Recognition: unknown
One Refiner to Unlock Them All: Inference-Time Reasoning Elicitation via Reinforcement Query Refinement
Pith reviewed 2026-05-07 16:13 UTC · model grok-4.3
The pith
A single reinforcement-learned refiner can rewrite queries to unlock reasoning in many different frozen large language models at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
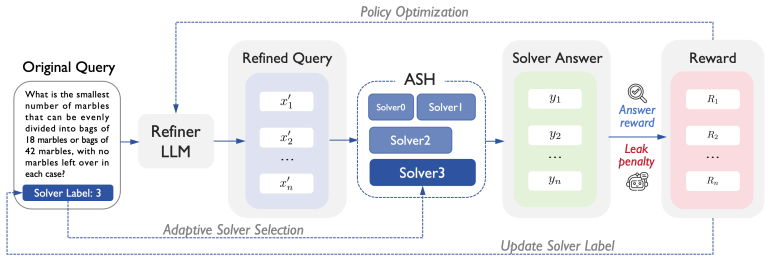
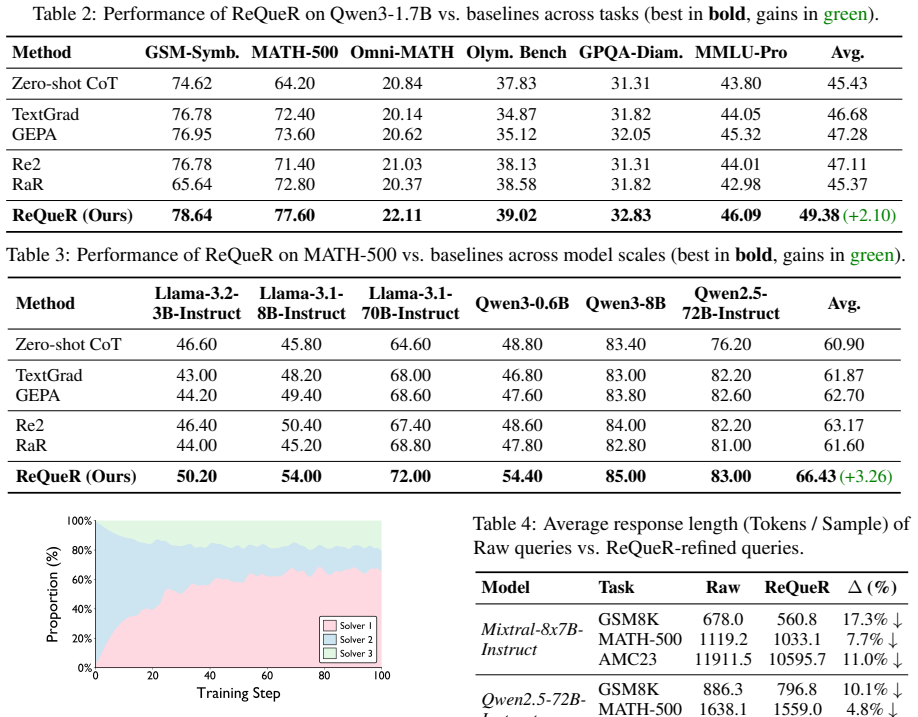
ReQueR trains a Refiner policy via reinforcement learning to rewrite ambiguous queries into explicit logical decompositions. Frozen LLMs serve as the environment, and the Adaptive Solver Hierarchy dynamically adjusts problem difficulty to the refiner's improving competence, drawing from the Zone of Proximal Development. Once trained on a small set of models, the same refiner produces consistent absolute improvements of 1.7 to 7.2 percent on diverse benchmarks and generalizes to unseen models, outperforming static prompts and per-model baselines by 2.1 percent on average.
What carries the argument
The Refiner policy inside ReQueR, trained by reinforcement learning to produce explicit logical decompositions of queries, with the Adaptive Solver Hierarchy acting as a curriculum that aligns environmental difficulty to the policy's competence.
If this is right
- Consistent absolute gains of 1.7 to 7.2 percent appear across architectures and benchmarks.
- The same refiner outperforms strong baselines by 2.1 percent on average.
- One trained refiner supports one-to-many inference-time reasoning elicitation.
- The refiner works on diverse models it never encountered during training.
Where Pith is reading between the lines
- The approach could lower the total compute needed to equip many LLMs with better reasoning by avoiding repeated fine-tuning runs.
- Similar inference-time refinement policies might be trained for other latent capabilities such as factual grounding or step-by-step planning.
- If the refiner's output format is kept model-agnostic, it could combine with existing prompting or decoding strategies without conflict.
Load-bearing premise
A single refiner policy trained on a limited set of models and tasks will generalize to improve reasoning in many unseen models without major performance drop or overfitting.
What would settle it
Train the refiner on one small group of models, then apply it to a new model architecture or task family never used in training; if performance stays flat or drops compared with the original queries, the generalization claim is falsified.
