Recognition: unknown
Generalizable 3D Gaussian Splatting enabled Semantic Coding for Real-Time Immersive Video Communications
Pith reviewed 2026-05-07 14:22 UTC · model grok-4.3
The pith
An end-to-end network fuses semantic coding and 3D Gaussian Splatting to process stereo video directly into renderable 3D scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
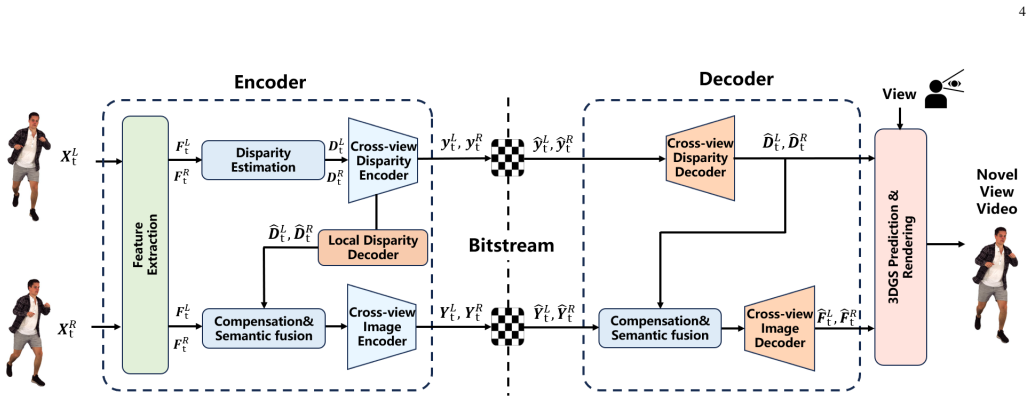
GS-SCNet is an end-to-end architecture in which a Disparity-Guided Parallel Semantic Codec processes stereo streams by using epipolar priors for disparity compensation and semantic fusion, while a Lightweight Gaussian Parameter Predictor converts the decoded semantic latents directly into 3D Gaussian attributes; by training the two components together the system captures geometric correlations only once and thereby removes the redundant pixel reconstruction stage present in conventional decoupled pipelines.
What carries the argument
The Disparity-Guided Parallel Semantic Codec together with the Lightweight Gaussian Parameter Predictor, which together project semantic latents directly into 3D Gaussian attributes.
If this is right
- Stereo video streams can be encoded and rendered in parallel at real-time rates.
- Rate-distortion performance improves relative to any pipeline that decodes to pixels before 3D reconstruction.
- The same trained model generalizes to new real-world human scenes without retraining.
- The framework remains robust when the input has already suffered compression artifacts.
Where Pith is reading between the lines
- Semantic latents may function as a shared intermediate representation usable by both compression and neural rendering tasks.
- The same direct-mapping idea could be tested on other 3D representations such as neural radiance fields.
- The approach may scale to wider camera baselines or additional views if the disparity guidance is extended accordingly.
Load-bearing premise
End-to-end training of the codec and predictor will reliably extract geometric correlations without any need for intermediate pixel reconstruction.
What would settle it
Training the codec and the Gaussian predictor separately on identical data, then measuring whether the joint model still produces measurably lower bitrates or higher rendering quality on out-of-domain real-world sequences.
