Recognition: unknown
Beyond Fidelity: Semantic Similarity Assessment in Low-Level Image Processing
Pith reviewed 2026-05-07 16:59 UTC · model grok-4.3
The pith
Low-level image processing needs evaluation for semantic preservation, not just visual fidelity, via a new triplet-based score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize Semantic Similarity as a new evaluation task for low-level image processing, aimed at measuring whether semantic content is preserved after processing. We present a structured formulation of image semantics based on semantic entities and their relations, and discuss the desired properties and constraints of a valid semantic similarity index. Based on this, we propose T3S, which models image semantics through foreground entities, background entities, and relations by combining semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling.
What carries the argument
Triplet-based Semantic Similarity Score (T3S) that assesses semantic preservation by extracting foreground entities, background entities, and their relations.
If this is right
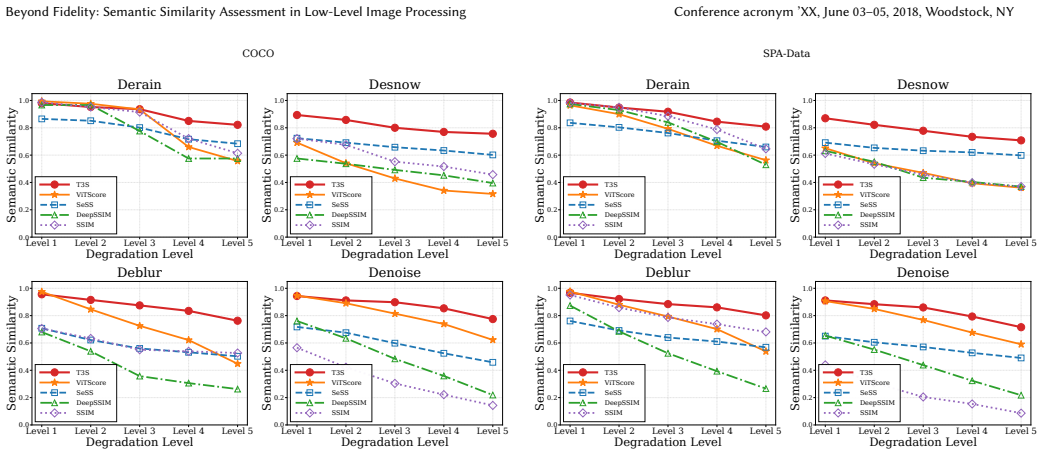
- T3S better reflects progressive semantic changes under diverse degradations compared to existing metrics.
- It consistently outperforms fidelity-oriented metrics and semantic-level baselines in experiments on COCO and SPA-Data.
- Semantic assessment becomes important for evaluating modern low-level vision methods that use generative models.
- Valid semantic similarity indices must satisfy specific properties and constraints derived from the entity-relation formulation.
Where Pith is reading between the lines
- This could lead to new loss functions in training that penalize semantic drift explicitly.
- Similar triplet modeling might apply to assessing semantic consistency in video processing or multimodal data.
- Integration with existing IQA tools could create hybrid metrics balancing fidelity and semantics.
Load-bearing premise
Reliable extraction of semantic entities, foreground-background separation, and open-world class/relation modeling can be done without errors that invalidate the similarity score.
What would settle it
Finding image pairs where T3S gives a high score but human observers see major semantic differences, or where it misses clear semantic loss under degradation.
