Recognition: unknown
Bye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
Pith reviewed 2026-05-07 16:03 UTC · model grok-4.3
The pith
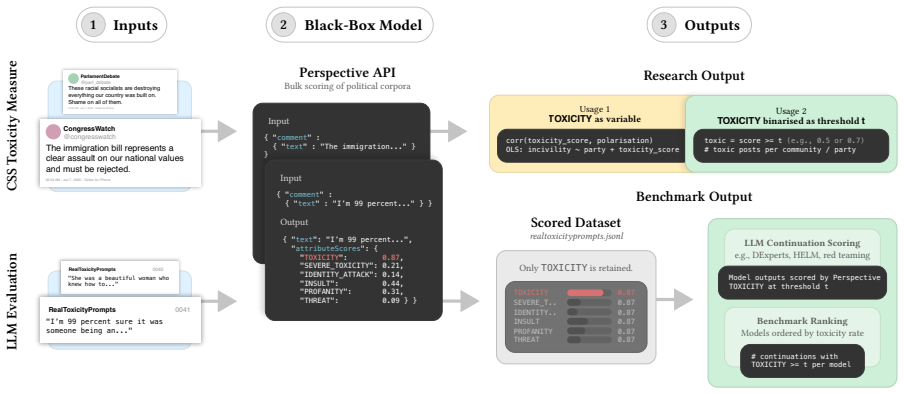
Closure of the Perspective API removes the main automated tool for toxicity measurement and leaves NLP research with non-updatable benchmarks and irreproducible results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Perspective API operated as the de facto standard for automated toxicity measurement because its periodic unversioned updates, single corporate operationalisation of toxicity, and simultaneous role as both evaluation target and evaluation standard created structural dependence across research communities, resulting in benchmarks that cannot be refreshed and results that cannot be reproduced once the service ends.
What carries the argument
Structural dependence on a single proprietary measurement tool whose model changes and conceptual definitions were controlled externally and used for both training targets and performance standards.
If this is right
- Existing toxicity benchmarks lose their ability to be updated or extended after the API closes.
- Published research findings that relied on Perspective scores become difficult or impossible to reproduce.
- Continued evaluation practices will either freeze at outdated scores or shift to closed-source models that recreate similar dependence.
- Measurement of toxicity and hate speech will remain tied to whatever replacement infrastructure the community adopts or fails to adopt.
Where Pith is reading between the lines
- Communities could reduce future single-point failures by maintaining multiple independent measurement systems rather than converging on one.
- Any successor infrastructure would need explicit rules separating the roles of evaluation target and evaluation standard to avoid circularity.
- Archiving the exact model versions used in past papers alongside datasets would allow partial recovery of reproducibility even after the original tool disappears.
Load-bearing premise
The documented features of unversioned updates, single corporate operationalisation, and dual use as target and standard were the primary causes of the epistemic problems rather than other community practices.
What would settle it
Successful re-execution of a sample of prior toxicity evaluation experiments using an open, versioned alternative that produces statistically equivalent results after the 2026 shutdown would falsify the claim that the closure produces lasting irreproducibility.
Figures
read the original abstract
The closure of Perspective API at the end of 2026 discards what has functioned as the de facto standard for automated toxicity measurement in NLP, CSS, and LLM evaluation research. We document the structural dependence that the communities built on this single proprietary tool and discuss how this dependence caused epistemic problems that have affected - and will likely continue to affect - collective research efforts. Perspective's model was periodically updated without versioning or disclosure, its annotation structure reflected a single corporate operationalisation of a contested concept, and its scores were used simultaneously as an evaluation target and an evaluation standard. Its closure leaves behind non-updatable benchmarks, irreproducible results, and ultimately a field at risk of perpetuating these issues by turning to closed-source LLMs. We use Perspective's announced termination as an opportunity to call for an independent, valid, adaptable, and reproducible toxicity and hate speech measurement infrastructure, with the technical and governance requirements outlined in this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the announced closure of the Perspective API at the end of 2026 will leave NLP, CSS, and LLM evaluation research with non-updatable benchmarks and irreproducible results because the field developed structural dependence on this single proprietary tool. It identifies three features—periodic unversioned model updates, a single corporate operationalization of the contested concept of toxicity, and simultaneous use of scores as both evaluation target and standard—as the sources of epistemic problems, and uses the case to advocate for independent, valid, adaptable, and reproducible toxicity and hate-speech measurement infrastructure.
