manifold with the flow-matching approach, proving that DDIM can generate high-quality content without time conditioning, provided the noisy manifold evolves according to the flow-matching method"
The 'proof' is obtained by redefining the forward dynamics to satisfy the flow-matching evolution condition; the absence of time conditioning then holds tautologically because flow-matching trajectories are already known to support unconditional generation. The result is equivalent to the input modification rather than an independent prediction from the hyper-cylinder manifold analysis.
-
fitted input called prediction
[Abstract]
"Additionally, we extend our framework to class-conditioned generation by decoupling classes into distinct time spaces, enabling class-conditioned synthesis with a class-unconditional denoising model"
Class separation is achieved by assigning distinct time spaces, which directly encodes the conditioning information into the manifold evolution; the unconditional denoiser then 'works' because the time-space decoupling has already injected the class signal by construction.
full rationale
The paper's central derivation modifies the DDIM forward process explicitly to force alignment between noisy data manifolds and flow-matching trajectories, then concludes that time conditioning becomes unnecessary under this alignment. This reduces the 'proof' to a definitional equivalence: the claimed performance without time conditioning follows directly from importing the flow-matching property via the modification, rather than deriving sufficiency from independent geometric analysis or bounds. The class-decoupling extension similarly relies on reparameterizing time spaces to enforce separation. No external verification or quantitative tightness result is supplied to break the construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Noisy data distributions concentrate on low-dimensional hyper-cylinder-like manifolds embedded in high-dimensional input space.
- domain assumption Successful generation stems from the disentanglement of these manifolds.
Reference graph
Works this paper leans on
-
[1]
StarGAN v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. StarGAN v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8188–8197, 2020
2020
-
[2]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE International Conference on Computer Vision, pages 3730–3738, 2015
2015
-
[3]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto,
-
[4]
URLhttps://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. Ieee, 2009
2009
-
[6]
Density-difference estimation.Neural Computation, 25(10):2734–2775, 2013
Masashi Sugiyama, Takafumi Kanamori, Taiji Suzuki, Marthinus Christoffel du Plessis, Song Liu, and Ichiro Takeuchi. Density-difference estimation.Neural Computation, 25(10):2734–2775, 2013. xvii Exploring Time Conditioning in Diffusion Generative Models from Disjoint Noisy Data Manifolds
2013
-
[7]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[8]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265. PMLR, 2015
2015
-
[9]
Thinking in frames: How visual context and test-time scaling empower video reasoning,
Chengzu Li, Zanyi Wang, Jiaang Li, Yi Xu, Han Zhou, Huanyu Zhang, Ruichuan An, Dengyang Jiang, Zhaochong An, Ivan Vuli´c, et al. Thinking in frames: How visual context and test-time scaling empower video reasoning,
-
[10]
URLhttps://arxiv.org/abs/2601.21037. Preprint at https://arxiv.org/abs/2601.21037
-
[11]
Addison-Wesley Professional, 2nd edition, 1995
James Foley, Andries van Dam, Steven Feiner, and John Hughes.Computer Graphics: Principles and Practice in C. Addison-Wesley Professional, 2nd edition, 1995
1995
-
[12]
Dengyang Jiang, Mengmeng Wang, Liuzhuozheng Li, Lei Zhang, Haoyu Wang, Wei Wei, Guang Dai, Yanning Zhang, and Jingdong Wang. No other representation component is needed: Diffusion transformers can pro- vide representation guidance by themselves, 2025. URL https://arxiv.org/abs/2505.02831. Preprint at https://arxiv.org/abs/2505.02831
-
[13]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014
2014
-
[14]
Neural discrete representation learning.Advances in Neural Information Processing Systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[15]
Understanding disentangling in $\beta$-VAE
Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in beta-V AE, 2018. URL https://arxiv.org/abs/1804.03599. Preprint at https://arxiv.org/abs/1804.03599
work page Pith review arXiv 2018
-
[16]
GANs trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[17]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2020. URL https: //arxiv.org/abs/2010.02502. Preprint at https://arxiv.org/abs/2010.02502
work page internal anchor Pith review arXiv 2020
-
[18]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2022. URLhttps://arxiv.org/abs/2210.02747. Preprint at https://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2022
-
[19]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[20]
J. R. Dormand and P. J. Prince. A family of embedded runge-kutta formulae.Journal of Computational and Applied Mathematics, 6(1):19–26, 1980
