Recognition: unknown
QFlash: Bridging Quantization and Memory Efficiency in Vision Transformer Attention
Pith reviewed 2026-05-07 16:52 UTC · model grok-4.3
The pith
QFlash runs FlashAttention's softmax entirely in integers for quantized vision transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QFlash is an end-to-end integer FlashAttention design that performs softmax entirely in the integer domain and runs as a single Triton kernel. It solves scale explosion during tile-wise accumulation, inefficient shift-based exponential operations on GPUs, and quantization granularity constraints requiring uniform scales for integer comparison, delivering up to 6.73× speedup over I-ViT and 8.69× on Swin while cutting energy 18.8% versus FP16 FlashAttention without sacrificing Top-1 accuracy on ViT/DeiT.
What carries the argument
Integer-domain online softmax that replaces floating-point scale tracking, exponentials, and comparisons with integer approximations while enforcing uniform per-tensor scales.
If this is right
- Up to 6.73× speedup over I-ViT on seven attention workloads from ViT, DeiT, and Swin models.
- Up to 8.69× speedup specifically on Swin attention layers.
- 18.8% lower energy consumption than FP16 FlashAttention.
- No loss in Top-1 accuracy on ViT and DeiT; competitive accuracy retained on Swin under per-tensor quantization.
Where Pith is reading between the lines
- The single-kernel Triton implementation could reduce launch overhead in latency-critical inference pipelines beyond the reported energy savings.
- The uniform-scale constraint solved here may allow direct combination with other per-tensor quantization passes already common in deployment toolchains.
- Because the design stays inside integer arithmetic, it opens a path to further memory-bandwidth reductions if paired with integer-only matrix multiplies in the rest of the transformer block.
Load-bearing premise
The integer approximations for scale handling, exponential computation, and comparisons preserve numerical behavior close enough to floating-point versions that model accuracy stays the same or competitive.
What would settle it
Running the same seven workloads on a new vision transformer under per-tensor quantization and observing a clear drop in Top-1 accuracy below the FP16 baseline would show the approximations do not preserve behavior adequately.
Figures






read the original abstract
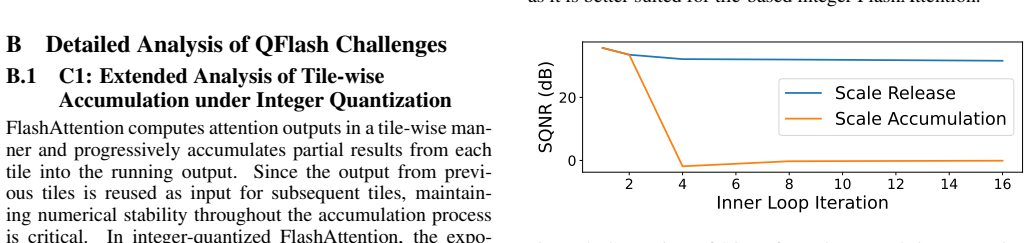
FlashAttention improves efficiency through tiling, but its online softmax still relies on floating-point arithmetic for numerical stability, making full quantization difficult. We identify three main obstacles to integer-only FlashAttention: (1) scale explosion during tile-wise accumulation, (2) inefficient shift-based exponential operations on GPUs, and (3) quantization granularity constraints requiring uniform scales for integer comparison. To address these challenges, we propose \textit{QFlash}, an end-to-end integer FlashAttention design that performs softmax entirely in the integer domain and runs as a single Triton kernel. On seven attention workloads from ViT, DeiT, and Swin models, QFlash achieves up to 6.73$\times$ speedup over I-ViT and up to 8.69$\times$ speedup on Swin, while reducing energy consumption by 18.8\% compared to FP16 FlashAttention, without sacrificing Top-1 accuracy on ViT/DeiT and remaining competitive on Swin under per-tensor quantization. Our code is publicly available at https://github.com/EfficientCompLab/qflash.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes QFlash, an end-to-end integer-only FlashAttention for Vision Transformers that performs the full online softmax in the integer domain inside a single Triton kernel. It identifies three obstacles—scale explosion during tile-wise accumulation, inefficient shift-based exponentials on GPUs, and quantization granularity constraints for uniform-scale comparisons—and claims that the resulting design delivers up to 6.73× speedup over I-ViT, 8.69× on Swin workloads, 18.8% lower energy than FP16 FlashAttention, and preserved Top-1 accuracy on ViT/DeiT (competitive on Swin) under per-tensor quantization.
