Recognition: unknown
Benchmarking Stopping Criteria for Evolutionary Multi-objective Optimization
Pith reviewed 2026-05-07 14:03 UTC · model grok-4.3
The pith
A scalar performance measure and file-based method for storing population states enable fair, reproducible benchmarking of stopping criteria in evolutionary multi-objective optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its proposed performance measure represents stopping-criterion quality as a single scalar value for easy comparison, that the file-based benchmarking approach simplifies experiments while supporting reproducibility, and that the accompanying data representation method solves the file-size problem in that approach, with effectiveness shown by applying the tools to five representative stopping criteria for EMO.
What carries the argument
The scalar performance measure for stopping criteria paired with the file-based benchmarking approach that stores population states in compact text files.
If this is right
- Direct numerical comparisons of different stopping criteria become possible without subjective judgment.
- Reproducibility improves because benchmark runs can be shared and re-evaluated from the stored population files.
- New stopping criteria can be validated more quickly against existing ones using the same standardized process.
- EMO applications in practice can adopt criteria shown to stop at appropriate times, reducing wasted evaluations.
Where Pith is reading between the lines
- The same scalar-plus-file structure could be adapted to benchmark early-stopping rules in single-objective evolutionary algorithms or in machine-learning training.
- Public archives of population-state files might emerge, allowing community-wide re-use and meta-analysis of stopping performance.
- The method opens the door to studying how stopping-criterion effectiveness changes with problem features such as objective count or decision-space dimensionality.
Load-bearing premise
A single scalar performance measure can meaningfully capture the quality of stopping criteria across varied EMO problems and saving population states in files preserves all information needed for accurate benchmarking.
What would settle it
Applying the scalar measure to the same set of problems and stopping criteria and obtaining rankings that contradict those produced by multiple independent metrics or expert review of the actual convergence behavior.
Figures






read the original abstract
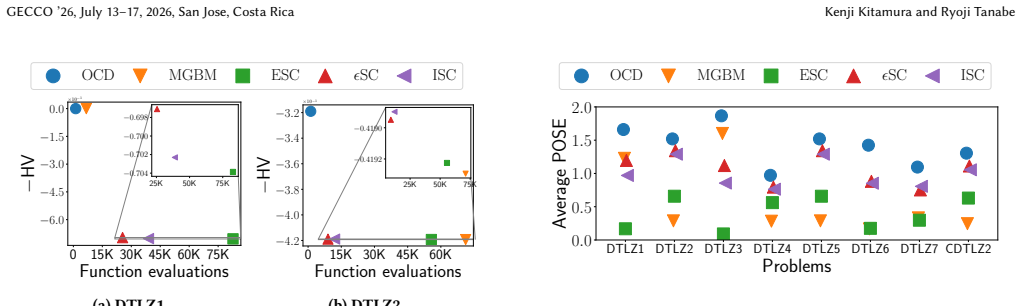
Stopping criteria automatically determine when to stop an evolutionary algorithm, so as not to waste function evaluations on a stagnant population. Although stopping criteria play an important role in real-world applications, they have attracted little attention in the evolutionary multi-objective optimization (EMO) community. In fact, new stopping criteria for EMO have been rarely developed in recent years. One reason for the stagnation in developing stopping criteria for EMO is a lack of effective benchmarking methodologies. To address this issue, this paper proposes (i) a performance measure of stopping criteria for EMO and (ii) a file-based benchmarking approach. This paper also proposes (iii) a data representation method that effectively stores population states in text files. (i) The proposed measure represents the performance of stopping criteria as a single scalar value, making comparison easy. (ii) The proposed file-based approach not only simplifies the benchmarking process but also facilitates reproducibility. (iii) The proposed data representation method addresses the issue of file size in (ii). We demonstrate the effectiveness of our three contributions (i)--(iii) by benchmarking five representative stopping criteria for EMO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three contributions to address the lack of benchmarking methodologies for stopping criteria in evolutionary multi-objective optimization (EMO): (i) a performance measure represented as a single scalar value to enable easy comparison of stopping criteria, (ii) a file-based benchmarking approach to simplify the process and improve reproducibility, and (iii) a data representation method for efficiently storing population states in text files to mitigate file size issues. These are demonstrated through benchmarking of five representative stopping criteria for EMO.
