Recognition: unknown
Cross-Linguistic Rhythmic and Spectral Feature-Based Analysis of Nyishi and Adi: Two Under-Resourced Languages of Arunachal Pradesh
Pith reviewed 2026-05-07 14:31 UTC · model grok-4.3
The pith
Rhythmic and spectral features distinguish Nyishi from Adi with up to 94 percent classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
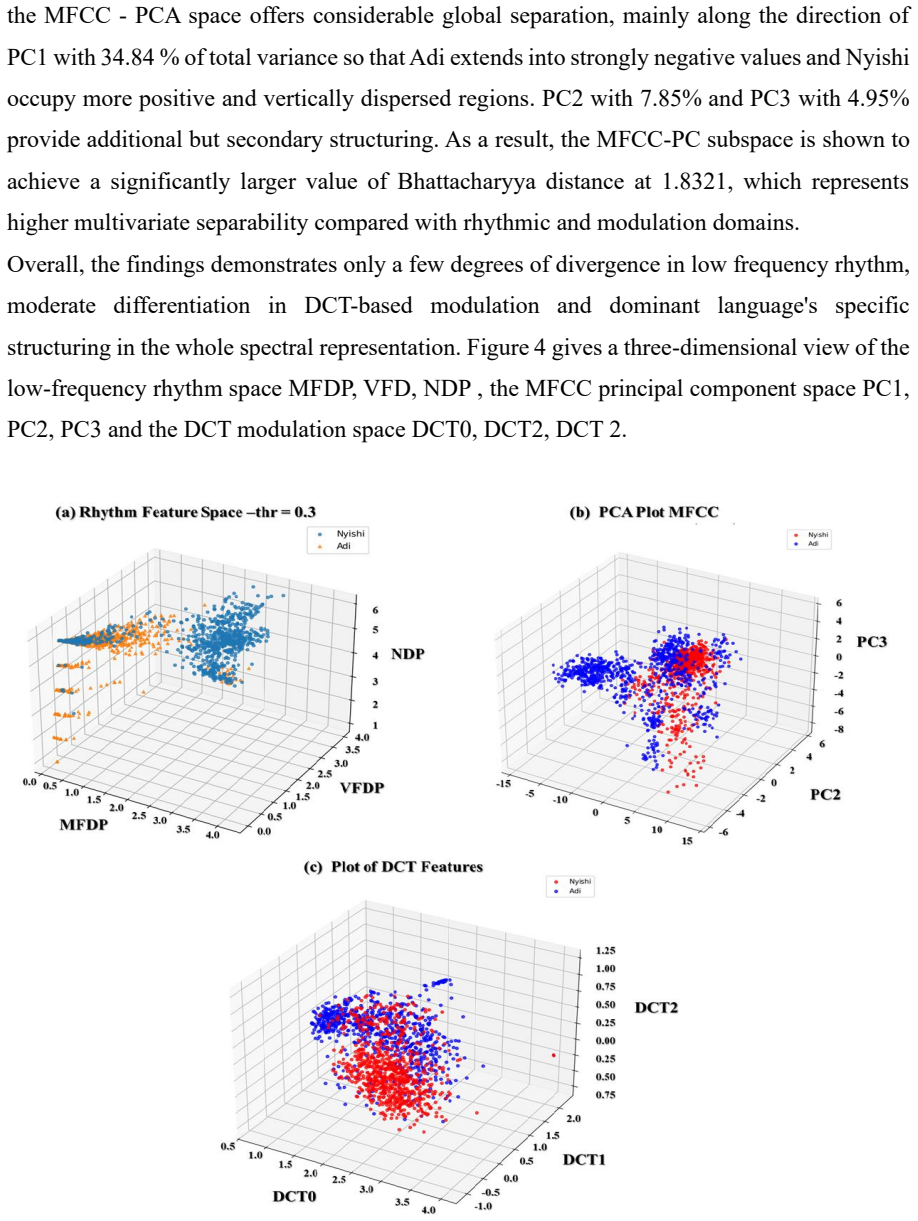
Intra-branch differentiation within the Tani group follows a hierarchical pattern across rhythmic and spectral domains. From the low-frequency modulation spectrum, the derived features show Nyishi with higher dominant modulation frequencies and greater dispersion than Adi. Rhythm-only features support classification at approximately 84-85 percent accuracy. Fusion with MFCC representations raises performance to 90.9 percent using SVM and 93.96 percent using MLP, demonstrating that low-frequency modulation captures constrained macro temporal structure while spectral features reflect finer phonological differentiation.
