Recognition: unknown
Learning from Medical Entity Trees: An Entity-Centric Medical Data Engineering Framework for MLLMs
Pith reviewed 2026-05-07 16:17 UTC · model grok-4.3
The pith
A Medical Entity Tree built from literature guides data curation to improve how multimodal models handle interconnected clinical knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that extracting entities from authoritative medical literature to build a Medical Entity Tree, then applying node-guided retrieval, a two-stage hybrid filtering and alignment pipeline, and knowledge-aware synthesis of captions and reasoning VQA pairs, produces training data that measurably strengthens general-purpose MLLMs on medical tasks and yields state-of-the-art results across six benchmarks.
What carries the argument
The Medical Entity Tree, a hierarchical structure that encodes diseases, anatomical structures, modalities, and symptoms into a unified repository used to anchor data retrieval and constrain synthesis.
If this is right
- Models trained with MET-guided data show improved fine-grained recognition of medical entities because training examples respect hierarchical relations.
- The two-stage filtering ensures visual-semantic alignment that supports more reliable reasoning VQA pairs.
- Knowledge-aware synthesis generates targeted questions that test interconnected clinical understanding rather than isolated facts.
- General-purpose MLLMs reach state-of-the-art performance on diverse medical benchmarks without requiring specialized medical pre-training.
- The framework reduces fragmentation in data curation by replacing department- or modality-based splits with concept-anchored organization.
Where Pith is reading between the lines
- The same entity-tree approach could be tested in other structured domains such as legal case data or biological pathway knowledge to see whether hierarchical extraction improves multimodal reasoning outside medicine.
- If the tree extraction step proves reliable, future systems might use the MET not only for training but also as an explicit knowledge scaffold during inference to reduce hallucination on rare clinical combinations.
- Scaling the method would require checking whether extraction quality remains stable when the source literature expands to include newer guidelines or non-English texts.
Load-bearing premise
Automatically extracted entities from medical literature form an accurate, unbiased hierarchy that captures clinical interconnections without extraction errors or domain gaps.
What would settle it
A controlled experiment in which the same base MLLM is trained on identical raw medical data but partitioned only by modality or department, then tested on the same six benchmarks, would falsify the claim if it matches or exceeds the MET-guided results.
Figures



read the original abstract
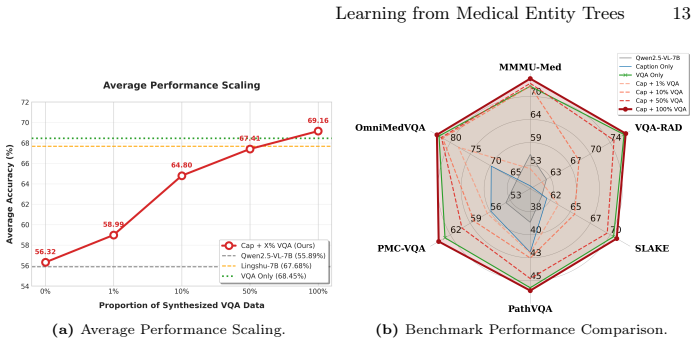
Multimodal Large Language Models (MLLMs) have shown transformative potential in medical applications, yet their performance is hindered by conventional data curation strategies that rely on coarse-grained partitioning by modality or department. Such fragmented approaches fail to capture the hierarchical and interconnected nature of clinical medical knowledge, limiting the models' ability to perform fine-grained recognition and complex reasoning. In this paper, we propose a novel Entity-Centric Medical Data Engineering framework. We automatically extract entities from authoritative medical literature to construct a Medical Entity Tree (MET), a hierarchical structure that systematically encodes diseases, anatomical structures, modalities, and symptoms into a unified knowledge repository. Building upon the MET, we propose an advanced data engine that includes: (1) node-guided retrieval to anchor raw data to specific medical concepts, (2) a two-stage hybrid filtering and alignment pipeline to ensure precise visual-semantic correspondence, and (3) knowledge-aware data synthesis to generate enriched captions and targeted reasoning VQA pairs, leveraging structural constraints. Extensive evaluations across six medical benchmarks demonstrate that our approach significantly enhances the medical capabilities of general-purpose MLLMs, improving their ability to handle complex clinical queries and achieve state-of-the-art performance in diverse medical contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an Entity-Centric Medical Data Engineering framework for multimodal large language models (MLLMs) in medicine. It automatically extracts entities from authoritative literature to build a hierarchical Medical Entity Tree (MET) encoding diseases, anatomical structures, modalities, and symptoms. This tree drives a data engine with node-guided retrieval, two-stage hybrid filtering/alignment, and knowledge-aware synthesis to produce enriched captions and reasoning VQA pairs. The central claim is that this approach substantially improves general-purpose MLLMs on complex clinical queries and yields state-of-the-art results across six medical benchmarks.
