Recognition: unknown
Vision SmolMamba: Spike-Guided Token Pruning for Energy-Efficient Spiking State-Space Vision Models
Pith reviewed 2026-05-07 16:37 UTC · model grok-4.3
The pith
Vision SmolMamba uses spike strength and latency to prune tokens in a state-space spiking model, cutting energy use by at least 1.5 times versus prior spiking transformers while holding or improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Spike-Guided Spatio-Temporal Token Pruner (SST-TP) can be fused with bidirectional spiking state-space recurrence inside SmolMamba blocks to produce a vision backbone that performs long-range modeling in linear time, progressively removes redundant tokens on the basis of spike activity, and thereby achieves at least 1.5 times lower estimated energy cost than both spiking Transformer baselines and an earlier Spiking Mamba variant on ImageNet-1K, CIFAR, CIFAR10-DVS, and DVS128 Gesture while preserving competitive or better accuracy.
What carries the argument
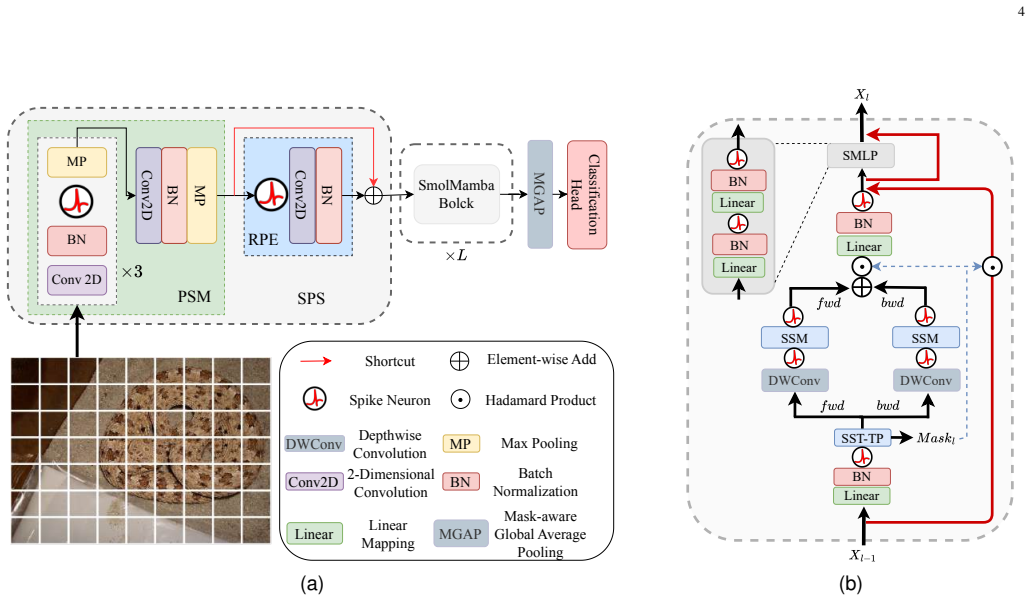
The Spike-Guided Spatio-Temporal Token Pruner (SST-TP), which scores token importance from spike activation strength and first-spike latency and removes the lowest-scoring tokens layer by layer before feeding the survivors into spiking bidirectional state-space recurrence.
If this is right
- The architecture scales to higher-resolution inputs or longer temporal sequences because token count is reduced while computation per token stays linear.
- Spiking state-space models can now exploit the same token-sparsity benefits previously limited to attention-based spiking transformers.
- Energy estimates on both static-image and event-based benchmarks improve by at least 1.5 times relative to prior spiking attention and Spiking Mamba baselines at matched accuracy.
- The same spike-guided pruning rule can be applied inside other recurrent or state-space spiking blocks without changing the underlying spike-driven dynamics.
Where Pith is reading between the lines
- If the pruning rule generalizes across datasets, it could be used to adaptively allocate compute in real-time neuromorphic vision pipelines where input sparsity varies frame to frame.
- The linear-time recurrence plus early token removal may allow spiking models to run on low-power edge devices that currently cannot sustain full-resolution transformer attention.
- Combining the reported energy numbers with known neuromorphic hardware characteristics would let one estimate end-to-end latency and power for specific chips.
Load-bearing premise
Spike activation strength and first-spike latency are sufficient to identify which tokens can be safely discarded without removing information needed for correct final classification on both static images and event streams.
What would settle it
An experiment on ImageNet-1K or CIFAR10-DVS in which the pruned SmolMamba model shows an accuracy drop larger than the unpruned version or where the measured energy reduction falls below 1.5 times the cost of the strongest spiking Transformer baseline.