Figures


read the original abstract
Large Language Models (LLMs) often fail to utilize their latent reasoning capabilities due to a distributional mismatch between ambiguous human inquiries and the structured logic required for machine activation. Existing alignment methods either incur prohibitive $O(N)$ costs by fine-tuning each model individually or rely on static prompts that fail to resolve query-level structural complexity. In this paper, we propose ReQueR (\textbf{Re}inforcement \textbf{Que}ry \textbf{R}efinement), a modular framework that treats reasoning elicitation as an inference-time alignment task. We train a specialized Refiner policy via Reinforcement Learning to rewrite raw queries into explicit logical decompositions, treating frozen LLMs as the environment. Rooted in the classical Zone of Proximal Development from educational psychology, we introduce the Adaptive Solver Hierarchy, a curriculum mechanism that stabilizes training by dynamically aligning environmental difficulty with the Refiner's evolving competence. ReQueR yields consistent absolute gains of 1.7\%--7.2\% across diverse architectures and benchmarks, outperforming strong baselines by 2.1\% on average. Crucially, it provides a promising paradigm for one-to-many inference-time reasoning elicitation, enabling a single Refiner trained on a small set of models to effectively unlock reasoning in diverse unseen models. Code is available at https://github.com/newera-xiao/ReQueR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReQueR, a modular RL-based framework that trains a single Refiner policy to rewrite raw queries into explicit logical decompositions at inference time, treating frozen LLMs as the environment. It introduces the Adaptive Solver Hierarchy as a curriculum mechanism rooted in the Zone of Proximal Development to stabilize training. The central empirical claim is that this yields consistent absolute gains of 1.7%–7.2% across diverse architectures and benchmarks, outperforming strong baselines by 2.1% on average, while enabling one-to-many generalization: a Refiner trained on a small set of models effectively unlocks reasoning in diverse unseen models.
Significance. If the generalization result holds under rigorous cross-model controls, the work would represent a meaningful advance in inference-time alignment techniques. It offers a scalable alternative to per-model fine-tuning (avoiding O(N) costs) and moves beyond static prompts by learning query-level structural refinements via RL. The provision of code further supports potential reproducibility and follow-up work on inference-time reasoning elicitation.
major comments (3)
- [Abstract and §4] Abstract and §4 (Results): The headline generalization claim—that a single Refiner trained on limited models unlocks reasoning in diverse unseen models—requires explicit evidence that the unseen models differ substantially in architecture, tokenizer, pre-training corpus, or scale from the training distribution. Without such controls, the reported gains may reflect overfitting to shared failure modes or output styles rather than learning architecture-invariant query decompositions.
- [§3.2] §3.2 (Adaptive Solver Hierarchy): While the curriculum stabilizes training by aligning environmental difficulty with the Refiner's competence, it does not directly enforce or measure invariance of the learned policy to the specific reward signals produced by the training LLMs. This leaves open whether the policy gradient is shaped by idiosyncratic model behaviors, undermining the one-to-many transfer argument.
- [§4] §4 (Experimental setup): The abstract reports specific percentage gains but the provided description lacks details on the exact baselines, number of runs, statistical significance tests, error bars, or the precise definition of 'unseen' models. These omissions make it impossible to verify whether the 2.1% average outperformance is robust or load-bearing for the central claim.
minor comments (2)
- [Abstract] Abstract: The code link is a positive addition for reproducibility; ensure the repository includes the exact training configurations and evaluation scripts used for the reported numbers.
- [§2] §2 (Related work): A brief comparison to prior inference-time prompt optimization or query-rewriting methods would help situate the contribution more precisely.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revision where the concerns are valid and actionable.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): The headline generalization claim—that a single Refiner trained on limited models unlocks reasoning in diverse unseen models—requires explicit evidence that the unseen models differ substantially in architecture, tokenizer, pre-training corpus, or scale from the training distribution. Without such controls, the reported gains may reflect overfitting to shared failure modes or output styles rather than learning architecture-invariant query decompositions.
Authors: We agree that the generalization claim would be strengthened by explicit documentation of differences between training and unseen models. The current manuscript describes the models as diverse but does not include a side-by-side comparison. In the revised version we will add a new table in §4 that reports architecture family, tokenizer vocabulary size and type, pre-training data sources, and parameter scale for the training models versus each unseen model. This addition will make the one-to-many transfer argument more rigorous. revision: yes
-
Referee: [§3.2] §3.2 (Adaptive Solver Hierarchy): While the curriculum stabilizes training by aligning environmental difficulty with the Refiner's competence, it does not directly enforce or measure invariance of the learned policy to the specific reward signals produced by the training LLMs. This leaves open whether the policy gradient is shaped by idiosyncratic model behaviors, undermining the one-to-many transfer argument.
