Recognition: unknown
From Local Indices to Global Identifiers: Generative Reranking for Recommender Systems via Global Action Space
Pith reviewed 2026-05-07 15:38 UTC · model grok-4.3
The pith
GloRank reformulates list-wise reranking as token generation over a global item identifier space, using supervised pre-training followed by reinforcement learning to maximize list-wise utility and outperforming baselines on benchmarks and industrial data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
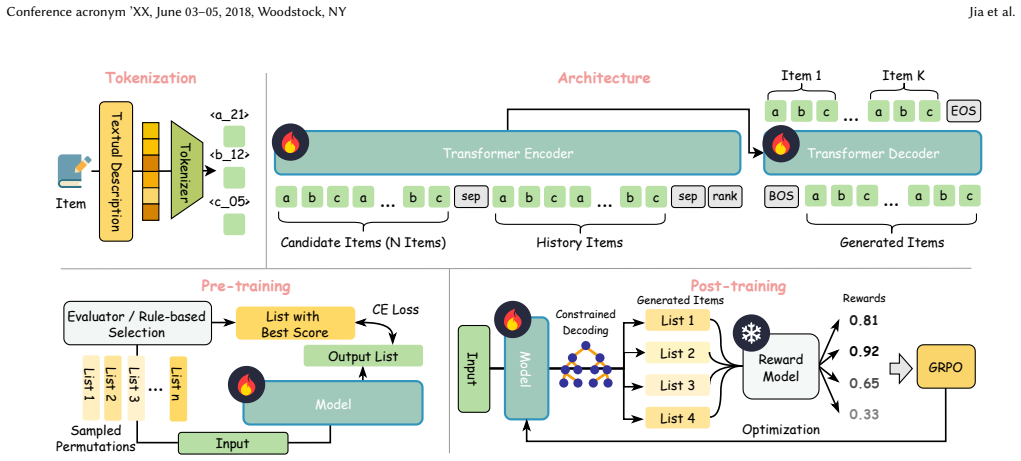
We propose GloRank (Global Action Space Ranker), a generative framework that shifts reranking from selecting local indices to generating global identifiers. ... Extensive experiments on two public benchmarks and a large-scale industrial dataset, coupled with online A/B tests, demonstrate that GloRank consistently outperforms state-of-the-art baselines and achieves superior robustness in cold-start scenarios.
Load-bearing premise
That representing items as sequences of discrete tokens and training via supervised pre-training plus RL will produce a stable global action space that generalizes beyond the training distribution without introducing new inconsistencies in token generation.
Figures



read the original abstract
In modern recommender systems, list-wise reranking serves as a critical phase within the multi-stage pipeline, finalizing the exposed item sequence and directly impacting user satisfaction by modeling complex intra-list item dependencies. Existing methods typically formulate this task as selecting indices from the local input list. However, this approach suffers from a semantically inconsistent action space: the same output neuron (logits) represents different items across different samples, preventing the model from establishing a stable, intrinsic understanding of the items. To address this, we propose GloRank (Global Action Space Ranker), a generative framework that shifts reranking from selecting local indices to generating global identifiers. Specifically, we represent items as sequences of discrete tokens and reformulate reranking as a token generation task. This design effectively decouples the scoring mechanism from the variable input order, ensuring that items are evaluated against a consistent global standard. We further enhance this with a two-stage optimization pipeline: a supervised pre-training phase to initialize the model with high-quality demonstrations, followed by a reinforcement learning-based post-training phase to directly maximize list-wise utility. Extensive experiments on two public benchmarks and a large-scale industrial dataset, coupled with online A/B tests, demonstrate that GloRank consistently outperforms state-of-the-art baselines and achieves superior robustness in cold-start scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GloRank, a generative reranking model for recommender systems that shifts from selecting local list indices to generating global item identifiers represented as token sequences. It employs a two-stage training process consisting of supervised pre-training on high-quality demonstrations followed by reinforcement learning to optimize list-wise utility. The paper reports consistent outperformance over state-of-the-art baselines on two public benchmarks, a large-scale industrial dataset, and through online A/B tests, with particular advantages in cold-start scenarios.
