Recognition: unknown
Improving Zero-Shot Offline RL via Behavioral Task Sampling
Pith reviewed 2026-05-07 16:22 UTC · model grok-4.3
The pith
Extracting task vectors from the offline dataset instead of random sampling improves zero-shot RL performance by an average of 20 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that replacing random task-vector sampling with a simple reward-function extraction procedure applied to the offline dataset produces a task distribution that yields stronger zero-shot generalization to unseen linear reward functions, delivering roughly 20 percent higher average performance across standard benchmark environments and multiple baseline algorithms.
What carries the argument
The reward function extraction procedure, which pulls task vectors straight from the offline dataset to define the training task distribution instead of drawing them at random.
If this is right
- Existing offline zero-shot RL methods gain performance simply by swapping their task-sampling step for the extraction procedure.
- Zero-shot policies generalize better to linear reward functions that never appeared during training.
- The performance lift appears consistently across several benchmark environments and baseline algorithms.
- Principled choice of the training task distribution matters more than the implicit assumption of random sampling allows.
Where Pith is reading between the lines
- The same extraction idea could be tested on datasets that contain only partial coverage of the state space to check whether it still supplies useful task vectors.
- If the procedure works for linear rewards, it raises the question of whether a similar extraction step can be defined for nonlinear reward functions without changing the rest of the pipeline.
- Connecting this sampling choice to other offline RL settings where task or goal distributions are chosen in advance might reveal shared principles about how behavioral data encodes useful structure.
Load-bearing premise
The extracted task vectors from the offline dataset capture the full structure of the task space without introducing selection bias or leaving gaps in coverage of possible unseen rewards.
What would settle it
Re-running the benchmark experiments with the extraction procedure turned off so that task vectors revert to random sampling, and finding no measurable drop in zero-shot success rates, would show the claimed improvement does not hold.
Figures





read the original abstract
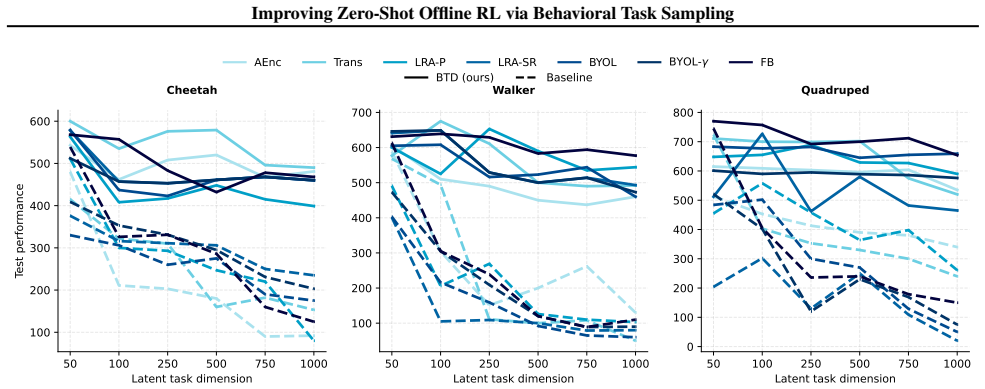
Offline zero-shot reinforcement learning (RL) aims to learn agents that optimize unseen reward functions without additional environment interaction. The standard approach to this problem trains task-conditioned policies by sampling task vectors that define linear reward functions over learned state representations. In most existing algorithms, these task vectors are randomly sampled, implicitly assuming this adequately captures the structure of the task space. We argue that doing so leads to suboptimal zero-shot generalization. To address this limitation, we propose extracting task vectors directly from the offline dataset and using them to define the task distribution used for policy training. We introduce a simple and general reward function extraction procedure that integrates into existing offline zero-shot RL algorithms. Across multiple benchmark environments and baselines, our approach improves zero-shot performance by an average of 20%, highlighting the importance of principled task sampling in offline zero-shot RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in offline zero-shot RL, randomly sampling task vectors for training task-conditioned policies is suboptimal, and proposes instead extracting task vectors directly from the offline dataset via a simple reward function extraction procedure. This change integrates into existing algorithms and yields an average 20% improvement in zero-shot performance across multiple benchmark environments and baselines.