Figures










read the original abstract
Low-level image processing has long been evaluated mainly from the perspective of visual fidelity. However, with the rise of deep learning and generative models, processed images may preserve perceptual quality while altering semantic content, making conventional Image Quality Assessment (IQA) insufficient for semantic-level assessment. In this paper, we formalize \textit{Semantic Similarity} as a new evaluation task for low-level image processing, aimed at measuring whether semantic content is preserved after processing. We further present a structured formulation of image semantics based on semantic entities and their relations, and discuss the desired properties and constraints of a valid semantic similarity index. Based on this formulation, we propose Triplet-based Semantic Similarity Score (T3S), which models image semantics through foreground entities, background entities, and relations. T3S combines semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling. Experiments on COCO and SPA-Data show that T3S consistently outperforms existing fidelity-oriented metrics and representative semantic-level baselines, while better reflecting progressive semantic changes under diverse degradations. These results highlight the importance of semantic assessment in modern low-level vision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes Semantic Similarity as a new evaluation task for low-level image processing to measure semantic content preservation (distinct from visual fidelity), presents a structured formulation of image semantics via entities and relations, proposes the Triplet-based Semantic Similarity Score (T3S) that integrates semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling, and reports that experiments on COCO and SPA-Data show T3S outperforming fidelity-oriented metrics and semantic baselines while better capturing progressive semantic changes under degradations.
Significance. If the robustness concerns are addressed, T3S could fill an important gap in evaluating modern low-level vision and generative models where perceptual quality is maintained but semantics are altered, providing a concrete metric grounded in entity-relation semantics that aligns better with application needs than traditional IQA.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the claim that T3S 'consistently outperforms' existing metrics and 'better reflecting progressive semantic changes' is presented without any details on the exact T3S computation formula, statistical tests, variance across runs, or controls for errors introduced by the (presumably pre-trained) entity/relation extraction model on degraded inputs.
- [T3S formulation] T3S formulation and desired properties discussion: the listed properties and constraints for a valid semantic similarity index omit any quantitative bound on extraction error tolerance. Since T3S scores are computed from foreground/background entities and relations extracted from the same degraded images used to demonstrate progressive semantic change, the outperformance result is load-bearing on the untested assumption that the extraction pipeline remains accurate as degradation strength increases.
minor comments (1)
- [Abstract] The abstract introduces T3S without immediately expanding the acronym, which appears later in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our presentation of T3S and for raising important robustness considerations. We address each major comment below and have revised the manuscript to incorporate additional details, formulas, statistical analyses, and empirical robustness checks.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim that T3S 'consistently outperforms' existing metrics and 'better reflecting progressive semantic changes' is presented without any details on the exact T3S computation formula, statistical tests, variance across runs, or controls for errors introduced by the (presumably pre-trained) entity/relation extraction model on degraded inputs.
Authors: We agree that the abstract and experiments would benefit from more explicit details. The T3S formula is defined in Section 3.3 as a weighted combination of foreground entity similarity, background entity similarity, and relation similarity (Equation 3), using open-world embeddings from a pre-trained model. To address the concern, we have expanded the abstract to include a concise description of this formulation and revised the experiments section to report paired statistical significance tests (Wilcoxon signed-rank), standard deviations over three independent runs of the extraction pipeline, and a dedicated control experiment measuring entity/relation extraction precision/recall on progressively degraded images from COCO and SPA-Data. revision: yes
-
Referee: [T3S formulation] T3S formulation and desired properties discussion: the listed properties and constraints for a valid semantic similarity index omit any quantitative bound on extraction error tolerance. Since T3S scores are computed from foreground/background entities and relations extracted from the same degraded images used to demonstrate progressive semantic change, the outperformance result is load-bearing on the untested assumption that the extraction pipeline remains accurate as degradation strength increases.
Authors: The properties in Section 3.2 are formulated at the semantic level and intentionally abstract from implementation-specific extraction errors. We acknowledge that no quantitative error-tolerance bound was previously provided. In the revision we add an analysis (new Figure 7 and Appendix C) that reports extraction accuracy versus degradation strength and shows that T3S remains superior to baselines even after injecting the observed extraction error rates; we also derive a simple first-order sensitivity bound relating extraction error to T3S deviation. These additions directly test and bound the assumption underlying the progressive-change experiments. revision: yes
Circularity Check
No significant circularity in T3S derivation chain
full rationale
The paper introduces T3S as a new construction that combines semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling to assess semantic similarity. No equations, definitions, or experimental steps in the manuscript reduce the proposed score to a fitted parameter, self-defined quantity, or load-bearing self-citation from the authors' prior work. The formulation starts from an external structured semantics model and relies on pre-trained extractors whose outputs are treated as independent inputs rather than derived from the current paper's data or claims. Experimental validation on COCO and SPA-Data therefore measures an independent metric rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Image semantics can be decomposed into foreground entities, background entities, and relations between them.
