Recognition: unknown
Safe-Support Q-Learning: Learning without Unsafe Exploration
Pith reviewed 2026-05-07 16:30 UTC · model grok-4.3
The pith
Safe-support Q-learning trains reinforcement learning agents without ever visiting unsafe states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the assumption that trajectories generated by the safe-support behavior policy stay inside the safe set, a KL-regularized Bellman target produces Q-values that support sufficient safe exploration; extracting a policy from those Q-values then yields an optimal safe policy without unsafe state visits during training.
What carries the argument
The KL-regularized Bellman target that constrains Q-function updates to remain close to the safe-support behavior policy, followed by separate parametric policy extraction from the trained Q-values.
If this is right
- The method adapts to both discrete and continuous action spaces as well as varied behavior policy types.
- Learning remains stable with well-calibrated value estimates throughout training.
- Final policies exhibit safer behavior while delivering comparable or superior task performance to existing safe RL baselines.
- Sufficient exploration inside the safe region occurs without requiring the behavior policy to be near-optimal.
Where Pith is reading between the lines
- The two-stage separation of Q-training from policy extraction could allow reuse of the same Q-function for multiple downstream tasks inside the safe set.
- In environments where defining an exact safe set is difficult, the approach would require an outer mechanism to maintain the safe-support assumption.
- Because value estimates stay calibrated, the method may reduce the sample complexity of subsequent safe policy improvement steps compared with methods that mix safe and unsafe data.
Load-bearing premise
The behavior policy's induced trajectories must remain inside the predefined safe set for the entire training process.
What would settle it
Any observation of the agent entering an unsafe state while following the safe-support behavior policy during Q-function training would invalidate the safety guarantee.
Figures


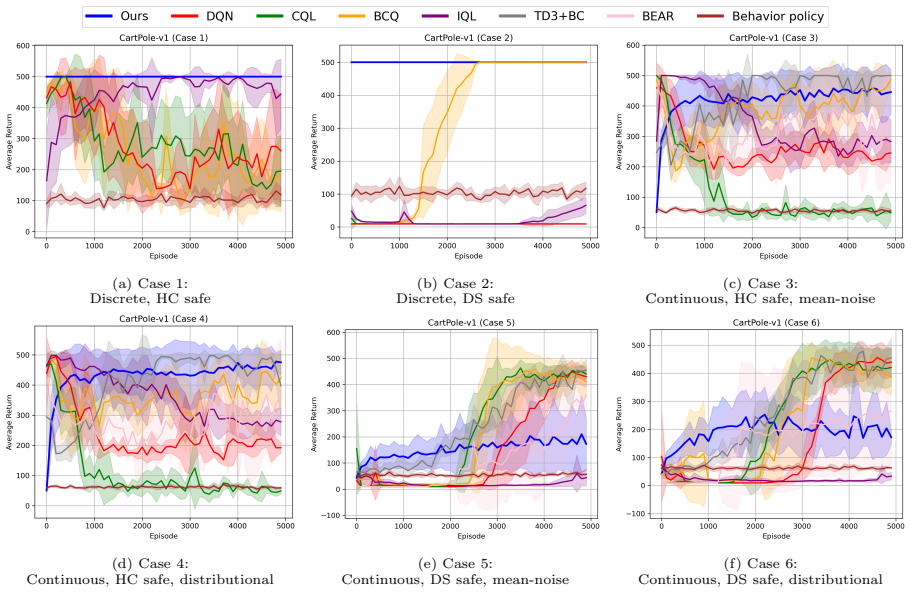

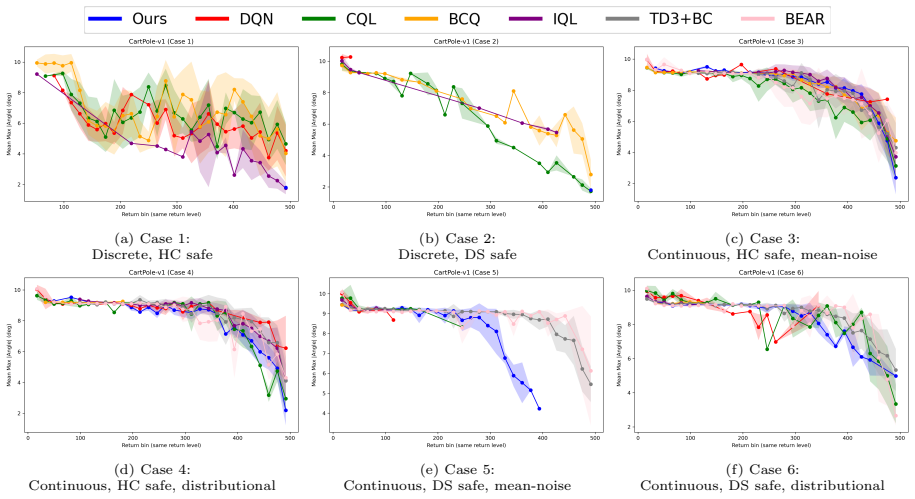



read the original abstract
Ensuring safety during reinforcement learning (RL) training is critical in real-world applications where unsafe exploration can lead to devastating outcomes. While most safe RL methods mitigate risk through constraints or penalization, they still allow exploration of unsafe states during training. In this work, we adopt a stricter safety requirement that eliminates unsafe state visitation during training. To achieve this goal, we propose a Q-learning-based safe RL framework that leverages a behavior policy supported on a safe set. Under the assumption that the induced trajectories remain within the safe set, this policy enables sufficient exploration within the safe region without requiring near-optimality. We adopt a two-stage framework in which the Q-function and policy are trained separately. Specifically, we introduce a KL-regularized Bellman target that constrains the Q-function to remain close to the behavior policy. We then derive the policy induced from the trained Q-values and propose a parametric policy extraction method to approximate the optimal policy. Our approach provides a unified framework that can be adapted to different action