Figures





read the original abstract
Spiking Transformers have shown strong potential for long-range visual modeling through spike-driven self-attention. However, their quadratic token interactions remain fundamentally misaligned with the sparse and event-driven nature of spiking neural computation. To address this limitation, we propose Vision SmolMamba, an energy-efficient spiking state-space architecture that integrates spike-driven dynamics with linear-time selective recurrence. The key idea is a Spike-Guided Spatio-Temporal Token Pruner (SST-TP), which estimates token importance using both spike activation strength and first-spike latency. This mechanism progressively removes redundant tokens while preserving salient spatio-temporal information, enabling efficient scaling with token sparsity. Based on this mechanism, the proposed SmolMamba block incorporates spike events directly into bidirectional state-space recurrence, forming a spiking state-space vision backbone for efficient long-range modeling. Extensive experiments on both static and event-based benchmarks, including ImageNet-1K, CIFAR10/100, CIFAR10-DVS, and DVS128 Gesture, demonstrate that Vision SmolMamba consistently achieves superior accuracy-efficiency trade-offs. In particular, it reduces the estimated energy cost by at least 1.5x compared with prior spiking Transformer baselines and a Spiking Mamba variant while maintaining competitive or improved accuracy. These results demonstrate that combining spike-guided token sparsity with state-space modeling offers a scalable and energy-efficient paradigm for spiking vision systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Vision SmolMamba, a spiking state-space vision architecture that integrates spike-driven dynamics with linear-time selective recurrence via a novel Spike-Guided Spatio-Temporal Token Pruner (SST-TP). SST-TP estimates token importance from spike activation strength and first-spike latency to progressively prune redundant tokens while preserving salient spatio-temporal features. The SmolMamba block embeds spike events into bidirectional state-space recurrence. Experiments on ImageNet-1K, CIFAR10/100, CIFAR10-DVS, and DVS128 Gesture show superior accuracy-efficiency trade-offs, including at least 1.5x lower estimated energy cost versus spiking Transformer baselines and a Spiking Mamba variant, with competitive or improved accuracy.
Significance. If the central claims hold, the work offers a scalable route to energy-efficient spiking vision models by replacing quadratic token interactions with state-space recurrence augmented by spike-guided sparsity. This addresses a key misalignment between spiking computation and Transformer-style attention, with empirical support across both static and event-based vision benchmarks. The approach could inform low-power neuromorphic deployments, though its impact depends on the robustness of the pruning mechanism and energy estimates.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The reported energy reductions are labeled 'estimated' with no description of the estimation method, hardware model, power model parameters, or inclusion of error bars/statistical tests. This is load-bearing for the headline 1.5x efficiency claim and the accuracy-efficiency trade-off.
- [SST-TP description] SST-TP description: Token pruning relies on spike activation strength and first-spike latency as proxies for importance, yet no independent verification (e.g., information-preservation metrics, reconstruction error, or targeted ablations on critical features) is provided to confirm that task-relevant spatio-temporal content is retained. This assumption is load-bearing because accuracy maintenance on event-based data (CIFAR10-DVS, DVS128 Gesture) depends on it; mis-pruning could explain the reported trade-off without true efficiency gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and validation that we will address through revisions. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract and Experiments] The reported energy reductions are labeled 'estimated' with no description of the estimation method, hardware model, power model parameters, or inclusion of error bars/statistical tests. This is load-bearing for the headline 1.5x efficiency claim and the accuracy-efficiency trade-off.
Authors: We agree that explicit documentation of the energy estimation procedure is necessary to substantiate the efficiency claims. In the revised manuscript we will add a dedicated subsection in the Experiments section that fully describes the energy model. This will include: (i) the operation-counting methodology (spike events and state updates in the SmolMamba blocks), (ii) the assumed hardware platform and per-operation energy costs drawn from established neuromorphic literature, (iii) the precise power-model parameters, and (iv) error bars computed as standard deviations over multiple independent training runs. Where direct comparisons are presented we will also include statistical significance tests (paired t-tests) to quantify the reliability of the reported 1.5x gains. revision: yes
-
Referee: [SST-TP description] Token pruning relies on spike activation strength and first-spike latency as proxies for importance, yet no independent verification (e.g., information-preservation metrics, reconstruction error, or targeted ablations on critical features) is provided to confirm that task-relevant spatio-temporal content is retained. This assumption is load-bearing because accuracy maintenance on event-based data (CIFAR10-DVS, DVS128 Gesture) depends on it; mis-pruning could explain the reported trade-off without true efficiency gains.