What carries the argument
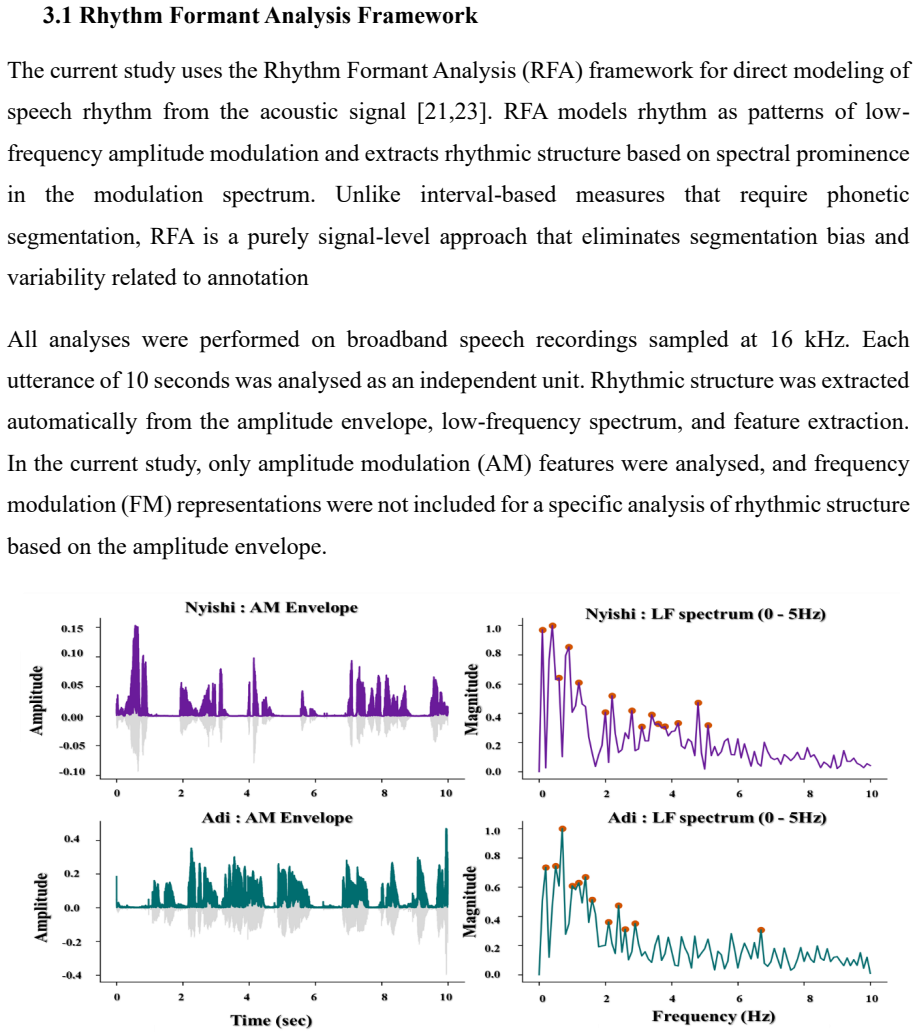
Rhythm formant analysis based on the low-frequency amplitude modulation spectrum, yielding Number of Dominant Peaks, Mean Frequency of Dominant Peaks, and Variance of Dominant Frequencies, together with Discrete Cosine Transform coefficients and Mel Frequency Cepstral Coefficients for spectral organisation.