spaces and types of behavior policies. Experimental results demonstrate that the proposed method achieves stable learning and well-calibrated value estimates and yields safer behavior with comparable or better performance than existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Safe-Support Q-Learning, a Q-learning framework for safe RL that eliminates unsafe state visitation during training by using a behavior policy whose support lies in a safe set. Under the assumption that induced trajectories remain safe, it employs a two-stage procedure: a KL-regularized Bellman target to keep the Q-function close to the behavior policy, followed by derivation and parametric extraction of an optimal policy. The method is presented as a unified framework adaptable to different action spaces and behavior policies, with experiments claimed to demonstrate stable learning, well-calibrated value estimates, and safer behavior with comparable or better performance than baselines.
Significance. If the safety invariant holds and the two-stage procedure can be shown to preserve safe support without additional enforcement, the work would provide a meaningful advance over constraint- or penalty-based safe RL methods by enabling sufficient exploration strictly within safe regions without requiring near-optimal behavior policies. The unified framework claim could increase applicability across discrete/continuous actions and policy types, but the absence of derivations or verification details limits current assessment of its potential impact.
major comments (2)
- [Abstract] Abstract: The central claim of 'learning without Unsafe Exploration' and elimination of unsafe state visitation rests on the unverified assumption that 'induced trajectories remain within the safe set.' The described two-stage procedure (KL-regularized Bellman target plus parametric policy extraction) supplies no projection, recovery policy, or invariant-preserving mechanism to maintain safe support under function approximation, stochastic transitions, or continuous action spaces. If this assumption fails, the safety guarantee does not hold.
- [Abstract] Abstract and manuscript body: No equations, derivations, proofs, experimental setup details, error bars, or ablation studies are supplied, so the performance claims (stable learning, well-calibrated values, safer behavior) and the assertion that the KL regularization plus extraction yields sufficient safe exploration cannot be evaluated or reproduced from the given text.
minor comments (1)
- [Abstract] Abstract: The phrase 'well-calibrated value estimates' is used without defining the calibration metric or reporting how it was measured, reducing clarity of the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below, clarifying the role of our stated assumptions and the content of the full manuscript while noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'learning without Unsafe Exploration' and elimination of unsafe state visitation rests on the unverified assumption that 'induced trajectories remain within the safe set.' The described two-stage procedure (KL-regularized Bellman target plus parametric policy extraction) supplies no projection, recovery policy, or invariant-preserving mechanism to maintain safe support under function approximation, stochastic transitions, or continuous action spaces. If this assumption fails, the safety guarantee does not hold.