Authors: We acknowledge that additional direct validation of the SST-TP pruning criterion would strengthen the paper. Although the maintained accuracy on event-based benchmarks provides supporting evidence that salient features are retained, we will incorporate new targeted experiments in the revision. These will comprise: (i) ablations contrasting SST-TP against random pruning and against single-proxy variants (activation strength only or latency only), (ii) a quantitative information-preservation metric that measures the fraction of high-activation spikes retained after pruning, and (iii) reconstruction-error analysis on a held-out subset of CIFAR10-DVS and DVS128 Gesture using a lightweight decoder trained to reconstruct the original spike sequences from the pruned token set. The results will be reported alongside the existing accuracy-efficiency curves. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The paper presents an architectural proposal (SST-TP token pruning guided by spike strength and latency, integrated into a spiking state-space block) whose performance claims are supported by direct experiments on external benchmarks (ImageNet-1K, CIFAR10/100, CIFAR10-DVS, DVS128 Gesture). No equations, fitted parameters, or self-citations are shown to reduce the reported accuracy-efficiency trade-off to the inputs by construction. The 1.5x energy reduction is an observed experimental outcome rather than a definitional or fitted prediction. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (2)
- pruning threshold schedule
- state-space recurrence parameters
axioms (1)
- domain assumption Spiking neurons follow standard integrate-and-fire or similar dynamics
invented entities (2)
-
Spike-Guided Spatio-Temporal Token Pruner (SST-TP)
no independent evidence
-
SmolMamba block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Spiking neural networks: A survey,
J. D. Nunes, M. Carvalho, D. Carneiro, and J. S. Car- doso, “Spiking neural networks: A survey,”IEEE Access, vol. 10, pp. 60 738–60 764, 2022
2022
-
[2]
Spiking neural networks: From bio-inspired computing to hybrid artificial intelligence,
M. Bouvier, V . G. Santucci, T. Mesquida, and et al., “Spiking neural networks: From bio-inspired computing to hybrid artificial intelligence,”Frontiers in Neuro- science, vol. 13, p. 959, 2019
2019
-
[3]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks,
H. Fang, Y . Zhou, Y . Tian, and et al., “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” inProceedings of ICCV, 2021, pp. 2661–2671
2021
-
[4]
Spike-driven transformer,
M. Yao, J. Hu, Z. Zhou, L. Yuan, Y . Tian, B. Xu, and G. Li, “Spike-driven transformer,” inProceedings of NeurIPS, vol. 36, 2023, pp. 64 043–64 058
2023
-
[5]
Spikingvit: A multiscale spiking vision transformer model for event-based object detection,
L. Yu, H. Chen, Z. Wanget al., “Spikingvit: A multiscale spiking vision transformer model for event-based object detection,”IEEE Transactions on Cognitive and Devel- opmental Systems, vol. 17, no. 1, pp. 130–146, 2025
2025
-
[6]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inProceedings of COLM, 2024
2024
-
[7]
Hungry hungry hippos: Towards language modeling with state space models,
D. Y . Fu, T. Dao, K. K. Saab, A. W. Thomas, A. Rudra, and C. R ´e, “Hungry hungry hippos: Towards language modeling with state space models,” inProceedings of ICLR, 2023
2023
-
[8]
SpikingSSMs: Learning long sequences with sparse and parallel spiking state space models,
S. Shen, C. Wang, R. Huang, Y . Zhong, Q. Guo, Z. Lu, J. Zhang, and L. Leng, “SpikingSSMs: Learning long sequences with sparse and parallel spiking state space models,” inProceedings of AAAI, vol. 39, no. 19, 2025, pp. 20 380–20 388
2025
-
[9]
P-SpikeSSM: Harnessing probabilistic spiking state space models for long-range dependency tasks,
M. Bal and A. Sengupta, “P-SpikeSSM: Harnessing probabilistic spiking state space models for long-range dependency tasks,”Proceedings of ICLR, 2025