Significance. If the MET accurately encodes clinical hierarchies and the resulting data pairs demonstrably drive the reported gains, the work could advance data curation practices beyond coarse modality- or department-based partitioning. It offers a scalable, knowledge-structured alternative that might improve fine-grained recognition and reasoning in medical MLLMs, with potential applicability to other domains requiring interconnected hierarchical knowledge.
major comments (2)
- [Abstract] Abstract: the claim of state-of-the-art performance on six medical benchmarks is presented without any quantitative results, ablation studies, error analysis, or baseline comparisons. This prevents verification of the central claim that the entity-centric pipeline is responsible for the improvements rather than generic scaling or implementation details.
- [MET construction] MET construction section: the Medical Entity Tree is formed by automatic extraction from literature, yet no precision/recall figures, inter-annotator agreement, or comparison against expert-curated ontologies (SNOMED, UMLS) are supplied. Because downstream node-guided retrieval, filtering, and synthesis depend directly on MET accuracy, unvalidated extraction errors could misalign training pairs and undermine attribution of any benchmark gains to the proposed framework.
minor comments (2)
- The two-stage hybrid filtering and alignment pipeline is described at a high level; adding pseudocode or a diagram would improve reproducibility.
- Notation for the knowledge-aware synthesis step could be clarified to distinguish structural constraints from the generated VQA pairs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback highlights opportunities to strengthen the presentation of results and the validation of the Medical Entity Tree. We address each major comment below and commit to revisions that improve verifiability without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of state-of-the-art performance on six medical benchmarks is presented without any quantitative results, ablation studies, error analysis, or baseline comparisons. This prevents verification of the central claim that the entity-centric pipeline is responsible for the improvements rather than generic scaling or implementation details.
Authors: We agree that the abstract is high-level and omits specific numbers, which limits immediate verification. The manuscript body reports quantitative results, ablations, error analyses, and baseline comparisons in the Experiments section. To address this, we will revise the abstract to incorporate key performance metrics (e.g., average improvement across benchmarks) and a brief reference to the ablation findings, while respecting length constraints. revision: yes
-
Referee: [MET construction] MET construction section: the Medical Entity Tree is formed by automatic extraction from literature, yet no precision/recall figures, inter-annotator agreement, or comparison against expert-curated ontologies (SNOMED, UMLS) are supplied. Because downstream node-guided retrieval, filtering, and synthesis depend directly on MET accuracy, unvalidated extraction errors could misalign training pairs and undermine attribution of any benchmark gains to the proposed framework.