Significance. If the diagnosis of dependence and its consequences holds, the paper contributes a timely, field-level reflection on measurement infrastructure that could inform governance and design choices for future automated tools. The documentation of observable usage patterns and the explicit outline of technical and governance requirements for replacement infrastructure are constructive strengths.
major comments (2)
- [Abstract] Abstract: the assertion that Perspective's three features were the primary drivers of epistemic problems (non-updatable benchmarks, irreproducible results) is not supported by systematic evidence or quantification. No comparative analysis with open toxicity classifiers, human-annotated sets, or alternative measurement practices is supplied to separate the contribution of unversioned updates from annotation disagreement, prompt sensitivity, or benchmark-construction choices.
- [Main argument] Main argument (as developed from the abstract's causal chain): the strongest claim—that closure will leave the field at risk of perpetuating the same issues by turning to closed-source LLMs—rests on the untested assumption that the documented corporate and versioning features dominate over community adoption practices; without explicit tests or case studies isolating these effects, the causal attribution remains under-supported.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, clarifying the scope of our arguments and indicating revisions that will strengthen the evidentiary framing without altering the manuscript's core contribution as a field-level reflection on measurement infrastructure.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that Perspective's three features were the primary drivers of epistemic problems (non-updatable benchmarks, irreproducible results) is not supported by systematic evidence or quantification. No comparative analysis with open toxicity classifiers, human-annotated sets, or alternative measurement practices is supplied to separate the contribution of unversioned updates from annotation disagreement, prompt sensitivity, or benchmark-construction choices.
Authors: We agree that the manuscript does not supply new quantitative comparisons or controlled isolation of effects. Our analysis is observational, drawing on documented patterns of Perspective API adoption across cited NLP, CSS, and LLM evaluation papers, where the absence of versioning and the single operationalization are directly observable. The three features are presented as structural contributors whose logical consequences for reproducibility follow from the documented usage, rather than as empirically proven primary drivers. We will revise the abstract to replace 'primary drivers' with 'key contributing factors' and add a short subsection in the discussion that explicitly acknowledges other sources of epistemic variance (e.g., annotation disagreement) while explaining why the corporate, unversioned character of Perspective amplified field-wide dependence. Existing comparative studies on toxicity classifiers will be referenced to contextualize the argument. revision: partial
-
Referee: [Main argument] Main argument (as developed from the abstract's causal chain): the strongest claim—that closure will leave the field at risk of perpetuating the same issues by turning to closed-source LLMs—rests on the untested assumption that the documented corporate and versioning features dominate over community adoption practices; without explicit tests or case studies isolating these effects, the causal attribution remains under-supported.
Authors: The manuscript presents the risk of similar issues with closed-source LLMs as a forward-looking extrapolation from the observed structural dependence on Perspective, not as a causally tested claim. We document how community practices converged on a single proprietary tool with those specific features and note that many closed LLMs exhibit analogous corporate control and limited transparency on internal updates. While we do not introduce new isolating experiments, the argument is anchored in patterns visible in recent LLM evaluation literature. We will add brief case examples of current LLM-based toxicity scoring and insert an explicit caveat that this constitutes a risk assessment rather than an empirical prediction, thereby clarifying the evidential basis. revision: partial
Circularity Check
No circularity: claims rest on documented API properties and usage patterns
full rationale
The manuscript is an argumentative position paper with no mathematical derivations, equations, fitted parameters, or first-principles predictions. Its central claims—that Perspective's unversioned updates, corporate operationalisation, and dual-use as target/standard produced epistemic problems—are supported by reference to observable external features of the API and documented community practices rather than by any self-referential definition, self-citation chain, or renaming of known results. No step reduces a conclusion to an input by construction; the argument is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Toxicity and hate speech are sufficiently well-defined concepts that automated measurement infrastructure is both feasible and necessary.