Authors: We agree that the safety claim is conditional on the assumption that trajectories induced by the behavior policy remain in the safe set; this assumption is stated explicitly in the abstract and introduction. The KL-regularized Bellman target is intended to keep the learned Q-function close to the behavior policy in a manner that preserves support on the safe set, and the subsequent policy extraction step derives an optimal policy within that support. However, we acknowledge that the manuscript does not provide a formal invariant proof or recovery mechanism for cases where function approximation or stochasticity could violate the assumption. We will add a dedicated limitations section discussing the conditions under which the assumption holds (e.g., deterministic safe behavior policies or environments with absorbing unsafe states) and potential failure modes under approximation. revision: partial
-
Referee: [Abstract] Abstract and manuscript body: No equations, derivations, proofs, experimental setup details, error bars, or ablation studies are supplied, so the performance claims (stable learning, well-calibrated values, safer behavior) and the assertion that the KL regularization plus extraction yields sufficient safe exploration cannot be evaluated or reproduced from the given text.
Authors: The full manuscript contains the derivations of the KL-regularized Bellman target, the closed-form policy extraction, and the parametric approximation method, along with the experimental protocol. The abstract is intentionally concise and omits these details. That said, we accept that the current version lacks error bars on the reported metrics, explicit ablation studies on the KL coefficient, and full hyperparameter tables. We will expand the experiments section with these elements, including standard deviations over multiple seeds and ablations on the regularization strength, to improve reproducibility. revision: yes
Circularity Check
No significant circularity; safety guarantee is conditional on an explicitly stated external assumption
full rationale
The paper states its core safety property under the explicit assumption that 'the induced trajectories remain within the safe set' and that the behavior policy is 'supported on a safe set.' This assumption is presented as given rather than derived from the KL-regularized Bellman target or the subsequent parametric policy extraction. No equations appear in the visible text, so no reduction of any 'prediction' to a fitted input by construction can be exhibited. The two-stage procedure is offered as a method that works inside the assumed safe support; it does not claim to enforce or derive the support invariant itself. The framework is therefore self-contained as a conditional construction whose validity rests on the external assumption plus experimental validation, not on any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The induced trajectories remain within the safe set
Reference graph
Works this paper leans on
-
[1]
[3]Boyd, S., and V andenberghe, L.Convex optimization
[2]Bharadhwaj, H., Kumar, A., Rhinehart, N., Levine, S., Shkurti, F., and Garg, A.Conservative safety critics for exploration.arXiv preprint arXiv:2010.14497(2020). [3]Boyd, S., and V andenberghe, L.Convex optimization. Cambridge university press,
-
[2]
[5]Chow, Y., Ghavamzadeh, M., Janson, L., and Pavone, M.Risk-constrained reinforcement learning with percentile risk criteria.Journal of Machine Learning Research 18, 167 (2018), 1–51. [6]Chow, Y., Nachum, O., Duenez-Guzman, E., and Ghavamzadeh, M.A Lyapunov-based approach to safe reinforcement learning.Advances in neural information processing systems 31...
-
[3]
Offline Reinforcement Learning with Implicit Q-Learning
[18]Kim, D., Lee, K., and Oh, S.Trust region-based safe distributional reinforcement learning for multiple constraints. Advances in neural information processing systems 36(2024). 14 [19]Kim, D., and Oh, S.Efficient off-policy safe reinforcement learning using trust region conditional value at risk.IEEE Robotics and Automation Letters 7, 3 (2022), 7644–76...
work page internal anchor Pith review arXiv 2024
-
[4]
[25]Lee, D.Unified ODE analysis of smooth Q-learning algorithms.arXiv preprint arXiv:2404.14442(2024). [26]Levine, S., Kumar, A., Tucker, G., and Fu, J.Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643(2020). [27]Li, S., and Bastani, O.Robust model predictive shielding for safe reinforcemen...
work page internal anchor Pith review arXiv 2024
-
[5]
[37]Thananjeyan, B., Balakrishna, A., Rosolia, U., Li, F., McAllister, R., Gonzalez, J. E., Levine, S., Borrelli, F., and Goldberg, K.Safety augmented value estimation from demonstrations: Safe deep model-based RL for sparse cost robotic tasks.IEEE Robotics and Automation Letters 5, 2 (2020), 3612–3619. [38]Turchetta, M., Kolobov, A., Shah, S., Krause, A....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.