Load-bearing premise
The low-frequency amplitude modulation spectrum and its derived features isolate language-specific rhythmic structure without being dominated by speaker variation, recording conditions, or other non-linguistic factors.
What would settle it
A controlled experiment using new recordings of the same languages that shows no significant difference in the rhythmic features or drops classification accuracy below 70 percent would falsify the hierarchical differentiation claim.
Figures


read the original abstract
Under-resourced languages remain underrepresented in quantitative rhythm research,particularly in systematic intra-branch analysis of acoustic differentiation within closely related linguistic groups.This study investigates acoustic differentiation within the Tani language subgroup by examining speech rhythm in Nyishi and Adi,two under-resourced Tani languages spoken in Arunachal Pradesh,North-East India,using a frequency domain framework based on amplitude modulation(AM) low-frequency(LF) spectrum analysis,commonly referred to as rhythm formant analysis(RFA).The analysis is designed to identify whether intra-branch differentiation follows a hierarchical pattern across rhythmic and spectral domains.From the LF modulation spectrum,three rhythm formant features were derived:Number of Dominant peaks(NDP),Mean Frequency of Dominant Peaks(MFDP),and Variance of Dominant Frequencies(VFDP).In addition,Discrete Cosine Transform (DCT)coefficients and Mel Frequency Cepstral Coefficient(MFCC) were extracted to characterise the spectral modulation structure and broad spectral organisation of the speech signal.Statistical modelling reveals a hierarchical pattern of differentiation,where rhythmic features show consistent but moderate separation,with Nyishi exhibiting higher dominant modulation frequencies as well as greater dispersion than Adi.Classification experiments further support this hierarchy,with rhythm-only features achieved approximately 84-85% classification accuracy.Fusion using MFCC representations improved performance to 90.9% classification accuracy using support vector machine (SVM) and 93.96% using multilayer perceptron (MLP).These findings demonstrate that rhythmic and spectral features encode complementary levels of linguistic variations,with low frequency modulation capturing constrained macro temporal structure and spectral features reflecting finer phonological differentiation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript investigates acoustic differentiation between Nyishi and Adi, two under-resourced Tani languages from Arunachal Pradesh, using low-frequency amplitude modulation spectrum analysis (rhythm formant analysis) to extract NDP, MFDP, and VFDP features, supplemented by DCT coefficients and MFCCs. It claims a hierarchical pattern of differentiation in which rhythmic features show consistent but moderate separation (Nyishi exhibiting higher dominant modulation frequencies and greater dispersion), with rhythm-only classification accuracies of approximately 84-85% that improve to 90.9% (SVM) and 93.96% (MLP) upon fusion with MFCC representations, indicating complementary rhythmic and spectral encoding of linguistic variation.
Significance. If the results hold after proper validation, the work would contribute to quantitative rhythm research on under-resourced languages by extending rhythm formant analysis to intra-branch Tani differentiation and demonstrating that low-frequency modulation features capture macro-temporal structure while spectral features reflect finer phonological distinctions. The hierarchical framing and fusion experiments are a positive step toward falsifiable, multi-level acoustic classification in data-scarce settings.
major comments (3)
- [Abstract] Abstract and implied Methods: The reported classification accuracies (84-85% rhythm-only; 90.9% SVM and 93.96% MLP with fusion) are presented without any information on speaker count, number of utterances, recording protocols, speaker normalization, cross-validation scheme, or statistical significance testing. This absence directly undermines assessment of whether the hierarchical separation and accuracies reflect language-specific rhythm rather than speaker or channel confounds.