Significance. If the single-scalar performance measure can be shown to aggregate proximity to the Pareto front, evaluation savings, and cross-problem robustness in a non-arbitrary, ranking-preserving manner, and if the file-based approach delivers lossless, reproducible comparisons, the work would provide a much-needed standardized framework for evaluating and developing stopping criteria in EMO, an area that has seen little recent progress. The explicit focus on reproducibility via file-based methods is a clear strength.
major comments (1)
- Abstract and contribution (i): the central claim that a single scalar performance measure enables meaningful comparisons rests on an unspecified aggregation of closeness to the true Pareto front, number of wasted evaluations avoided, and robustness across problem classes. Without an explicit formula, weighting scheme, or demonstration that the scalar preserves rankings under changes in objective scaling, front shape, or noise, the measure risks oversimplifying heterogeneous EMO landscapes and the subsequent benchmarking demonstration loses force.
minor comments (1)
- Abstract: the description of contributions (i)–(iii) remains at a high level with no formulas for the performance measure, no pseudocode or specification for the file format or data representation, and no quantitative results from the five-criteria benchmark, which makes it difficult to assess the claimed effectiveness.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation for major revision. We address the single major comment below and describe the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [—] Abstract and contribution (i): the central claim that a single scalar performance measure enables meaningful comparisons rests on an unspecified aggregation of closeness to the true Pareto front, number of wasted evaluations avoided, and robustness across problem classes. Without an explicit formula, weighting scheme, or demonstration that the scalar preserves rankings under changes in objective scaling, front shape, or noise, the measure risks oversimplifying heterogeneous EMO landscapes and the subsequent benchmarking demonstration loses force.
Authors: We agree that the aggregation underlying the single-scalar performance measure must be made fully explicit. In the submitted manuscript the measure is described at a high level as combining proximity to the Pareto front, evaluation savings, and cross-problem robustness, but the precise formula and weighting scheme were not stated in the abstract or early sections. In the revised manuscript we will insert a new subsection (Section 3.1) that gives the mathematical definition of the scalar, specifies the weighting coefficients (with justification), and reports additional experiments that test ranking stability under objective scaling, different front geometries, and additive noise. These additions will also include a short discussion of the measure’s limitations with respect to heterogeneous landscapes. We believe the expanded presentation will remove any ambiguity and reinforce the validity of the subsequent benchmarking results. revision: yes
Circularity Check
No circularity: independent methodological proposals with no self-referential derivations
full rationale
The paper introduces three standalone contributions—a scalar performance measure for EMO stopping criteria, a file-based benchmarking framework, and a compact text-file data representation—without any equations, fitted parameters, or derivations that reduce to prior inputs. Benchmarking of five existing criteria is presented as an empirical demonstration rather than a self-referential prediction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core methods. The work is self-contained as a set of practical tools; the single-scalar measure is explicitly proposed as a new construct, not derived from or fitted to the benchmarking results themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evolutionary multi-objective optimization algorithms maintain populations and use Pareto dominance or similar ranking to guide search.