Authors: The referee correctly identifies that the Adaptive Solver Hierarchy is a curriculum device for training stability and does not contain an explicit invariance regularizer with respect to reward signals. While the empirical transfer results provide supporting evidence, we will revise §3.2 to add a short discussion of this limitation and include a new ablation that evaluates the Refiner when reward signals are drawn from held-out models during training. This will directly test the degree of reward-signal invariance. revision: partial
-
Referee: [§4] §4 (Experimental setup): The abstract reports specific percentage gains but the provided description lacks details on the exact baselines, number of runs, statistical significance tests, error bars, or the precise definition of 'unseen' models. These omissions make it impossible to verify whether the 2.1% average outperformance is robust or load-bearing for the central claim.
Authors: We accept that the experimental section is insufficiently detailed for full verification. The revised manuscript will expand §4 to list all baselines with citations, state that all results are averaged over five independent runs with standard deviation error bars, report paired t-test p-values for the 2.1% average improvement, and provide an explicit definition of 'unseen' models together with the precise list of models used in each category. These changes will be reflected in the results tables and figures as well. revision: yes
Circularity Check
No circularity: purely empirical RL training and evaluation
full rationale
The paper presents ReQueR as an RL-trained query refiner using frozen LLMs as the environment, with the Adaptive Solver Hierarchy as a curriculum for training stability. All reported gains (1.7%-7.2% absolute) and the one-to-many generalization claim are framed as outcomes of training on a small model set and testing on held-out architectures, with no equations, derivations, or first-principles predictions that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no fitted parameters are relabeled as predictions. The method is self-contained against external benchmarks via direct experimentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Haonan Dong, Kehan Jiang, Haoran Ye, Wenhao Zhu, Zhaolu Kang, and Guojie Song
Prpo: Aligning process reward with out- come reward in policy optimization.arXiv preprint arXiv:2601.07182. Haonan Dong, Kehan Jiang, Haoran Ye, Wenhao Zhu, Zhaolu Kang, and Guojie Song. 2026. Neurea- soner: Towards explainable, controllable, and unified reasoning via mixture-of-neurons.arXiv preprint arXiv:2604.02972. Haonan Dong, Wenhao Zhu, Guojie Song...
-
[2]
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Hongzhang Liu, Ronghao Chen, Yangfan He, and 1 others. 2025. Se- agent: Self-evolution trajectory optimization in multi- step reasoning with llm-based agents.arXiv preprint arXiv:2...
-
[3]
Neural chain-of-thought search: Searching the optimal reasoning path to enhance large language models.arXiv preprint arXiv:2601.11340. Zheng Liu, Mengjie Liu, Siwei Wen, Mengzhang Cai, Bin Cui, Conghui He, and Wentao Zhang. 2025. From uniform to heterogeneous: Tailoring policy optimization to every token’s nature.arXiv preprint arXiv:2509.16591. Hongxu Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229. Jun Rao, Xuebo Liu, Hexuan Deng, Zepeng Lin, Zix- iong Yu, Jiansheng Wei, Xiaojun Meng, and Min Zhang. 2025. Dynamic sampling that adapts: It- erative dpo for self-aware mathematical reasoning. arXiv preprint arXiv:2505.16176. D...
work page Pith review arXiv 2025
-
[5]
Unlocking Exploration in RLVR: Uncertainty-aware Advantage Shaping for Deeper Reasoning
Visual instance-aware prompt tuning. InPro- ceedings of the 33rd ACM International Conference on Multimedia, pages 2880–2889. Can Xie, Ruotong Pan, Xiangyu Wu, Yunfei Zhang, Jiayi Fu, Tingting Gao, and Guorui Zhou. 2025. Un- locking exploration in rlvr: Uncertainty-aware advan- tage shaping for deeper reasoning.arXiv preprint arXiv:2510.10649. Xiaohan Xu,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen
work page internal anchor Pith review arXiv
-
[7]
In The Twelfth International Conference on Learning Representations
Large language models as optimizers. In The Twelfth International Conference on Learning Representations. Jiawei Yao, Chuming Li, and Canran Xiao. 2024. Swift sampler: Efficient learning of sampler by 10 param- eters.Advances in Neural Information Processing Systems, 37:59030–59053. Shenghao Ye, Yu Guo, Dong Jin, Yikai Shen, Yunpeng Hou, Shuangwu Chen, Ji...
2024
-
[8]
When tableqa meets noise: A dual denoising framework for complex questions and large-scale tables.arXiv preprint arXiv:2509.17680. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXi...
-
[9]
For three paraphrased leakage variants, the ratio is consistently well aboveτ= 5.0: Naturally predictable answers.For well-posed queries with inherently predictable answers, the penalty does not produce false positives. For exam- ple, with “What is 1 + 1?” rephrased as “Compute the sum of 1 and 1.”, we obtain PPL(y∗|x) = 1.26 and PPL(y∗|x′) = 1.08, giving...
-
[10]
logic-dense
fromknowledge retrieval, ReQueR enables a scalable Edge-Cloud Collaborative Inference archi- tecture where a centralized, high-capacity Refiner empowers a diverse fleet of edge-deployed models without individual fine-tuning. Autonomous Code Agents as Requirement Ar- chitectsIn the domain of complex software engi- neering, ReQueR transcends simple query re...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.