invented entities (1)
-
T3S score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sebastian Bosse, Dominique Maniry, Klaus-Robert Müller, Thomas Wiegand, and Wojciech Samek. 2018. Deep Neural Networks for No-Reference and Full- Reference Image Quality Assessment.IEEE Transactions on Image Processing27, 1 (2018), 206–219. doi:10.1109/TIP.2017.2760518
-
[2]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging Properties in Self-Supervised Vision Transformers. In2021 IEEE/CVF International Conference on Computer Vision (ICCV). 9630–9640. doi:10.1109/ICCV48922.2021.00951
-
[3]
Baoliang Chen, Hanwei Zhu, Lingyu Zhu, Shanshe Wang, Jingshan Pan, and Shiqi Wang. 2025. Debiased Mapping for Full-Reference Image Quality Assessment. IEEE Transactions on Multimedia27 (2025), 2638–2649. doi:10.1109/TMM.2025. 3535280
-
[4]
Weiling Chen, Honggang Liao, Rongfu Lin, Tiesong Zhao, Ke Gu, and Patrick Le Callet. 2025. Utility-Centered Underwater Image Quality Evaluation.IEEE Jour- nal of Oceanic Engineering50, 2 (2025), 743–757. doi:10.1109/JOE.2024.3498273
-
[5]
Weiling Chen, Weitao Lin, Xiaoyi Xu, Liqun Lin, and Tiesong Zhao. 2024. Face Super-Resolution Quality Assessment Based on Identity and Recognizability. IEEE Transactions on Biometrics, Behavior, and Identity Science6, 3 (2024), 364–373. doi:10.1109/TBIOM.2024.3389982
-
[6]
Weiling Chen, Ranwen Zhuang, Weitao Lin, Keke Zhang, Xuejin Wang, and Tiesong Zhao. 2026. Machine Vision-Oriented Image Quality Evaluation for Face Super-Resolution.IEEE Transactions on Biometrics, Behavior, and Identity Science (2026), 1–1. doi:10.1109/TBIOM.2026.3658611
-
[7]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. 2022. Image Quality Assessment: Unifying Structure and Texture Similarity.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 5 (2022), 2567–2581. doi:10.1109/ TPAMI.2020.3045810
-
[8]
Alexey Dosovitskiy et al. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InICLR
2021
-
[9]
Minhao Fan, Wenjing Wang, Wenhan Yang, and Jiaying Liu. 2020. Integrating Semantic Segmentation and Retinex Model for Low-Light Image Enhancement. InProceedings of the 28th ACM International Conference on Multimedia(Seattle, WA, USA)(MM ’20). Association for Computing Machinery, New York, NY, USA, 2317–2325. doi:10.1145/3394171.3413757
-
[10]
Senran Fan, Zhicheng Bao, Chen Dong, Haotai Liang, Xiaodong Xu, and Ping Zhang. 2025. Semantic Similarity Score for Measuring Visual Similarity at Semantic Level.IEEE Internet of Things Journal12, 9 (2025), 12034–12047. doi:10.1109/JIOT.2024.3518543
-
[11]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi
-
[12]
Clipscore: A reference-free evaluation metric for image captioning
CLIPScore: A Reference-free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen- tau Yih (Eds.). Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 7514–7528. doi:10.18653/v1/20...