- [Abstract] Abstract: The claim that LF amplitude-modulation features (NDP, MFDP, VFDP) reliably isolate rhythmic structure is load-bearing for the central hierarchical-differentiation argument, yet no controls for speaking rate, pitch, or recording conditions are described. These features are known to be sensitive to such non-linguistic factors; without speaker-held-out validation or explicit compensation, the moderate separation (Nyishi higher MFDP/VFDP) and 84-85% accuracy may not demonstrate intra-Tani linguistic signal.
- [Abstract] Abstract: The assertion of a 'hierarchical pattern' supported by 'statistical modelling' lacks specification of the models, effect sizes, or p-values used to establish 'consistent but moderate separation.' Without these, it is impossible to determine whether the reported pattern is statistically robust or merely descriptive.
minor comments (2)
- [Abstract] Abstract contains minor typographical issues including missing spaces after commas (e.g., 'Pradesh,North-East India').
- [Abstract] The abbreviation 'RFA' is introduced without a reference to prior rhythm formant literature or an explicit definition of the amplitude-modulation spectrum computation.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas where the manuscript can be strengthened. We address each of the major comments in detail below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: The reported classification accuracies (84-85% rhythm-only; 90.9% SVM and 93.96% MLP with fusion) are presented without any information on speaker count, number of utterances, recording protocols, speaker normalization, cross-validation scheme, or statistical significance testing. This absence directly undermines assessment of whether the hierarchical separation and accuracies reflect language-specific rhythm rather than speaker or channel confounds.
Authors: We agree that these details are necessary for a proper evaluation of the results. The abstract was kept concise, but this led to the omission of key methodological information. In the revised manuscript, we will expand the abstract to include a summary of the dataset (speaker count and utterances), recording protocols, normalization procedures, cross-validation approach, and mention of statistical testing. We will also ensure that the Methods section provides full transparency on these aspects to rule out potential confounds. revision: yes
-
Referee: The claim that LF amplitude-modulation features (NDP, MFDP, and VFDP) reliably isolate rhythmic structure is load-bearing for the central hierarchical-differentiation argument, yet no controls for speaking rate, pitch, or recording conditions are described. These features are known to be sensitive to such non-linguistic factors; without speaker-held-out validation or explicit compensation, the moderate separation (Nyishi higher MFDP/VFDP) and 84-85% accuracy may not demonstrate intra-Tani linguistic signal.
Authors: We appreciate this important point regarding potential confounds. While the recordings for both languages were conducted using standardized protocols to control for recording conditions, we acknowledge that explicit controls for speaking rate and pitch were not detailed. In the revision, we will add a subsection on feature robustness and potential non-linguistic influences, including any normalization steps taken. We will also report results from speaker-held-out cross-validation to better support that the observed separation reflects linguistic differences. revision: partial
-
Referee: The assertion of a 'hierarchical pattern' supported by 'statistical modelling' lacks specification of the models, effect sizes, or p-values used to establish 'consistent but moderate separation.' Without these, it is impossible to determine whether the reported pattern is statistically robust or merely descriptive.