1980
-
[21]
Diffusion schrödinger bridge with applications to score-based generative modeling
Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion schrödinger bridge with applications to score-based generative modeling. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
2021
-
[22]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
2022
-
[23]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
2022
-
[24]
arXiv preprint arXiv:2405.03150 (2024)
Andrew Melnik, Michal Ljubljanac, Cong Lu, Qi Yan, Weiming Ren, and Helge Ritter. Video diffusion models: A survey, 2024. URLhttps://arxiv.org/abs/2405.03150. Preprint at https://arxiv.org/abs/2405.03150
-
[25]
Archisound: Audio generation with diffusion, 2023
Flavio Schneider. Archisound: Audio generation with diffusion, 2023. URL https://arxiv.org/abs/2301. 13267. Preprint at https://arxiv.org/abs/2301.13267
-
[26]
RefTon: Reference person shot assist virtual Try-on
Liuzhuozheng Li, Yue Gong, Shanyuan Liu, Bo Cheng, Yuhang Ma, Liebucha Wu, Dengyang Jiang, Zanyi Wang, Dawei Leng, and Yuhui Yin. RefVTON: person-to-person try on with additional unpaired visual reference, 2025. URLhttps://arxiv.org/abs/2511.00956. Preprint at https://arxiv.org/abs/2511.00956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Jian Zhu, Shanyuan Liu, Liuzhuozheng Li, Yue Gong, He Wang, Bo Cheng, Yuhang Ma, Liebucha Wu, Xiaoyu Wu, Dawei Leng, et al. FLUX-Makeup: High-fidelity, identity-consistent, and robust makeup transfer via diffusion transformer, 2025. URL https://arxiv.org/abs/2508.05069. Preprint at https://arxiv.org/abs/2508.05069
-
[28]
A survey on generative diffusion models.IEEE Transactions on Knowledge and Data Engineering, 2024
Hanqun Cao, Cheng Tan, Zhangyang Gao, Yilun Xu, Guangyong Chen, Pheng-Ann Heng, and Stan Z Li. A survey on generative diffusion models.IEEE Transactions on Knowledge and Data Engineering, 2024. xviii Exploring Time Conditioning in Diffusion Generative Models from Disjoint Noisy Data Manifolds
2024
-
[29]
Deforming videos to masks: Flow matching for referring video segmentation, 2025
Zanyi Wang, Dengyang Jiang, Liuzhuozheng Li, Sizhe Dang, Chengzu Li, Harry Yang, Guang Dai, Mengmeng Wang, and Jingdong Wang. Deforming videos to masks: Flow matching for referring video segmentation, 2025. URLhttps://arxiv.org/abs/2510.06139. Preprint at https://arxiv.org/abs/2510.06139
-
[30]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[31]
Neural networks and physical systems with emergent collective computational abilities.Proceed- ings of the National Academy of Sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceed- ings of the National Academy of Sciences, 79(8):2554–2558, 1982
1982
-
[32]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, dec 2005
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, dec 2005
2005
-
[33]
Springer, 2013
Bernt Oksendal.Stochastic Differential Equations: An Introduction with Applications. Springer, 2013
2013
-
[34]
Brian D. O. Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12 (3):313–326, 1982. doi:10.1016/0304-4149(82)90051-5
-
[35]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015, pages 234–241. Springer, 2015
2015
-
[36]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
2023
-
[37]
Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[38]
Sliced score matching: A scalable approach to density and score estimation
Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. InUncertainty in Artificial Intelligence, pages 574–584. PMLR, 2020
2020
-
[39]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[40]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale, 2020. URL https://arxiv.org/abs/2010.11929. Preprint at https://arxiv.org/abs/2010.11929
work page internal anchor Pith review arXiv 2020
-
[41]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[42]
Addressing negative transfer in diffusion models.Advances in Neural Information Processing Systems, 36:27199–27222, 2023
Hyojun Go, Yunsung Lee, Seunghyun Lee, Shinhyeok Oh, Hyeongdon Moon, and Seungtaek Choi. Addressing negative transfer in diffusion models.Advances in Neural Information Processing Systems, 36:27199–27222, 2023
2023
-
[43]
Decouple-then-merge: Towards better training for diffusion models, 2024
Qianli Ma, Xuefei Ning, Dongrui Liu, Li Niu, and Linfeng Zhang. Decouple-then-merge: Towards better training for diffusion models, 2024. URL https://arxiv.org/abs/2410.06664. Preprint at https://arxiv.org/abs/2410.06664
-
[44]
Is noise condition- ing necessary for denoising generative models?arXiv preprint arXiv:2502.13129,
Qiao Sun, Zhicheng Jiang, Hanhong Zhao, and Kaiming He. Is noise conditioning necessary for denoising genera- tive models?, 2025. URL https://arxiv.org/abs/2502.13129. Preprint at https://arxiv.org/abs/2502.13129
-
[45]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Image Team, Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, Zhen Li, Zhong-Yu Li, David Liu, Dongyang Liu, Junhan Shi, Qilong Wu, Feng Yu, Chi Zhang, Shifeng Zhang, and Shilin Zhou. Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 202...