Figures






read the original abstract
Real-time immersive video communications, particularly high-fidelity 3D telepresence, necessitates a synergistic balance between instantaneous dynamic scene reconstruction and high-efficiency data transmission. While recent advancements in feed-forward 3D Gaussian Splatting (3DGS) have enabled real-time rendering, performing multi-view video coding and 3D reconstruction in a decoupled manner leads to suboptimal compression efficiency and high computational complexity. To address this, we propose GS-SCNet, the first unified end-to-end framework that seamlessly integrates generalizable 3DGS reconstruction with a dedicated deep Semantic Coding pipeline. Our architecture is underpinned by two core technical contributions: (i) we introduce a Disparity-Guided Parallel Semantic Codec that exploits epipolar geometric priors to facilitate cross-view contextual interaction via disparity compensation and semantic fusion, thereby enabling real-time parallel processing of stereo streams while significantly enhancing rate-distortion performance, and (ii) we develop a Lightweight Gaussian Parameter Predictor which directly projects decoded semantic latents into 3DGS attributes, obviating the need for intermediate pixel-domain reconstruction. By coupling the codec with the task-specific predictor, our framework extracts geometric correlations only once, effectively eliminating the redundant computational bottleneck inherent in conventional decoupled paradigms. Extensive evaluations on both synthetic and real-world human datasets demonstrate that GS-SCNet achieves a superior trade-off across compression efficiency, rendering quality, and real-time performance. Notably, our framework exhibits strong cross-domain generalization and robustness against compression artifacts when applied to out-of-domain real-world data, significantly outperforming conventional decoupled transmission paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GS-SCNet, the first unified end-to-end framework integrating generalizable 3D Gaussian Splatting reconstruction with a deep semantic coding pipeline for real-time immersive video communications. It introduces two main components: (i) a Disparity-Guided Parallel Semantic Codec that exploits epipolar geometric priors for cross-view contextual interaction via disparity compensation and semantic fusion, enabling parallel stereo stream