Significance. If the validity concerns are addressed, this work could be significant for the field by providing a more stable and semantically consistent action space for reranking models. The decoupling from variable input orders via global identifiers is a conceptually appealing idea, and the integration of generative modeling with RL for direct utility optimization represents a promising direction. The inclusion of industrial-scale experiments and online tests strengthens the practical implications.
major comments (1)
- The framework reformulates reranking as autoregressive generation over a global vocabulary, but the manuscript does not describe any mechanism to ensure that generated token sequences decode to valid and unique items from the provided candidate list (e.g., no mention of vocabulary restriction, masked decoding, or post-hoc validation in the generation or reward function). This is a load-bearing issue for the central claim, as without it the output may include invalid items, undermining the interpretation as a reranker and the claimed benefits over local-index methods.
minor comments (1)
- [Abstract] The abstract refers to 'two public benchmarks' without naming them; this should be specified for clarity in the introduction or experimental setup.
Simulated Author's Rebuttal
We sincerely thank the referee for the thoughtful and constructive review. We are encouraged by the recognition of the conceptual appeal of decoupling reranking from local indices via global identifiers, as well as the value of our two-stage training and industrial-scale validation. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: The framework reformulates reranking as autoregressive generation over a global vocabulary, but the manuscript does not describe any mechanism to ensure that generated token sequences decode to valid and unique items from the provided candidate list (e.g., no mention of vocabulary restriction, masked decoding, or post-hoc validation in the generation or reward function). This is a load-bearing issue for the central claim, as without it the output may include invalid items, undermining the interpretation as a reranker and the claimed benefits over local-index methods.
Authors: We thank the referee for identifying this important implementation detail. The manuscript indeed provides insufficient description of the constrained generation process, which is a valid point. In the revised manuscript we will add a dedicated subsection (Section 3.4) that explicitly describes the following mechanisms: (1) at each autoregressive step we maintain a dynamic mask over the global vocabulary that only permits tokens consistent with completing an item identifier present in the current candidate list (implemented via a prefix trie of candidate token sequences); (2) after full sequence generation we apply a deterministic post-processing step that replaces any duplicate items with the next-highest-probability valid candidate not yet selected; and (3) the list-wise reward in the RL stage is computed exclusively on the resulting valid, unique list. These additions ensure the generated output is always a permutation of items from the provided candidate set, preserving the reranking interpretation while retaining the benefits of the global action space. We believe this clarification directly resolves the concern. revision: yes
Circularity Check
New generative reformulation with independent experimental support
full rationale
The paper introduces GloRank as a shift from local-index selection to autoregressive token generation over global item identifiers, motivated by the claimed semantic inconsistency of per-list action spaces. This is presented as a modeling choice rather than a mathematical derivation. The two-stage pipeline (supervised pre-training on demonstrations followed by RL on list-wise utility) is described as an optimization procedure whose outputs are validated externally via benchmarks, industrial data, and A/B tests. No equations or claims reduce a 'prediction' to a fitted parameter, self-citation chain, or definitional tautology. The skeptic concern about unconstrained generation producing invalid items is an implementation or correctness issue, not evidence that any load-bearing step collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qingyao Ai, Keping Bi, Jiafeng Guo, and W. Bruce Croft. 2018. Learning a Deep Listwise Context Model for Ranking Refinement. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, July 08-12, 2018, Kevyn Collins-Thompson, Qiaozhu Mei, Brian D. Davison, Yiqun Liu, and Emine Yilmaz (...
-
[2]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems, RecSys 2023, Singapore, Singapore, September 18-22, 2023, Jie Zhang, Li Chen, Shlomo Berkovsky, Min Zhang...
- [3]
- [4]
-
[5]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, September 15-19, 2016, Shilad Sen, Werner Geyer, Jill Freyne, and Pablo Castells (Eds.). ACM, 191–198. doi:10.1145/2959100. 2959190
- [6]
-
[7]
Marco Cuturi. 2013. Sinkhorn Distances: Lightspeed Computation of Opti- mal Transport. InAdvances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceed- ings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani,...
2013
- [8]
-
[9]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review arXiv 2025
- [10]
-
[11]
Kairui Fu, Tao Zhang, Shuwen Xiao, Ziyang Wang, Xinming Zhang, Chenchi Zhang, Yuliang Yan, Junjun Zheng, Yu Li, Zhihong Chen, Jian Wu, Xiangheng Kong, Shengyu Zhang, Kun Kuang, Yu-Gang Jiang, and Bo Zheng. 2025. FORGE: Forming Semantic Identifiers for Generative Retrieval in Industrial Datasets. CoRRabs/2509.20904 (2025). arXiv:2509.20904 doi:10.48550/ARX...
-
[12]
Luke Gallagher, Ruey-Cheng Chen, Roi Blanco, and J. Shane Culpepper. 2019. Joint Optimization of Cascade Ranking Models. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, VIC, Australia, February 11-15, 2019, J. Shane Culpepper, Alistair Moffat, Paul N. Bennett, and Kristina Lerman (Eds.). ACM, ...
