Recognition: unknown
Beyond Isolated Utterances: Cue-Guided Interaction for Context-Dependent Conversational Multimodal Understanding
Pith reviewed 2026-05-07 13:39 UTC · model grok-4.3
The pith
CUCI-Net abstracts the dependency between dialogue context and current utterance into an interpretation cue that conditions the final multimodal prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CUCI-Net fully preserves the structural distinction between context and utterance during encoding, effectively abstracts their dependency into an interpretation cue by combining local modality evidence with global contextual evidence, and seamlessly integrates the resulting cue into the final multimodal interaction stage for context-conditioned prediction.
What carries the argument
The interpretation cue, formed by combining local modality evidence with global contextual evidence to represent the context-utterance dependency for guiding later predictions.
If this is right
- The method maintains separation of context and utterance to avoid premature mixing of information.
- Deriving a single cue allows focused integration of dependency information at the prediction stage.
- Experiments on benchmark datasets confirm gains in context-conditioned multimodal understanding.
- Context-conditioned predictions become possible without full propagation of context throughout the model.
Where Pith is reading between the lines
- This cue-based abstraction could be adapted for other tasks involving sequential multimodal data with dependencies.
- Future models might benefit from using multiple or hierarchical cues for more complex dialogues.
- The late-stage integration suggests potential efficiency gains by avoiding constant context awareness in early layers.
Load-bearing premise
That the context-utterance dependency can be fully captured by one interpretation cue combined from local and global evidence and added only during the final interaction stage, without losing essential details or creating biases.
What would settle it
Observing whether CUCI-Net achieves higher performance metrics than previous methods on the mainstream benchmark datasets for conversational multimodal understanding would test the claim; failure to do so would indicate the cue does not provide the expected benefit.
Figures



read the original abstract
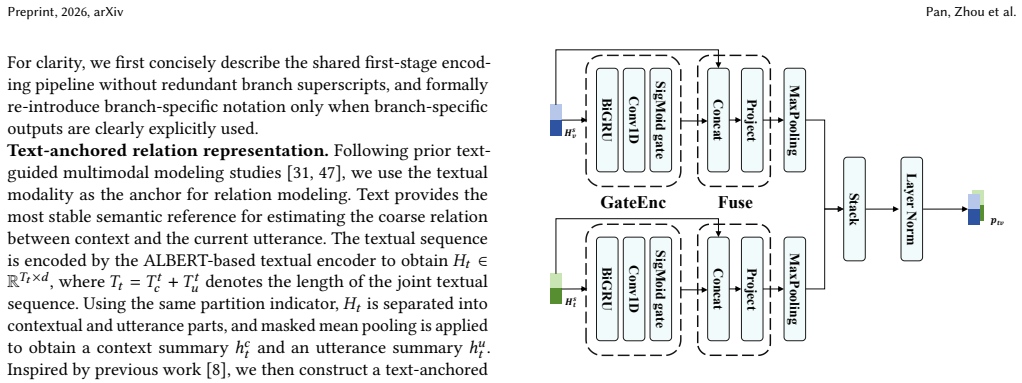
Conversational multimodal understanding aims to infer the meaning or label of the current utterance from its preceding dialogue context together with textual, acoustic, and visual signals. Existing methods mainly strengthen contextual modeling through enhanced encoding, fusion, or propagation, but rarely abstract the context-utterance dependency into an explicit cue and incorporate it into later multimodal reasoning. To address this issue, we propose CUCI-Net for conversational multimodal understanding. CUCI-Net fully preserves the structural distinction between context and utterance during encoding, effectively abstracts their dependency into an interpretation cue by combining local modality evidence with global contextual evidence, and seamlessly integrates the resulting cue into the final multimodal interaction stage for context-conditioned prediction. Extensive experiments on mainstream benchmark datasets fully demonstrate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CUCI-Net for conversational multimodal understanding. The model preserves the structural distinction between context and utterance during encoding, abstracts their dependency into an explicit interpretation cue by combining local modality evidence with global contextual evidence, and integrates the cue into the final multimodal interaction stage to enable context-conditioned prediction. Effectiveness is asserted via extensive experiments on mainstream benchmark datasets.