Authors: The referee correctly notes the absence of quantitative validation for the MET. The submitted manuscript describes the automatic extraction from authoritative sources but does not include precision/recall, IAA, or direct ontology comparisons. We will add a validation subsection reporting precision/recall on a sampled subset of entities, inter-annotator agreement from expert review, and overlap with UMLS concepts. This revision will better substantiate the MET's reliability and support attribution of downstream gains. revision: yes
Circularity Check
No circularity: empirical engineering pipeline validated on external benchmarks
full rationale
The paper presents an entity-centric data engineering framework that constructs a Medical Entity Tree via automatic extraction from literature, then applies node-guided retrieval, hybrid filtering, and knowledge-aware synthesis to create training data for MLLMs. Performance claims rest entirely on evaluations across six external medical benchmarks rather than any internal derivation, fitted parameters, or self-referential definitions. No equations, predictions derived from fits, uniqueness theorems, or self-citations appear in the provided text to support the central claims. The approach is self-contained against external benchmarks, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM18(6), 333–340 (1975)
Aho, A.V., Corasick, M.J.: Efficient string matching: an aid to bibliographic search. Communications of the ACM18(6), 333–340 (1975)
1975
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
In: Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes
Ben Abacha, A., Hasan, S.A., Datla, V.V., Demner-Fushman, D., Müller, H.: Vqa- med: Overview of the medical visual question answering task at imageclef 2019. In: Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019 (2019)
2019
-
[4]
Journal of Chinese Information Processing33(10), 1–9 (2019)
Byambasuren, O., Yang, Y., Sui, Z., Dai, D., Chang, B., Li, S., Zan, H.: Preliminary study on the construction of chinese medical knowledge graph. Journal of Chinese Information Processing33(10), 1–9 (2019)
2019
-
[5]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Chen, J., Gui, C., Ouyang, R., Gao, A., Chen, S., Chen, G.H., Wang, X., Cai, Z., Ji, K., Wan, X., et al.: Towards injecting medical visual knowledge into multimodal llms at scale. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 7346–7370 (2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[7]
Chowdhury, M.E., Rahman, T., Khandakar, A., Mazhar, R., Kadir, M.A., Mahbub, Z.B., Islam, K.R., Khan, M.S., Iqbal, A., Al Emadi, N., et al.: Can ai help in screening viral and covid-19 pneumonia? Ieee Access8, 132665–132676 (2020)
2020
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gao, F., Ping, Q., Thattai, G., Reganti, A., Wu, Y.N., Natarajan, P.: Transform- retrieve-generate: Natural language-centric outside-knowledge visual question an- swering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5067–5077 (2022)
2022
-
[9]
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020)
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, Y., Li, T., Lu, Q., Shao, W., He, J., Qiao, Y., Luo, P.: Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22170–22183 (2024)
2024
-
[11]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review arXiv 2024
-
[12]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021) 16 J. Lin, H. Yang et al
2021
-
[13]
Scientific data 5(1), 1–10 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5(1), 1–10 (2018)
2018
-
[14]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[15]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[16]
Advances in Neural Information Processing Systems36, 22820–22840 (2023)
Lin, W., Chen, J., Mei, J., Coca, A., Byrne, B.: Fine-grained late-interaction multi- modal retrieval for retrieval augmented visual question answering. Advances in Neural Information Processing Systems36, 22820–22840 (2023)
2023
-
[17]
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically- labeledknowledge-enhanceddatasetformedicalvisualquestionanswering.In:2021 IEEE 18th international symposium on biomedical imaging (ISBI). pp. 1650–1654. IEEE (2021)
2021
-
[18]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[19]
Neural Networks185, 107228 (2025)
Lou, M., Ying, H., Liu, X., Zhou, H.Y., Zhang, Y., Yu, Y.: Sdr-former: A siamese dual-resolution transformer for liver lesion classification using 3d multi-phase imag- ing. Neural Networks185, 107228 (2025)
2025
-
[20]
In: Proc
McQueen, J.B.: Some methods of classification and analysis of multivariate ob- servations. In: Proc. of 5th Berkeley Symposium on Math. Stat. and Prob. pp. 281–297 (1967)
1967