-
[13]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). InRecSys ’22: Sixteenth ACM Conference on Recommender Systems, Seattle, W A, USA, September 18 - 23, 2022, Jennifer Golbeck, F. Maxwell Harper, Vanessa Murdock, Michael ...
-
[14]
F. Maxwell Harper and Joseph A. Konstan. 2016. The MovieLens Datasets: History and Context.ACM Trans. Interact. Intell. Syst.5, 4 (2016), 19:1–19:19. doi:10.1145/2827872
-
[15]
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung- Yeung Shum. 2025. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290 (2025)
work page internal anchor Pith review arXiv 2025
- [16]
-
[17]
Guangda Huzhang, Zhen-Jia Pang, Yongqing Gao, Yawen Liu, Weijie Shen, Wen-Ji Zhou, Qianying Lin, Qing Da, Anxiang Zeng, Han Yu, Yang Yu, and Zhi-Hua Zhou
-
[18]
AliExpress Learning-to-Rank: Maximizing Online Model Performance Without Going Online.IEEE Trans. Knowl. Data Eng.35, 2 (2023), 1214–1226. doi:10.1109/TKDE.2021.3098898
-
[19]
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. 2025. Generative Recommendation with Seman- tic IDs: A Practitioner’s Handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM 2025, Seoul, Repub- lic of Korea, November 10-14, 2025, Meeyoung Ch...
-
[20]
Xiaoyu Kong, Leheng Sheng, Junfei Tan, Yuxin Chen, Jiancan Wu, An Zhang, Xiang Wang, and Xiangnan He. 2025. MiniOneRec: An Open-Source Frame- work for Scaling Generative Recommendation.CoRRabs/2510.24431 (2025). arXiv:2510.24431 doi:10.48550/ARXIV.2510.24431
-
[21]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. 2025. A Survey of Generative Recommendation from a Tri-Decoupled Perspective: Tokenization, Architecture, and Optimization. (2025)
2025
-
[22]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. LLaRA: Large Language-Recommendation Assistant. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, Grace Hui Yang, Hongning Wang, Sam Han, Claud...
-
[23]
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. 2024. Discrete Conditional Diffusion for Reranking in Rec- ommendation. InCompanion Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, Singapore, May 13-17, 2024, Tat-Seng Chua, Chong-Wah Ngo, Roy Ka-Wei Lee, Ravi Kumar, and Hady W. Lauw (Eds.). ACM,...
-
[24]
Zhijie Lin, Zhuofeng Li, Chenglei Dai, Wentian Bao, Shuai Lin, Enyun Yu, Haox- iang Zhang, and Liang Zhao. 2025. GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token Prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Manage- ment, CIKM 2025, Seoul, Republic of Korea, November 10-...
-
[25]
Qi Liu, Kai Zheng, Rui Huang, Wuchao Li, Kuo Cai, Yuan Chai, Yanan Niu, Yiqun Hui, Bing Han, Na Mou, Hongning Wang, Wentian Bao, Yunen Yu, Guorui Zhou, Han Li, Yang Song, Defu Lian, and Kun Gai. 2025. RecFlow: An Industrial Full Flow Recommendation Dataset. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April ...
2025
-
[26]
McAuley, Dong Zheng, Peng Jiang, and Kun Gai
Shuchang Liu, Qingpeng Cai, Zhankui He, Bowen Sun, Julian J. McAuley, Dong Zheng, Peng Jiang, and Kun Gai. 2023. Generative Flow Network for Listwise Recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6- 10, 2023, Ambuj K. Singh, Yizhou Sun, Leman Akoglu, Dimitrio...
-
[27]
Weiwen Liu, Yunjia Xi, Jiarui Qin, Fei Sun, Bo Chen, Weinan Zhang, Rui Zhang, and Ruiming Tang. 2022. Neural Re-ranking in Multi-stage Recommender Sys- tems: A Review. InProceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, Luc De Raedt (Ed.). ijcai.org, 5512–5520. doi:10.2...
