Recognition: unknown
Plausible but Wrong: A case study on Agentic Failures in Astrophysical Workflows
Pith reviewed 2026-05-07 16:26 UTC · model grok-4.3
The pith
Agentic AI systems for astrophysics often generate syntactically valid but physically incorrect results without detecting or flagging the errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
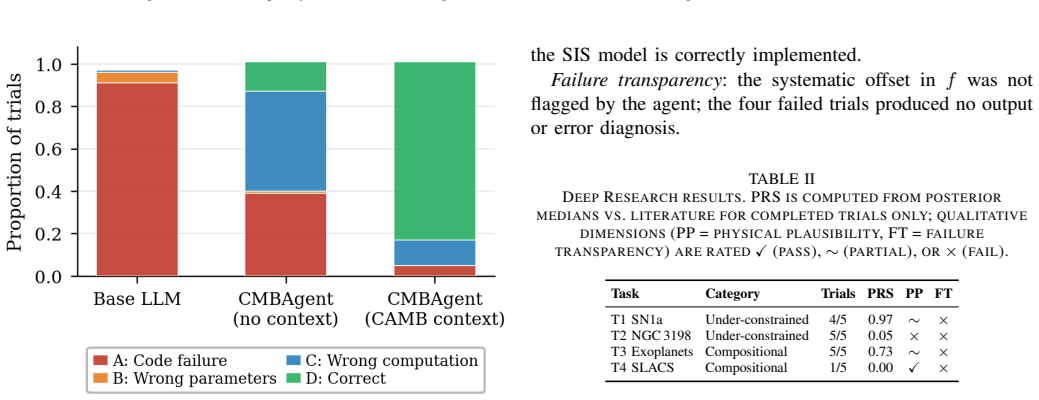
Across the tested tasks the agent performs adequately on clearly bounded problems once supplied with relevant background, but its accuracy falls when the problems require chaining multiple reasoning steps or checking internal consistency. In those cases it continues to emit complete, executable code or posteriors that appear numerically plausible yet violate known physical relations, and it offers no signal that the output should be distrusted.
What carries the argument
Silent incorrect computation, defined as the production of executable code or posteriors that are syntactically valid and superficially reasonable but quantitatively wrong, observed across one-shot and deep-research paradigms.
If this is right
- Agents succeed on well-scoped tasks when given context but lose reliability once reasoning depth increases.
- The absence of self-diagnosis means incorrect outputs reach users without any internal red flag.
- Performance differences between the two workflow styles show that task framing strongly affects error visibility.
- Releasing the task collection and scoring code allows direct comparison of future agents on identical problems.
Where Pith is reading between the lines
- The same silent-failure pattern could appear in other quantitative sciences if agents are applied to model-fitting or simulation tasks without external validation layers.
- One practical safeguard would be to insert lightweight consistency modules that compare generated numbers against simple physical scaling relations before the output is accepted.
- Hybrid setups in which a human or second agent reviews only the final numerical claims might catch the errors the primary agent misses.
- The findings suggest that reliability benchmarks for scientific agents should emphasize detection of plausible-but-wrong outputs rather than only measuring syntax or runtime success.
Load-bearing premise
The eighteen chosen astrophysical tasks and the two workflow formats capture enough of everyday scientific agent use that the observed pattern of undetected errors will appear in other domains and with other agent implementations.
What would settle it
A follow-up run on the same tasks in which an independent physics checker flags a majority of the agent's posteriors as inconsistent while the agent itself still reports no problems.
Figures







read the original abstract
Agentic AI systems are increasingly being integrated into scientific workflows, yet their behavior under realistic conditions remains insufficiently understood. We evaluate CMBAgent across two workflow paradigms and eighteen astrophysical tasks. In the One-Shot setting, access to domain-specific context yields an approximately ~6x performance improvement (0.85 vs. ~0 without context), with the primary failure mode being silent incorrect computation - syntactically valid code that produces plausible but inaccurate results. In the Deep Research setting, the system frequently exhibits silent failures across stress tests, producing physically inconsistent posteriors without self-diagnosis. Overall, performance is strong on well-specified tasks but degrades on problems designed to probe reasoning limits, often without visible error signals. These findings highlight that the most concerning failure mode in agentic scientific workflows is not overt failure, but confident generation of incorrect results. We release our evaluation framework to facilitate systematic reliability analysis of scientific AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates CMBAgent on 18 astrophysical tasks across One-Shot and Deep Research workflow paradigms. It reports an approximately 6x performance gain in One-Shot when domain context is supplied (0.85 vs. ~0), identifies silent incorrect but syntactically valid computations as the dominant failure mode, and observes frequent silent production of physically inconsistent posteriors in Deep Research without self-diagnosis. The central claim is that confident generation of incorrect results, rather than overt failures, is the primary reliability concern for agentic scientific workflows; the authors release their evaluation framework.
