Recognition: unknown
Self-DACE++: Robust Low-Light Enhancement via Efficient Adaptive Curve Estimation
Pith reviewed 2026-05-07 16:43 UTC · model grok-4.3
The pith
Enhanced adaptive curves with randomized training enable real-time low-light image enhancement that outperforms prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
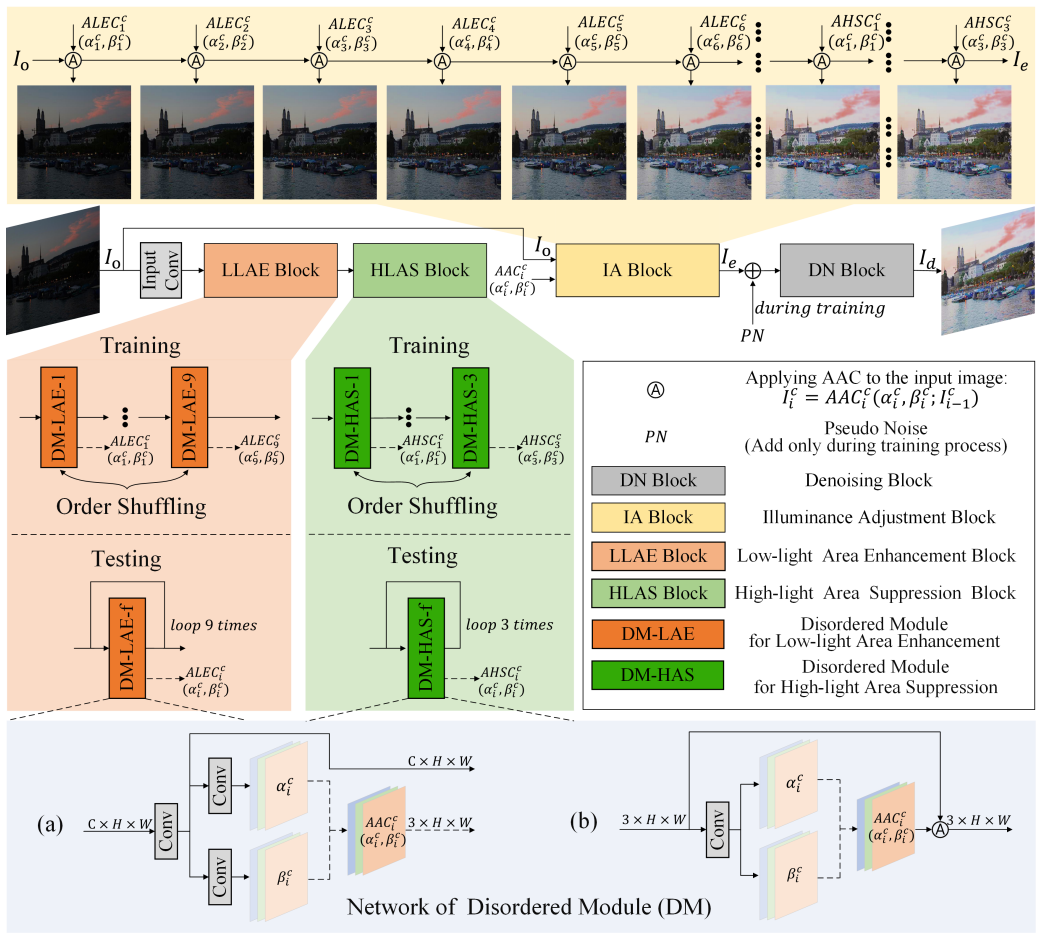
Self-DACE++ shows that enhanced Adaptive Adjustment Curves governed by few parameters, when trained via randomized order with network fusion into an iterative structure and paired with a Retinex-grounded loss plus dedicated denoising, produce higher-quality enhanced images than previous state-of-the-art techniques and run at real-time speeds on standard hardware.
What carries the argument
Enhanced Adaptive Adjustment Curves (AACs) with minimal trainable parameters that adjust dynamic range while preserving color fidelity, structure, and naturalness.
If this is right
- Enhanced images maintain better color accuracy and structural detail than earlier curve-based enhancement techniques.
- The compressed iterative structure supports real-time processing suitable for live camera feeds.
- Noise common in dark areas is reduced without introducing visible artifacts or color shifts.