Significance. If the empirical gains hold under rigorous validation, the work would be significant for highlighting that data-driven task sampling can outperform random sampling in capturing task-space structure for generalization to unseen linear rewards w · ϕ(s). It provides a lightweight, algorithm-agnostic modification that could be adopted broadly in offline RL pipelines.
major comments (2)
- [Experiments] Experiments section: the reported average 20% improvement lacks accompanying details on run count, standard deviations, confidence intervals, or statistical significance tests, making it impossible to determine whether the gains are reliable or could be explained by variance.
- [Method] Method section (reward extraction procedure): no analysis is provided showing that the extracted task vectors improve coverage of the evaluation task space (e.g., via convex-hull volume, principal-component span, or distance to unseen w vectors) rather than merely reweighting toward behaviors already present in the data-collection policy; without this, the 20% gain does not yet establish superior zero-shot generalization.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief equation or pseudocode snippet illustrating the reward extraction step for immediate clarity.
- [Experiments] Table captions and axis labels in the experimental figures should explicitly state the number of seeds and whether error bars represent standard error or deviation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported average 20% improvement lacks accompanying details on run count, standard deviations, confidence intervals, or statistical significance tests, making it impossible to determine whether the gains are reliable or could be explained by variance.
Authors: We agree that these statistical details are necessary to establish the reliability of the results. The manuscript currently reports only the average improvement without run counts, standard deviations, confidence intervals, or significance tests. In the revised version, we will expand the Experiments section to include the number of independent runs (with random seeds), standard deviations across runs, 95% confidence intervals, and statistical significance tests (such as paired t-tests against baselines) for the reported gains. revision: yes
-
Referee: [Method] Method section (reward extraction procedure): no analysis is provided showing that the extracted task vectors improve coverage of the evaluation task space (e.g., via convex-hull volume, principal-component span, or distance to unseen w vectors) rather than merely reweighting toward behaviors already present in the data-collection policy; without this, the 20% gain does not yet establish superior zero-shot generalization.
Authors: We acknowledge that a direct analysis of task-space coverage would provide stronger support for the claim of improved generalization. The current manuscript relies on the empirical zero-shot performance gains as primary evidence. To address this, we will add to the revised manuscript a quantitative comparison of task vector distributions, including convex-hull volume of extracted versus randomly sampled vectors, principal component analysis of span, and average Euclidean distances to the unseen evaluation vectors w. This will help demonstrate that the extraction procedure improves coverage of the relevant task space. revision: yes
Circularity Check
No circularity: empirical gains from dataset-derived sampling
full rationale
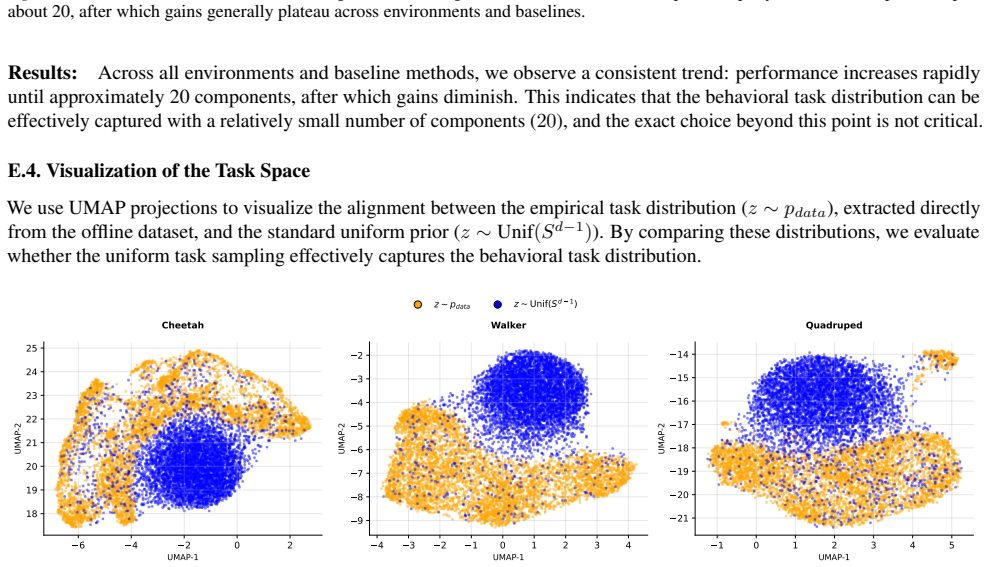
The paper presents an empirical method for extracting task vectors from the offline dataset to replace random sampling in zero-shot offline RL, reporting an average 20% improvement across benchmarks and baselines. No equations, derivations, or self-citations are shown that reduce the claimed performance gain to a fitted parameter, self-definition, or prior result by the same authors. The central claim rests on experimental comparison rather than a closed mathematical chain, and the extraction procedure is described as a simple integration into existing algorithms without invoking uniqueness theorems or ansatzes that collapse to inputs. The result is therefore self-contained as an observable empirical outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The offline dataset contains sufficient state-action coverage to extract representative task vectors for the broader task space.