Significance. If the experimental claims hold, the work offers a structured alternative to existing context-modeling techniques (enhanced encoding, fusion, or propagation) by making the context-utterance dependency explicit as a cue. This could reduce information loss in multimodal dialogue systems and improve context-sensitive predictions across text, acoustic, and visual modalities.
major comments (2)
- Abstract: the central claim that the method 'fully demonstrate[s] the effectiveness' rests on an assertion of improvement over baselines, yet the manuscript provides no quantitative results, ablation studies, error bars, dataset statistics, or performance tables. Without these, the load-bearing experimental validation cannot be assessed.
- Method description (inferred from abstract and architecture claims): the process of forming the interpretation cue from local modality evidence and global contextual evidence, and its seamless integration at the final stage, is described at a high level without equations, pseudocode, or architectural diagrams that would allow verification of information preservation or bias introduction.
minor comments (2)
- The abstract is overly promotional ('fully demonstrate'); a more measured statement of contributions would improve clarity.
- No discussion of computational overhead or scalability of the cue-generation and integration steps is provided, which would be useful for practical deployment.
Simulated Author's Rebuttal
Dear Editor, We thank the referee for the constructive and detailed review of our manuscript. The comments identify key areas where the presentation of experimental validation and methodological specifics can be strengthened to better support the claims. We respond to each major comment below and commit to revisions that address the concerns without altering the core contributions.
read point-by-point responses
-
Referee: Abstract: the central claim that the method 'fully demonstrate[s] the effectiveness' rests on an assertion of improvement over baselines, yet the manuscript provides no quantitative results, ablation studies, error bars, dataset statistics, or performance tables. Without these, the load-bearing experimental validation cannot be assessed.
Authors: We appreciate the referee highlighting this issue. The abstract is intended as a high-level summary, but the full manuscript includes a dedicated Experiments section with quantitative results on mainstream benchmarks (e.g., performance tables comparing CUCI-Net to baselines, ablation studies on the interpretation cue components, dataset statistics, and figures incorporating error bars and statistical significance tests). To ensure the validation is immediately assessable, we will revise the abstract to include a concise summary of key quantitative improvements and add explicit cross-references to the tables and figures in the revised version. revision: yes
-
Referee: Method description (inferred from abstract and architecture claims): the process of forming the interpretation cue from local modality evidence and global contextual evidence, and its seamless integration at the final stage, is described at a high level without equations, pseudocode, or architectural diagrams that would allow verification of information preservation or bias introduction.
Authors: We acknowledge that the current description of the interpretation cue formation and integration is presented at a conceptual level. To enable rigorous verification, the revised manuscript will include: (1) mathematical equations defining the cue as a combination of local modality features and global context representations, (2) pseudocode outlining the step-by-step process, and (3) a detailed architectural diagram showing the encoding, cue abstraction, and multimodal interaction stages. These additions will clarify how the structural distinction is preserved and how context conditioning is achieved without introducing bias. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces CUCI-Net as a novel architecture that preserves context-utterance structural distinction during encoding, forms an interpretation cue from local and global evidence, and injects the cue at the final multimodal stage. No mathematical derivations, equations, fitted parameters, or predictions are described that reduce by construction to the inputs or to self-referential definitions. The central claims rest on the architectural design choices and external experimental validation on benchmark datasets rather than any load-bearing self-citation chain or ansatz smuggled via prior work. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wei Ai, Fuchen Zhang, Yuntao Shou, Tao Meng, Haowen Chen, and Keqin Li. 2025. Revisiting Multimodal Emotion Recognition in Conversation from the Perspective of Graph Spectrum. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 11418–11426. doi:10.1609/AAAI.V39I11.33242
-
[2]
Khalid Alnajjar, Mika Hämäläinen, Jörg Tiedemann, Jorma Laaksonen, and Mikko Kurimo. 2022. When to Laugh and How Hard? A Multimodal Ap- proach to Detecting Humor and Its Intensity. InProceedings of the 29th In- ternational Conference on Computational Linguistics. International Commit- tee on Computational Linguistics, Gyeongju, Republic of Korea, 6875–688...
