Recognition: unknown
PLMGH: What Matters in PLM-GNN Hybrids for Code Classification and Vulnerability Detection
Pith reviewed 2026-05-07 16:01 UTC · model grok-4.3
The pith
PLM choice affects hybrid performance more than GNN backbone for code classification and vulnerability detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across both code classification and vulnerability detection tasks, PLM-GNN hybrids consistently outperform GNN-only baselines and often improve ranking quality over frozen PLMs. On Devign, performance and robustness are more sensitive to the PLM feature source than to the GNN backbone. Larger PLMs are not necessarily better feature extractors in this pipeline, and the PLM choice has more impact than the GNN choice.
What carries the argument
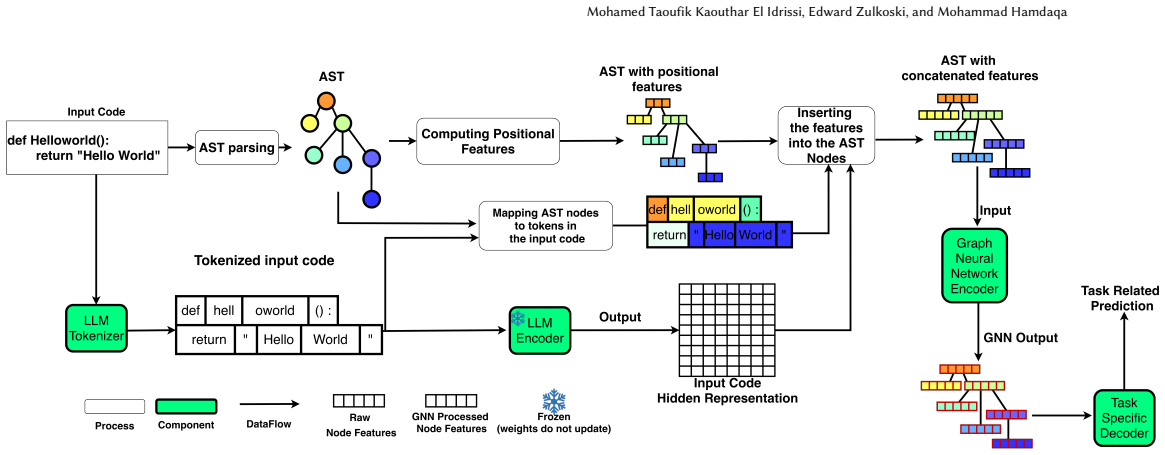
The controlled empirical pipeline that feeds PLM-derived embeddings as node features into a GNN for joint semantic and structural processing of code graphs.
If this is right
- Hybrids should be preferred over GNN-only models for code classification and vulnerability detection.
- Model builders should allocate more effort to selecting and testing PLMs than to selecting GNN backbones.
- Larger PLMs cannot be assumed to provide superior features for downstream GNN stages.
- The derived guidelines can be used to narrow design choices before full training runs.
Where Pith is reading between the lines
- Similar PLM-dominant sensitivity may appear in other code-graph tasks such as clone detection or bug localization.
- Repeating the study with fine-tuned rather than frozen PLMs could test whether the current ranking of feature quality persists after adaptation.
- The finding that size does not predict feature quality suggests efficiency gains by trying smaller PLMs first in hybrid pipelines.
Load-bearing premise
That the three chosen PLMs, three GNN architectures, and two datasets are representative enough to yield general design guidelines for PLM-GNN hybrids in code tasks.
What would settle it
A follow-up experiment on a third code dataset in which swapping the GNN backbone changes performance and robustness rankings more than swapping the PLM would falsify the claim that PLM source dominates.
Figures
read the original abstract
Code understanding models increasingly rely on pretrained language models (PLMs) and graph neural networks (GNNs), which capture complementary semantic and structural information. We conduct a controlled empirical study of PLM-GNN hybrids for code classification and vulnerability detection tasks by systematically pairing three code-specialized PLMs with three foundational GNN architectures. We compare these hybrids against PLM-only and GNN-only baselines on Java250 and Devign, including an identifier-obfuscation setting. Across both tasks, hybrids consistently outperform GNN-only baselines and often improve ranking quality over frozen PLMs. On Devign, performance and robustness are more sensitive to the PLM feature source than to the GNN backbone. We also find that larger PLMs are not necessarily better feature extractors in this pipeline, and that the PLM choice has more impact than the GNN choice. Finally, we distill these findings into practical guidelines for PLM-GNN design choices in code classification and vulnerability detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a controlled empirical study of PLM-GNN hybrid models for code classification (Java250) and vulnerability detection (Devign). It pairs three code-specialized PLMs with three GNN architectures, compares hybrids to PLM-only and GNN-only baselines (including identifier-obfuscated settings), and reports that hybrids consistently outperform GNN-only baselines, often improve over frozen PLMs, with greater sensitivity to PLM source than GNN backbone on Devign. Larger PLMs are not always better, PLM choice matters more than GNN, and these are distilled into practical guidelines for design choices.