work page internal anchor Pith review arXiv 2025
-
[46]
Bingda Tang, Boyang Zheng, Xichen Pan, Sayak Paul, and Saining Xie. Exploring the deep fusion of large language models and diffusion transformers for text-to-image synthesis, 2025. URL https://arxiv.org/abs/ 2505.10046. Preprint at https://arxiv.org/abs/2505.10046
-
[47]
Self-supervised flow matching for scalable multi-modal synthesis, 2026
Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, and Robin Rombach. Self-supervised flow matching for scalable multi-modal synthesis, 2026. URL https://arxiv.org/ abs/2603.06507. Preprint at https://arxiv.org/abs/2603.06507
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models, 2025. URL https: //arxiv.org/abs/2503.20314. Preprint at https://arxiv.org/abs/2503.20314. xix Exploring Time Conditioning in Diffusion Generative Models from Disjoint Noisy Da...
work page internal anchor Pith review arXiv 2025
-
[49]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-First International Conference on Machine Learning, 2024
2024
-
[50]
Improved techniques for training score-based generative models.Advances in Neural Information Processing Systems, 33:12438–12448, 2020
Yang Song and Stefano Ermon. Improved techniques for training score-based generative models.Advances in Neural Information Processing Systems, 33:12438–12448, 2020
2020
-
[51]
Practical blind image denoising via Swin-Conv-UNet and data synthesis.Machine Intelligence Research, 20(6):822–836, 2023
Kai Zhang, Yawei Li, Jingyun Liang, Jiezhang Cao, Yulun Zhang, Hao Tang, Deng-Ping Fan, Radu Timofte, and Luc Van Gool. Practical blind image denoising via Swin-Conv-UNet and data synthesis.Machine Intelligence Research, 20(6):822–836, 2023
2023
-
[52]
Representation learning: A review and new perspectives
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828, 2013
2013
-
[53]
Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
2016
-
[54]
Sample complexity of testing the manifold hypothesis.Advances in Neural Information Processing Systems, 23, 2010
Hariharan Narayanan and Sanjoy Mitter. Sample complexity of testing the manifold hypothesis.Advances in Neural Information Processing Systems, 23, 2010
2010
-
[55]
Caterini, Brendan Leigh Ross, Jesse C Cresswell, and Gabriel Loaiza-Ganem
Bradley CA Brown, Anthony L. Caterini, Brendan Leigh Ross, Jesse C Cresswell, and Gabriel Loaiza-Ganem. Verifying the union of manifolds hypothesis for image data. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[56]
Cheongjae Jang, Yonghyeon Lee, Yung-Kyun Noh, and Frank C. Park. Geometrically regularized autoencoders for non-euclidean data. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[57]
Isometric quotient variational auto-encoders for structure-preserving representation learning.Advances in Neural Information Processing Systems, 36:39075– 39087, 2023
In Huh, Jae Myung Choe, Younggu Kim, Daesin Kim, et al. Isometric quotient variational auto-encoders for structure-preserving representation learning.Advances in Neural Information Processing Systems, 36:39075– 39087, 2023
2023
-
[58]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veli ˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges, 2021. URL https://arxiv.org/abs/2104.13478. Preprint at https://arxiv.org/abs/2104.13478
work page internal anchor Pith review arXiv 2021
-
[59]
Diffusion models are minimax optimal distribution estimators
Kazusato Oko, Shunta Akiyama, and Taiji Suzuki. Diffusion models are minimax optimal distribution estimators. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 26517–26582, 2023
2023
-
[60]
Adaptivity of diffusion models to manifold structures
Rong Tang and Yun Yang. Adaptivity of diffusion models to manifold structures. InInternational Conference on Artificial Intelligence and Statistics, pages 1648–1656. PMLR, 2024
2024
-
[61]
Shallow diffusion networks provably learn hidden low-dimensional structure
Nicholas Matthew Boffi, Arthur Jacot, Stephen Tu, and Ingvar Ziemann. Shallow diffusion networks provably learn hidden low-dimensional structure. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[62]
Cresswell, and Anthony L
Gabriel Loaiza-Ganem, Brendan Leigh Ross, Jesse C. Cresswell, and Anthony L. Caterini. Diagnosing and fixing manifold overfitting in deep generative models.Transactions on Machine Learning Research, 2022
2022
-
[63]
Caterini, and Jesse C