Significance. If the integer approximations for scale handling, exponential, and comparisons preserve numerical fidelity sufficiently close to FP16 FlashAttention, the work would meaningfully advance quantized ViT inference by combining FlashAttention’s memory efficiency with integer arithmetic. Public code release supports reproducibility and is a clear strength.
major comments (3)
- [Abstract and §3] Abstract and §3 (integer-only online softmax): the central accuracy claim—that the chosen integer fixes for scale explosion, shift-based exp, and uniform-scale comparisons do not accumulate error across tiles or heads—remains unverified without explicit description of the approximations (e.g., any rescaling or integer exp implementation) and direct numerical comparison of attention outputs to FP16 FlashAttention.
- [Experimental results] Experimental results (Tables 1–3 and associated figures): the reported speedups and 18.8% energy reduction lack error bars, multiple random seeds, or ablations that isolate each of the three obstacles, so it is impossible to determine whether the claimed gains are robust or sensitive to the specific integer approximations.
- [Implementation] Implementation section: no verification is supplied that the Triton kernel executes strictly integer arithmetic (no hidden FP16 fallbacks), which is load-bearing for the quantization and energy claims.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly named the concrete integer techniques chosen for the exponential and scale handling.
- Ensure all baseline references (I-ViT, FP16 FlashAttention) include exact citation details and implementation versions used for timing.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (integer-only online softmax): the central accuracy claim—that the chosen integer fixes for scale explosion, shift-based exp, and uniform-scale comparisons do not accumulate error across tiles or heads—remains unverified without explicit description of the approximations (e.g., any rescaling or integer exp implementation) and direct numerical comparison of attention outputs to FP16 FlashAttention.
Authors: We agree that explicit descriptions and numerical verification are needed to substantiate the accuracy claims. In the revised manuscript we will expand §3 with the precise formulations for scale handling (including rescaling steps), the shift-based exponential implementation, and the uniform-scale comparison logic. We will also add a dedicated subsection (or appendix) with direct numerical comparisons of attention outputs between QFlash and FP16 FlashAttention, reporting maximum absolute error, relative error, and tile/head-wise statistics to confirm that approximation errors do not accumulate meaningfully. revision: yes
-
Referee: [Experimental results] Experimental results (Tables 1–3 and associated figures): the reported speedups and 18.8% energy reduction lack error bars, multiple random seeds, or ablations that isolate each of the three obstacles, so it is impossible to determine whether the claimed gains are robust or sensitive to the specific integer approximations.
Authors: We acknowledge the benefit of additional statistical detail. Performance and energy measurements derive from deterministic kernel executions on fixed hardware, so multiple random seeds are not applicable to these metrics; we will clarify this point explicitly. We will add error bars for accuracy-related results and include new ablation experiments that isolate the contribution of each of the three obstacle solutions. These changes will allow readers to evaluate robustness and sensitivity of the reported gains. revision: partial
-
Referee: [Implementation] Implementation section: no verification is supplied that the Triton kernel executes strictly integer arithmetic (no hidden FP16 fallbacks), which is load-bearing for the quantization and energy claims.