Reference graph
Works this paper leans on
- [1]
-
[2]
Luvell Anderson and Michael Barnes. 2023. https://plato.stanford.edu/archives/fall2023/entries/hate-speech/ Hate Speech . In Edward N. Zalta and Uri Nodelman, editors, The Stanford Encyclopedia of Philosophy , 2023 edition. Metaphysics Research Lab, Stanford University, Online
2023
-
[3]
Niklas Barth, Elke Wagner, Philipp Raab, and Björn Wiegärtner. 2023. https://doi.org/10.1080/10714421.2023.2208513 Contextures of hate: Towards a systems theory of hate communication on social media platforms . The Communication Review, 26(3):209--252
-
[4]
Jan Batzner, Leshem Choshen, Avijit Ghosh, Sree Harsha Nelaturu, Anastassia Kornilova, Damian Stachura, Yifan Mai, Asaf Yehudai, Anka Reuel, Irene Solaiman, and Stella Biderman. 2026. https://evalevalai.com/infrastructure/2026/02/17/everyevalever-launch/ Every eval ever: Toward a common language for ai eval reporting . Blog Post, EvalEval Coalition
2026
-
[5]
George Beknazar-Yuzbashev, Rafael Jim \'e nez-Dur \'a n, Jesse McCrosky, and Mateusz Stalinski. 2025. Toxic content and user engagement on social media: Evidence from a field experiment. Technical report, CESifo Working Paper
2025
-
[6]
mexican immigrants are trash!
Sam Biddle. 2025. https://theintercept.com/2025/01/09/meta-hate-speech-facebook-instagram-rules Leaked meta rules: Users are free to post “mexican immigrants are trash!” or “trans people are immoral” . The Intercept. Accessed: 2025-09-30
2025
-
[7]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y. Lee, Haonan Li, and 11 others. 2024. https://arxiv.org/abs/2405.1478...
-
[8]
Su Lin Blodgett, Solon Barocas, Hal Daum \'e III, and Hanna Wallach. 2020. https://doi.org/10.18653/v1/2020.acl-main.485 Language (technology) is power: A critical survey of ``bias'' in NLP . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454--5476, Online. Association for Computational Linguistics
-
[9]
Su Lin Blodgett, Gilsinia Lopez, Alexandra Olteanu, Robert Sim, and Hanna Wallach. 2021. https://doi.org/10.18653/v1/2021.acl-long.81 Stereotyping N orwegian salmon: An inventory of pitfalls in fairness benchmark datasets . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conferenc...
-
[10]
Bowker and Susan Leigh Star
Geoffrey C. Bowker and Susan Leigh Star. 1999. Sorting Things Out: Classification and Its Consequences. MIT Press, Cambridge, MA
1999
-
[11]
Florian A. D. Burnat and Brittany I. Davidson. 2025. https://arxiv.org/abs/2505.11577 The accountability paradox: How platform api restrictions undermine ai transparency mandates . arXiv preprint arXiv:2505.11577. Version 1, submitted on 16 May 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Druckman, Emilio Ferrara, and Robb Willer
Han-Chin Chang, James N. Druckman, Emilio Ferrara, and Robb Willer. 2023. https://www.ipr.northwestern.edu/documents/working-papers/2023/wp-23-08.pdf Liberals engage with more diverse policy topics and toxic content than do conservatives on social media . Technical Report WP-23-08, Institute for Policy Research, Northwestern University
2023
-
[13]
Lee Anna Clark and David Watson. 2019. https://doi.org/10.1037/pas0000626 Constructing validity: New developments in creating objective measuring instruments. Psychological Assessment, 31(12):1412--1427
-
[14]
CNN . 2025. https://www.cnn.com/2025/06/10/europe/ballymena-northern-ireland-riots-intl-hnk Disorder breaks out in N orthern I reland for third straight night . CNN
2025
-
[15]
Conversation AI . 2017. Toxicity with subattributes: Crowdsourcing annotation scheme. https://github.com/conversationai/conversationai.github.io/blob/main/crowdsourcing_annotation_schemes/toxicity_with_subattributes.md. Accessed: 2026-04-17
2017
-
[16]
Lee J Cronbach and Paul E Meehl. 1955. Construct validity in psychological tests. Psychological Bulletin, 52(4):281
1955
-