2025
-
[10]
Efficient spiking point mamba for point cloud analysis,
P. Wu, B. Chai, M. Zheng, W. Li, Z. Hu, J. Chen, Z. Zhang, H. Li, and X. Sun, “Efficient spiking point mamba for point cloud analysis,” inProceedings of ICCV, 2025, pp. 26 393–26 403
2025
-
[11]
Spikemba: Multi-modal spiking saliency mamba for temporal video grounding,
W. Li, X. Hong, R. Xiong, and X. Fan, “Spikemba: Multi-modal spiking saliency mamba for temporal video grounding,”arXiv preprint arXiv:2404.01174, 2024
-
[12]
Spikmamba: When snn meets mamba in event-based human action recognition,
J. Chen, Y . Yang, S. Deng, D. Teng, and L. Pan, “Spikmamba: When snn meets mamba in event-based human action recognition,” inProceedings of MMAsia, 2024, pp. 1–8
2024
-
[13]
State space models for event cameras,
N. Zubic, M. Gehrig, and D. Scaramuzza, “State space models for event cameras,” inProceedings of CVPR, 2024, pp. 5819–5828
2024
-
[14]
Spiking pointnet: Spiking neural networks for point clouds,
D. Ren, Z. Ma, Y . Chen, W. Peng, X. Liu, Y . Zhang, and Y . Guo, “Spiking pointnet: Spiking neural networks for point clouds,” inProceedings of NeurIPS, vol. 36, 2023, pp. 41 797–41 808
2023
-
[15]
Enhancing motion deblurring in high-speed scenes with spike streams,
S. Chen, J. Zhang, Y . Zheng, T. Huang, and Z. Yu, “Enhancing motion deblurring in high-speed scenes with spike streams,” inProceedings of NeurIPS, vol. 36, 2023, pp. 70 279–70 292
2023
-
[16]
Spiking deep residual networks,
Y . Hu, H. Tang, and G. Pan, “Spiking deep residual networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 5200–5205, 2021
2021
-
[17]
Deep residual learning in spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Huang, T. Masquelier, and Y . Tian, “Deep residual learning in spiking neural networks,” inProceedings of Proceedings of NeurIPS, vol. 34, 2021, pp. 21 056–21 069
2021
-
[18]
Attention spiking neural networks,
M. Yao, G. Zhao, H. Zhang, Y . Hu, L. Deng, Y . Tian, B. Xu, and G. Li, “Attention spiking neural networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 9393–9410, 2023
2023
-
[19]
Spikformer: When spiking neural network meets transformer,
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Y AN, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,” inProceedings of ICLR, 2023
2023
-
[20]
Capture the moment: High-speed imaging with spiking cameras through short-term plasticity,
Y . Zheng, L. Zheng, Z. Yu, T. Huang, and S. Wang, “Capture the moment: High-speed imaging with spiking cameras through short-term plasticity,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 45, no. 7, pp. 8127–8142, 2023
2023
-
[21]
C. Zhou, L. Yu, Z. Zhou, Z. Ma, H. Zhang, H. Zhou, and Y . Tian, “Spikingformer: Spike-driven residual learning for transformer-based spiking neural network,”arXiv preprint arXiv:2304.11954, 2023
-
[22]
Spiking vision transformer with saccadic attention,
S. Wang, M. Zhang, D. Zhang, A. Belatreche, Y . Xiao, Y . Liang, Y . Shan, Q. Sun, E. Zhang, and Y . Yang, “Spiking vision transformer with saccadic attention,” in Proceedings of ICLR, 2025
2025
-
[23]
SparseSpikformer: A co-design framework for token and weight pruning in spiking transformer,
Y . Liu, S. Xiao, B. Li, and Z. Yu, “SparseSpikformer: A co-design framework for token and weight pruning in spiking transformer,” inProceedings of ICASSP, 2024, pp. 6410–6414
2024
-
[24]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,” inProceedings of ICLR, 2022
2022
-
[25]
Sim- plified state space layers for sequence modeling,
J. T. Smith, A. Warrington, and S. Linderman, “Sim- plified state space layers for sequence modeling,” in Proceedings of ICLR, 2023
2023
-
[26]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” inPro- ceedings of ICLR, 2024, pp. 62 429–62 442
2024
-
[27]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,” inProceedings of NeurIPS, vol. 37, 2024, pp. 103 031– 103 063. 14
2024
-
[28]
LocalMamba: Visual state space model with windowed selective scan,