Reference graph
Works this paper leans on
-
[1]
Anne Auger, Johannes Bader, Dimo Brockhoff, and Eckart Zitzler. 2012. Hypervolume-based multiobjective optimization: Theoretical foundations and practical implications.Theor. Comput. Sci.425 (2012), 75–103. doi:10.1016/J.TCS. 2011.03.012 Benchmarking Stopping Criteria for Evolutionary Multi-objective Optimization GECCO ’26, July 13–17, 2026, San Jose, Costa Rica
-
[2]
Nicola Beume, Boris Naujoks, and Michael Emmerich. 2007. SMS-EMOA: Mul- tiobjective selection based on dominated hypervolume.European journal of operational research181, 3 (2007), 1653–1669
2007
-
[3]
2009.A Statistical Learning Perspective of Genetic Programming
Mauro Birattari. 2009.Tuning Metaheuristics - A Machine Learning Perspective. Studies in Computational Intelligence, Vol. 197. Springer. doi:10.1007/978-3-642- 00483-4
-
[4]
Francesco Biscani and Dario Izzo. 2020. A parallel global multiobjective frame- work for optimization: pagmo.Journal of Open Source Software5, 53 (2020), 2338
2020
-
[5]
Julian Blank and Kalyanmoy Deb. 2020. Pymoo: Multi-Objective Optimization in Python.IEEE Access8 (2020), 89497–89509. doi:10.1109/ACCESS.2020.2990567
-
[6]
Dimo Brockhoff. 2015. A Bug in the Multiobjective Optimizer IBEA: Salutary Lessons for Code Release and a Performance Re-Assessment. InEvolutionary Multi-Criterion Optimization - 8th International Conference, EMO 2015, Guimarães, Portugal, March 29 -April 1, 2015. Proceedings, Part I (Lecture Notes in Computer Science, Vol. 9018), António Gaspar-Cunha, Ca...
-
[7]
Coello Coello and Margarita Reyes Sierra
Carlos A. Coello Coello and Margarita Reyes Sierra. 2004. A Study of the Paral- lelization of a Coevolutionary Multi-objective Evolutionary Algorithm. InMICAI. 688–697. doi:10.1007/978-3-540-24694-7_71
-
[8]
2001.Multi-objective optimization using evolutionary algorithms
Kalyanmoy Deb. 2001.Multi-objective optimization using evolutionary algorithms. Wiley
2001
-
[9]
Kalyanmoy Deb, Samir Agrawal, Amrit Pratap, and T. Meyarivan. 2002. A fast and elitist multiobjective genetic algorithm: NSGA-II.IEEE Trans. Evol. Comput. 6, 2 (2002), 182–197. doi:10.1109/4235.996017
-
[10]
Kalyanmoy Deb and Himanshu Jain. 2014. An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach, Part I: Solving Problems With Box Constraints.IEEE Trans. Evol. Comput.18, 4 (2014), 577–601. doi:10.1109/TEVC.2013.2281535
-
[11]
Kalyanmoy Deb, Lothar Thiele, Marco Laumanns, and Eckart Zitzler. 2005. Scal- able Test Problems for Evolutionary Multiobjective Optimization. InEvolutionary Multiobjective Optimization. Springer, 105–145. doi:10.1007/1-84628-137-7_6
-
[12]
Hammouri, and Moham- mad Qasem Bataineh
Iyad Abu Doush, Mohammed El-Abd, Abdelaziz I. Hammouri, and Moham- mad Qasem Bataineh. 2023. The effect of different stopping criteria on multi- objective optimization algorithms.Neural Comput. Appl.35, 2 (2023), 1125–1155. doi:10.1007/S00521-021-05805-1
-
[13]
Salvador García, Alberto Fernández, Julián Luengo, and Francisco Herrera. 2010. Advanced nonparametric tests for multiple comparisons in the design of experi- ments in computational intelligence and data mining: Experimental analysis of power.Inf. Sci.180, 10 (2010), 2044–2064. doi:10.1016/J.INS.2009.12.010
-
[14]
Tushar Goel and Nielen Stander. 2010. A non-dominance-based online stopping criterion for multi-objective evolutionary algorithms.Internat. J. Numer. Methods Engrg.84, 6 (2010), 661—-684. doi:10.1002/nme.2909
-
[15]
Cheng Gong, Yang Nan, Lie Meng Pang, Hisao Ishibuchi, and Qingfu Zhang
-
[16]
