Recognition: unknown
Benchmarking Layout-Guided Diffusion Models through Unified Semantic-Spatial Evaluation in Closed and Open Settings
Pith reviewed 2026-05-07 16:54 UTC · model grok-4.3
The pith
New closed and open benchmarks with a unified semantic-spatial score enable consistent ranking of layout-guided text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
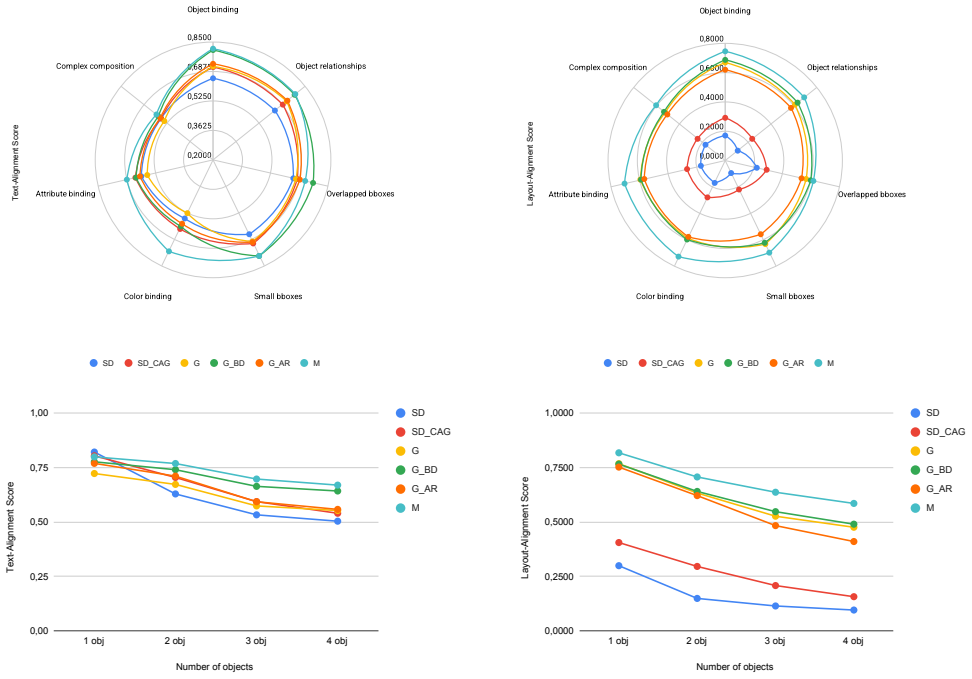
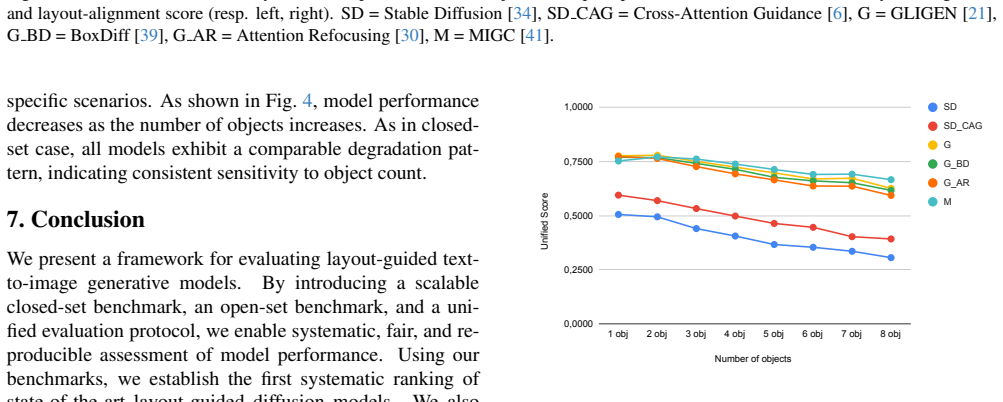
We introduce a closed-set benchmark (C-Bench) designed to isolate key generative capabilities while providing varying levels of complexity in both prompt structure and layout. To complement this controlled setting, we propose an open-set benchmark (O-Bench) that evaluates models using real-world prompts and layouts. We further develop a unified evaluation protocol that combines semantic and spatial accuracy into a single score, ensuring consistent model ranking. Using these, we evaluate six models on 319,086 images and establish performance rankings with detailed breakdowns.
