Recognition: unknown
CoRE: A Fine-Grained Code Reasoning Benchmark Beyond Output Prediction
Pith reviewed 2026-05-07 15:57 UTC · model grok-4.3
The pith
Large language models exhibit inconsistent code reasoning across equivalent implementations and fail to track intermediate execution states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
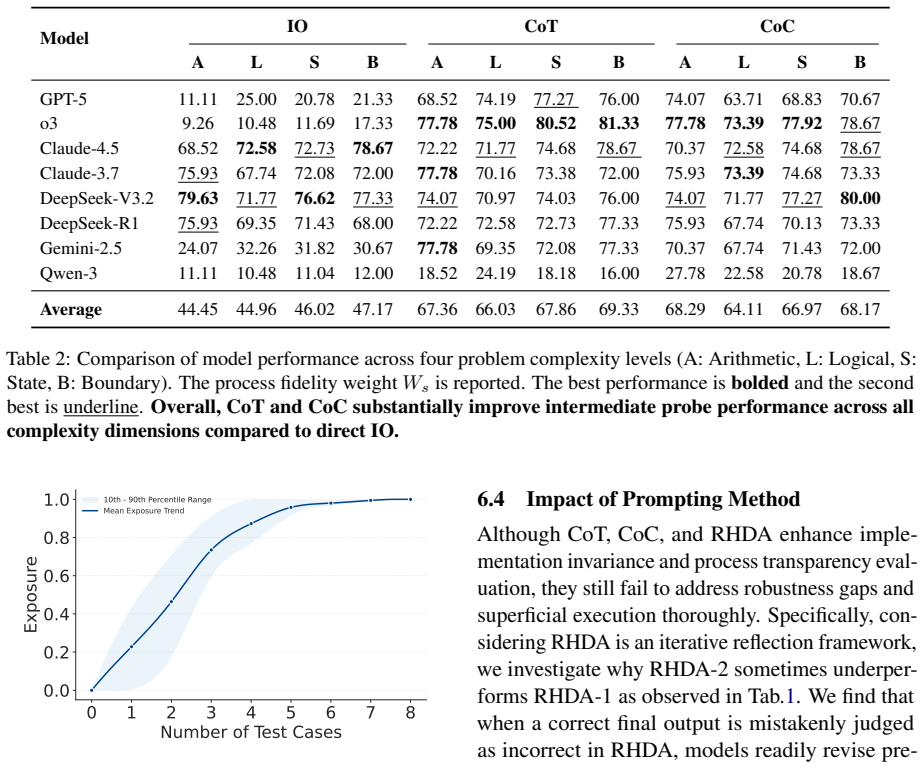
Through the CoRE benchmark, which measures implementation invariance and process transparency, the authors demonstrate that large language models display a robustness gap in performance across equivalent code implementations and engage in superficial execution by producing correct outputs without accurately reasoning about intermediate states. These findings establish that output-only evaluations are insufficient for assessing code reasoning and highlight the need for benchmarks that probe deeper into the reasoning process.
What carries the argument
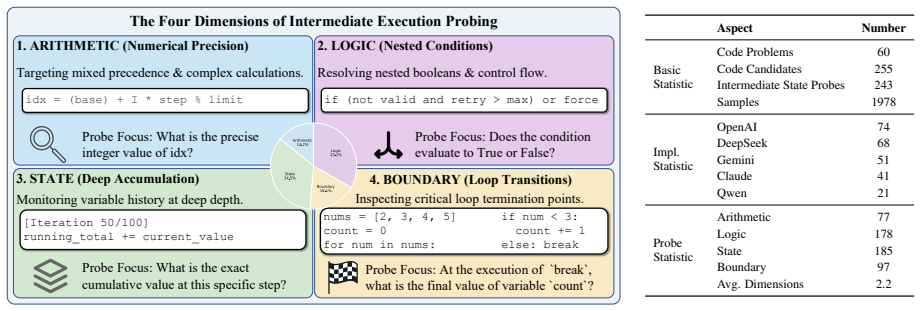
The CoRE benchmark, which evaluates code reasoning via implementation invariance across equivalent code variants and process transparency through intermediate state questions.