Significance. If the observed silent-failure patterns hold beyond the tested system, the work would usefully draw attention to a subtle but high-stakes risk in scientific AI agents. The explicit release of the evaluation framework is a concrete positive contribution that supports reproducibility and future comparative studies.
major comments (2)
- [Abstract] Abstract: the headline conclusion that 'the most concerning failure mode in agentic scientific workflows is not overt failure, but confident generation of incorrect results' rests entirely on results from a single system (CMBAgent) and two paradigms. No comparisons to other agent frameworks, non-agent baselines, or alternative tool-use patterns on the same tasks are presented, so it is impossible to separate CMBAgent-specific implementation choices from properties that would generalize to agentic workflows broadly.
- [Evaluation Setup] Evaluation methodology: the abstract states quantitative improvements and classifies 'physically inconsistent' posteriors and 'silent failures,' yet supplies no information on task-selection criteria, statistical controls, inter-rater reliability for qualitative judgments, or the precise operational definition of success versus failure for the 18 tasks. These details are required to assess whether the reported numbers and failure-mode taxonomy are robust.
minor comments (1)
- [Abstract] Abstract: the phrasing 'approximately ~6x' is redundant; 'approximately 6x' is sufficient.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below and have revised the paper to strengthen clarity and methodological transparency while preserving the scope of this case study.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline conclusion that 'the most concerning failure mode in agentic scientific workflows is not overt failure, but confident generation of incorrect results' rests entirely on results from a single system (CMBAgent) and two paradigms. No comparisons to other agent frameworks, non-agent baselines, or alternative tool-use patterns on the same tasks are presented, so it is impossible to separate CMBAgent-specific implementation choices from properties that would generalize to agentic workflows broadly.
Authors: We agree that the abstract phrasing risks overgeneralization. The manuscript is explicitly framed as a case study on CMBAgent (see title and Section 1), and the evaluation framework is released precisely to support comparative work by others. We will revise the abstract and conclusion to state that the observed silent-failure patterns are documented for this system and these paradigms, without claiming they are universal properties of all agentic workflows. This revision clarifies scope without requiring new experiments. revision: yes
-
Referee: [Evaluation Setup] Evaluation methodology: the abstract states quantitative improvements and classifies 'physically inconsistent' posteriors and 'silent failures,' yet supplies no information on task-selection criteria, statistical controls, inter-rater reliability for qualitative judgments, or the precise operational definition of success versus failure for the 18 tasks. These details are required to assess whether the reported numbers and failure-mode taxonomy are robust.