What carries the argument
The unified evaluation protocol that combines semantic and spatial accuracy into a single score, applied to the new C-Bench and O-Bench benchmarks.
If this is right
- Models can be ranked consistently across controlled and real-world settings based on the combined score.
- Detailed breakdowns allow identification of specific strengths in text alignment versus layout fidelity.
- Fine-grained analysis across prompt complexities reveals where current models perform well or struggle.
- The benchmarks support large-scale evaluation without relying on costly fine-grained annotations for every case.
Where Pith is reading between the lines
- Developers could use the unified score to guide targeted improvements in spatial control mechanisms.
- The benchmarks might be extended to test emerging models or new layout conditioning techniques.
- If the single score correlates strongly with human preferences, it could replace separate metric evaluations in future work.
Load-bearing premise
The proposed unified evaluation protocol accurately measures both semantic alignment and spatial fidelity across diverse prompts and layouts without introducing its own biases.
What would settle it
Re-running the evaluation of the six models using independent human annotations for semantic and spatial quality and finding that the rankings or relative performances differ significantly from those produced by the unified score would falsify the claim.
Figures


read the original abstract
Evaluating layout-guided text-to-image generative models requires assessing both semantic alignment with textual prompts and spatial fidelity to prescribed layouts. Assessing layout alignment requires collecting fine-grained annotations, which is costly and labor-intensive. Consequently, current benchmarks rarely provide comprehensive layout evaluation and often remain limited in scale or coverage, making model comparison, ranking, and interpretation difficult. In this work, we introduce a closed-set benchmark (C-Bench) designed to isolate key generative capabilities while providing varying levels of complexity in both prompt structure and layout. To complement this controlled setting, we propose an open-set benchmark (O-Bench) that evaluates models using real-world prompts and layouts, offering a measure of semantic and spatial alignment in the wild. We further develop a unified evaluation protocol that combines semantic and spatial accuracy into a single score, ensuring consistent model ranking. Using our benchmarks, we conduct a large-scale evaluation of six state-of-the-art layout-guided diffusion models, totaling 319,086 generated and evaluated images. We establish a model ranking based on their overall performance and provide detailed breakdowns for text and layout alignment to enhance interpretability. Fine-grained analyses across scenarios and prompt complexities highlight the strengths and limitations of current models. Code is available at https://github.com/lparolari/cobench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a closed-set benchmark (C-Bench) with controlled prompt and layout complexity to isolate generative capabilities, an open-set benchmark (O-Bench) using real-world prompts and layouts, and a unified evaluation protocol that fuses semantic (text-prompt) and spatial (layout) accuracies into a single score for consistent model ranking. It reports results from evaluating six state-of-the-art layout-guided diffusion models on 319,086 generated images, including overall rankings and fine-grained breakdowns by text/layout alignment and prompt complexity.
Significance. If the unified protocol is robust, the work offers a scalable alternative to annotation-heavy layout evaluation, enabling standardized comparisons across closed and open settings. The large-scale evaluation (319k images) and public code repository are clear strengths that support reproducible rankings and interpretability analyses. This could help address gaps in current benchmarks for layout-guided text-to-image models.
major comments (2)
- [Unified evaluation protocol] Unified evaluation protocol section: the central claim that the protocol 'ensures consistent model ranking' by combining semantic and spatial accuracy into a single score lacks any reported validation against human judgments, inter-annotator agreement metrics, ablation on normalization/weighting choices, or sensitivity analysis on the fusion function. Since all model rankings, breakdowns, and fine-grained analyses derive directly from this aggregate score, the absence of these checks is load-bearing for the headline results.