If this is right
- Output-only evaluations do not sufficiently assess code reasoning in large language models.
- Models show substantial variation in performance when presented with functionally equivalent but differently implemented code.
- Correct final outputs often mask incorrect reasoning about execution intermediates.
- New benchmarks are required to evaluate robust and faithful code reasoning.
Where Pith is reading between the lines
- Practitioners relying on LLMs for code tasks may need to implement additional verification steps beyond output checking.
- This pattern of superficial reasoning could apply to other structured reasoning tasks such as algorithm simulation or debugging.
- Future model development might benefit from training objectives that explicitly reward accurate intermediate state prediction.
Load-bearing premise
The selected functionally equivalent implementations behave identically in all execution aspects relevant to reasoning, and the intermediate-state questions measure genuine process understanding rather than superficial pattern matching.
What would settle it
An experiment showing that a model achieves consistent high accuracy across multiple equivalent code implementations while also correctly answering detailed questions about every intermediate execution state would challenge the identified limitations.
Figures





read the original abstract
Despite strong performance on code generation tasks, it remains unclear whether large language models (LLMs) genuinely reason about code execution. Existing code reasoning benchmarks primarily evaluate final output correctness under a single canonical implementation, leaving two critical aspects underexplored: (1) whether LLMs can maintain consistency to functionally equivalent implementations, and (2) whether LLMs can accurately reason about intermediate execution states. We introduce \textbf{CoRE}, a \textbf{Co}de \textbf{Re}asoning benchmark that evaluates code reasoning through \textbf{implementation invariance} and \textbf{process transparency}. Extensive evaluations on eight frontier LLMs reveal two fundamental limitations. First, models exhibit a substantial \textbf{robustness gap}, with performance varying significantly across equivalent implementations. Second, we observe \textbf{superficial execution}, where models arrive at correct final outputs without correctly reasoning about intermediate execution states. Together, these findings demonstrate that output-only evaluations are insufficient for assessing code reasoning and position CoRE as a necessary benchmark for evaluating robust and faithful code reasoning.\footnote{Data and code are available at https://github.com/ZJUSig/CoRE.}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoRE, a benchmark for assessing LLMs' code reasoning via implementation invariance (consistency across functionally equivalent code variants) and process transparency (accuracy on intermediate execution states). Evaluations across eight frontier LLMs demonstrate a substantial robustness gap, with performance varying across equivalent implementations, and superficial execution, where models produce correct final outputs without accurate intermediate reasoning. The work argues that output-only evaluations are insufficient and releases data/code at the cited GitHub link.
Significance. If the empirical claims hold after verification, CoRE would be a valuable addition to code reasoning benchmarks by exposing gaps not captured by final-output metrics alone. The public release of data and code strengthens reproducibility and enables follow-on work. The findings align with broader concerns about LLM faithfulness in reasoning tasks but would benefit from tighter controls on task construction to isolate model limitations from benchmark artifacts.
major comments (2)
- [§3] §3 (Benchmark Construction), implementation pairs: The central robustness-gap claim rests on the premise that selected functionally equivalent implementations produce identical answers to all intermediate-state questions. No explicit cross-verification (e.g., execution traces or static analysis confirming invariance of control flow, variable lifetimes, or short-circuit behavior) is described; without it, observed performance drops could reflect legitimate differences in expected intermediate states rather than model failure.
- [§4] §4 (Experiments), data selection and metrics: The abstract and evaluation summary report results on eight models and two limitations, yet the manuscript provides insufficient detail on how code pairs were sampled, how equivalence was operationalized beyond final output, and the precise definition/scoring of 'superficial execution' (e.g., how many intermediate questions must be answered incorrectly to classify a case). This makes it difficult to assess whether the reported gaps are robust or sensitive to task design choices.
minor comments (2)
- [§4] Clarify the exact prompt templates and few-shot examples used for each sub-task (implementation invariance vs. process transparency) to support replication.