- Training requires no paired bright and dark images because the framework is fully unsupervised.
- Quantitative scores on standard benchmark datasets exceed those reported for existing state-of-the-art methods.
Where Pith is reading between the lines
- The few-parameter curve design could be adapted to related tasks such as video frame enhancement if temporal consistency is added to the iterative steps.
- Because the model is lightweight, it may run directly on mobile devices for on-the-fly photo correction in consumer cameras.
- The Retinex-based objective might transfer to other physics-inspired image problems like dehazing or underwater restoration.
- If the denoising module generalizes, it could simplify pipelines that currently chain separate noise reduction after enhancement.
Load-bearing premise
The randomized order training and network fusion successfully compress the model into an efficient iterative structure without any drop in quality, and the Retinex objective plus denoising module removes dark-region noise without creating new artifacts.
What would settle it
Apply the released code to a new collection of real low-light photographs and check whether its visual quality or standard metrics fall below those of current real-time competitors, or whether inference time exceeds real-time thresholds on typical consumer hardware.
Figures


read the original abstract
In this paper, we present Self-DACE++, an improved unsupervised and lightweight framework for Low-Light Image Enhancement (LLIE), building upon our previous Self-Reference Deep Adaptive Curve Estimation (Self-DACE). To better address the trade-off between computational efficiency and restoration quality, Self-DACE++ introduces enhanced Adaptive Adjustment Curves (AACs). These curves, governed by minimal trainable parameters, flexibly adjust the dynamic range while preserving the color fidelity, structural integrity, and naturalness of the enhanced images. To achieve an extremely lightweight architecture without sacrificing performance, we propose a randomized order training strategy coupled with a network fusion mechanism, which compresses the model into an efficient iterative inference structure. Furthermore, we formulate a physics-grounded objective function based on Retinex theory and incorporate a dedicated denoising module to effectively estimate and suppress latent noise in dark regions. Extensive qualitative and quantitative evaluations on multiple real-world benchmark datasets demonstrate that Self-DACE++ outperforms existing state-of-the-art methods, delivering superior enhancement quality with real-time inference capability. The code is available at https://github.com/John-Wendell/Self-DACE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Self-DACE++, an improved unsupervised and lightweight framework for low-light image enhancement building on Self-DACE. It introduces enhanced Adaptive Adjustment Curves (AACs) controlled by minimal trainable parameters to adjust dynamic range while preserving color fidelity and structure. A randomized-order training strategy combined with network fusion compresses the model into an efficient iterative inference pipeline. A physics-grounded Retinex-based objective is paired with a dedicated denoising module to suppress noise in dark regions. Extensive qualitative and quantitative evaluations on multiple real-world benchmarks are reported to show outperformance over state-of-the-art methods together with real-time inference.
Significance. If the reported gains and noise-handling claims hold after verification, the work would be significant for practical low-light enhancement on edge devices, as it advances unsupervised curve-based methods with explicit efficiency mechanisms and provides public code for reproducibility.
major comments (2)
- [§4] §4 (Retinex objective and denoising module): The central claim of superior enhancement quality rests on the Retinex-based objective plus dedicated denoising module accurately estimating and suppressing latent noise in dark regions without new artifacts or color shifts. Retinex decomposition is inherently ill-posed under heavy noise; the unsupervised formulation with minimal parameters risks under-constrained solutions. No ablation on synthetic heavy-noise cases, residual-noise metrics, or explicit failure-case analysis is provided to substantiate the assumption.
- [§3.3] §3.3 (randomized order training and network fusion): The assertion that randomized-order training coupled with network fusion successfully compresses the model into an efficient iterative structure without sacrificing performance is load-bearing for the real-time claim. Direct before/after compression comparisons on identical benchmarks and datasets are needed to confirm performance preservation.
minor comments (2)
- [Abstract] The abstract states 'real-time inference capability' but does not report concrete FPS or latency numbers on specified hardware; adding these in §5 would strengthen the efficiency claim.
- Notation for the AAC parameters and the fusion operation could be introduced earlier with a clear table of trainable parameter counts to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on Self-DACE++. We address each major comment point by point below and commit to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [§4] §4 (Retinex objective and denoising module): The central claim of superior enhancement quality rests on the Retinex-based objective plus dedicated denoising module accurately estimating and suppressing latent noise in dark regions without new artifacts or color shifts. Retinex decomposition is inherently ill-posed under heavy noise; the unsupervised formulation with minimal parameters risks under-constrained solutions. No ablation on synthetic heavy-noise cases, residual-noise metrics, or explicit failure-case analysis is provided to substantiate the assumption.