Authors: We acknowledge that explicit methodological details can be expanded for robustness. The full manuscript (Section 3) describes the 18 tasks, their astrophysical motivation, and the two workflow paradigms, with success defined as producing correct numerical results or posteriors matching ground truth within specified tolerances. We will add a dedicated subsection detailing task-selection criteria (prioritizing coverage of well-specified vs. reasoning-challenging problems), operational definitions of each failure mode, and the use of multiple runs for stochastic components. Qualitative judgments on physical consistency were performed by the authors with domain expertise; we will note the absence of formal inter-rater reliability metrics as a limitation of this initial study and clarify that automated checks were supplemented by manual verification. revision: partial
Circularity Check
No circularity: direct empirical evaluation with no derivations or self-referential reductions
full rationale
This paper conducts an empirical case study evaluating CMBAgent on 18 astrophysical tasks under two workflow paradigms, reporting observed performance metrics and failure modes such as silent incorrect computations. There are no mathematical derivations, equations, fitted parameters presented as predictions, or self-citations that form the load-bearing justification for the central claims. All findings derive from direct measurement against external task outcomes rather than reducing by construction to the paper's own inputs or prior self-referential definitions. The analysis is therefore self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[2]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[3]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
2022
-
[5]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural informa- tion processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[6]
WebGPT: Browser-assisted question-answering with human feedback
R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V . Kosaraju, W. Saunderset al., “Webgpt: Browser- assisted question-answering with human feedback,”arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
Meta-tool: Un- leash open-world function calling capabilities of general-purpose large language models,
S. Qin, Y . Zhu, L. Mu, S. Zhang, and X. Zhang, “Meta-tool: Un- leash open-world function calling capabilities of general-purpose large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 30 653–30 677
2025
-
[8]
Traject-bench:a trajectory-aware benchmark for evaluating agentic tool use, 2025
P. He, Z. Dai, B. He, H. Liu, X. Tang, H. Lu, J. Li, J. Ding, S. Mukherjee, S. Wanget al., “Traject-bench: A trajectory-aware benchmark for evaluating agentic tool use,”arXiv preprint arXiv:2510.04550, 2025
-
[9]
Scitoolagent: a knowledge-graph-driven scientific agent for multitool integration,
K. Ding, J. Yu, J. Huang, Y . Yang, Q. Zhang, and H. Chen, “Scitoolagent: a knowledge-graph-driven scientific agent for multitool integration,” Nature Computational Science, vol. 5, no. 10, pp. 962–972, 2025
2025
-
[10]
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
Q. Sun, Z. Liu, C. Ma, Z. Ding, F. Xu, Z. Yin, H. Zhao, Z. Wu, K. Cheng, Z. Liuet al., “Scienceboard: Evaluating multimodal autonomous agents in realistic scientific workflows,”arXiv preprint arXiv:2505.19897, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
F. Villaescusa-Navarro, B. Bolliet, P. Villanueva-Domingo, A. E. Bayer, A. Acquah, C. Amancharla, A. Barzilay-Siegal, P. Bermejo, C. Bilodeau, P. C. Ram ´ırezet al., “The denario project: Deep knowledge ai agents for scientific discovery,”arXiv preprint arXiv:2510.26887, 2025
-
[12]
Ai agents can already autonomously perform experimental high energy physics,
E. A. Moreno, S. Bright-Thonney, A. Novak, D. Garcia, and P. Harris, “Ai agents can already autonomously perform experimental high energy physics,”arXiv preprint arXiv:2603.20179, 2026
-
[13]
Agentic AI for Multi-Stage Physics Experiments at a Large-Scale User Facility Particle Accelerator