processing, and (ii) a Lightweight Gaussian Parameter Predictor that directly maps decoded semantic latents to 3DGS attributes (position, covariance, opacity, SH coefficients) without intermediate pixel-domain reconstruction. The authors claim this coupling extracts geometric correlations only once, yielding superior rate-distortion performance, rendering quality, real-time capability, and strong cross-domain generalization on synthetic and real-world human datasets compared to conventional decoupled transmission paradigms.
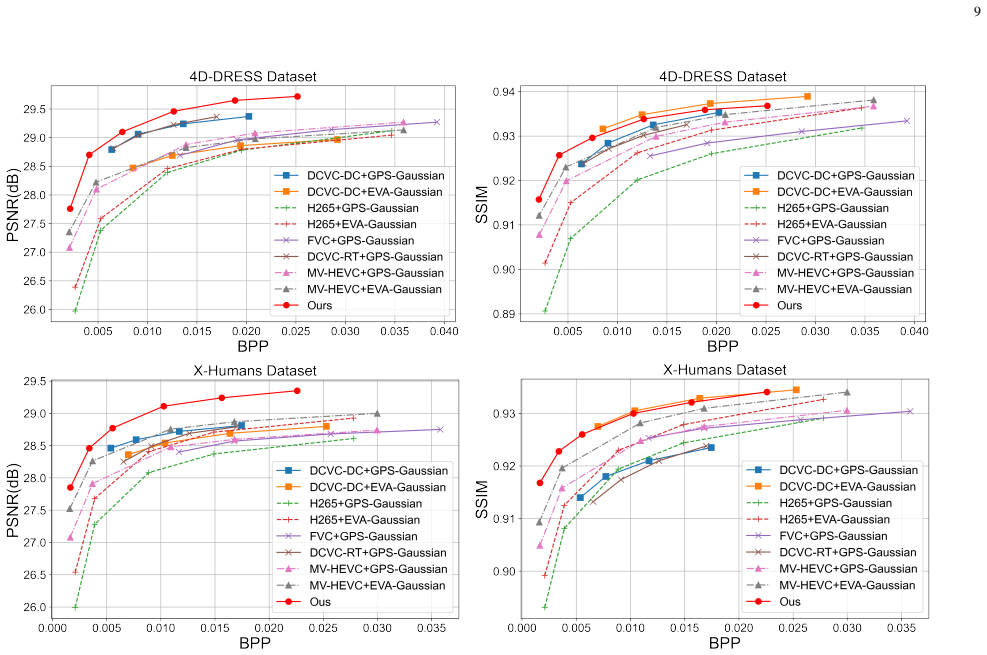
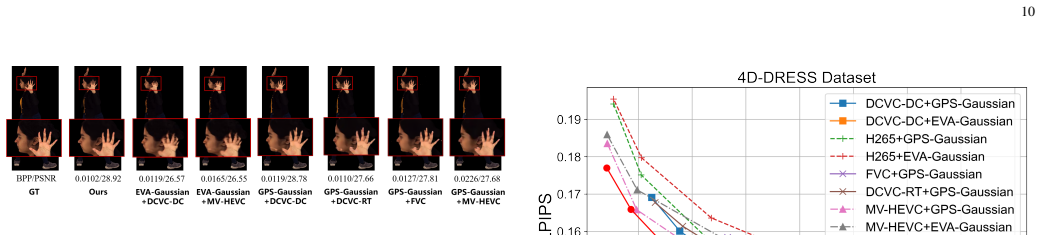
Significance. If the empirical claims hold, the work offers a meaningful advance for real-time 3D telepresence by unifying semantic coding and feed-forward 3DGS reconstruction, potentially reducing redundant computation and transmission overhead in immersive communications. The end-to-end design that avoids pixel reconstruction while preserving geometric fidelity through latent-space priors is a conceptually attractive direction, though its practical impact depends on verifiable gains in compression efficiency and robustness.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claims of 'superior trade-off across compression efficiency, rendering quality, and real-time performance' plus 'strong cross-domain generalization and robustness against compression artifacts' on out-of-domain real-world data are stated without any reported quantitative metrics (e.g., PSNR, SSIM, bitrate savings, runtime), baselines, or error analysis in the abstract and lack explicit cross-references to supporting tables or figures in the evaluation section, making it impossible to assess whether the data supports the end-to-end advantage over decoupled pipelines.
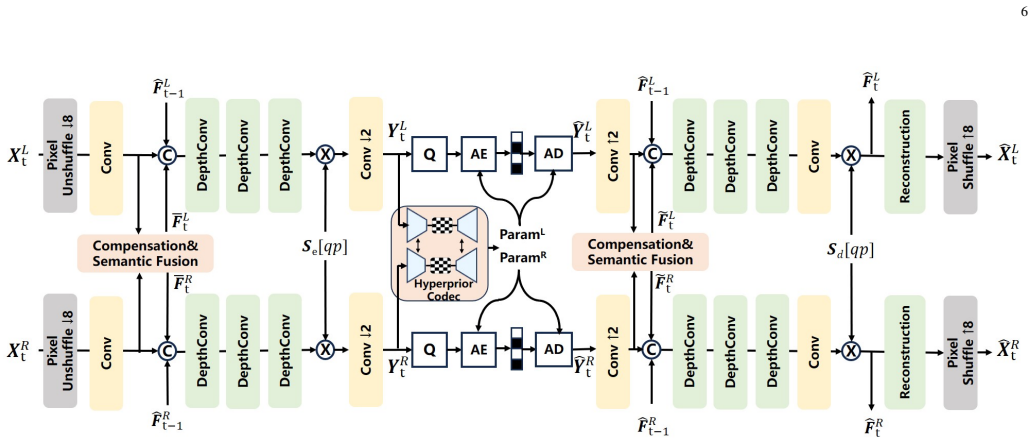
- [§3.2] §3.2 (Lightweight Gaussian Parameter Predictor): The claim that the predictor 'directly projects decoded semantic latents into 3DGS attributes, obviating the need for intermediate pixel-domain reconstruction' is load-bearing for the efficiency and generalization assertions, yet the section provides no analysis or ablation showing how high-frequency disparity details survive the rate-distortion optimized latent bottleneck (especially under compression on out-of-domain data); if such details are lost, the no-reconstruction advantage collapses relative to a decoupled pipeline that reconstructs pixels first.