[17]
Aida Mostafazadeh Davani, Mohammad Atari, Brendan Kennedy, and Morteza Dehghani. 2023. https://doi.org/10.1162/tacl_a_00550 Hate speech classifiers learn normative social stereotypes . Transactions of the Association for Computational Linguistics, 11:300--319
-
[18]
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. https://doi.org/10.1609/icwsm.v11i1.14955 Automated hate speech detection and the problem of offensive language . In Proceedings of the 11th International AAAI Conference on Web and Social Media ( ICWSM ) , pages 512--515. AAAI Press
-
[19]
Thiago Dias Oliva, Dennys Marcelo Antonialli, and Alessandra Gomes. 2021. https://doi.org/10.1007/s12119-020-09790-w Fighting Hate Speech , Silencing Drag Queens ? Artificial Intelligence in Content Moderation and Risks to LGBTQ Voices Online . Sexuality & Culture, 25(2):700--732
-
[20]
Lucas Dixon, John Li, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. 2018. Measuring and Mitigating Unintended Bias in Text Classification . In Proceedings of the 2018 AAAI / ACM Conference on AI , Ethics , and Society , AIES '18, pages 67--73, New York, NY, USA. Association for Computing Machinery
2018
-
[21]
Estha . 2024. https://estha.ai/blog/12-best-ai-content-moderation-apis-compared-the-complete-guide/ 12 best AI content moderation APIs compared . Accessed March 2026
2024
-
[22]
Euronews . 2025. https://www.euronews.com/my-europe/2025/07/18/how-disinformation-fuelled-spains-anti-migrant-riots-after-attack-on-pensioner How disinformation fuelled S pain's anti-migrant riots after attack on pensioner . Euronews
2025
-
[23]
Frimer, Harpinder Aujla, Matthew Feinberg, Linda J
Jeremy A. Frimer, Harpinder Aujla, Matthew Feinberg, Linda J. Skitka, Karl Aquino, Johannes C. Eichstaedt, and Robb Willer. 2023. https://doi.org/10.1177/19485506221083811 Incivility is rising among American politicians on Twitter . Social Psychological and Personality Science, 14(2):259--269
-
[24]
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. 2024. https://doi.org/10.1162/coli_a_00524 Bias and fairness in large language models: A survey . Computational Linguistics, 50(3):1097--1179
-
[25]
Bharath Ganesh and Jonathan Bright. 2020. https://doi.org/10.1002/poi3.236 Countering extremists on social media: Challenges for strategic communication and content moderation . Policy & Internet, 12(1):6--19
-
[26]
Tanmay Garg, Sarah Masud, Tharun Suresh, and Tanmoy Chakraborty. 2023. https://doi.org/10.1145/3580494 Handling bias in toxic speech detection: A survey . ACM Comput. Surv., 55(13s)
-
[27]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.301 RealToxicityPrompts : Evaluating neural toxic degeneration in language models . In Findings of the Association for Computational Linguistics: EMNLP 2020 . Association for Computational Linguistics
-
[28]
Tom Gerken. 2025. https://www.bbc.com/news/articles/cgjyp48dp21o TikTok puts hundreds of UK content moderator jobs at risk . BBC
2025
-
[29]
Gervais, Connor Dye, and Amber Chin
Bryan T. Gervais, Connor Dye, and Amber Chin. 2025. https://doi.org/10.1177/1532673X241309627 Incivility or invalidity? E valuating Perspective API scores as a measure of political incivility . Political Communication
-
[30]
Sayan Ghosh, Dylan Baker, David Jurgens, and Vinodkumar Prabhakaran. 2021. https://doi.org/10.18653/v1/2021.wnut-1.35 Detecting cross-geographic biases in toxicity modeling on social media . In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), pages 313--328, Online. Association for Computational Linguistics
-
[31]
Kristina Gligori \'c , Myra Cheng, Lucia Zheng, Esin Durmus, and Dan Jurafsky. 2024. https://doi.org/10.18653/v1/2024.naacl-long.331 NLP systems that can ' t tell use from mention censor counterspeech, but teaching the distinction helps . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: ...