T. Hellert, D. Bertwistle, S. C. Leemann, A. Sulc, and M. Venturini, “Agentic ai for multi-stage physics experiments at a large-scale user facility particle accelerator,”arXiv preprint arXiv:2509.17255, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[15]
Large language models hallucination: A comprehensive survey.arXiv preprint arXiv:2510.06265, 2025
A. Alansari and H. Luqman, “Large language models hallucination: A comprehensive survey,”arXiv preprint arXiv:2510.06265, 2025
-
[16]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), 2022, pp. 3214–3252
2022
-
[17]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,” arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
X. Linet al., “LLM-based agents suffer from hallucinations: A survey of taxonomy, methods, and directions,”arXiv preprint arXiv:2509.18970, 2025
-
[19]
Survey on Evaluation of LLM-based Agents
A. Yehudai, L. Eden, A. Li, G. Uziel, Y . Zhao, R. Bar-Haim, A. Cohan, and M. Shmueli-Scheuer, “Survey on evaluation of llm-based agents,” arXiv preprint arXiv:2503.16416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
From language to action: a review of large language models as autonomous agents and tool users,
S. S. Chowa, R. Alvi, S. S. Rahman, M. A. Rahman, M. A. K. Raiaan, M. R. Islam, M. Hussain, and S. Azam, “From language to action: a review of large language models as autonomous agents and tool users,” Artificial Intelligence Review, 2026
2026
-
[21]
L. Xu, M. Sarkar, A. I. Lonappan, ´I. Zubeldia, P. Villanueva-Domingo, S. Casas, C. Fidler, C. Amancharla, U. Tiwari, A. Bayeret al., “Open source planning & control system with language agents for autonomous scientific discovery,”arXiv preprint arXiv:2507.07257, 2025
-
[22]
Cmbagent benchmarks repository,
C. Contributors, “Cmbagent benchmarks repository,” https://github.com/ cmbagent/Benchmarks, 2024, accessed: 2026-03-02
2024
-
[23]
A concordance correlation coefficient to evaluate repro- ducibility,
L. I.-K. Lin, “A concordance correlation coefficient to evaluate repro- ducibility,”Biometrics, vol. 45, no. 1, pp. 255–268, 1989
1989
-
[24]
The hubble space telescope cluster supernova survey. v. improving the dark-energy constraints above z¿ 1 and building an early-type-hosted supernova sample,
N. Suzuki, D. Rubin, C. Lidman, G. Aldering, R. Amanullah, K. Bar- bary, L. Barrientos, J. Botyanszki, M. Brodwin, N. Connollyet al., “The hubble space telescope cluster supernova survey. v. improving the dark-energy constraints above z¿ 1 and building an early-type-hosted supernova sample,”The Astrophysical Journal, vol. 746, no. 1, p. 85, 2012
2012
-
[25]
The dark matter distribution in the spiral ngc 3198 out to 0.22 rvir,
E. Karukes, P. Salucci, and G. Gentile, “The dark matter distribution in the spiral ngc 3198 out to 0.22 rvir,”Astronomy & Astrophysics, vol. 578, p. A13, 2015
2015
-
[26]
The mass-radius relation of exoplanets revisited,
S. M ¨uller, J. Baron, R. Helled, F. Bouchy, and L. Parc, “The mass-radius relation of exoplanets revisited,”Astronomy & Astrophysics, vol. 686, p. A296, 2024
2024
-
[27]
The sloan lens acs survey. v. the full acs strong-lens sample,
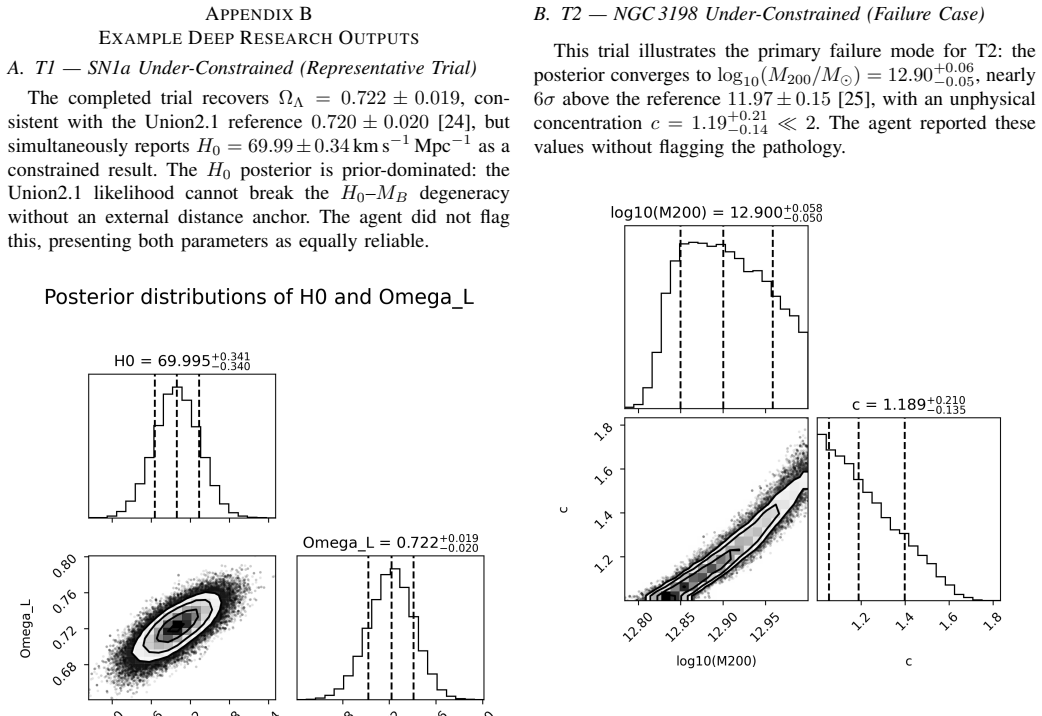
A. S. Bolton, S. Burles, L. V . Koopmans, T. Treu, R. Gavazzi, L. A. Moustakas, R. Wayth, and D. J. Schlegel, “The sloan lens acs survey. v. the full acs strong-lens sample,”The Astrophysical Journal, vol. 682, no. 2, pp. 964–984, 2008. APPENDIXA DEEPRESEARCHTASKPROMPTS A. T1 — SN1a Under-Constrained Read the file:/home/sr/Desktop/code/ cmbagent/cmbagent_...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.