- [§3.1] §3.1 (Disparity-Guided Parallel Semantic Codec): The architecture is described as embedding 'epipolar geometric priors' to enable semantic fusion and cross-view interaction, but no equations or diagrams detail the disparity compensation mechanism or prove that all necessary geometric correlations are preserved in the latent space for the downstream predictor; this leaves the 'extracts geometric correlations only once' claim unverified and risks circularity with the generalization results.
minor comments (2)
- [§3] Notation for semantic latents and disparity maps is introduced without a consolidated table of symbols, which would improve readability in the method sections.
- [Figures 2 and 5] Figure captions for the overall architecture and qualitative results could more explicitly label the data flow from codec latents to 3DGS attributes.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below and outline the revisions we will make to strengthen the presentation and supporting analysis.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claims of 'superior trade-off across compression efficiency, rendering quality, and real-time performance' plus 'strong cross-domain generalization and robustness against compression artifacts' on out-of-domain real-world data are stated without any reported quantitative metrics (e.g., PSNR, SSIM, bitrate savings, runtime), baselines, or error analysis in the abstract and lack explicit cross-references to supporting tables or figures in the evaluation section, making it impossible to assess whether the data supports the end-to-end advantage over decoupled pipelines.
Authors: We agree that adding explicit cross-references will improve readability and verifiability. While abstracts conventionally remain high-level and avoid dense numerical reporting, we will revise the abstract to include targeted references (e.g., 'as demonstrated in Tables 1–3 and Figures 4–6 of Section 4'). All quantitative metrics (PSNR, SSIM, bitrate savings, runtime), baseline comparisons, and error analysis for cross-domain generalization on out-of-domain real-world data are already reported in full in Section 4; the revision simply makes these links explicit in the abstract and introduction. revision: yes
-
Referee: [§3.2] §3.2 (Lightweight Gaussian Parameter Predictor): The claim that the predictor 'directly projects decoded semantic latents into 3DGS attributes, obviating the need for intermediate pixel-domain reconstruction' is load-bearing for the efficiency and generalization assertions, yet the section provides no analysis or ablation showing how high-frequency disparity details survive the rate-distortion optimized latent bottleneck (especially under compression on out-of-domain data); if such details are lost, the no-reconstruction advantage collapses relative to a decoupled pipeline that reconstructs pixels first.
Authors: This observation is fair and highlights a point where additional evidence would strengthen the manuscript. The end-to-end rate-distortion optimization is intended to retain task-relevant geometric information, but we acknowledge the absence of targeted ablation. In the revised version we will add an ablation study (new subsection in §3.2 plus supplementary figures) that measures disparity detail preservation (via edge sharpness and depth error metrics) across compression rates on both in-domain and out-of-domain data, directly comparing the direct-prediction path against pixel-reconstruction baselines. These results will quantify that high-frequency details critical for 3DGS attributes are retained sufficiently to preserve the claimed efficiency advantage. revision: yes
-
Referee: [§3.1] §3.1 (Disparity-Guided Parallel Semantic Codec): The architecture is described as embedding 'epipolar geometric priors' to enable semantic fusion and cross-view interaction, but no equations or diagrams detail the disparity compensation mechanism or prove that all necessary geometric correlations are preserved in the latent space for the downstream predictor; this leaves the 'extracts geometric correlations only once' claim unverified and risks circularity with the generalization results.