Significance. If the empirical findings hold under rigorous controls, the work offers actionable insights for practitioners and researchers designing hybrid models for code understanding tasks. It highlights the complementary nature of PLM semantic features and GNN structural info, and provides evidence that design choices should prioritize PLM selection. The obfuscation experiments add value by testing robustness. However, the significance is tempered by the narrow scope of models and datasets, which may not support broad guidelines without further validation.
major comments (2)
- [Experimental Setup] The abstract reports consistent outperformance and sensitivity findings but provides no details on statistical tests, hyperparameter controls, or exact training protocols. Without these, the central empirical claims (e.g., hybrids outperforming baselines and PLM source mattering more than GNN backbone) cannot be verified or reproduced.
- [Results and Discussion] The practical guidelines distilled from the results rest on patterns observed with only three PLMs, three GNNs, and two datasets. The claim that performance and robustness are more sensitive to PLM feature source than GNN backbone (and that larger PLMs are not necessarily better) may be an artifact of the specific fusion mechanism and chosen models rather than a general principle; no ablations on additional architectures or datasets are described to test robustness.
minor comments (2)
- [Abstract] The abstract could explicitly name the three PLMs and three GNN architectures to allow readers to immediately assess the scope of the study.
- [Tables] Tables reporting performance metrics should include standard deviations across multiple runs or confidence intervals to substantiate claims of 'consistent' outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the acknowledgment of the value in our controlled experiments, the comparison to baselines, and the inclusion of identifier-obfuscation settings. We address each major comment below, indicating the revisions we will make to improve clarity, reproducibility, and appropriate qualification of our findings.
read point-by-point responses
-
Referee: [Experimental Setup] The abstract reports consistent outperformance and sensitivity findings but provides no details on statistical tests, hyperparameter controls, or exact training protocols. Without these, the central empirical claims (e.g., hybrids outperforming baselines and PLM source mattering more than GNN backbone) cannot be verified or reproduced.
Authors: We agree that the abstract would benefit from a concise summary of key experimental controls to support immediate verification of the claims. The full manuscript (Section 4) already specifies the training protocols, hyperparameter ranges, grid-search procedure, early-stopping criteria, and evaluation metrics, along with the use of paired t-tests (p < 0.05) for significance. To address the concern directly, we will revise the abstract to include a brief clause noting the consistent hyperparameter controls, statistical testing, and availability of reproducibility artifacts. This change will make the central claims more readily verifiable without altering the manuscript's length or focus. revision: yes
-
Referee: [Results and Discussion] The practical guidelines distilled from the results rest on patterns observed with only three PLMs, three GNNs, and two datasets. The claim that performance and robustness are more sensitive to PLM feature source than GNN backbone (and that larger PLMs are not necessarily better) may be an artifact of the specific fusion mechanism and chosen models rather than a general principle; no ablations on additional architectures or datasets are described to test robustness.