2022
-
[3]
Elaheh Baharlouei, Mahsa Shafaei, Yigeng Zhang, Hugo Jair Escalante, and Thamar Solorio. 2024. Labeling Comic Mischief Content in Online Videos with a Multimodal Hierarchical-Cross-Attention Model. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL, Tor...
2024
-
[4]
Tadas Baltrušaitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency
-
[5]
In2018 13th IEEE Inter- national Conference on Automatic Face & Gesture Recognition (FG 2018)
OpenFace 2.0: Facial Behavior Analysis Toolkit. In2018 13th IEEE Inter- national Conference on Automatic Face & Gesture Recognition (FG 2018). 59–66. doi:10.1109/FG.2018.00019
-
[6]
Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmer- mann, Rada Mihalcea, and Soujanya Poria. 2019. Towards Multimodal Sarcasm Detection (An Obviously Perfect Paper). InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 4619–4629. doi:10.1...
-
[7]
Dushyant Singh Chauhan, Dhanush S R, Asif Ekbal, and Pushpak Bhattacharyya
-
[8]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp
Sentiment and Emotion help Sarcasm? A Multi-task Learning Framework for Multi-Modal Sarcasm, Sentiment and Emotion Analysis. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 4351–4360. doi:10.18653/v1/2020.acl-main.401
-
[9]
Dushyant Singh Chauhan, Gopendra Vikram Singh, Aseem Arora, Asif Ekbal, and Pushpak Bhattacharyya. 2022. A Sentiment and Emotion Aware Multi- modal Multiparty Humor Recognition in Multilingual Conversational Setting. InProceedings of the 29th International Conference on Computational Linguistics. International Committee on Computational Linguistics, Gyeon...
2022
-
[10]
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loic Barrault, and Antoine Bordes. 2017. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. InProceedings of the 2017 Conference on Empir- ical Methods in Natural Language Processing. 670–680. doi:10.18653/v1/D17-1070
-
[11]
Gilles Degottex, John Kane, Thomas Drugman, Tuomo Raitio, and Stefan Scherer
-
[12]
InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing
COVAREP: A Collaborative Voice Analysis Repository for Speech Tech- nologies. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. 960–964. doi:10.1109/ICASSP.2014.6853739
-
[13]
Junlin Fang, Wenya Wang, Guosheng Lin, and Fengmao Lv. 2024. Sentiment- oriented Sarcasm Integration for Video Sentiment Analysis Enhancement with Sarcasm Assistance. InProceedings of the 32nd ACM International Conference on Multimedia (MM ’24). ACM, Melbourne, VIC, Australia, 5810–5819. doi:10.1145/ 3664647.3680703
-
[14]
Deepanway Ghosal, Navonil Majumder, Alexander Gelbukh, Rada Mihalcea, and Soujanya Poria. 2020. COSMIC: COmmonSense knowledge for eMotion Preprint, 2026, arXiv Pan, Zhou et al. Identification in Conversations. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, Online, 2470–2481. doi:10.18653...
-
[15]
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, and Alexander Gelbukh. 2019. DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-...
-
[16]
Hongyu Guo, Wenbo Shang, Xueyao Zhang, Shubo Zhang, Xu Han, and Binyang Li. 2024. MUCH: A Multimodal Corpus Construction for Conversational Humor Recognition Based on Chinese Sitcom. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL, Torino, Italia, 11...