Authors: We appreciate the call for greater technical transparency. In the revised manuscript we will insert the explicit equations governing disparity compensation and semantic fusion (including the epipolar prior integration and cross-view attention formulation) directly into §3.1. A new architectural diagram will also be added to illustrate the latent-space flow. A short paragraph will discuss how the single extraction of geometric correlations in the latent domain supports downstream prediction, thereby removing any potential circularity with the empirical generalization results. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes GS-SCNet as a novel end-to-end architecture with two explicitly designed components: a Disparity-Guided Parallel Semantic Codec that incorporates epipolar priors for cross-view fusion, and a Lightweight Gaussian Parameter Predictor that maps decoded latents directly to 3DGS attributes. All performance claims, including superior rate-distortion trade-offs, real-time capability, cross-domain generalization, and robustness on out-of-domain data, are presented as outcomes of extensive empirical evaluations on synthetic and real-world human datasets. No load-bearing step equates a prediction or result to its own fitted inputs by construction, nor does any central premise reduce to a self-citation chain or renamed ansatz; the architecture is described as an independent design whose benefits are validated externally rather than tautologically derived.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-view image-based 3d reconstruc- tion in indoor scenes: a survey,
P. LU, W. SHI, and X. QIAO, “Multi-view image-based 3d reconstruc- tion in indoor scenes: a survey,”ZTE Communications, vol. 22, no. 3, p. 91, 2024
2024
-
[2]
Project starline: A high-fidelity telepresence system,
J. Lawrence, R. Overbeck, T. Prives, T. Fortes, N. Roth, and B. New- man, “Project starline: A high-fidelity telepresence system,” inACM SIGGRAPH 2024 Emerging Technologies, 2024, pp. 1–2
2024
-
[3]
Tele-aloha: A low-budget and high- authenticity telepresence system using sparse RGB cameras,
H. Tu, R. Shao, X. Dong, S. Zheng, H. Zhang, L. Chen, M. Wang, W. Li, S. Ma, S. Zhanget al., “Tele-aloha: A low-budget and high- authenticity telepresence system using sparse RGB cameras,”arXiv preprint arXiv:2405.14866, 2024
-
[4]
Iscom: Interest-aware semantic communication scheme for point cloud video streaming,
Y . Huang, B. Bai, Y . Zhu, X. Qiao, X. Su, and P. Zhang, “Iscom: Interest-aware semantic communication scheme for point cloud video streaming,”arXiv preprint arXiv:2210.06808, 2022
-
[5]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99– 106, 2021
2021
-
[6]
3D Gaussian Splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian Splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[7]
MVSplat: Efficient 3D Gaussian Splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.- J. Cham, and J. Cai, “MVSplat: Efficient 3D Gaussian Splatting from sparse multi-view images,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 370–386
2024
-
[8]
GPS-Gaussian: Generalizable pixel-wise 3D Gaussian Splatting for real-time human novel view synthesis,
S. Zheng, B. Zhou, R. Shao, B. Liu, S. Zhang, L. Nie, and Y . Liu, “GPS-Gaussian: Generalizable pixel-wise 3D Gaussian Splatting for real-time human novel view synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 680–19 690
2024
-
[9]
Y . Hu, Z. Liu, J. Shao, Z. Lin, and J. Zhang, “Eva-gaussian: 3d gaussian- based real-time human novel view synthesis under diverse multi-view camera settings,”arXiv preprint arXiv:2410.01425, 2024
-
[10]
Overview of the high efficiency video coding (HEVC) standard,
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649– 1668, 2012
2012
-
[11]
Overview of the multiview and 3D extensions of high efficiency video coding,
G. Tech, Y . Chen, K. M ¨uller, J.-R. Ohm, A. Vetro, and Y .-K. Wang, “Overview of the multiview and 3D extensions of high efficiency video coding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 26, no. 1, pp. 35–49, 2016
2016
-
[12]
Neural video compression with diverse contexts,