Authors: We agree that Retinex decomposition remains ill-posed under heavy noise and that an unsupervised formulation with few parameters can risk under-constrained solutions. Our design pairs the Retinex-grounded objective with a dedicated denoising module to target latent noise in dark regions while preserving color and structure. Evaluations were performed on real-world benchmarks containing natural noise, yet we acknowledge the absence of targeted synthetic heavy-noise ablations, residual-noise metrics, and explicit failure-case analysis. We will add these elements to the revised manuscript to provide stronger substantiation. revision: yes
-
Referee: [§3.3] §3.3 (randomized order training and network fusion): The assertion that randomized-order training coupled with network fusion successfully compresses the model into an efficient iterative structure without sacrificing performance is load-bearing for the real-time claim. Direct before/after compression comparisons on identical benchmarks and datasets are needed to confirm performance preservation.
Authors: The randomized-order training and network fusion mechanism are intended to produce a lightweight iterative inference pipeline while retaining performance. The manuscript reports results for the final compressed model against state-of-the-art methods. To directly verify preservation, we will include explicit before-and-after performance comparisons on the same benchmarks and datasets in the revised version. revision: yes
Circularity Check
Minor self-citation to prior Self-DACE work; new components (AACs, randomized training, Retinex objective) are independently specified
full rationale
The derivation introduces enhanced Adaptive Adjustment Curves with minimal trainable parameters, a randomized-order training strategy plus network fusion for iterative inference, and a Retinex-based objective with dedicated denoising module. None of these reduce by construction to quantities fitted from the cited prior Self-DACE result or to self-definitions. The central performance claim rests on the new architecture and objective rather than on a self-citation chain. Public code availability supplies an external check. This yields only a minor self-citation that is not load-bearing, consistent with score 2.
Axiom & Free-Parameter Ledger
free parameters (1)
- minimal trainable parameters for AACs
axioms (1)
- domain assumption Retinex theory decomposes images into reflectance and illumination components
Reference graph
Works this paper leans on
-
[1]
Self-reference deep adaptive curve estimation for low-light image enhancement,
J. Wen, C. Wu, T. Zhang, Y . Yu, and P. Swierczynski, “Self-reference deep adaptive curve estimation for low-light image enhancement,”arXiv preprint arXiv:2308.08197, 2023
-
[2]
Illumicurvenet: Low-light image enhancement of lunar permanently shadowed regions using a self-guided loss framework,
S. Jain, S. Jain, A. Prajapati, G. Singh, and D. Kumar Vishwakarma, “Illumicurvenet: Low-light image enhancement of lunar permanently shadowed regions using a self-guided loss framework,” in2025 Inter- national Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–8
2025
-
[3]
A multi-exposure generation and fusion method for low-light image enhancement,
H. Jin, L. Li, H. Su, Y . Zhang, Z. Xiao, and B. Wang, “A multi-exposure generation and fusion method for low-light image enhancement,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–7
2024
-
[4]
An image denoising and enhancement approach for dynamic low-light environment,
J. Wang, W. Liang, X. Wang, and Z. Yang, “An image denoising and enhancement approach for dynamic low-light environment,” in2022 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC). IEEE, 2022, pp. 6–11
2022
-
[5]
Rellie: Deep reinforcement learning for customized low-light image enhancement,
R. Zhang, L. Guo, S. Huang, and B. Wen, “Rellie: Deep reinforcement learning for customized low-light image enhancement,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2429–2437
2021
-
[6]
B ´ezierce: Low-light image en- hancement via zero-reference b ´ezier curve estimation,
X. Gao, K. Zhao, L. Han, and J. Luo, “B ´ezierce: Low-light image en- hancement via zero-reference b ´ezier curve estimation,”Sensors, vol. 23, no. 23, p. 9593, 2023
2023
-
[7]
Optimized bezier curve based intensity mapping scheme for low light image enhance- ment,