-
[13]
Jingwen Hou, Henghui Ding, Weisi Lin, Weide Liu, and Yuming Fang. 2022. Distilling Knowledge From Object Classification to Aesthetics Assessment.IEEE Transactions on Circuits and Systems for Video Technology32, 11 (2022), 7386–7402. doi:10.1109/TCSVT.2022.3186307
-
[14]
Danlan Huang, Feifei Gao, Xiaoming Tao, Qiyuan Du, and Jianhua Lu. 2023. Toward Semantic Communications: Deep Learning-Based Image Semantic Cod- ing.IEEE Journal on Selected Areas in Communications41, 1 (2023), 55–71. doi:10.1109/JSAC.2022.3221999
-
[15]
Yipo Huang, Leida Li, Pengfei Chen, Haoning Wu, Weisi Lin, and Guangming Shi
-
[16]
doi:10.1109/TPAMI.2024.3492259
Multi-Modality Multi-Attribute Contrastive Pre-Training for Image Aes- thetics Computing.IEEE Transactions on Pattern Analysis and Machine Intelligence 47, 2 (2025), 1205–1218. doi:10.1109/TPAMI.2024.3492259
-
[17]
Ruixiang Jiang and Chang Wen Chen. 2025. Multimodal LLMs Can Reason about Aesthetics in Zero-Shot(MM ’25). Association for Computing Machinery, New York, NY, USA, 6634–6643. doi:10.1145/3746027.3754961
-
[18]
Zhi Jin, Yuwei Qiu, Kaihao Zhang, Hongdong Li, and Wenhan Luo. 2025. MB- TaylorFormer V2: Improved Multi-Branch Linear Transformer Expanded by Taylor Formula for Image Restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 7 (2025), 5990–6005. doi:10.1109/TPAMI.2025.3559891
-
[19]
Mingye Ju and Xinyang Yu. 2026. Semantic-Aware Low-Light Image Enhance- ment Network for Recognizing Semantics in Intelligent Transportation Systems. IEEE Transactions on Intelligent Transportation Systems27, 2 (2026), 2683–2694. doi:10.1109/TITS.2025.3540257
-
[20]
Jongyoo Kim and Sanghoon Lee. 2017. Deep Learning of Human Visual Sensitivity in Image Quality Assessment Framework. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1969–1977. doi:10.1109/CVPR.2017.213
- [21]
-
[22]
Chao Li et al. 2025. Image Quality Assessment From Human to Machine Prefer- ence. InCVPR
2025
-
[23]
Chunyi Li, Yuan Tian, Xiaoyue Ling, Zicheng Zhang, Haodong Duan, Haoning Wu, Ziheng Jia, Xiaohong Liu, Xiongkuo Min, Guo Lu, Weisi Lin, and Guangtao Zhai. 2025. Image Quality Assessment: From Human to Machine Preference. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 7570–7581. doi:10.1109/CVPR52734.2025.00709
-
[24]
Leida Li, Xiangfei Sheng, Pengfei Chen, Jinjian Wu, and Weisheng Dong. 2025. Towards Explainable Image Aesthetics Assessment With Attribute-Oriented Cri- tiques Generation.IEEE Transactions on Circuits and Systems for Video Technology 35, 2 (2025), 1464–1477. doi:10.1109/TCSVT.2024.3470870
-
[25]
Xin Li, Yulin Ren, Xin Jin, Cuiling Lan, Xing Kui Wang, Wenjun Zeng, Xinchao Wang, and Zhibo Chen. 2023. Diffusion Models for Image Restoration and Enhancement: A Comprehensive Survey.International Journal of Computer Vision133 (2023), 8078 – 8108
2023
-
[26]
Dong Liang, Ling Li, Mingqiang Wei, Shuo Yang, Liyan Zhang, Wenhan Yang, Yun Du, and Huiyu Zhou. 2022. Semantically Contrastive Learning for Low-Light Image Enhancement.Proceedings of the AAAI Conference on Artificial Intelligence 36 (06 2022), 1555–1563. doi:10.1609/aaai.v36i2.20046
-
[27]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. InComputer Vision – ECCV 2014. Springer International Publishing, Cham, 740–755. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2014
-
[28]
Yuhao Liu, Zhanghan Ke, Fang Liu, Nanxuan Zhao, and Rynson W.H. Lau. 2024. Diff-Plugin: Revitalizing Details for Diffusion-Based Low-Level Tasks. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4197–
2024
-
[29]
doi:10.1109/CVPR52733.2024.00402
-
[30]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Lab...