Authors: We will revise the Implementation section to provide explicit verification of strictly integer arithmetic. The updated section will include annotated kernel code excerpts demonstrating the absence of floating-point operations, together with pointers to the publicly released GitHub repository for full inspection. We will also add static-analysis or profiling evidence confirming integer-only execution, directly supporting the quantization and energy claims. revision: yes
Circularity Check
No circularity: empirical implementation results against external baselines
full rationale
The paper proposes QFlash as an engineering solution to three identified obstacles in integer-only FlashAttention (scale explosion, shift-based exp, uniform-scale comparisons) and evaluates it via direct runtime, energy, and accuracy measurements on seven ViT/DeiT/Swin workloads. No equations, derivations, fitted parameters, or self-citations are presented that reduce the central claims to inputs by construction. Results are framed as measured speedups (up to 6.73× over I-ViT) and accuracy preservation under per-tensor quantization, which are falsifiable against independent baselines and do not rely on any load-bearing self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Instructions’ latencies characterization for nvidia gpgpus.arXiv preprint arXiv:1905.08778,
[Arafaet al., 2019 ] Yehia Arafa, AH Badawy, Gopinath Chennupati, Nandakishore Santhi, and Stephan Eiden- benz. Instructions’ latencies characterization for nvidia gpgpus.arXiv preprint arXiv:1905.08778,
-
[2]
Understanding gpu power: A survey of profiling, modeling, and simulation methods.ACM Com- puting Surveys (CSUR), 49(3):1–27,
[Bridgeset al., 2016 ] Robert A Bridges, Neena Imam, and Tiffany M Mintz. Understanding gpu power: A survey of profiling, modeling, and simulation methods.ACM Com- puting Surveys (CSUR), 49(3):1–27,
2016
-
[3]
Int-flashattention: Enabling flash attention for int8 quantization.arXiv preprint arXiv:2409.16997,
[Chenet al., 2024 ] Shimao Chen, Zirui Liu, Zhiying Wu, Ce Zheng, Peizhuang Cong, Zihan Jiang, Yuhan Wu, Lei Su, and Tong Yang. Int-flashattention: Enabling flash attention for int8 quantization.arXiv preprint arXiv:2409.16997,
-
[4]
Hardware for deep learning
[Dally, 2023] Bill Dally. Hardware for deep learning. In 2023 IEEE Hot Chips 35 Symposium (HCS), pages 1–58. IEEE Computer Society,
2023
-
[5]
Flashattention: Fast and memory-efficient exact attention with io-awareness
[Daoet al., 2022 ] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35:16344–16359,
2022
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
[Dao, 2023] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review arXiv 2023
-
[7]
1.1 computing’s energy problem (and what we can do about it)
[Horowitz, 2014] Mark Horowitz. 1.1 computing’s energy problem (and what we can do about it). In2014 IEEE international solid-state circuits conference digest of tech- nical papers (ISSCC), pages 10–14. IEEE,
2014
-
[8]
[Huet al., 2024 ] Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, and Sifan Zhou. I-llm: Efficient integer-only inference for fully- quantized low-bit large language models.arXiv preprint arXiv:2405.17849,
-
[9]
Fused tensor core: A hardware–software co- design for efficient execution of attentions on gpus.IEEE Embedded Systems Letters, 17(5):317–320,
[Jahadiet al., 2025 ] Reza Jahadi, Phil Munz, and Ehsan Atoofian. Fused tensor core: A hardware–software co- design for efficient execution of attentions on gpus.IEEE Embedded Systems Letters, 17(5):317–320,
2025
-
[10]
I-bert: Integer- only bert quantization
[Kimet al., 2021 ] Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. I-bert: Integer- only bert quantization. InInternational conference on ma- chine learning, pages 5506–5518. PMLR,
2021
-
[11]
Mixed non-linear quantization for vision transformers
[Kimet al., 2024 ] Gihwan Kim, Jemin Lee, Sihyeong Park, Yongin Kwon, and Hyungshin Kim. Mixed non-linear quantization for vision transformers. InEuropean Confer- ence on Computer Vision, pages 97–112. Springer,
2024
-
[12]
Qattn: Efficient gpu kernels for mixed- precision vision transformers
[Kluskaet al., 2024 ] Piotr Kluska, Adri ´an Castell ´o, Flo- rian Scheidegger, A Cristiano I Malossi, and Enrique S Quintana-Ort´ı. Qattn: Efficient gpu kernels for mixed- precision vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3648–3657,
2024
-
[13]
Performance analysis of picongpu: particle-in-cell on gpus using nvidia’s nsight systems and nsight compute