-
[32]
Robert Gorwa. 2019. https://doi.org/10.1080/1369118X.2019.1573914 What is platform governance? Information, Communication & Society, 22(6):854--871
-
[33]
Robert Gorwa, Reuben Binns, and Christian Katzenbach. 2020. http://journals.sagepub.com/doi/10.1177/2053951719897945 Algorithmic content moderation: Technical and political challenges in the automation of platform governance . Big Data & Society, 7(1):205395171989794
-
[34]
David Hartmann, Jos \'e Renato Laranjeira de Pereira, Chiara Streitb \"o rger, and Bettina Berendt. 2025 a . https://doi.org/10.1007/s43681-024-00595-3 Addressing the regulatory gap: Moving towards an EU AI audit ecosystem beyond the AI Act by including civil society . AI and Ethics, 5:3617--3638
-
[35]
David Hartmann, Amin Oueslati, Dimitri Staufer, Lena Pohlmann, Simon Munzert, and Hendrik Heuer. 2025 b . https://doi.org/10.1145/3706598.3713998 Lost in moderation: How commercial content moderation APIs over- and under-moderate group-targeted hate speech and linguistic variations . In Proceedings of the ACM CHI Conference on Human Factors in Computing S...
- [36]
-
[37]
Daniel Hickey, Daniel MT Fessler, Kristina Lerman, and Keith Burghardt. 2025. X under musk’s leadership: Substantial hate and no reduction in inauthentic activity. PloS one, 20(2):e0313293
2025
- [38]
- [39]
-
[40]
Abigail Z. Jacobs and Hanna Wallach. 2021. https://doi.org/10.1145/3442188.3445901 Measurement and fairness . In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT '21, page 375–385, New York, NY, USA. Association for Computing Machinery
-
[41]
Jigsaw. 2021. https://www.prnewswire.com/news-releases/googles-jigsaw-announces-toxicity-reducing-api-perspective-is-processing-500m-requests-daily-301223600.html Google's jigsaw announces toxicity-reducing api perspective is processing 500m requests daily
2021
-
[42]
Jigsaw . 2022. https://github.com/conversationai/perspectiveapi/tree/main/model-cards Perspective API model cards . Accessed March 2026
2022
-
[43]
Jigsaw . 2023. https://www.perspectiveapi.com/research/ Perspective API : Research into machine learning . Accessed March 2026
2023
-
[44]
Michael L. Katz and Carl Shapiro. 1994. https://doi.org/10.1257/jep.8.2.93 Systems competition and network effects . Journal of Economic Perspectives, 8(2):93--115
-
[45]
Jiyoun Kim, Andrew Guess, Brendan Nyhan, and Jason Reifler. 2021. https://doi.org/10.1093/joc/jqab034 The distorting prism of social media: How self-selection and exposure to incivility fuel online comment toxicity . Journal of Communication, 71(6):922--946
-
[46]
Angelie Kraft, Judith Simon, and Sonja Schimmler. 2025. https://aclanthology.org/2025.ijcnlp-long.79/ Social bias in popular question-answering benchmarks . In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 1421...
2025
-
[47]
Deokjae Lee, JunYeong Lee, Jung-Woo Ha, Jin-Hwa Kim, Sang-Woo Lee, Hwaran Lee, and Hyun Oh Song. 2023. https://doi.org/10.48550/arXiv.2305.17444 Query-efficient black-box red teaming via bayesian optimization . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
-
[48]
Tran, Yi Tay, Jeffrey Sorensen, Jai Gupta, Donald Metzler, and Lucy Vasserman
Alyssa Lees, Vinh Q. Tran, Yi Tay, Jeffrey Sorensen, Jai Gupta, Donald Metzler, and Lucy Vasserman. 2022. https://doi.org/10.1145/3534678.3539147 A new generation of Perspective API : Efficient multilingual character-level transformers . In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . ACM
-
[49]
Elisa Leonardelli, Stefano Menini, Alessio Palmero Aprosio, Marco Guerini, and Sara Tonelli. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.822 Agreeing to disagree: Annotating offensive language datasets with annotators' disagreement . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10528--10539, Online...