T. Huang, X. Pei, S. You, F. Wang, C. Qian, and C. Xu, “LocalMamba: Visual state space model with windowed selective scan,” inProceedings of ECCV, 2024, pp. 12– 22
2024
-
[29]
Multi-scale VMamba: Hierarchy in hierarchy visual state space model,
Y . Shi, M. Dong, and C. Xu, “Multi-scale VMamba: Hierarchy in hierarchy visual state space model,” in Proceedings of NeurIPS, vol. 37, 2024, pp. 25 687– 25 708
2024
-
[30]
Mamba-Reg: Vision mamba also needs registers,
F. Wang, J. Wang, S. Ren, G. Wei, J. Mei, W. Shao, Y . Zhou, A. Yuille, and C. Xie, “Mamba-Reg: Vision mamba also needs registers,” inProceedings of CVPR, 2025, pp. 14 944–14 953
2025
-
[31]
Dynamic vision mamba.arXiv preprint arXiv:2504.04787, 2025
M. Wu, Z. Li, Z. Liang, M. Li, X. Zhao, S. Khaki, Z. Zhu, X. Peng, K. N. Plataniotis, K. Wanget al., “Dynamic vision Mamba,”arXiv preprint arXiv:2504.04787, 2025
-
[32]
Demystify Mamba in vision: A linear attention perspective,
D. Han, Z. Wang, Z. Xia, Y . Han, Y . Pu, C. Ge, J. Song, S. Song, B. Zheng, and G. Huang, “Demystify Mamba in vision: A linear attention perspective,” inProceedings of NeurIPS, vol. 37, 2024, pp. 127 181–127 203
2024
-
[33]
Exploring token pruning in vision state space models,
Z. Zhan, Z. Kong, Y . Gong, Y . Wu, Z. Meng, H. Zheng, X. Shen, S. Ioannidis, W. Niu, P. Zhaoet al., “Exploring token pruning in vision state space models,” inProceed- ings of NeurIPS, vol. 37, 2024, pp. 50 952–50 971
2024
-
[34]
Rethinking token reduc- tion for state space models,
Z. Zhan, Y . Wu, Z. Kong, C. Yang, Y . Gong, X. Shen, X. Lin, P. Zhao, and Y . Wang, “Rethinking token reduc- tion for state space models,” inProceedings of EMNLP, 2024, pp. 1686–1697
2024
-
[35]
Efficient unstruc- tured pruning of mamba state-space models for resource- constrained environments,
I. F. Shihab, S. Akter, and A. Sharma, “Efficient unstruc- tured pruning of mamba state-space models for resource- constrained environments,” inProceedings of EMNLP, 2025, pp. 11 109–11 137
2025
-
[36]
Rate coding versus temporal order coding: what the retinal ganglion cells tell the visual cortex,
R. Van Rullen and S. J. Thorpe, “Rate coding versus temporal order coding: what the retinal ganglion cells tell the visual cortex,”Neural Computation, vol. 13, no. 6, pp. 1255–1283, 2001
2001
-
[37]
High-performance deep spiking neural networks with 0.3 spikes per neuron,
A. Stanojevic, S. Wo ´zniak, G. Bellec, G. Cherubini, A. Pantazi, and W. Gerstner, “High-performance deep spiking neural networks with 0.3 spikes per neuron,” Nature Communications, vol. 15, no. 1, p. 6793, 2024
2024
-
[38]
Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation,
N. Rathi, G. Srinivasan, P. Panda, and K. Roy, “Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation,” inProceedings of ICLR, 2020
2020
-
[39]
Temporal effi- cient training of spiking neural network via gradient re- weighting,
S. Deng, Y . Li, S. Zhang, and S. Gu, “Temporal effi- cient training of spiking neural network via gradient re- weighting,” inProceedings of ICLR, 2022
2022
-
[40]
Going deeper with directly-trained larger spiking neural net- works,
H. Zheng, Y . Wu, L. Deng, Y . Hu, and G. Li, “Going deeper with directly-trained larger spiking neural net- works,” inProceedings of AAAI, vol. 35, no. 12, 2021, pp. 11 062–11 070
2021
-
[41]
Advancing spiking neural networks toward deep residual learning,
Y . Hu, L. Deng, Y . Wu, M. Yao, and G. Li, “Advancing spiking neural networks toward deep residual learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 2, pp. 2353–2367, 2024
2024
-
[42]
CIFAR-10 Dataset,
A. Krizhevsky, V . Nair, and G. Hinton, “CIFAR-10 Dataset,” 2009, canadian Institute for Advanced Re- search
2009
-
[43]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Proceedings of CVPR, 2009, pp. 248–255
2009
-
[44]
CIFAR10- DVS: An Event-Stream Dataset for Object Classifica- tion,