2024
-
[17]
Md Kamrul Hasan, Sangwu Lee, Wasifur Rahman, AmirAli Bagher Zadeh, Rada Mihalcea, Louis-Philippe Morency, and Enamul Hoque. 2021. Humor Knowledge Enriched Transformer for Understanding Multimodal Humor. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12972–12980. doi:10.1609/ aaai.v35i14.17534
2021
-
[18]
Md Kamrul Hasan, Wasifur Rahman, AmirAli Bagher Zadeh, Jianyuan Zhong, Md Iftekhar Tanveer, Louis-Philippe Morency, and Mohammed (Ehsan) Hoque
-
[19]
UR-FUNNY: A Multimodal Language Dataset for Understanding Humor. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 2046–2056. doi:10.18653/v1/D19-1211
-
[20]
Devamanyu Hazarika, Soujanya Poria, Rada Mihalcea, Erik Cambria, and Roger Zimmermann. 2018. ICON: Interactive Conversational Memory Network for Multimodal Emotion Detection. InProceedings of the 2018 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, 2594–2604. doi:10.18653/v1/D18-1280
-
[21]
Devamanyu Hazarika, Soujanya Poria, Amir Zadeh, Erik Cambria, Louis-Philippe Morency, and Roger Zimmermann. 2018. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long P...
2018
-
[22]
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. 2020. MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Anal- ysis. InProceedings of the 28th ACM International Conference on Multimedia. ACM, 1122–1131. doi:10.1145/3394171.3413678
-
[23]
Simin Hong, Jun Sun, and Taihao Li. 2024. DetectiveNN: Imitating Human Emo- tional Reasoning with a Recall-Detect-Predict Framework for Emotion Recogni- tion in Conversations. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, Florida, USA, 9170–9180. doi:10.18653/v1/2024.findings-emnlp.536
-
[24]
Sayed Muddashir Hossain, Jan Alexandersson, and Philipp Müller. 2024. M3TCM: Multi-modal Multi-task Context Model for Utterance Classification in Motiva- tional Interviews. InProceedings of the 2024 Joint International Conference on Com- putational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL, Torino, Italia, 10872–1087...
2024
-
[25]
Dou Hu, Lingwei Wei, and Xiaoyong Huai. 2021. DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Lingui...
-
[26]
Guimin Hu, Ting-En Lin, Yi Zhao, Guangming Lu, Yuchuan Wu, and Yongbin Li
-
[27]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 7837–7851. doi:10.18653/v1/2022.emnlp-main.534
-
[28]
Jingwen Hu, Yuchen Liu, Jinming Zhao, and Qin Jin. 2021. MMGCN: Multi- modal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Associa...
-
[29]
Soumyadeep Jana, Animesh Dey, and Ranbir Singh Sanasam. 2024. Continuous Attentive Multimodal Prompt Tuning for Few-Shot Multimodal Sarcasm Detec- tion. InProceedings of the 28th Conference on Computational Natural Language Learning. Association for Computational Linguistics, Miami, FL, USA, 314–326. doi:10.18653/v1/2024.conll-1.25
-
[31]
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. InInternational Conference on Learning Representations
2020
-
[32]
Dongyuan Li, Yusong Wang, Kotaro Funakoshi, and Manabu Okumura. 2023. Joyful: Joint Modality Fusion and Graph Contrastive Learning for Multimodal Emotion Recognition. InProceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics, Singapore, 16051–16069. doi:10.18653/v1/2023.emnlp-main.996
-
[33]
Kuntao Li, Yifan Chen, Qiaofeng Wu, Weixing Mai, Fenghuan Li, and Yun Xue
-
[34]
InProceedings of the 31st International Conference on Compu- tational Linguistics
Ambiguity-aware Multi-level Incongruity Fusion Network for Multi-Modal Sarcasm Detection. InProceedings of the 31st International Conference on Compu- tational Linguistics. Association for Computational Linguistics, Abu Dhabi, UAE, 380–391. https://aclanthology.org/2025.coling-main.26/
2025
-
[35]
Yong Li, Yuanzhi Wang, and Zhen Cui. 2023. Decoupled Multi- modal Distilling for Emotion Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6631–
2023
-
[36]
https://openaccess.thecvf.com/content/CVPR2023/html/Li_Decoupled_ Multimodal_Distilling_for_Emotion_Recognition_CVPR_2023_paper.html
-
[37]
Yong Li, Yuanzhi Wang, and Zhen Cui. 2023. Decoupled Multimodal Distilling for Emotion Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6631–6640
2023
-
[38]
Zuocheng Li and Lishuang Li. 2025. t-HNE: A Text-guided Hierarchical Noise Eliminator for Multimodal Sentiment Analysis. InProceedings of the 31st Interna- tional Conference on Computational Linguistics. Association for Computational Linguistics, Abu Dhabi, UAE, 2834–2844. https://aclanthology.org/2025.coling- main.192/
2025
-
[39]
Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. 2018. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Associa- tion for Computational Linguistics, 2247–2256....