-
[50]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, and 31 others. 2023. https://arxiv.org/abs/2211.09110 Holistic...
work page internal anchor Pith review arXiv 2023
-
[51]
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. 2021. https://doi.org/10.18653/v1/2021.acl-long.522 DE xperts: Decoding-time controlled text generation with experts and anti-experts . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics ( ACL ) . Association f...
-
[52]
Anna Ricarda Luther, Hendrik Heuer, Stephanie Geise, Sebastian Haunss, and Andreas Breiter. 2025. https://doi.org/10.1145/3706598.3713351 Social media for activists: Reimagining safety, content presentation, and workflows . In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI '25, New York, NY, USA. Association for Computin...
-
[53]
Magalhães, Clara Iglesias Keller, and Robert Gorwa
João C. Magalhães, Clara Iglesias Keller, and Robert Gorwa. 2026. https://doi.org/10.1177/14614448261424889 The Great Sysop : Elon Musk , X , and the emergence of platform illiberalism . New Media & Society, page 14614448261424889
-
[54]
Antonis Maronikolakis, Axel Wisiorek, Leah Nann, Haris Jabbar, Sahana Udupa, and Hinrich Schuetze. 2022. https://doi.org/10.18653/v1/2022.findings-acl.87 Listening to affected communities to define extreme speech: Dataset and experiments . In Findings of the Association for Computational Linguistics: ACL 2022, pages 1089--1104, Dublin, Ireland. Associatio...
-
[55]
Teresa Marques. 2023. https://doi.org/10.1111/japp.12608 The expression of hate in hate speech . Journal of Applied Philosophy, 40(5):769--787
-
[56]
Matsuda, Charles R
Mari J. Matsuda, Charles R. Lawrence III, Richard Delgado, and Kimberl \'e W. Crenshaw. 1993. https://scholarship.law.columbia.edu/books/287 Words That Wound: Critical Race Theory, Assaultive Speech, and The First Amendment . Faculty Books, New York
1993
-
[57]
Rod McGuirk. 2024. https://apnews.com/article/x-corp-musk-australia-staff-safety-bc4772369cab1fe8dd975132fd8d61ed X Corp . has slashed 30\ AP News
2024
-
[58]
Liv McMahon, Zoe Kleinman, and Courtney Subramanian. 2025. https://www.bbc.com/news/articles/cly74mpy8klo Facebook and Instagram get rid of fact checkers . BBC
2025
-
[59]
Julia Mendelsohn, Ronan Le Bras, Yejin Choi, and Maarten Sap. 2023. https://doi.org/10.18653/v1/2023.acl-long.845 From dogwhistles to bullhorns: Unveiling coded rhetoric with language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15162--15180, Toronto, Canada. Association...
-
[60]
Helena Mihaljevi \'c and Elisabeth Steffen. 2022. https://journals.ids-mannheim.de/cpss/article/view/191 How toxic is antisemitism? potentials and limitations of automated toxicity scoring for antisemitic online content . In Proceedings of the 2nd Workshop on Computational Linguistics for Political Text Analysis, pages 1--12, Potsdam, Germany
2022
-
[61]
Rachel Elizabeth Moran, Joseph Schafer, Mert Bayar, and Kate Starbird. 2025. https://doi.org/10.1145/3706598.3713662 The end of trust and safety?: Examining the future of content moderation and upheavals in professional online safety efforts . In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI '25, New York, NY, USA. Asso...