Performance of NSGA-III on Multi-objective Combinatorial Optimization Problems Heavily Depends on Its Implementations. InProceedings of the Genetic and Evolutionary Computation Conference, GECCO 2024, Melbourne, VIC, Australia, July 14-18, 2024, Xiaodong Li and Julia Handl (Eds.). ACM. doi:10.1145/3638529. 3654004
-
[17]
David Hadka and Patrick M. Reed. 2013. Borg: An Auto-Adaptive Many-Objective Evolutionary Computing Framework.Evol. Comput.21, 2 (2013), 231–259. doi:10. 1162/EVCO_A_00075
2013
-
[18]
1998.Evaluating the quality of approximations to the non-dominated set
Michael Pilegaard Hansen and Andrzej Jaszkiewicz. 1998.Evaluating the quality of approximations to the non-dominated set. Technical Report IMM-REP-1998-7. Poznan University of Technology
1998
- [19]
-
[20]
2006.The base16, base32, and base64 data encodings
Simon Josefsson. 2006.The base16, base32, and base64 data encodings. Technical Report
2006
-
[21]
Manuel López-Ibáñez, Jürgen Branke, and Luís Paquete. 2021. Reproducibility in Evolutionary Computation.ACM Trans. Evol. Learn. Optim.1, 4 (2021), 14:1–14:21. doi:10.1145/3466624
-
[22]
Manuel López-Ibáñez, Joshua D. Knowles, and Marco Laumanns. 2011. On Sequential Online Archiving of Objective Vectors. InEMO, Vol. 6576. 46–60. doi:10.1007/978-3-642-19893-9_4
-
[23]
Shahriar Mahbub, Tobias Wagner, and Luigi Crema
Md. Shahriar Mahbub, Tobias Wagner, and Luigi Crema. 2015. Improving Ro- bustness of Stopping Multi-objective Evolutionary Algorithms by Simultane- ously Monitoring Objective and Decision Space. InProceedings of the Genetic and Evolutionary Computation Conference, GECCO 2015, Madrid, Spain, July 11-15, 2015, Sara Silva and Anna Isabel Esparcia-Alcázar (Ed...
-
[24]
Luis Martí, Jesús García, Antonio Berlanga, and José Manuel Molina. 2007. A cumulative evidential stopping criterion for multiobjective optimization evolu- tionary algorithms. InGECCO. 911. doi:10.1145/1276958.1277141
-
[25]
Luis Martí, Jesús García, Antonio Berlanga, and José M. Molina. 2016. A stopping criterion for multi-objective optimization evolutionary algorithms.Inf. Sci.367- 368 (2016), 700–718. doi:10.1016/J.INS.2016.07.025
-
[26]
Dhish Kumar Saxena, Arnab Sinha, Joao A Duro, and Qingfu Zhang. 2015. Entropy-based termination criterion for multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput.20, 4 (2015), 485–498
2015
-
[27]
Tobias Wagner, Heike Trautmann, and Boris Naujoks. 2009. OCD: Online Conver- gence Detection for Evolutionary Multi-Objective Algorithms Based on Statistical Testing. InEMO. 198–215. doi:10.1007/978-3-642-01020-0_19
-
[28]
Qingfu Zhang and Hui Li. 2007. MOEA/D: A Multiobjective Evolutionary Algo- rithm Based on Decomposition.IEEE Trans. Evol. Comput.11, 6 (2007), 712–731. doi:10.1109/TEVC.2007.892759
-
[29]
Eckart Zitzler and Simon Künzli. 2004. Indicator-Based Selection in Multiobjective Search. InParallel Problem Solving from Nature - PPSN VIII, 8th International Conference, Birmingham, UK, September 18-22, 2004, Proceedings (Lecture Notes in Computer Science, Vol. 3242), Xin Yao, Edmund K. Burke, José Antonio Lozano, Jim Smith, Juan Julián Merelo Guervós,...
2004
-
[30]
Eckart Zitzler and Lothar Thiele. 1998. Multiobjective Optimization Using Evolu- tionary Algorithms - A Comparative Case Study. InPPSN. 292–304. doi:10.1007/ BFb0056872
1998
-
[31]
Fonseca, and Vi- viane Grunert da Fonseca
Eckart Zitzler, Lothar Thiele, Marco Laumanns, Carlos M. Fonseca, and Vi- viane Grunert da Fonseca. 2003. Performance assessment of multiobjective optimizers: an analysis and review.IEEE Trans. Evol. Comput.7, 2 (2003), 117–132. doi:10.1109/TEVC.2003.810758
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.