Authors: We concur that more detail on the statistical analysis is required. The manuscript refers to 'statistical modelling' but does not specify the exact methods. We will revise the relevant sections to describe the statistical models used, report effect sizes, and provide p-values to substantiate the claims of consistent but moderate separation between Nyishi and Adi. revision: yes
Circularity Check
No circularity: empirical feature extraction and standard classification on raw signals
full rationale
The paper extracts NDP/MFDP/VFDP rhythm-formant features plus DCT/MFCC from the LF amplitude-modulation spectrum of raw speech waveforms, then applies ordinary statistical tests and off-the-shelf SVM/MLP classifiers. No equation or procedure defines a target quantity in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation. The reported accuracies (84-85 % rhythm-only, 90.9-93.96 % fused) are ordinary empirical outcomes of training on the extracted feature vectors; they do not reduce by construction to the inputs. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dauer, R. M. (1983). Stress -timing and syllable -timing reanalyzed. Journal of phonetics, 11(1), 51-62
1983
-
[2]
Loukina, A., Kochanski, G., Rosner, B., Keane, E., & Shih, C. (2011). Rhythm measures and dimensions of durational variation in speech. The Journal of the Acoustical Society of America, 129(5), 3258-3270
2011
-
[3]
Duarte, D., Galves, A., Lopes, N., & Maronna, R. (2001). The statistical analysis of acoustic correlates of speech rhythm. In Workshop on Rhythmic patterns, parameter setting and language change, ZiF , University of Bielefeld. Can be downloaded from http://www. physik. unibielefeld. de/complexity/duarte. pdf
2001
-
[4]
Abercrombie, D. (2019). Elements of general phonetics. Edinburgh University Press
2019
-
[5]
Wiget, L., White, L., Schuppler, B., Grenon, I., Rauch, O., & Mattys, S. L. (2010). How stable are acoustic metrics of contrastive speech rhythm? The Journal of the Acoustical Society of America, 127(3), 1559-1569
2010
-
[6]
Leong, V ., & Goswami, U. (2015). Acoustic -emergent phonology in the amplitude envelope of child-directed speech. PloS one, 10(12), e0144411
2015
-
[7]
Tilsen, S., & Johnson, K. (2008). Low-frequency Fourier analysis of speech rhythm. The Journal of the Acoustical Society of America, 124(2), EL34-EL39
2008
-
[8]
Greenberg, S., Carvey, H., Hitchcock, L., & Chang, S. (2003). Temporal properties of spontaneous speech—a syllable-centric perspective. Journal of Phonetics, 31(3-4), 465- 485
2003
-
[9]
Dafydd Gibbon and Peng Li. 2019. Quantifying and correlating rhythm formants in speech. In Proceedings of the International Symposium on Linguistic Patterns in Spontaneous Speech (LPSS’19). Taipei, Academia Sinica
2019
-
[10]
Ramus, F., Nespor, M., & Mehler, J. (1999). Correlates of linguistic rhythm in the speech signal. Cognition, 73(3), 265–292
1999
-
[11]
Grabe, E., & Low, E. L. (2002). Durational variability in speech and the rhythm class hypothesis. In Papers in Laboratory Phonology 7 (pp. 515–546). Cambridge University Press
2002
-
[12]
White, L., & Mattys, S. L. (2007). Rhythmic typology and variation in first and second languages. Amsterdam Studies in the Theory and History of Linguistic Science Series 4, 237–257
2007
-
[13]
Nolan, F., & Asu, E. L. (2009). The pairwise variability index and coexisting rhythms in language. Phonetica, 66(1–2), 64–77
2009
-
[14]
Arvaniti, A. (2009). Rhythm, timing and the timing of rhythm. Phonetica, 66(1–2), 46– 63
2009
-
[15]
Arvaniti, A. (2012). The usefulness of metrics in the quantification of speech rhythm. Journal of Phonetics, 40(3), 351–373
2012
-
[16]
Barbosa, P. A. (2002). Explaining cross-linguistic rhythmic variability via a coupled- oscillator model of rhythm production. In Proceedings of Speech Prosody 2002 (pp. 163–166)
2002
-
[17]
Lancia, L., Krasovitsky, G., & Stuntebeck, F. (2019). Coordinative patterns underlying cross-linguistic rhythmic differences. Journal of Phonetics, 72, 66–80