-
[21]
arXiv preprint arXiv:2412.07769 (2024)
Mullappilly, S.S., Kurpath, M.I., Pieri, S., Alseiari, S.Y., Cholakkal, S., Aldahmani, K., Khan, F., Anwer, R., Khan, S., Baldwin, T., et al.: Bimedix2: Bio-medical expert lmm for diverse medical modalities. arXiv preprint arXiv:2412.07769 (2024)
-
[22]
PLOS Digital Health3(7), e0000454 (2024)
Nakayama, L.F., Restrepo, D., Matos, J., Ribeiro, L.Z., Malerbi, F.K., Celi, L.A., Regatieri, C.S.: Brset: a brazilian multilabel ophthalmological dataset of retina fundus photos. PLOS Digital Health3(7), e0000454 (2024)
2024
-
[23]
Organization,W.H.,etal.:Internationalclassificationofdiseases-icd.WorldHealth Organization - 2009 (2009)
2009
-
[24]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[25]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review arXiv 1908
-
[26]
Journal of computational and applied mathematics20, 53–65 (1987)
Rousseeuw, P.J.: Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics20, 53–65 (1987)
1987
-
[27]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Shao, Z., Yu, Z., Wang, M., Yu, J.: Prompting large language models with answer heuristics for knowledge-based visual question answering. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 14974– 14983 (2023) Learning from Medical Entity Trees 17
2023
-
[29]
MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Shi, B., Cui, B., Jiang, B., Yu, D., Qian, F., Yang, H., Wang, H., Chen, J., Pan, J., Cao, J., et al.: Medxiaohe: A comprehensive recipe for building medical mllms. arXiv preprint arXiv:2602.12705 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Nature620(7972), 172–180 (2023)
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., et al.: Large language models encode clinical knowledge. Nature620(7972), 172–180 (2023)
2023
-
[31]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review arXiv 2023
-
[32]
Scientific data5(1), 1–9 (2018)
Tschandl, P., Rosendahl, C., Kittler, H.: The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data5(1), 1–9 (2018)
2018
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review arXiv 2024
-
[34]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Wang, Q., Ji, R., Peng, T., Wu, W., Li, Z., Liu, J.: Soft knowledge prompt: Help externalknowledgebecomeabetterteachertoinstructllminknowledge-basedvqa. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 6132–6143 (2024)
2024
-
[35]
arXiv preprint arXiv:2601.18496 (2026)
Wang, Z., Wang, H., Feng, S., Yang, X., Wang, D., Zhang, Y., Lin, J., Yang, H., Ji, X.:Deepmed:Buildingamedicaldeepresearchagentviamulti-hopmed-searchdata and turn-controlled agentic training & inference. arXiv preprint arXiv:2601.18496 (2026)
-
[36]
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
-
[37]
Journal of medical imaging5(3), 036501–036501 (2018)
Yan, K., Wang, X., Lu, L., Summers, R.M.: Deeplesion: automated mining of large- scale lesion annotations and universal lesion detection with deep learning. Journal of medical imaging5(3), 036501–036501 (2018)
2018
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yan,S.,Hu,M.,Jiang,Y.,Li,X.,Fei,H.,Tschandl,P.,Kittler,H.,Ge,Z.:Derm1m: A million-scale vision-language dataset aligned with clinical ontology knowledge for dermatology. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12681–12690 (2025)
2025
-
[39]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizingreasoningandactinginlanguagemodels.In:Theeleventhinternational conference on learning representations (2022)
2022
-
[40]
arXiv preprint arXiv:2504.21051 (2025)
Ye, J., Tang, H.: Multimodal large language models for medicine: A comprehensive survey. arXiv preprint arXiv:2504.21051 (2025)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9556– 9567 (2024)
2024
-
[42]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
2023
-
[43]
In: Findings of the association for computational linguistics: EMNLP 2023
Zhang, H., Chen, J., Jiang, F., Yu, F., Chen, Z., Chen, G., Li, J., Wu, X., Zhiyi, Z., Xiao, Q., et al.: Huatuogpt, towards taming language model to be a doctor. In: Findings of the association for computational linguistics: EMNLP 2023. pp. 10859–10885 (2023) 18 J. Lin, H. Yang et al
2023
-
[44]
Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., et al.: Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915 (2023)
work page internal anchor Pith review arXiv 2023
-
[45]
Zhang, X., Wu, C., Zhao, Z., Lin, W., Zhang, Y., Wang, Y., Xie, W.: Pmc-vqa: Visual instruction tuning for medical visual question answering. arXiv preprint arXiv:2305.10415 (2023) Learning from Medical Entity Trees 19 A Medical Entity Tree Construction Details Prompt for Stage 1: Batch Entity Extraction Belowareseveralsentences.Analyzethemformedicalentit...