work page internal anchor Pith review arXiv 2024
- [31]
-
[32]
David Rouse, Romuald Pepion, Sheila Hemami, and Patrick Le Callet. 2009. Image Utility Assessment and a Relationship with Image Quality Assessment.Proc SPIE 7240 (02 2009). doi:10.1117/12.811664
-
[33]
Bingnan Wang, Bin Qin, Jiangmeng Li, Fanjiang Xu, Fuchun Sun, and Hui Xiong. 2026. All-in-One Image Restoration via Causal-Deconfounding Wavelet- Disentangled Prompt Network.IEEE Transactions on Image Processing(2026), 1–1. doi:10.1109/TIP.2026.3675478
- [34]
-
[35]
Mo Wang, Minjuan Wang, Xin Xu, Lanqing Yang, Dunbo Cai, and Minghao Yin
-
[36]
Unleashing ChatGPT’s Power: A Case Study on Optimizing Information Retrieval in Flipped Classrooms via Prompt Engineering.IEEE Transactions on Learning Technologies17 (2024), 629–641. doi:10.1109/TLT.2023.3324714
-
[37]
Weizhi Xian, Mingliang Zhou, Bin Fang, Tao Xiang, Weijia Jia, and Bin Chen
-
[38]
Perceptual Quality Analysis in Deep Domains Using Structure Separation and High-Order Moments.IEEE Transactions on Multimedia26 (2024), 2219–2234. doi:10.1109/TMM.2023.3293730
-
[39]
Ce Zhang, Simon Stepputtis, Joseph Campbell, Katia Sycara, and Yaqi Xie. 2024. HiKER-SGG: Hierarchical Knowledge Enhanced Robust Scene Graph Generation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 28233–28243. doi:10.1109/CVPR52733.2024.02667
-
[40]
Keke Zhang, Weiling Chen, Tiesong Zhao, and Zhou Wang. 2026. Structural Similarity in Deep Features: Unified Image Quality Assessment Robust to Geomet- rically Disparate Reference.IEEE Transactions on Pattern Analysis and Machine Intelligence48, 3 (2026), 2581–2595. doi:10.1109/TPAMI.2025.3627285
-
[41]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang
-
[42]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 586–595. doi:10.1109/CVPR.2018.00068
-
[43]
Ronghui Zhang, Jiongze Yu, Junzhou Chen, Guofa Li, Liang Lin, and Danwei Wang. 2024. A Prior Guided Wavelet-Spatial Dual Attention Transformer Frame- work for Heavy Rain Image Restoration.IEEE Transactions on Multimedia26 (2024), 7043–7057. doi:10.1109/TMM.2024.3359480
-
[44]
Xu Zhang, Jiaqi Ma, Guoli Wang, Qian Zhang, Huan Zhang, and Lefei Zhang
- [45]
-
[46]
Changmeng Zheng, Zhiwei Wu, Tao Wang, Yi Cai, and Qing Li. 2021. Object- Aware Multimodal Named Entity Recognition in Social Media Posts With Ad- versarial Learning.IEEE Transactions on Multimedia23 (2021), 2520–2532. doi:10.1109/TMM.2020.3013398
-
[47]
Haibin Zhu. 2021. E-CARGO and Role-Based Collaboration. In2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD). iii–iii. doi:10.1109/CSCWD49262.2021.9437766
-
[48]
Tingting Zhu, Bo Peng, Jifan Liang, Tingchen Han, Hai Wan, Jing Fu, and Jun- jie Chen. 2023. How to Evaluate Semantic Communications for Images With ViTScore Metric?IEEE Transactions on Cognitive Communications and Networking 10 (2023), 1744–1758. https://api.semanticscholar.org/CorpusID:261682367 Beyond Fidelity: Semantic Similarity Assessment in Low-Lev...
2023
-
[49]
Specifically, T3S follows a clear monotonic pattern, i.e., Level 1 > Level 2 > Level 3, in every group
Among the compared methods, only T3S consistently preserves this ordering across all three groups of examples. Specifically, T3S follows a clear monotonic pattern, i.e., Level 1 > Level 2 > Level 3, in every group. This indicates that T3S can correctly recognize that heavy snow mainly affects visual quality rather than semantics, assign an intermediate si...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.