- [Evaluation results] Evaluation results (around the model ranking tables): the reported rankings and scenario-specific breakdowns are presented without evidence that the aggregate score is invariant to reasonable variations in the semantic-spatial fusion method, undermining the claim of consistent ranking across C-Bench and O-Bench.
minor comments (1)
- [Abstract] Abstract: states that the unified protocol combines accuracies 'into a single score' but provides no details on validation or inter-annotator agreement, which should be summarized at this level given its centrality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our unified evaluation protocol and the robustness of the reported rankings. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: Unified evaluation protocol section: the central claim that the protocol 'ensures consistent model ranking' by combining semantic and spatial accuracy into a single score lacks any reported validation against human judgments, inter-annotator agreement metrics, ablation on normalization/weighting choices, or sensitivity analysis on the fusion function. Since all model rankings, breakdowns, and fine-grained analyses derive directly from this aggregate score, the absence of these checks is load-bearing for the headline results.
Authors: We acknowledge that the original manuscript does not include human validation, inter-annotator agreement, or explicit ablations/sensitivity analyses for the fused score. The semantic component uses standard CLIP similarity and the spatial component uses layout overlap metrics, both drawn from prior literature; the fusion is a normalized linear combination chosen for interpretability. In the revised manuscript we will add: (1) an ablation on weighting and normalization choices, (2) a sensitivity analysis showing how model rankings vary (or remain stable) under alternative fusion functions, and (3) a dedicated limitations paragraph discussing the absence of human correlation studies. These additions will be placed in the evaluation protocol section and the results appendix. revision: partial
-
Referee: Evaluation results (around the model ranking tables): the reported rankings and scenario-specific breakdowns are presented without evidence that the aggregate score is invariant to reasonable variations in the semantic-spatial fusion method, undermining the claim of consistent ranking across C-Bench and O-Bench.
Authors: We agree that explicit invariance evidence was missing. The revised manuscript will include new experiments that recompute all rankings under several reasonable fusion variants (arithmetic mean, geometric mean, and two weighted schemes with different semantic/spatial emphasis). We will report the resulting rank stability across both C-Bench and O-Bench, together with quantitative measures of ranking correlation (e.g., Kendall tau). This directly addresses the concern that the headline results depend on a single, untested fusion choice. revision: yes
- Full human validation and inter-annotator agreement studies for the fused score, which would require new large-scale annotation campaigns beyond the computational resources available for this revision.
Circularity Check
No circularity in empirical benchmarking setup
full rationale
The paper is a pure empirical benchmarking study that introduces C-Bench and O-Bench datasets plus an explicit unified scoring protocol combining semantic and spatial metrics. No mathematical derivations, fitted parameters, or predictions are claimed; model rankings are computed directly from the defined metrics on generated images. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core protocol. The work is self-contained and externally falsifiable via the released code and generated outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models
Eslam Mohamed Bakr, Pengzhan Sun, Xiaoqian Shen, Faizan Farooq Khan, Li Erran Li, and Mohamed Elhoseiny. Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models. InIEEE/CVF International Confer- ence on Computer Vision, ICCV 2023, Paris, France, Octo- ber 1-6, 2023, pages 19984–19996. IEEE, 2023. 1, 2
2023
-
[2]
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with an ensem- ble of expert denoisers.CoRR, abs/2211.01324, 2022. 1
-
[3]
Multimodal garment designer: Human-centric latent diffusion models for fashion image editing
Alberto Baldrati, Davide Morelli, Giuseppe Cartella, Mar- cella Cornia, Marco Bertini, and Rita Cucchiara. Multimodal garment designer: Human-centric latent diffusion models for fashion image editing. InIEEE/CVF International Confer- ence on Computer Vision, ICCV 2023, Paris, France, Octo- ber 1-6, 2023, pages 23336–23345. IEEE, 2023. 1
2023
-
[4]
David C. Blair. Information retrieval, 2nd ed. C.J. van rijs- bergen. london: Butterworths; 1979: 208 pp. price: $32.50. J. Am. Soc. Inf. Sci., 30(6):374–375, 1979. 6
1979
-
[5]
Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, , et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, , et al. Language models are few-shot learners. InAdvances in Neural Information Processing Sys- tems 33: NeurIPS 2020, 2020, virtual, 2020. 4
2020
-
[6]
Training-free layout control with cross-attention guidance
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, pages 5331–5341. IEEE, 2024. 6, 7, 8
2024
-
[7]
HiCo: Hierar- chical controllable diffusion model for layout-to-image gen- eration
Bo Cheng, Yuhang Ma, Liebucha Wu, Shanyuan Liu, Ao Ma, Xiaoyu Wu, Dawei Leng, and Yuhui Yin. HiCo: Hierar- chical controllable diffusion model for layout-to-image gen- eration. InAdvances in Neural Information Processing Sys- tems 38: Annual Conference on Neural Information Process- ing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, ...