Reference graph
Works this paper leans on
-
[1]
URL https://doi.org/ 10.48550/arxiv.2402.01886. 8 Improving Zero-Shot Offline RL via Behavioral Task Sampling Borsa, D., Barreto, A., Quan, J., Mankowitz, D., Munos, R., Van Hasselt, H., Silver, D., and Schaul, T. Uni- versal successor features approximators.arXiv preprint arXiv:1812.07626,
-
[2]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
1901
-
[3]
Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
Burda, Y ., Edwards, H., Storkey, A., and Klimov, O. Ex- ploration by random network distillation.arXiv preprint arXiv:1810.12894,
-
[4]
B., Rockt¨aschel, T., and Grefenstette, E
Campero, A., Raileanu, R., K¨uttler, H., Tenenbaum, J. B., Rockt¨aschel, T., and Grefenstette, E. Learning with amigo: Adversarially motivated intrinsic goals.arXiv preprint arXiv:2006.12122,
-
[5]
Castanet, N., Lamprier, S., and Sigaud, O. Stein variational goal generation for adaptive exploration in multi-goal reinforcement learning.arXiv preprint arXiv:2206.06719,
-
[6]
Frans, K., Park, S., Abbeel, P., and Levine, S. Unsupervised zero-shot reinforcement learning via functional reward encodings.arXiv preprint arXiv:2402.17135,
-
[7]
Freihaut, T. and Ramponi, G. On feasible rewards in multi- agent inverse reinforcement learning.arXiv preprint arXiv:2411.15046,
-
[8]
URL https://doi.org/ 10.48550/arxiv.2411.15046. Fu, J., Levine, S., and Abbeel, P. Learning robust rewards with adversarial inverse reinforcement learning. InInter- national Conference on Learning Representations (ICLR),
-
[9]
Open-endedness is essential for artificial superhuman intelligence.arXiv preprint arXiv:2406.04268,
Hughes, E., Dennis, M., Parker-Holder, J., Behbahani, F., Mavalankar, A., Shi, Y ., Schaul, T., and Rocktaschel, T. Open-endedness is essential for artificial superhuman intelligence.arXiv preprint arXiv:2406.04268,
-
[10]
Zero-shot rein- forcement learning via function encoders.arXiv preprint arXiv:2401.17173,
Ingebrand, T., Zhang, A., and Topcu, U. Zero-shot rein- forcement learning via function encoders.arXiv preprint arXiv:2401.17173,
-
[11]
H-gap: Hu- manoid control with a generalist planner.arXiv preprint arXiv:2312.02682,
9 Improving Zero-Shot Offline RL via Behavioral Task Sampling Jiang, Z., Xu, Y ., Wagener, N., Luo, Y ., Janner, M., Grefen- stette, E., Rockt ¨aschel, T., and Tian, Y . H-gap: Hu- manoid control with a generalist planner.arXiv preprint arXiv:2312.02682,
-
[12]
URL https://doi.org/10. 48550/arxiv.2501.12633. Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y ., et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026,
-
[13]
Self-Predictive Representations for Combinatorial Generalization in Behavioral Cloning
URL https://arxiv.org/abs/2506.10137. Ledoux, M.The Concentration of Measure Phe- nomenon. Mathematical surveys and monographs. Amer- ican Mathematical Society,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Goal-conditioned re- inforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
ISBN 9780821837924. URL https://books.google.fr/books?id= mCX_cWL6rqwC. Liu, M., Zhu, M., and Zhang, W. Goal-conditioned re- inforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
-
[15]
Playing Atari with Deep Reinforcement Learning
Mnih, V ., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602,
work page internal anchor Pith review arXiv
-
[16]
arXiv preprint arXiv:1903.03698 , year=