J. Li, B. Li, and Y . Lu, “Neural video compression with diverse contexts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 22 616–22 626
2023
-
[13]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,”arXiv preprint arXiv:2502.20762, 2025
-
[14]
LSVC: A learning-based stereo video compression framework,
Z. Chen, G. Lu, Z. Hu, S. Liu, W. Jiang, and D. Xu, “LSVC: A learning-based stereo video compression framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6073–6082
2022
-
[15]
Low-latency neural stereo streaming,
Q. Hou, F. Farhadzadeh, A. Said, G. Sautiere, and H. Le, “Low-latency neural stereo streaming,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7974–7984
2024
-
[16]
Hac: Hash-grid assisted context for 3d gaussian splatting compression,
Y . Chen, Q. Wu, W. Lin, M. Harandi, and J. Cai, “Hac: Hash-grid assisted context for 3d gaussian splatting compression,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 422–438
2024
-
[17]
Generalizable 3d gaussian splatting enabled immersive video communications with semantic coding,
D. Yang and Z. Qin, “Generalizable 3d gaussian splatting enabled immersive video communications with semantic coding,” inProceedings of the 3rd ACM Workshop on Mobile Immersive Computing, Networking, and Systems, ser. ImmerCom ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 36–42. [Online]. Available: https://doi.org/10.1145/3742889.3768350
-
[18]
Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering,
W. Cheng, R. Chen, S. Fan, W. Yin, K. Chen, Z. Cai, J. Wang, Y . Gao, Z. Yu, Z. Linet al., “Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 982–19 993
2023
-
[19]
End-to-end optimized image compression.arXiv preprint arXiv:1611.01704, 2016
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,”arXiv preprint arXiv:1611.01704, 2016
-
[20]
Variational image compression with a scale hyperprior
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Vari- ational image compression with a scale hyperprior,”arXiv preprint arXiv:1802.01436, 2018
work page Pith review arXiv 2018
-
[21]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[22]
Coarse-to-fine hyper-prior modeling for learned image compression,
Y . Hu, W. Yang, and J. Liu, “Coarse-to-fine hyper-prior modeling for learned image compression,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 013–11 020
2020
-
[23]
ELIC: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “ELIC: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5718–5727
2022
-
[24]
The JPEG AI standard: Providing efficient human and machine visual data consumption,
J. Ascenso, E. Alshina, and T. Ebrahimi, “The JPEG AI standard: Providing efficient human and machine visual data consumption,”Ieee Multimedia, vol. 30, no. 1, pp. 100–111, 2023
2023
-
[25]
DVC: An end-to-end deep video compression framework,
G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[26]
ELF-VC: Efficient learned flexible-rate video coding,
O. Rippel, A. G. Anderson, K. Tatwawadi, S. Nair, C. Lytle, and L. Bourdev, “ELF-VC: Efficient learned flexible-rate video coding,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 479–14 488
2021
-
[27]
Boosting neural video codecs by exploiting hierarchical redundancy,
R. Pourreza, H. Le, A. Said, G. Sautiere, and A. Wiggers, “Boosting neural video codecs by exploiting hierarchical redundancy,” inProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 5355–5364
2023
-
[28]
FVC: A new framework towards deep video compression in feature space,
Z. Hu, G. Lu, and D. Xu, “FVC: A new framework towards deep video compression in feature space,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1502– 1511
2021
-
[29]
Deep contextual video compression,
J. Li, B. Li, and Y . Lu, “Deep contextual video compression,”Advances in Neural Information Processing Systems, vol. 34, pp. 18 114–18 125, 2021
2021
-
[30]
Temporal context min- ing for learned video compression,
X. Sheng, J. Li, B. Li, L. Li, D. Liu, and Y . Lu, “Temporal context min- ing for learned video compression,”IEEE Transactions on Multimedia, vol. 25, pp. 7311–7322, 2022
2022
-
[31]
Hybrid spatial-temporal entropy modelling for neural video compression,