2024
-
[8]
Diagnostic benchmark and it- erative inpainting for layout-guided image generation
Jaemin Cho, Linjie Li, Zhengyuan Yang, Zhe Gan, Lijuan Wang, and Mohit Bansal. Diagnostic benchmark and it- erative inpainting for layout-guided image generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024, pages 5280–5289. IEEE, 2024. 1, 2
2024
-
[9]
Transvg: End-to-end visual ground- ing with transformers
Jiajun Deng, Zhengyuan Yang, Tianlang Chen, Wengang Zhou, and Houqiang Li. Transvg: End-to-end visual ground- ing with transformers. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 1749–1759. IEEE,
2021
-
[10]
Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang
Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Ar- jun R. Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang. Training-free structured dif- fusion guidance for compositional text-to-image synthesis. InThe Eleventh International Conference on Learning Rep- resentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, ...
2023
-
[11]
LLM blueprint: Enabling text-to-image generation with complex and detailed prompts
Hanan Gani, Shariq Farooq Bhat, Muzammal Naseer, Salman Khan, and Peter Wonka. LLM blueprint: Enabling text-to-image generation with complex and detailed prompts. InThe Twelfth International Conference on Learning Rep- resentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 1, 2
2024
-
[12]
TIAM - A metric for evaluating alignment in text- to-image generation
Paul Grimal, Herv ´e Le Borgne, Olivier Ferret, and Julien Tourille. TIAM - A metric for evaluating alignment in text- to-image generation. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, 2024, pages 2878–2887. IEEE, 2024. 1, 6, 7
2024
-
[13]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, De- cember 6-12, 2020, virtual, 2020. 1
2020
-
[14]
spacy: Industrial-strength natural lan- guage processing in python, 2020
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. spacy: Industrial-strength natural lan- guage processing in python, 2020. 4
2020
-
[15]
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Os- tendorf, Ranjay Krishna, and Noah A. Smith. TIFA: accurate and interpretable text-to-image faithfulness evaluation with question answering. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 20349–20360. IEEE, 2023. 1, 2, 5, 6
2023
-
[16]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xi- hui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. InAd- vances in Neural Information Processing Systems 36: An- nual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. 1, 2
2023
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[18]
Elena Izzo, Luca Parolari, Davide Vezzaro, and Lam- berto Ballan. 7bench: a comprehensive benchmark for layout-guided text-to-image models.arXiv preprint arXiv:2508.12919, 2025. 1, 2, 6
-
[19]
Unifiedqa: Crossing format boundaries with a single QA system
Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabhar- wal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. Unifiedqa: Crossing format boundaries with a single QA system. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, pages 1896–1907. Association for Computational Lin- guistics, 2020. 5
2020
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, pages 19730– 19742. PMLR, 2023. 5
2023
-
[21]
GLIGEN: open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. GLIGEN: open-set grounded text-to-image generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17- 24, 2023, pages 22511–22521. IEEE, 2023. 1, 2, 6, 7, 8
2023
-
[22]
Image synthesis from layout with locality- aware mask adaption
Zejian Li, Jingyu Wu, Immanuel Koh, Yongchuan Tang, and Lingyun Sun. Image synthesis from layout with locality- aware mask adaption. InICCV, 2021. 2
2021
-
[23]
LLM- grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. LLM- grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. Trans. Mach. Learn. Res., 2024, 2024. 1, 2
2024
-
[24]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. InComputer Vision - ECCV 2014 - 13th Eu- ropean Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, pages 740–755. Springer, 2014. 2
2014
-
[25]
