Recognition: unknown
Identification and Estimation of Consumers' Preferences from Repeated Observations under Nonlinear Pricing
Pith reviewed 2026-05-07 14:05 UTC · model grok-4.3
The pith
With sufficient variation across price schedules, the utility function and distribution of consumer preference types can be nonparametrically identified.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a nonparametric approach to identify and estimate consumer preferences and unobserved heterogeneity under nonlinear price schedules. Leveraging variation across multiple price schedules, we show that both the utility function and the distribution of preference types can be nonparametrically identified. The quantile function of unobserved types becomes solution of a functional equation, and we derive conditions ensuring identification. We propose an iterative approach for estimation, in which the regularization bias decays exponentially in the number of iterations while the variance grows only polynomially, yielding a near-parametric convergence rate.
What carries the argument
The quantile function of unobserved preference types, defined as the solution to a functional equation derived from observed demand under varying nonlinear price schedules.
If this is right
- The utility function is recovered nonparametrically for all relevant income levels.
- The distribution of unobserved preference heterogeneity is fully identified.
- Estimation achieves near-parametric rates through iteration.
- Bootstrap procedures provide valid inference.
- Extensions handle price endogeneity and observed covariates.
Where Pith is reading between the lines
- This approach could enable nonparametric analysis of welfare effects from changes in nonlinear tariffs.
- It might be adapted to other repeated choice settings with varying menus, like insurance or subscription services.
- Sufficient variation in price schedules could be verified empirically by subsample stability.
- Future work could incorporate dynamics if choices are observed over time.
Load-bearing premise
There is sufficient independent variation in the multiple price schedules observed by consumers to trace out the utility function and type distribution.
What would settle it