2019
-
[18]
G., & Ordin, M
Polyanskaya, L., Busà, M. G., & Ordin, M. (2020). Capturing cross -linguistic differences in macro -rhythm: The case of Italian and English. Language and Speech, 63(2), 242–263
2020
-
[19]
Tilsen, S., & Arvaniti, A. (2013). Speech rhythm analysis with decomposition of the amplitude envelope: Characterizing rhythmic patterns within and across languages. The Journal of the Acoustical Society of America, 134(1), 628–639
2013
- [20]
-
[21]
Gibbon, D. (2020). Rhythm formants of story reading in standard Mandarin. Chinese Journal of Phonetics, 14, 1–16
2020
-
[22]
Gibbon, D. (2023). The rhythms of rhythm. Journal of the International Phonetic Association, 53(1), 233–265
2023
-
[23]
Gibbon, D., & Lin, X. (2019). Rhythm zone theory: Speech rhythms are physical after all. In Approaches to the Study of Sound Structure and Speech (pp. 109–128). Routledge
2019
-
[24]
Gogoi, P., Sarmah, P., & Prasanna, S. R. M. (2024). Cross-linguistic rhythm analysis of Mising and Assamese. ACM Transactions on Asian and Low-Resource Language Information Processing, 23(10), 1–18
2024
-
[25]
Gogoi, P., Kalita, S., Sarmah, P., & Prasanna, S. R. M. (2025). Exploring Rhythm Formant Analysis for Indic language classification. In Proceedings of the 28th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA) (pp. 1–6)
2025
-
[26]
Chakraborty, J., Sinha, R., & Sarmah, P. (2024). Effects of rate of articulation in Rhythm Formant Analysis-based dialect classification. In Proceedings of the International Conference on Asian Language Processing (IALP) (pp. 417–422)
2024
-
[27]
Sun, J. T. S. (2003). Tani languages. The Sino-Tibetan Languages, 456-66
2003
-
[28]
W., & Sun, J
Post, M. W., & Sun, J. T. S. (2017). Tani languages. The Sino-Tibetan languages, 322- 337
2017
-
[29]
Post, M. W. (2021). On reconstructing ethno -linguistic prehistory: The case of tani. Crossing boundaries: Tibetan studies unlimited, 311-40
2021
-
[30]
Dafydd Gibbon. 2019. The phonetic grounding of prosody: Analysis and visualisation tools. In Human Language Tech nology. Challenges for Computer Science and Linguistics: 9th Language and Technology Conference, LTC 2019, Poznan, Poland, May 17–19, 2019, Rev ised Selected Papers (Poznań, Poland), Zygmunt Vetulani, Patrick Paroubek, and Marek Kubis (Eds.). S...
-
[31]
Dafydd Gibbon. 2020. Computational induction of prosodic structure. Studies in Prosodic Grammar 6, 2 (2020), 1–46
2020
-
[32]
TIME, COHESION, STYLE: RHYTHM FORMANTS IN ORAL NARRATIVE
Gibbon, D. TIME, COHESION, STYLE: RHYTHM FORMANTS IN ORAL NARRATIVE
-
[33]
Ahmed, N., Natarajan, T., & Rao, K. R. (1974). Discrete cosines transform. IEEE transactions on Computers, 100(1), 90-93
1974
-
[34]
Rabiner, L., & Schafer, R. (2010). Theory and applications of digital speech processing. Prentice Hall Press
2010
-
[35]
Davis, S., & Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE transactions on acoustics, speech, and signal processing, 28(4), 357-366
1980
-
[36]
Comparison of parametric representation for monosyllabic word recognition in continuously spoken sentences,
Davis, S.B. and Mermelstein, P. (1980), “Comparison of parametric representation for monosyllabic word recognition in continuously spoken sentences,” IEEE Trans. on ASSP, Aug. 1980
1980
-
[37]
Douglas Bates, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67, 1 (2015), 1–48
2015
-
[38]
Welch, B. L. (1947). The generalization of ‘STUDENT'S’problem when several different population varlances are involved. Biometrika, 34(1-2), 28-35
1947
-
[39]
G., & Lloyd, G
Brereton, R. G., & Lloyd, G. R. (2010). Support vector machines for classification and regression. Analyst, 135(2), 230-267
2010
-
[40]
Bourlard, H., & Wellekens, C. J. (1989). Speech pattern discrimination and multilayer perceptrons. Computer Speech & Language, 3(1), 1-19
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.