J. Li, B. Li, and Y . Lu, “Hybrid spatial-temporal entropy modelling for neural video compression,” inProceedings of the 30th ACM Interna- tional Conference on Multimedia, 2022, pp. 1503–1511
2022
-
[32]
Towards real-time neural video codec for cross-platform application using cal- ibration information,
K. Tian, Y . Guan, J. Xiang, J. Zhang, X. Han, and W. Yang, “Towards real-time neural video codec for cross-platform application using cal- ibration information,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7961–7970
2023
-
[33]
Data compression of stereopairs,
M. G. Perkins, “Data compression of stereopairs,”IEEE Transactions on communications, vol. 40, no. 4, pp. 684–696, 2002
2002
-
[34]
Overview of the stereo and multiview video coding extensions of the H.264/MPEG-4 A VC standard,
A. Vetro, T. Wiegand, and G. J. Sullivan, “Overview of the stereo and multiview video coding extensions of the H.264/MPEG-4 A VC standard,”Proceedings of the IEEE, vol. 99, no. 4, pp. 626–642, 2011
2011
-
[35]
Hgc-avatar: Hierarchical gaussian compression for streamable dynamic 3d avatars,
H. Tang, R. Yan, X. Yin, Q. Zhang, X. Zhang, S. Ma, W. Gao, and C. Jia, “Hgc-avatar: Hierarchical gaussian compression for streamable dynamic 3d avatars,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 8125–8134. 14
2025
-
[36]
Splatter image: Ultra- fast single-view 3D reconstruction,
S. Szymanowicz, C. Rupprecht, and A. Vedaldi, “Splatter image: Ultra- fast single-view 3D reconstruction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 208–10 217
2024
-
[37]
pixelSplat: 3D Gaussian Splats from image pairs for scalable generalizable 3D re- construction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelSplat: 3D Gaussian Splats from image pairs for scalable generalizable 3D re- construction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 457–19 467
2024
-
[38]
GPS-Gaussian+: Generalizable pixel-wise 3D Gaussian Splatting for real-time human-scene rendering from sparse views,
B. Zhou, S. Zheng, H. Tu, R. Shao, B. Liu, S. Zhang, L. Nie, and Y . Liu, “GPS-Gaussian+: Generalizable pixel-wise 3D Gaussian Splatting for real-time human-scene rendering from sparse views,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[39]
Generalizable human gaus- sians for sparse view synthesis,
Y . Kwon, B. Fang, Y . Lu, H. Dong, C. Zhang, F. V . Carrasco, A. Mosella- Montoro, J. Xu, S. Takagi, D. Kimet al., “Generalizable human gaus- sians for sparse view synthesis,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 451–468
2024
-
[40]
Xception: Deep learning with depthwise separable convolu- tions,
F. Chollet, “Xception: Deep learning with depthwise separable convolu- tions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258
2017
-
[41]
Raft-stereo: Multilevel recurrent field transforms for stereo matching,
L. Lipson, Z. Teed, and J. Deng, “Raft-stereo: Multilevel recurrent field transforms for stereo matching,” in2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 218–227
2021
-
[42]
Neural video compression with feature modulation,
J. Li, B. Li, and Y . Lu, “Neural video compression with feature modulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 099–26 108
2024
-
[43]
4D-DRESS: A 4D dataset of real-world human clothing with semantic annotations,
W. Wang, H.-I. Ho, C. Guo, B. Rong, A. Grigorev, J. Song, J. J. Zarate, and O. Hilliges, “4D-DRESS: A 4D dataset of real-world human clothing with semantic annotations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 550– 560
2024
-
[44]
X-Avatar: Expressive human avatars,
K. Shen, C. Guo, M. Kaufmann, J. J. Zarate, J. Valentin, J. Song, and O. Hilliges, “X-Avatar: Expressive human avatars,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16 911–16 921
2023
-
[45]
Calculation of average PSNR differences between RD- curves,
G. Bjontegaard, “Calculation of average PSNR differences between RD- curves,”ITU SG16 Doc. VCEG-M33, 2001. Dingxi Yang(Student Member, IEEE) received the bachelor’s degree in electronic engineering from Tsinghua University, Beijing, China, in 2023, where he is currently pursuing the Ph.D. degree with the Department of Electronic Engineering. His research ...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.