If estimates of the utility function obtained from different combinations of price schedules are inconsistent or fail to satisfy monotonicity conditions in an empirical application, the identification would not hold.
Figures

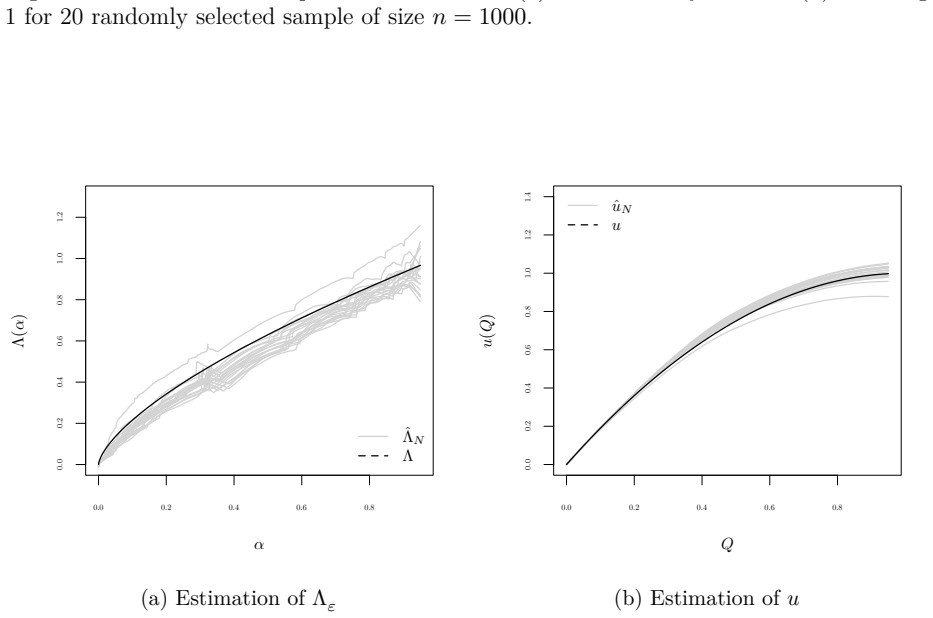
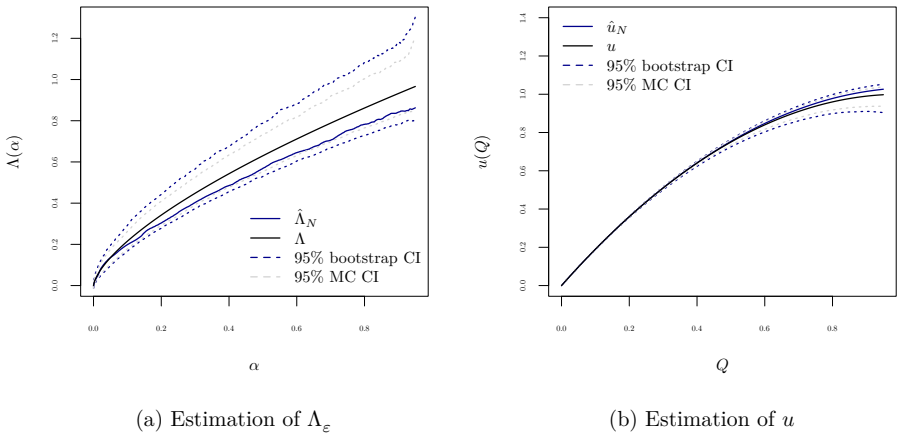
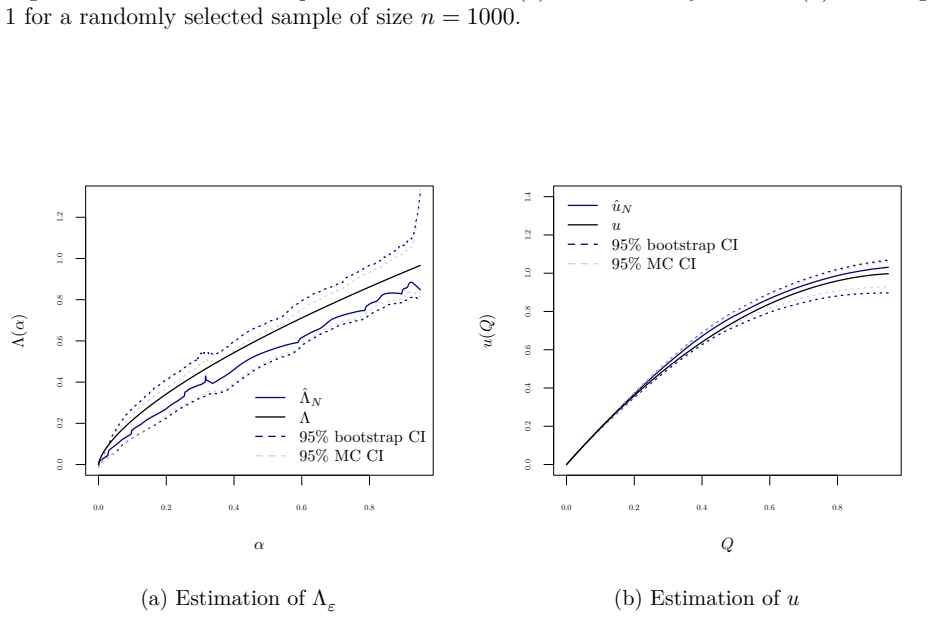


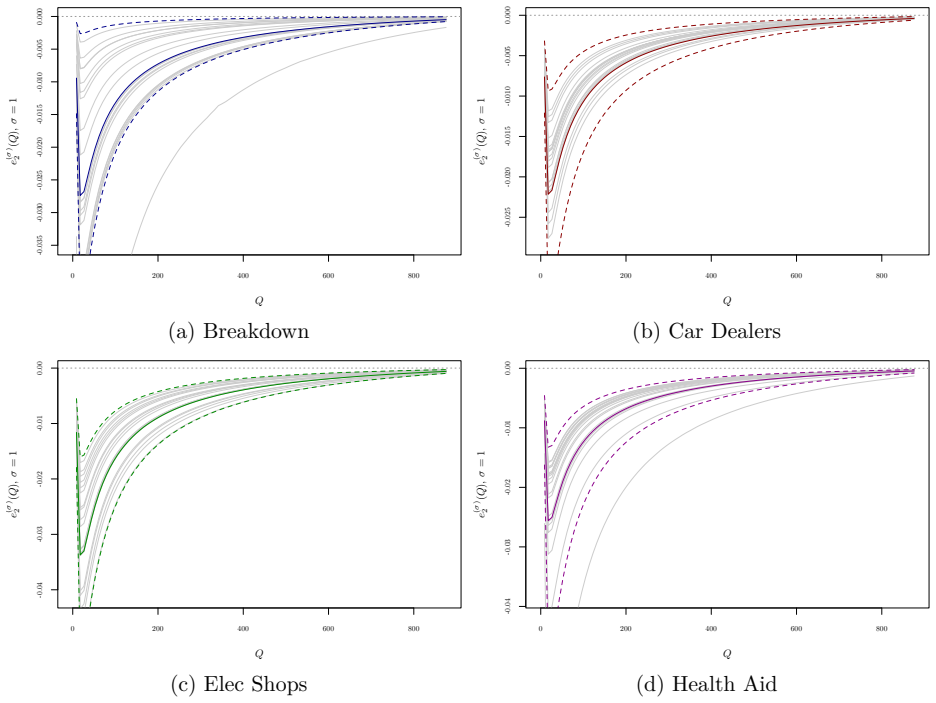
read the original abstract
We develop a nonparametric approach to identify and estimate consumer preferences and unobserved heterogeneity under nonlinear price schedules. Leveraging variation across multiple price schedules, we show that both the utility function and the distribution of preference types can be nonparametrically identified. The quantile function of unobserved types becomes solution of a functional equation, and we derive conditions ensuring identification. We propose an iterative approach for estimation, in which the regularization bias decays exponentially in the number of iterations while the variance grows only polynomially, yielding a near-parametric convergence rate. We propose a valid bootstrap procedure for finite-sample inference and extend the framework to accommodate potential endogeneity of prices and additional observed heterogeneity. Monte Carlo simulations and an empirical application to data from a European mail carrier demonstrate how we can recover the utility functions and preference distributions in finite samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a nonparametric identification strategy for consumer utility functions and the distribution of unobserved preference types from repeated choice data under nonlinear pricing. It shows that the quantile function of unobserved types solves a functional equation derived from optimal bundle choices across multiple price schedules, derives conditions for unique identification, proposes an iterative estimator achieving near-parametric convergence rates via exponentially decaying regularization bias, provides a bootstrap for inference, and extends the framework to price endogeneity and observed heterogeneity. The approach is illustrated via Monte Carlo simulations and an empirical application to European mail carrier data.