Gabriel Loaiza-Ganem, Brendan Leigh Ross, Rasa Hosseinzadeh, Anthony L. Caterini, and Jesse C. Cresswell. Deep generative models through the lens of the manifold hypothesis: A survey and new connections.Transactions on Machine Learning Research, 2024
2024
-
[64]
Convergence of denoising diffusion models under the manifold hypothesis.Transactions on Machine Learning Research, 2022
Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis.Transactions on Machine Learning Research, 2022
2022
-
[65]
Available: https://arxiv.org/abs/2406.08070
Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. CFG++: Manifold-constrained classifier free guidance for diffusion models, 2024. URL https://arxiv.org/abs/2406.08070. Preprint at https://arxiv.org/abs/2406.08070
-
[66]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems, 2022. URL https://arxiv.org/abs/2209.14687. Preprint at https://arxiv.org/abs/2209.14687
work page internal anchor Pith review arXiv 2022
-
[67]
Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35:25683–25696, 2022
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35:25683–25696, 2022
2022
-
[68]
Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J Zico Kolter, Ruslan Salakhutdinov, et al. Manifold preserving guided diffusion, 2023. URL https://arxiv.org/abs/2311.16424. Preprint at https://arxiv.org/abs/2311.16424. xx Exploring Time Conditioning in Diffusion Generative Models fro...
-
[69]
Understanding guidance scale in diffusion models from a geometric perspective.Transactions on Machine Learning Research, 2026
Zhiyuan Zhan, Liuzhuozheng Li, and Masashi Sugiyama. Understanding guidance scale in diffusion models from a geometric perspective.Transactions on Machine Learning Research, 2026
2026
-
[70]
Manifold learning: What, how, and why.Annual Review of Statistics and Its Application, 11(1):393–417, 2024
Marina Meil˘a and Hanyu Zhang. Manifold learning: What, how, and why.Annual Review of Statistics and Its Application, 11(1):393–417, 2024
2024
-
[71]
Manifold constraint reduces exposure bias in accelerated diffusion sampling
Yuzhe Y AO, Jun Chen, Zeyi Huang, Haonan Lin, Mengmeng Wang, Guang Dai, and Jingdong Wang. Manifold constraint reduces exposure bias in accelerated diffusion sampling. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[72]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URL https://arxiv.org/abs/2207. 12598. Preprint at https://arxiv.org/abs/2207.12598
work page internal anchor Pith review arXiv 2022
-
[73]
Diffusion models beat GANs on image synthesis.Advances in Neural Information Processing Systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis.Advances in Neural Information Processing Systems, 34:8780–8794, 2021
2021
-
[74]
Your diffusion model secretly knows the dimension of the data manifold, 2022
Jan Stanczuk, Georgios Batzolis, Teo Deveney, and Carola-Bibiane Schönlieb. Your diffusion model secretly knows the dimension of the data manifold, 2022. URL https://arxiv.org/abs/2212.12611. Preprint at https://arxiv.org/abs/2212.12611
-
[75]
Score approximation, estimation, and distribution recovery of diffusion models on low-dimensional data
Minshuo Chen, Kaixuan Huang, Tuo Zhao, and Mengdi Wang. Score approximation, estimation, and distribution recovery of diffusion models on low-dimensional data. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 4672–4712, 2023
2023
-
[76]
Log-concave sampling, 2023
Sinho Chewi. Log-concave sampling, 2023. URLhttps://chewisinho.github.io. Book draft
2023
-
[77]
The spacetime of diffusion models: An information geometry perspective
Rafal Karczewski, Markus Heinonen, Alison Pouplin, Søren Hauberg, and Vikas K Garg. The spacetime of diffusion models: An information geometry perspective. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[78]
Improved techniques for training GANs.Advances in Neural Information Processing Systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs.Advances in Neural Information Processing Systems, 29, 2016
2016
-
[79]
Graduate Texts in Mathematics
Jean-François Le Gall.Brownian Motion, Martingales, and Stochastic Calculus. Graduate Texts in Mathematics. Springer, 2016
2016
-
[80]
A connection between score matching and denoising autoencoders.Neural Computation, 23(7): 1661–1674, 2011
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7): 1661–1674, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.