[Leinhauseret al., 2021 ] Matthew Leinhauser, Jeffrey Young, Sergei Bastrakov, Ren ´e Widera, Ronnie Chatter- jee, and Sunita Chandrasekaran. Performance analysis of picongpu: particle-in-cell on gpus using nvidia’s nsight systems and nsight compute. Technical report, Oak Ridge National Laboratory (ORNL), Oak Ridge, TN (United States),
2021
-
[14]
I-vit: Integer- only quantization for efficient vision transformer infer- ence
[Li and Gu, 2023] Zhikai Li and Qingyi Gu. I-vit: Integer- only quantization for efficient vision transformer infer- ence. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17065–17075,
2023
-
[15]
Repq-vit: Scale reparameterization for post- training quantization of vision transformers
[Liet al., 2023 ] Zhikai Li, Junrui Xiao, Lianwei Yang, and Qingyi Gu. Repq-vit: Scale reparameterization for post- training quantization of vision transformers. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 17227–17236,
2023
-
[16]
[Linet al., 2021 ] Yang Lin, Tianyu Zhang, Peiqin Sun, Zheng Li, and Shuchang Zhou. Fq-vit: Post-training quantization for fully quantized vision transformer.arXiv preprint arXiv:2111.13824,
-
[17]
Online normalizer calculation for softmax,
[Milakov and Gimelshein, 2018] Maxim Milakov and Na- talia Gimelshein. Online normalizer calculation for soft- max.arXiv preprint arXiv:1805.02867,
-
[18]
Picachu: Plug-in cgra han- dling upcoming nonlinear operations in llms
[Qinet al., 2025 ] Jiajun Qin, Tianhua Xia, Cheng Tan, Jeff Zhang, and Sai Qian Zhang. Picachu: Plug-in cgra han- dling upcoming nonlinear operations in llms. InProceed- ings of the 30th ACM International Conference on Archi- tectural Support for Programming Languages and Oper- ating Systems, Volume 2, pages 845–861,
2025
-
[19]
Clamp-vit: Contrastive data- free learning for adaptive post-training quantization of vits
[Ramachandranet al., 2024 ] Akshat Ramachandran, Souvik Kundu, and Tushar Krishna. Clamp-vit: Contrastive data- free learning for adaptive post-training quantization of vits. InEuropean Conference on Computer Vision, pages 307–325. Springer,
2024
-
[20]
Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision.Advances in Neural Informa- tion Processing Systems, 37:68658–68685,
[Shahet al., 2024 ] Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision.Advances in Neural Informa- tion Processing Systems, 37:68658–68685,
2024
-
[21]
Shiftaddllm: Ac- celerating pretrained llms via post-training multiplication- less reparameterization.Advances in Neural Information Processing Systems, 37:24822–24848,
[Youet al., 2024 ] Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, and Yingyan Celine Lin. Shiftaddllm: Ac- celerating pretrained llms via post-training multiplication- less reparameterization.Advances in Neural Information Processing Systems, 37:24822–24848,
2024
-
[22]
Know your enemy to save cloud energy: Energy- performance characterization of machine learning serv- ing
[Yuet al., 2023 ] Junyeol Yu, Jongseok Kim, and Euiseong Seo. Know your enemy to save cloud energy: Energy- performance characterization of machine learning serv- ing. In2023 IEEE International Symposium on High- Performance Computer Architecture (HPCA), pages 842–
2023
-
[23]
Ptq4vit: Post-training quan- tization for vision transformers with twin uniform quanti- zation
[Yuanet al., 2022 ] Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. Ptq4vit: Post-training quan- tization for vision transformers with twin uniform quanti- zation. InEuropean conference on computer vision, pages 191–207. Springer,
2022
-
[24]
Quark: Quantization-enabled circuit shar- ing for transformer acceleration by exploiting common patterns in nonlinear operations
[Zhaoet al., 2025 ] Zhixiong Zhao, Haomin Li, Fangxin Liu, Yuncheng Lu, Zongwu Wang, Tao Yang, Li Jiang, and Haibing Guan. Quark: Quantization-enabled circuit shar- ing for transformer acceleration by exploiting common patterns in nonlinear operations. In2025 IEEE/ACM In- ternational Conference On Computer Aided Design (IC- CAD), pages 1–9. IEEE,
2025
-
[25]
Erq: Error reduction for post-training quantization of vision transformers
[Zhonget al., 2024 ] Yunshan Zhong, Jiawei Hu, You Huang, Yuxin Zhang, and Rongrong Ji. Erq: Error reduction for post-training quantization of vision transformers. InForty- first International Conference on Machine Learning,
2024
-
[26]
Per-tensor quantization applies a single scale to the entire input tensor, offering the simplest implementation and the lowest scale storage cost. Per-head quantization assigns different scales to each head, capturing head-wise distribution differences and providing a balanced trade-off between accuracy and overhead. Per-token quanti- zation applies a sep...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.