-
[46]
Determine if it is a medical entity; if not, do not output
-
[47]
Separate entity nouns with commas; do not include duplicates
-
[48]
If there are no medical-related entity nouns, output "None"
-
[49]
Output strictly in JSON format. The example format is as follows: {’Sentence0’: ’Entity1,Entity2,...’, ’Sentence1’: ’Entity1,Entity2,...’, ...} Sentences: {lines} Prompt for Stage 2: Joint Extraction and Typing Below are several sentences. Analyze these sentences formedicalentity nouns and their types, and output according to the following requirements:
-
[50]
Secondarily, determine if they aremedicalentities; if not, do not output
Entity nouns must be informative proper nouns. Secondarily, determine if they aremedicalentities; if not, do not output
-
[51]
Pay attention to overly long medical entity nouns and determine if they can be segmented/split
-
[52]
The sentences below may contain special symbols and meaningless spaces; please ignore them directly
-
[53]
Replace <EntityType> with the specific entity category
-
[54]
Replace <EntityName> with the specific entity noun
-
[55]
{entity}
Output strictly in JSON format. The example format is as follows: { ’Sentence0’: [<EntityType>:<EntityName>, ...], ’Sentence1’: [...], ... } Sentences: {lines} The construction of the Medical Entity Tree (MET) is a crucial step in our framework, designed to support data retrieval, alignment, and synthesis for Mul- timodal Large Language Models (MLLMs). Th...
-
[56]
Contextual Re-Captioning
Parent Path A: {path_a} 2. Parent Path B: {path_b} ... You must search for the exact medical definition via Google/Wiki and adjudi- cate based on the following principles: 1.Principle of Etiological Dominance: Classification based on patho- logical mechanism or anatomical location takes precedence over clinical symptoms. 2.PrincipleofSpecificity:Ifonepare...
-
[57]
An original_caption (like a noisy or sparse Alt Text from the web)
-
[58]
Your goal is tosynthesizethese inputs into a single, enriched, and contextu- alized caption
A set of hierarchically medical linked_entities relevant to the image. Your goal is tosynthesizethese inputs into a single, enriched, and contextu- alized caption. Instructions:
-
[59]
First, analyze the visual evidence in the medical image
-
[60]
Review the original_caption to understand its starting point, even if it is noisy or sparse
-
[61]
4.Injecttheprecise medicalterminologyfrom thelinked_entitiesintoa new, comprehensive description
Your main task is tofusethe original_caption with the linked_entities and your visual analysis. 4.Injecttheprecise medicalterminologyfrom thelinked_entitiesintoa new, comprehensive description
-
[62]
LobarPneumonia
Use thehierarchical contextof the entities to create a more structured andinformativedescription.Forexample,ifanentityis“LobarPneumonia” and another is “Consolidation,” explain that the consolidation is a feature of the pneumonia
-
[63]
Output requirements:
The final caption must be objective, fact-based, and grounded in the visual evidence. Output requirements:
-
[64]
Produce a single, detailed, and coherent paragraph
-
[65]
ground truth
The output should be the final enriched captionONLY. original_caption: {original_caption} linked_entities: {entities} 24 J. Lin, H. Yang et al. Prompt for Track 2: Structure-Constrained Reasoning Synthesis You are an expert medical AI specializing in knowledge-driven data synthesis. Your task is to generate reasoning-intensive training samples (Multiple-C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.