Significance. If the identification conditions hold, the paper makes a substantial contribution to the econometric literature on demand estimation under nonlinear tariffs by delivering nonparametric recovery of both preferences and heterogeneity without strong functional form assumptions. The near-parametric rate of the iterative estimator and the valid bootstrap are technically attractive features, as is the explicit handling of endogeneity in an extension. The Monte Carlo and empirical results provide concrete evidence of finite-sample performance in a relevant setting.
major comments (2)
- [Identification section (functional equation and conditions)] The nonparametric identification result hinges on the functional equation for the quantile function of types admitting a unique solution, which in turn requires sufficient independent variation across observed price schedules that is uncorrelated with unobserved preference heterogeneity. The manuscript states that conditions ensuring identification are derived, but the precise statement of these conditions (including invertibility of the type-to-bundle mapping and the support requirements on the schedule distribution) is central to the claim and would benefit from a more explicit theorem statement with verifiable primitives.
- [Estimation and rate analysis] The iterative estimator is presented as delivering near-parametric rates because regularization bias decays exponentially while variance grows only polynomially. However, the manuscript should clarify the precise dependence of the rate on the number of iterations, the choice of regularization parameter, and the dimension of heterogeneity, as these details are load-bearing for the rate claim and its comparison to standard nonparametric estimators.
minor comments (3)
- [Abstract] The abstract claims 'near-parametric convergence rate' without stating the exact rate; adding the rate (e.g., n^{-1/2} up to logs) would improve clarity for readers.
- [Monte Carlo simulations] In the Monte Carlo section, the design of the price schedules and the data-generating process for types should be described in sufficient detail to allow readers to verify that the simulated variation satisfies the identification conditions.