Pong, V . H., Dalal, M., Lin, S., Nair, A., Bahl, S., and Levine, S. Skew-fit: State-covering self-supervised re- inforcement learning.arXiv preprint arXiv:1903.03698,
-
[17]
Automatic curriculum learning for deep rl: A short survey.arXiv preprint arXiv:2003.04664,
Portelas, R., Colas, C., Weng, L., Hofmann, K., and Oudeyer, P.-Y . Automatic curriculum learning for deep rl: A short survey.arXiv preprint arXiv:2003.04664,
- [18]
-
[19]
Tassa, Y ., Doron, Y ., Muldal, A., Erez, T., Li, Y ., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review arXiv
-
[20]
Does zero- shot reinforcement learning exist?arXiv preprint arXiv:2209.14935,
Touati, A., Rapin, J., and Ollivier, Y . Does zero- shot reinforcement learning exist?arXiv preprint arXiv:2209.14935,
-
[21]
Finetuned Language Models Are Zero-Shot Learners
Wei, J., Bosma, M., Zhao, V . Y ., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V . Finetuned lan- guage models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review arXiv
-
[22]
Deep maximum entropy inverse reinforcement learning.arXiv preprint arXiv:1507.04888,
Wulfmeier, M., Ondruska, P., and Posner, I. Deep maximum entropy inverse reinforcement learning.arXiv preprint arXiv:1507.04888,
-
[23]
Deep maximum entropy inverse reinforcement learning.arXiv preprint arXiv:1507.04888,
URL https://doi.org/ 10.48550/arxiv.1507.04888. Yarats, D., Brandfonbrener, D., Liu, H., Laskin, M., Abbeel, P., Lazaric, A., and Pinto, L. Don’t change the algorithm, change the data: Exploratory data for offline reinforce- ment learning.arXiv preprint arXiv:2201.13425,
-
[24]
Language to rewards for robotic skill synthesis
Yu, W., Gileadi, N., Fu, C., Kirmani, S., Lee, K.-H., Are- nas, M. G., Chiang, H.-T. L., Erez, T., Hasenclever, L., Humplik, J., et al. Language to rewards for robotic skill synthesis.arXiv preprint arXiv:2306.08647,
-
[25]
The critic uses twin Q-networks with analogous two-stream preprocessing of(s, a, z)tuples for stable value estimation
with task-conditioned networks: the actor π(s, z) uses parallel preprocessing streams (one for state features, another for task-conditioned states) with LayerNorm-Tanh initialization followed by ReLU activations, converging through a shared trunk network with Tanh output activation and truncated normal exploration (σ= 0.2 ). The critic uses twin Q-network...
2048
-
[26]
Each dataset consists of 107 total transitions, composed of 104 trajectories with a length of10 3 steps each
benchmark collected via Random Network Distillation (RND) (Burda et al., 2018). Each dataset consists of 107 total transitions, composed of 104 trajectories with a length of10 3 steps each. 14 Improving Zero-Shot Offline RL via Behavioral Task Sampling D. Baselines details This section provides objective functions for all baseline representation learning ...
2018
-
[27]
Here, f and ϕ are the learned factors that represent the state and its temporally extended features
learns a low-rank factorization of the successor measure M(s, s ′) using temporal difference learning. Here, f and ϕ are the learned factors that represent the state and its temporally extended features. min f,ϕ E(st,st+1)∼D s′∼D h f(s t)⊤ϕ(s′)−γf(s t+1)⊤ ¯ϕ(s′) 2i −2E (st,st+1)∼D f(s t)⊤ϕ(st+1) . • Bootstrap Your Own Latent (BYOL) (Grill et al., 2020)lea...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.