Matthias Minderer, Alexey A. Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. Simple open-vocabulary object detection with vision transformers.CoRR, abs/2205.06230, 2022. 6
-
[26]
Gritsenko, and Neil Houlsby
Matthias Minderer, Alexey A. Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection. InThirty-seventh Conference on Neural Information Processing Systems,
-
[27]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: towards photorealistic image genera- tion and editing with text-guided diffusion models.CoRR, abs/2112.10741, 2021. 1
work page internal anchor Pith review arXiv 2021
-
[28]
Harlequin: Color-driven generation of synthetic data for referring ex- pression comprehension
Luca Parolari, Elena Izzo, and Lamberto Ballan. Harlequin: Color-driven generation of synthetic data for referring ex- pression comprehension. InPattern Recognition - 27th In- ternational Conference, ICPR 2024, Kolkata, India, Decem- ber 1-5, 2024, Proceedings, Part XVIII, pages 292–307. Springer, 2024. 1
2024
-
[29]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.CoRR, abs/2306.14824, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[30]
Grounded text-to-image synthesis with attention refocusing
Quynh Phung, Songwei Ge, and Jia-Bin Huang. Grounded text-to-image synthesis with attention refocusing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 7932–7942. IEEE, 2024. 2, 6, 7, 8
2024
-
[31]
Plummer, Liwei Wang, Chris M
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspon- dences for richer image-to-sentence models.Int. J. Comput. Vis., 123(1):74–93, 2017. 4
2017
-
[32]
Weakly-supervised visual- textual grounding with semantic prior refinement
Davide Rigoni, Luca Parolari, Luciano Serafini, Alessandro Sperduti, and Lamberto Ballan. Weakly-supervised visual- textual grounding with semantic prior refinement. In34th British Machine Vision Conference 2023, BMVC 2023, Ab- erdeen, UK, November 20-24, 2023, page 229. BMV A Press,
2023
-
[33]
A new interpretation of average preci- sion
Stephen Robertson. A new interpretation of average preci- sion. InProceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, SIGIR 2008, Singapore, July 20-24, 2008, pages 689–690. ACM, 2008. 2
2008
-
[34]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022. 1, 6, 7, 8
2022
-
[35]
Denton, , et al
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, , et al. Photorealistic text-to- image diffusion models with deep language understanding. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys- tems 2022, NeurIPS 2022, New Orleans, LA, USA, Novem- ber 28 - December...
2022
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[37]
Lin- ear spaces of meanings: Compositional structures in vision- language models
Matthew Trager, Pramuditha Perera, Luca Zancato, Alessan- dro Achille, Parminder Bhatia, and Stefano Soatto. Lin- ear spaces of meanings: Compositional structures in vision- language models. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, 2023. 3
2023
-
[38]
ConceptMix: A compositional image generation benchmark with controllable difficulty
Xindi Wu, Dingli Yu, Yangsibo Huang, Olga Russakovsky, and Sanjeev Arora. ConceptMix: A compositional image generation benchmark with controllable difficulty. InAd- vances in Neural Information Processing Systems 38: An- nual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024. 1, 2
2024
-
[39]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion
Jinheng Xie, Yuexiang Li, Yawen Huang, Haozhe Liu, Wen- tian Zhang, Yefeng Zheng, and Mike Zheng Shou. Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. InIEEE/CVF International Conference on Com- puter Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 7418–7427. IEEE, 2023. 1, 4, 6, 7, 8
2023
-
[40]
Hui Zhang, Dexiang Hong, Tingwei Gao, Yitong Wang, Jie Shao, Xinglong Wu, Zuxuan Wu, and Yu-Gang Jiang. CreatiLayout: Siamese multimodal diffusion transformer for creative layout-to-image generation.CoRR, abs/2412.03859,
-
[41]
MIGC: multi-instance generation controller for text- to-image synthesis
Dewei Zhou, You Li, Fan Ma, Xiaoting Zhang, and Yi Yang. MIGC: multi-instance generation controller for text- to-image synthesis. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6818–6828. IEEE, 2024. 1, 2, 6, 7, 8
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.