Authors: We acknowledge that the study scope is limited to the three PLMs, three GNN architectures, two datasets, and the chosen fusion mechanism, as already stated in the manuscript. The guidelines are presented as empirical observations from this controlled setting rather than universal principles. We will revise the Results and Discussion sections to more explicitly qualify the sensitivity findings and guidelines as specific to the examined configurations. We will also add a dedicated Limitations and Threats to Validity subsection that discusses the narrow model and dataset selection and recommends future validation on additional architectures and tasks. These textual revisions will better contextualize the claims while preserving the contribution of the systematic comparisons and obfuscation experiments. revision: yes
Circularity Check
Purely empirical study with no derivation chain or self-referential predictions
full rationale
The paper performs controlled experiments pairing three PLMs with three GNNs, evaluates hybrids vs. baselines on Java250 and Devign (including obfuscation), and summarizes observed patterns into guidelines. No equations, fitted parameters, uniqueness theorems, or ansatzes are present; claims rest on direct performance measurements rather than any reduction to inputs by construction. Self-citations, if any, are not load-bearing for a central premise. This matches the default non-circular case for empirical comparison papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang
- [2]
-
[3]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work. InProceedings of the 25th ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining
2019
-
[4]
Miltiadis Allamanis, Earl T Barr, Premkumar Devanbu, and Charles Sutton. 2018. A survey of machine learning for big code and naturalness.ACM Computing Surveys (CSUR)51, 4 (2018), 1–37
2018
- [5]
-
[6]
Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. 2018. Learning to Represent Programs with Graphs. InInternational Conference on Learning Representations. PLMGH: What Matters in PLM-GNN Hybrids for Code Classification and Vulnerability Detection
2018
-
[7]
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A neural probabilistic language model.Journal of machine learning research3, Feb (2003), 1137–1155
2003
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review arXiv 2021
- [9]
-
[10]
Vijay Prakash Dwivedi, Chaitanya K Joshi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. 2023. Benchmarking graph neural networks. Journal of Machine Learning Research24, 43 (2023), 1–48
2023
-
[11]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155 (2020)
work page internal anchor Pith review arXiv 2020
- [12]
-
[13]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366 (2020)
work page internal anchor Pith review arXiv 2020
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al . 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Abram Hindle, Earl T Barr, Mark Gabel, Zhendong Su, and Premkumar Devanbu
-
[16]
ACM59, 5 (2016), 122–131
On the naturalness of software.Commun. ACM59, 5 (2016), 122–131
2016
-
[17]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review arXiv 2024
-
[18]
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review arXiv 2016
-
[19]
Alexander LeClair, Sakib Haque, Lingfei Wu, and Collin McMillan. 2020. Im- proved code summarization via a graph neural network. InProceedings of the 28th international conference on program comprehension. 184–195
2020
-
[20]
Ruitong Liu, Yanbin Wang, Haitao Xu, Jianguo Sun, Fan Zhang, Peiyue Li, and Zhenhao Guo. 2025. Vul-LMGNNs: Fusing language models and online-distilled graph neural networks for code vulnerability detection.Information Fusion115 (2025), 102748
2025
-
[21]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review arXiv 2024
-
[22]
Van-Anh Nguyen, Dai Quoc Nguyen, Van Nguyen, Trung Le, Quan Hung Tran, and Dinh Phung. 2022. Regvd: Revisiting graph neural networks for vulnerabil- ity detection. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 178–182
2022
-
[23]
José Carlos Paiva, José Paulo Leal, and Álvaro Figueira. 2024. Comparing se- mantic graph representations of source code: the case of automatic feedback on programming assignments.Computer Science and Information Systems21, 1 (2024), 117–142
2024
-
[24]
Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al
- [25]
-
[26]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review arXiv 2023
- [27]
-
[28]
Ze Tang, Xiaoyu Shen, Chuanyi Li, Jidong Ge, Liguo Huang, Zhelin Zhu, and Bin Luo. 2022. Ast-trans: Code summarization with efficient tree-structured attention. InProceedings of the 44th International Conference on Software Engineering. 150– 162
2022
-
[29]
Hoai-Chau Tran, Anh-Duy Tran, and Kim-Hung Le. 2025. DetectVul: A statement- level code vulnerability detection for Python.Future Generation Computer Sys- tems163 (2025), 107504. doi:10.1016/j.future.2024.107504
-
[30]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[31]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review arXiv 2017
- [32]
- [33]
- [34]
- [35]
- [36]
-
[37]
Kechi Zhang, Zhuo Li, Zhi Jin, and Ge Li. 2023. Implant global and local hierarchy information to sequence based code representation models. In2023 IEEE/ACM 31st International Conference on Program Comprehension (ICPC). IEEE, 157–168
2023
-
[38]
Kechi Zhang, Wenhan Wang, Huangzhao Zhang, Ge Li, and Zhi Jin. 2022. Learn- ing to represent programs with heterogeneous graphs. InProceedings of the 30th IEEE/ACM international conference on program comprehension. 378–389
2022
-
[39]
Yuguo Zhang, Jia Yang, and Ou Ruan. 2024. Cross-language source code clone de- tection based on graph neural network. InProceedings of the 2024 3rd International Conference on Cryptography, Network Security and Communication Technology. 189–194
2024
-
[40]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing systems32 (2019)
2019
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.