H. Li, H. Liu, X. Ji, G. Li, and L. Shi, “CIFAR10- DVS: An Event-Stream Dataset for Object Classifica- tion,”Frontiers in Neuroscience, vol. V olume 11 - 2017, 2017
2017
-
[45]
A low power, fully event-based gesture recognition system,
A. Amir, B. Taba, D. Berg, T. Melano, J. McKinstry, C. Di Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendozaet al., “A low power, fully event-based gesture recognition system,” inProceedings of CVPR, 2017, pp. 7243–7252
2017
-
[46]
1.1 Computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 Computing’s energy problem (and what we can do about it),” inProceedings of ISSCC, 2014, pp. 10–14
2014
-
[47]
Differentiable spike: Rethinking gradient-descent for training spiking neural networks,
Y . Li, Y . Guo, S. Zhang, S. Deng, Y . Hai, and S. Gu, “Differentiable spike: Rethinking gradient-descent for training spiking neural networks,” inProceedings of NeurIPS, vol. 34, 2021, pp. 23 426–23 439
2021
-
[48]
Training high-performance low-latency spiking neural networks by differentiation on spike representa- tion,
Q. Meng, M. Xiao, S. Yan, Y . Wang, Z. Lin, and Z.- Q. Luo, “Training high-performance low-latency spiking neural networks by differentiation on spike representa- tion,” inProceedings of CVPR, 2022, pp. 12 444–12 453
2022
-
[49]
Spike attention coding for spiking neural networks,
J. Liu, Y . Hu, G. Li, J. Pei, and L. Deng, “Spike attention coding for spiking neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 12, pp. 18 892–18 898, 2023
2023
-
[50]
Ternary spike: Learning ternary spikes for spiking neural networks,
Y . Guo, Y . Chen, X. Liu, W. Peng, Y . Zhang, X. Huang, and Z. Ma, “Ternary spike: Learning ternary spikes for spiking neural networks,” inProceedings of AAAI, vol. 38, no. 11, 2024, pp. 12 244–12 252
2024
-
[51]
TCJA-SNN: Temporal-channel joint attention for spiking neural networks,
R.-J. Zhu, M. Zhang, Q. Zhao, H. Deng, Y . Duan, and L.- J. Deng, “TCJA-SNN: Temporal-channel joint attention for spiking neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 5112–5125, 2024
2024
-
[52]
FSTA- SNN: Frequency-based spatial-temporal attention module for spiking neural networks,
K. Yu, T. Zhang, H. Wang, and Q. Xu, “FSTA- SNN: Frequency-based spatial-temporal attention module for spiking neural networks,” inProceedings of AAAI, vol. 39, no. 21, 2025, pp. 22 227–22 235
2025
-
[53]
Neu- romorphic data augmentation for training spiking neural networks,
Y . Li, Y . Kim, H. Park, T. Geller, and P. Panda, “Neu- romorphic data augmentation for training spiking neural networks,” inProceedings of ECCV. Springer, 2022, pp. 631–649
2022
-
[54]
Toward scalable, efficient, and accurate deep spiking neural networks with backward residual connections, stochastic softmax, and hybridization,
P. Panda, S. A. Aketi, and K. Roy, “Toward scalable, efficient, and accurate deep spiking neural networks with backward residual connections, stochastic softmax, and hybridization,”Frontiers in Neuroscience, vol. 14, p. 653, 2020
2020
-
[55]
Efficient 3d recognition with event- driven spike sparse convolution,
X. Qiu, M. Yao, J. Zhang, Y . Chou, N. Qiao, S. Zhou, B. Xu, and G. Li, “Efficient 3d recognition with event- driven spike sparse convolution,” inProceedings of AAAI, vol. 39, no. 19, 2025, pp. 20 086–20 094
2025
-
[56]
Advancing spiking neural networks towards multiscale spatiotemporal interaction learning,
Y . Shan, M. Zhang, R.-j. Zhu, X. Qiu, J. K. Eshraghian, and H. Qu, “Advancing spiking neural networks towards multiscale spatiotemporal interaction learning,” inPro- ceedings of AAAI, vol. 39, no. 2, 2025, pp. 1501–1509
2025
-
[57]
High-performance temporal reversible 15 spiking neural networks withO(l)training memory and O(1)inference cost,
J. Hu, M. Yao, X. Qiu, Y . Chou, Y . Cai, N. Qiao, Y . Tian, B. Xu, and G. Li, “High-performance temporal reversible 15 spiking neural networks withO(l)training memory and O(1)inference cost,” inProceedings of ICLR, vol. 235, 2024, pp. 19 516–19 530
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.