- [Inference section] The bootstrap procedure is stated to be valid, but a brief discussion of the resampling scheme (e.g., whether it resamples schedules or consumers) would help assess its robustness to the dependence structure induced by repeated observations.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our paper and the constructive suggestions. We agree that greater explicitness in the identification theorem and the rate analysis will improve readability. We address each major comment below and will revise the manuscript to incorporate the clarifications.
read point-by-point responses
-
Referee: The nonparametric identification result hinges on the functional equation for the quantile function of types admitting a unique solution, which in turn requires sufficient independent variation across observed price schedules that is uncorrelated with unobserved preference heterogeneity. The manuscript states that conditions ensuring identification are derived, but the precise statement of these conditions (including invertibility of the type-to-bundle mapping and the support requirements on the schedule distribution) is central to the claim and would benefit from a more explicit theorem statement with verifiable primitives.
Authors: We agree that consolidating the identification conditions into a single, self-contained theorem statement will make the result easier to verify. The manuscript already derives the required primitives (invertibility of the type-to-bundle mapping under the maintained assumptions on utility and the support conditions on the distribution of price schedules that ensure sufficient independent variation uncorrelated with unobserved heterogeneity). In the revision we will add an explicit theorem that lists these primitives verbatim and states the unique solution property of the functional equation for the quantile function. revision: yes
-
Referee: The iterative estimator is presented as delivering near-parametric rates because regularization bias decays exponentially while variance grows only polynomially. However, the manuscript should clarify the precise dependence of the rate on the number of iterations, the choice of regularization parameter, and the dimension of heterogeneity, as these details are load-bearing for the rate claim and its comparison to standard nonparametric estimators.
Authors: We thank the referee for highlighting the need for greater precision on the rate. The paper establishes that the regularization bias decays exponentially in the number of iterations while the variance term grows only polynomially in the sample size, yielding a near-parametric rate. In the revision we will add an explicit corollary that states the convergence rate as a function of the iteration count T, the regularization parameter, and the dimension of heterogeneity, showing how T is chosen to make the bias term negligible relative to the parametric rate and why the exponential decay ensures the overall rate remains near-parametric regardless of dimension under the maintained conditions. revision: yes
Circularity Check
No circularity: identification via functional equation from observed price schedule variation is self-contained
full rationale
The paper's core claim is that the quantile function of unobserved types solves a functional equation derived from consumer choices under multiple observed nonlinear price schedules, with identification ensured by sufficient independent variation across schedules. This setup draws directly from the data-generating process and standard consumer theory without reducing to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The iterative estimator is described separately with its own convergence properties. No quoted steps in the provided text exhibit any of the enumerated circular patterns; the derivation remains independent of its target objects.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Consumers maximize a utility function subject to nonlinear budget constraints.
- domain assumption There exists sufficient independent variation in price schedules across repeated observations.
Reference graph
Works this paper leans on
- [1]
-
[2]
Blomquist, Sören, Anil Kumar, Che-Yuan Liang, and Whitney K. Newey. 2021. ``On Bunching and Identification of the Taxable Income Elasticity.'' Journal of Political Economy 129 (8): 2320--43
2021
-
[3]
Blomquist, Sören, and Whitney Newey. 2002. ``Nonparametric Estimation with Nonlinear Budget Sets.'' Econometrica 70 (6): 2455--80