- [§3] Add a table summarizing the number of code pairs, languages covered, and average number of intermediate questions per example.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that greater transparency in benchmark construction and evaluation details will strengthen the paper. Below we respond to each major comment and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction), implementation pairs: The central robustness-gap claim rests on the premise that selected functionally equivalent implementations produce identical answers to all intermediate-state questions. No explicit cross-verification (e.g., execution traces or static analysis confirming invariance of control flow, variable lifetimes, or short-circuit behavior) is described; without it, observed performance drops could reflect legitimate differences in expected intermediate states rather than model failure.
Authors: We acknowledge the validity of this concern. The implementation pairs were selected such that they produce identical outputs on the same test suites, and intermediate questions were derived from a canonical execution trace; however, the manuscript does not describe a systematic verification step confirming that all intermediate states are invariant across pairs. In the revised manuscript we will add an appendix containing execution-trace comparisons (via dynamic instrumentation) for the full set of pairs, along with a brief static analysis confirming control-flow and variable-lifetime equivalence. This will directly address the possibility of benchmark artifacts. revision: yes
-
Referee: [§4] §4 (Experiments), data selection and metrics: The abstract and evaluation summary report results on eight models and two limitations, yet the manuscript provides insufficient detail on how code pairs were sampled, how equivalence was operationalized beyond final output, and the precise definition/scoring of 'superficial execution' (e.g., how many intermediate questions must be answered incorrectly to classify a case). This makes it difficult to assess whether the reported gaps are robust or sensitive to task design choices.
Authors: We agree that additional methodological detail is warranted. The original text in §3 and §4 is brief on these points. In the revision we will expand §4 with: (i) the exact sampling procedure (stratified random selection from a curated pool of 200 problems, each with 2–4 implementations), (ii) a formal definition of functional equivalence (identical input–output behavior on a held-out test suite of at least 10 cases), and (iii) the precise scoring rule for superficial execution (a trial is labeled superficial when the final output is correct yet at least one of the intermediate-state questions is answered incorrectly). We will also include a sensitivity table showing that the reported robustness gap and superficial-execution rates remain stable under modest changes to these thresholds. revision: yes
Circularity Check
No circularity: new benchmark with independent empirical claims
full rationale
The paper introduces CoRE as an external benchmark evaluating LLMs on implementation invariance and process transparency via new tasks. Central claims about robustness gaps and superficial execution rest on direct empirical results from eight models rather than any derivation, fitted parameters, or self-referential definitions. No equations, ansatzes, or load-bearing self-citations appear in the provided text; the benchmark is presented as falsifiable with released data and code. The derivation chain is therefore self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Functionally equivalent implementations produce identical execution semantics for the purposes of the benchmark tasks
- domain assumption Correct answers on intermediate execution state questions indicate faithful process reasoning rather than pattern matching
Reference graph
Works this paper leans on
-
[1]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel
IEEE. Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2024. Repairagent: An autonomous, llm- based agent for program repair.arXiv preprint arXiv:2403.17134. Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, and Xin Xia. 2025. Reasoning runtime behavior of a program with llm: How far are we? In2025 IEEE/ACM 47th International Conference on Soft-...
-
[2]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Cruxeval: A benchmark for code reason- ing, understanding and execution.arXiv preprint arXiv:2401.03065. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12...
work page internal anchor Pith review arXiv 2025
-
[3]
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024a. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- ...
work page internal anchor Pith review arXiv 2025
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528– 50652. Yuze Zhao, Tianyun Ji, Wenjun Feng, Zhenya...
work page internal anchor Pith review arXiv 2024
-
[5]
Complex Arithmetic:Lines with mul- tiple operators (e.g., res = (a + b) * c % d) or list indexing with math
-
[6]
Loop Boundaries:The last iteration of a loop, or the state immediately after a loop finishes
-
[7]
Nested Logic:Steps inside a nested loop or a nested if block where context is deep
-
[8]
Compound Conditions:Boolean eval- uations involvingand, or, not
-
[9]
At the end of the 3rd iteration
State Accumulation:A variable modi- fied multiple times (e.g.,total after the 5th iteration). ## Rules: • Answer Integrity:The ‘ground_truth‘ must be extracted EXACTLY from the provided trace. Do not compute it your- self. • Precision:The question must specify the exact context (e.g., "At the end of the 3rd iteration...", "In the evaluation of the conditi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.