M. Veluchamy, A. K. Bhandari, and B. Subramani, “Optimized bezier curve based intensity mapping scheme for low light image enhance- ment,”IEEE Transactions on Emerging Topics in Computational Intel- ligence, vol. 6, no. 3, pp. 602–612, 2021
2021
-
[8]
Learning to adapt to light,
K.-F. Yang, C. Cheng, S.-X. Zhao, H.-M. Yan, X.-S. Zhang, and Y .-J. Li, “Learning to adapt to light,”International Journal of Computer Vision (IJCV), vol. 131, no. 4, pp. 1022–1041, 2023
2023
-
[9]
Zero- reference deep curve estimation for low-light image enhancement,
C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, and R. Cong, “Zero- reference deep curve estimation for low-light image enhancement,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1780–1789
2020
-
[10]
Learning to enhance low-light image via zero-reference deep curve estimation,
C. Li, C. Guo, and C. C. Loy, “Learning to enhance low-light image via zero-reference deep curve estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4225–4238, 2021
2021
-
[11]
Automatic contrast enhancement of low-light images based on local statistics of wavelet coefficients,
A. Łoza, D. R. Bull, P. R. Hill, and A. M. Achim, “Automatic contrast enhancement of low-light images based on local statistics of wavelet coefficients,”Digital Signal Processing, vol. 23, no. 6, pp. 1856–1866, 2013
2013
-
[12]
Zero- shot restoration of back-lit images using deep internal learning,
L. Zhang, L. Zhang, X. Liu, Y . Shen, S. Zhang, and S. Zhao, “Zero- shot restoration of back-lit images using deep internal learning,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1623–1631
2019
-
[13]
Lime: Low-light image enhancement via illumination map estimation,
X. Guo, Y . Li, and H. Ling, “Lime: Low-light image enhancement via illumination map estimation,”IEEE Transactions on Image Processing (TIP), vol. 26, no. 2, pp. 982–993, 2016
2016
-
[14]
Kindling the darkness: A practical low-light image enhancer,
Y . Zhang, J. Zhang, and X. Guo, “Kindling the darkness: A practical low-light image enhancer,” inProceedings of the 27th ACM international conference on multimedia, 2019, pp. 1632–1640
2019
-
[15]
Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhance- ment,
R. Liu, L. Ma, J. Zhang, X. Fan, and Z. Luo, “Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhance- ment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 10 561–10 570
2021
-
[16]
Toward fast, flexible, and robust low-light image enhancement,
L. Ma, T. Ma, R. Liu, X. Fan, and Z. Luo, “Toward fast, flexible, and robust low-light image enhancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5637–5646
2022
-
[17]
Structure-texture aware network for low-light image enhancement,
K. Xu, H. Chen, C. Xu, Y . Jin, and C. Zhu, “Structure-texture aware network for low-light image enhancement,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 8, pp. 4983– 4996, 2022
2022
-
[18]
Low-light image enhancement via structure modeling and guidance,
X. Xu, R. Wang, and J. Lu, “Low-light image enhancement via structure modeling and guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 9893– 9903
2023
-
[19]
Semantically contrastive learning for low-light image enhancement,
D. Liang, L. Li, M. Wei, S. Yang, L. Zhang, W. Yang, Y . Du, and H. Zhou, “Semantically contrastive learning for low-light image enhancement,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1555–1563
2022
-
[20]
Learning semantic-aware knowledge guidance for low-light image en- hancement,
Y . Wu, C. Pan, G. Wang, Y . Yang, J. Wei, C. Li, and H. T. Shen, “Learning semantic-aware knowledge guidance for low-light image en- hancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 1662–1671
2023
-
[21]
Enlightengan: Deep light enhancement without paired supervision,
Y . Jiang, X. Gong, D. Liu, Y . Cheng, C. Fang, X. Shen, J. Yang, P. Zhou, and Z. Wang, “Enlightengan: Deep light enhancement without paired supervision,”IEEE Transactions on Image Processing (TIP), vol. 30, pp. 2340–2349, 2021
2021
-
[22]
Le-gan: unsupervised low- light image enhancement network using attention module and identity invariant loss,
Y . Fu, Y . Hong, L. Chen, and S. You, “Le-gan: unsupervised low- light image enhancement network using attention module and identity invariant loss,”Knowledge-Based Systems, vol. 240, p. 108010, 2022
2022
-
[23]