2002
-
[4]
Blundell, Richard, Martin Browning, and Ian Crawford. 2008. ``Best Nonparametric Bounds on Demand Responses.'' Econometrica 76 (6): 1227--62
2008
-
[5]
Carrasco, Marine, Jean-Pierre Florens, and Eric Renault. 2007. ``Linear Inverse Problems in Structural Econometrics Estimation Based on Spectral Decomposition and Regularization.'' In Handbook of Econometrics, edited by J. J. Heckman and E. E. Leamer, 5633--5751. Elsevier
2007
-
[6]
Centorrino, Samuele, Frédérique Fève, and Jean-Pierre Florens. 2017. `` Additive Nonparametric Instrumental Regressions: a Guide to Implementation .'' Journal of Econometric Methods 6 (1)
2017
-
[7]
---------. 2025. ``Iterative Estimation of Nonparametric Regressions with Continuous Endogenous Variables and Discrete Instruments.'' Journal of Econometrics 247: 105950
2025
-
[8]
Darolles, Serge, Yanqin Fan, Jean-Pierre Florens, and Eric Renault. 2011. `` Nonparametric Instrumental Regression .'' Econometrica 79 (5): 1541--65
2011
-
[9]
Heckman, and Lars Nesheim
Ekeland, Ivar, James J. Heckman, and Lars Nesheim. 2002. ``Identifying Hedonic Models.'' American Economic Review 92 (2): 304--9
2002
-
[10]
---------. 2004. ``Identification and Estimation of Hedonic Models.'' Journal of Political Economy 112 (S1): S60--109
2004
-
[11]
Florens, Jean-Pierre, Jeffrey Racine, and Samuele Centorrino. 2018. `` Nonparametric Instrumental Variable Derivative Estimation .'' Jounal of Nonparametric Statistics 30 (2): 368--91
2018
-
[12]
Hausman, Jerry A. 1985. ``The Econometrics of Nonlinear Budget Sets.'' Econometrica 53 (6): 1255--82
1985
-
[13]
Kosorok, Michael R. 2008. Introduction to empirical processes and semiparametric inference . Springer Series in Statistics. Springer
2008
-
[14]
Kuczma, Marek, Bogdan Choczewski, and Roman Ger. 1990. Iterative Functional Equations . Encyclopedia of Mathematics and Its Applications. Cambridge University Press
1990
-
[15]
Li, Qi, and Jeffrey S. Racine. 2007. Nonparametric Econometrics: Theory and Practice . Princeton University Press
2007
-
[16]
---------. 2008. `` Nonparametric Estimation of Conditional CDF and Quantile Functions with Mixed Categorical and Continuous Data .'' Journal of Business & Economic Statistics 26 (4): 423--34
2008
-
[17]
Linton, Oliver, Esfandiar Maasoumi, and Yoon-Jae Whang. 2005. `` Consistent Testing for Stochastic Dominance under General Sampling Schemes .'' The Review of Economic Studies 72 (3): 735--65
2005
-
[18]
Mason, David M., and Jan W. H. Swanepoel. 2013. `` Uniform in bandwidth limit laws for kernel distribution function estimators .'' In, edited by M. Banerjee, F. Bunea, J. Huang, V. Koltchinskii, and M. H. Maathuis. Vol. From Probability to Statistics and Back: High--Dimensional Models and Processes -- A Festschrift in Honor of Jon A. Wellner. IMS Collections. IMS
2013
-
[19]
Matzkin, Rosa L. 2003. ``Nonparametric Estimation of Nonadditive Random Functions.'' Econometrica 71 (5): 1339--75
2003
-
[20]
Moffitt, Robert. 1986. ``The Econometrics of Piecewise-Linear Budget Constraints: A Survey and Exposition of the Maximum Likelihood Method.'' Journal of Business & Economic Statistics 4 (3): 317--28
1986
-
[21]
Newey, Whitney K., and James L. Powell. 2003. `` Instrumental Variable Estimation of Nonparametric Models .'' Econometrica 71 (5): 1565--78
2003
-
[22]
Reiss, Peter C., and Matthew W. White. 2005. ``Household Electricity Demand, Revisited.'' Review of Economic Studies 72 (3): 853--83
2005
-
[23]
Saez, Emmanuel. 2010. ``Do Taxpayers Bunch at Kink Points?'' American Economic Journal: Economic Policy 2 (3): 180--212
2010
-
[24]
Thas, Olivier. 2009. Comparing Distributions . Springer Series in Statistics. Springer-Verlag
2009
-
[25]
Tirole, Jean. 1988. The Theory of Industrial Organization. Cambridge, MA: MIT Press
1988
-
[26]
Tsybakov, Alexandre B. 2008. Introduction to Nonparametric Estimation . Springer Series in Statistics. Springer New York
2008
-
[27]
Van der Vaart, A. W. 1998. Asymptotic Statistics . Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press
1998
-
[28]
Wilson, Robert B. 1993. Nonlinear Pricing. New York: Oxford University Press. CSLReferences section 0 section table 0 A table figure 0 A figure * Appendix appendix toc section Appendix Proofs proofs Proof of Lemma lem-lem:cdfcont Proof of Lemma proof-of-lem-lemcdfcont enumerate ( enumi ) Let \(G_j = F_ _j\). That is, \[ G_j(q) = F_ (- _j(q)). \] Because o...
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.