-
[28]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783(2025)
work page internal anchor Pith review arXiv 2025
-
[29]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In7th International Conference on Learning Representations, ICLR 2019, New Or- leans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum? id=Bkg6RiCqY7
2019
- [30]
-
[31]
McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel
Julian J. McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel
-
[32]
Image-Based Recommendations on Styles and Substitutes. InProceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, August 9-13, 2015, Ricardo Baeza-Yates, Mounia Lalmas, Alistair Moffat, and Berthier A. Ribeiro-Neto (Eds.). ACM, 43–52. doi:10.1145/2766462.2767755
-
[33]
Yue Meng, Cheng Guo, Yi Cao, Tong Liu, and Bo Zheng. 2025. A Generative Re-ranking Model for List-level Multi-objective Optimization at Taobao. InPro- ceedings of the 48th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, Nicola Ferro, Maria Maistro, Gabriella Pasi, Omar ...
-
[34]
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models , url =
Jianmo Ni, Gustavo Hernández Ábrego, Noah Constant, Ji Ma, Keith B. Hall, Daniel Cer, and Yinfei Yang. 2022. Sentence-T5: Scalable Sentence Encoders from Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Jia et al. Pre-trained Text-to-Text Models. InFindings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022...
-
[35]
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, and Dan Pei. 2019. Personalized re-ranking for recommendation. InProceedings of the 13th ACM Conference on Recommender Systems, RecSys 2019, Copenhagen, Denmark, September 16-20, 2019, Toine Bogers, Alan Said, Peter Brusilovsky, and Domonkos ...
-
[36]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.J. Mach. Learn. Res.21 (2020), 140:1–140:67. https://jmlr.org/papers/v21/20-074.html
2020
-
[37]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Kesha- van, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. 2023. Rec- ommender Systems with Generative Retrieval. InAdvances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Pro- ...
2023
-
[38]
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang
-
[39]
Non-autoregressive Generative Models for Reranking Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29, 2024, Ricardo Baeza-Yates and Francesco Bonchi (Eds.). ACM, 5625–5634. doi:10.1145/3637528.3671645
-
[40]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review arXiv 2024
-
[41]
Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Yongkang Wang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, Ambuj K. Sing...
-
[42]
Shuli Wang, Xue Wei, Senjie Kou, Chi Wang, Wenshuai Chen, Qi Tang, Yinhua Zhu, Xiong Xiao, and Xingxing Wang. 2025. NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems. InCompanion Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Aus- tralia, 28 April 2025 - 2 May 2025, Guodong Long, Michale Blu...
-
[43]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable Item Tokenization for Generative Recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM 2024, Boise, ID, USA, October 21-25, 2024, Edoardo Serra and Francesca Spezzano (Eds....
-
[44]
Yunjia Xi, Weiwen Liu, Jieming Zhu, Xilong Zhao, Xinyi Dai, Ruiming Tang, Weinan Zhang, Rui Zhang, and Yong Yu. 2022. Multi-Level Interaction Reranking with User Behavior History. InSIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, ...
-
[45]
Hailan Yang, Zhenyu Qi, Shuchang Liu, Xiaoyu Yang, Xiaobei Wang, Xiang Li, Lantao Hu, Han Li, and Kun Gai. 2025. Comprehensive List Generation for Multi-Generator Reranking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, Nicola Ferro, Maria Mais...
-
[46]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review arXiv 2025
-
[47]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. Op...
2024
-
[48]
Kaike Zhang, Xiaobei Wang, Shuchang Liu, Hailan Yang, Xiang Li, Lantao Hu, Han Li, Qi Cao, Fei Sun, and Kun Gai. 2025. GoalRank: Group-Relative Optimiza- tion for a Large Ranking Model.CoRRabs/2509.22046 (2025). arXiv:2509.22046 doi:10.48550/ARXIV.2509.22046
-
[49]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[50]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review arXiv 2025
-
[51]
Kesen Zhao, Shuchang Liu, Qingpeng Cai, Xiangyu Zhao, Ziru Liu, Dong Zheng, Peng Jiang, and Kun Gai. 2023. KuaiSim: A Comprehensive Sim- ulator for Recommender Systems. InAdvances in Neural Information Pro- cessing Systems 36: Annual Conference on Neural Information Processing Sys- tems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Ali...
2023
-
[52]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting Large Language Models by Integrating Col- laborative Semantics for Recommendation. In40th IEEE International Conference on Data Engineering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 1435–1448. doi:10.1109/ICDE60146.2024.00118
- [53]
-
[54]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, Pengfei Zheng, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Ruiming Tang, Shiyao Wang, Shujie Yang, Tao Wu, Wuchao Li, Xinchen Luo, Xingmei Wang, Yi Su, Yunfan Wu, Zexuan Cheng, Zhanyu Liu, Zixing Zhang, Bin Zhang, Boxuan Wang, Chaoyi ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.