Global structure- aware diffusion process for low-light image enhancement,
J. Hou, Z. Zhu, J. Hou, H. Liu, H. Zeng, and H. Yuan, “Global structure- aware diffusion process for low-light image enhancement,”Advances in Neural Information Processing Systems (NIPS), vol. 36, 2024
2024
-
[24]
Ts-diff: Two-stage diffusion model for low-light raw image enhancement,
Y . Li, Z. Zhang, J. Xia, J. Cheng, Q. Wu, J. Li, Y . Tian, and H. Kong, “Ts-diff: Two-stage diffusion model for low-light raw image enhancement,”2025 International Joint Conference on Neural Networks (IJCNN), pp. 1–8, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:278368190
2025
-
[25]
Learning frequency-aware representation for low- light image enhancement,
J. Wang and X. Tang, “Learning frequency-aware representation for low- light image enhancement,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–8
2024
-
[26]
Ultra-high- definition low-light image enhancement: A benchmark and transformer- based method,
T. Wang, K. Zhang, T. Shen, W. Luo, B. Stenger, and T. Lu, “Ultra-high- definition low-light image enhancement: A benchmark and transformer- based method,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 3, 2023, pp. 2654–2662
2023
-
[27]
Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,
Y . Cai, H. Bian, J. Lin, H. Wang, R. Timofte, and Y . Zhang, “Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 12 504–12 513
2023
-
[28]
Attention-capsule network for low-light image recognition,
S. Shen, Z. Jiang, X. Lei, X. Wu, and Y . He, “Attention-capsule network for low-light image recognition,” in2023 International Joint Conference on Neural Networks (IJCNN), 2023, pp. 1–7
2023
-
[29]
Implicit multi- spectral transformer: An lightweight and effective visible to infrared image translation model,
Y . Chen, P. Chen, X. Zhou, Y . Lei, Z. Zhou, and M. Li, “Implicit multi- spectral transformer: An lightweight and effective visible to infrared image translation model,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–8
2024
-
[30]
Beyond brightening low-light images,
Y . Zhang, X. Guo, J. Ma, W. Liu, and J. Zhang, “Beyond brightening low-light images,”International Journal of Computer Vision (IJCV), vol. 129, no. 4, pp. 1013–1037, 2021
2021
-
[31]
Uretinex- net: Retinex-based deep unfolding network for low-light image enhance- ment,
W. Wu, J. Weng, P. Zhang, X. Wang, W. Yang, and J. Jiang, “Uretinex- net: Retinex-based deep unfolding network for low-light image enhance- ment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5901–5910
2022
-
[32]
Snr-aware low-light image enhancement,
X. Xu, R. Wang, C.-W. Fu, and J. Jia, “Snr-aware low-light image enhancement,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 17 714–17 724
2022
-
[33]
Learning a simple low-light image enhancer from paired low-light instances,
Z. Fu, Y . Yang, X. Tu, Y . Huang, X. Ding, and K.-K. Ma, “Learning a simple low-light image enhancer from paired low-light instances,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (CVPR), June 2023, pp. 22 252–22 261
2023
-
[34]
Zero-shot restoration of underexposed images via robust retinex decomposition,
A. Zhu, L. Zhang, Y . Shen, Y . Ma, S. Zhao, and Y . Zhou, “Zero-shot restoration of underexposed images via robust retinex decomposition,” in 2020 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2020, pp. 1–6
2020
-
[35]
Learning a deep single image contrast enhancer from multi-exposure images,
J. Cai, S. Gu, and L. Zhang, “Learning a deep single image contrast enhancer from multi-exposure images,”IEEE Transactions on Image Processing (TIP), vol. 27, no. 4, pp. 2049–2062, 2018
2049
-
[36]
Deep retinex decomposition for low-light enhancement,
W. Y . Chen Wei, Wenjing Wang and J. Liu, “Deep retinex decomposition for low-light enhancement,” inBritish Machine Vision Conference (BMVC), 2018
2018
-
[37]
Y . Yuan, W. Yang, W. Ren, J. Liu, W. J. Scheirer, and Z. Wang, “Ug 2+ track 2: A collective benchmark effort for evaluating and advancing image understanding in poor visibility environments,”arXiv preprint arXiv:1904.04474, 2019
-
[38]
Retinaface: Single-shot multi-level face localisation in the wild,
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou, “Retinaface: Single-shot multi-level face localisation in the wild,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5203–5212
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.