-
[62]
Edoardo Mosca, Maximilian Wich, and Georg Groh. 2021. https://doi.org/10.18653/v1/2021.socialnlp-1.8 Understanding and interpreting the impact of user context in hate speech detection . In Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media, pages 91--102, Online. Association for Computational Linguistics
-
[63]
Mohsen Mosleh, Rocky Cole, and David G Rand. 2024. https://doi.org/10.1093/pnasnexus/pgae111 Misinformation and harmful language are interconnected, rather than distinct, challenges . PNAS Nexus, 3(3):pgae111
-
[64]
Paul Mozur. 2018. https://www.nytimes.com/2018/10/15/technology/myanmar-facebook-genocide.html A genocide incited on Facebook , with posts from Myanmar 's military . The New York Times
2018
-
[65]
Sarah Myers West. 2018. https://doi.org/10.1177/1461444818773059 Censored, suspended, shadowbanned: User interpretations of content moderation on social media platforms . New Media & Society, 20(11):4366--4383
-
[66]
Gianluca Nogara, Francesco Pierri, Stefano Cresci, Luca Luceri, Petter T \"o rnberg, and Silvia Giordano. 2025. https://ojs.aaai.org/index.php/ICWSM/article/view/35876 Toxic bias: Perspective API misreads German as more toxic . In Proceedings of the 19th AAAI International Conference on Web and Social Media ( ICWSM '25) , pages 12--23, Copenhagen, Denmark...
2025
-
[67]
Bender, Emily Denton, and Alex Hanna
Amandalynne Paullada, Inioluwa Deborah Raji, Emily M. Bender, Emily Denton, and Alex Hanna. 2021. https://doi.org/10.1016/j.patter.2021.100336 Data and its (dis)contents: A survey of dataset development and use in machine learning research . Patterns, 2(11):100336
-
[68]
John Pavlopoulos, Nithum Thain, Lucas Dixon, and Ion Androutsopoulos. 2019. https://doi.org/10.18653/v1/S19-2102 C onv AI at S em E val-2019 task 6: Offensive language identification and categorization with perspective and BERT . In Proceedings of the 13th International Workshop on Semantic Evaluation, pages 571--576, Minneapolis, Minnesota, USA. Associat...
-
[69]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. https://doi.org/10.48550/arXiv.2202.03286 Red teaming language models with language models . arXiv preprint arXiv:2202.03286
- [70]
- [71]
-
[72]
doi:10.1073/pnas.2024292118 , author =
Steve Rathje, Jay J. Van Bavel, and Sander Van Der Linden. 2021. https://doi.org/10.1073/pnas.2024292118 Out-group animosity drives engagement on social media . Proceedings of the National Academy of Sciences, 118(26):e2024292118
-
[73]
Manoel Horta Ribeiro. 2024. https://doi.org/10.5075/EPFL-THESIS-10387 Content Moderation in Online Platforms . Ph.D. thesis, \'E cole Polytechnique F \'e d \'e rale de Lausanne
-
[74]
Bernhard Rieder and Yarden Skop. 2021. https://doi.org/10.1177/20539517211046181 The fabrics of machine moderation: Studying the technical, normative, and organizational structure of Perspective API . Big Data & Society, 8(2)
-
[75]
Paul R \"o ttger, Bertie Vidgen, Dong Nguyen, Zeerak Waseem, Helen Margetts, and Janet Pierrehumbert. 2021. https://doi.org/10.18653/v1/2021.acl-long.4 H ate C heck: Functional tests for hate speech detection models . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on N...
-
[76]
Nithya Sambasivan, Shivani Kapania, Hannah Highfill, Diana Akrong, Praveen Paritosh, and Lora M. Aroyo. 2021. https://doi.org/10.1145/3411764.3445518 ``everyone wants to do the model work, not the data work'': Data cascades in high-stakes AI . In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pages 1--15. ACM
-
[77]
Maarten Sap, Swabha Swayamdipta, Laura Vianna, Xuhui Zhou, Yejin Choi, and Noah A. Smith. 2022. https://doi.org/10.18653/v1/2022.naacl-main.431 Annotators with attitudes: How annotator beliefs and identities bias toxic language detection . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:...
-
[78]
Martin Saveski, Brandon Roy, and Deb Roy. 2021. The structure of toxic conversations on twitter. In Proceedings of the web conference 2021, pages 1086--1097
2021
-
[79]
Alexandra A Siegel. 2020. Online hate speech. Social media and democracy: The state of the field, prospects for reform, pages 56--88
2020
-
[80]
Susan Leigh Star. 1999. https://doi.org/10.1177/00027649921955326 The ethnography of infrastructure . American Behavioral Scientist, 43(3):377--391
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.