-
[40]
Sijie Mai, Ya Sun, Ying Zeng, and Haifeng Hu. 2023. Excavating Multimodal Correlation for Representation Learning.Information Fusion91 (2023), 542–555. doi:10.1016/j.inffus.2022.11.003
-
[41]
Sijie Mai, Ying Zeng, and Haifeng Hu. 2023. Learning from the Global View: Supervised Contrastive Learning of Multimodal Representation.Information Fusion100 (2023), 101920. doi:10.1016/j.inffus.2023.101920
-
[42]
Gelbukh, and Erik Cambria
Navonil Majumder, Soujanya Poria, Devamanyu Hazarika, Rada Mihalcea, Alexander F. Gelbukh, and Erik Cambria. 2019. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. InProceedings of the AAAI Confer- ence on Artificial Intelligence, Vol. 33. 6818–6825. https://ojs.aaai.org/index.php/ AAAI/article/view/4657
2019
-
[43]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2019. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 527–536. doi:10.186...
-
[44]
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. 2020. Integrating Multimodal Information in Large Pretrained Transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2359–2369. doi:10.18653/v...
-
[45]
Anupama Ray, Shubham Mishra, Apoorva Nunna, and Pushpak Bhattacharyya
-
[46]
A Multimodal Corpus for Emotion Recognition in Sarcasm. InProceedings of the Thirteenth Language Resources and Evaluation Conference, Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Jan Odijk, and Stelios Piperidis (Eds.). ...
2022
-
[47]
Tao Shi and Shao-Lun Huang. 2023. MultiEMO: An Attention-Based Correlation- Aware Multimodal Fusion Framework for Emotion Recognition in Conversations. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 14752–14766. doi:10.18653/v1/2...
-
[48]
Yuntao Shou, Tao Meng, Wei Ai, and Keqin Li. 2025. Dynamic Graph Neural ODE Network for Multi-modal Emotion Recognition in Conversation. InProceedings of the 31st International Conference on Computational Linguistics. Association for Computational Linguistics, Abu Dhabi, UAE, 256–268. https://aclanthology.org/ 2025.coling-main.18/ Beyond Isolated Utteranc...
2025
-
[49]
Chuanqi Tao, Jiaming Li, Tianzi Zang, and Peng Gao. 2025. A Multi-Focus- Driven Multi-Branch Network for Robust Multimodal Sentiment Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 1547–1555. doi:10.1609/aaai.v39i2.32146
-
[50]
Divyank Tiwari, Diptesh Kanojia, Anupama Ray, Apoorva Nunna, and Pushpak Bhattacharyya. 2023. Predict and Use: Harnessing Predicted Gaze to Improve Multimodal Sarcasm Detection. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 15933–15948. doi:10.18653/v1/2023...
-
[52]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal Transformer for Unaligned Multimodal Language Sequences. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 6558–6569. doi:1...
-
[53]
Geng Tu, Bin Liang, Ruibin Mao, Min Yang, and Ruifeng Xu. 2023. Context or Knowledge is Not Always Necessary: A Contrastive Learning Framework for Emotion Recognition in Conversations. InFindings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 14054–14067. doi:10.18653/v1/2023.finding...
-
[54]
Geng Tu, Jun Wang, Zhenyu Li, Shiwei Chen, Bin Liang, Xi Zeng, Min Yang, and Ruifeng Xu. 2024. Multiple Knowledge-Enhanced Interactive Graph Net- work for Multimodal Conversational Emotion Recognition. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computa- tional Linguistics, Miami, Florida, USA, 3861–3874. doi:1...
-
[55]
Di Wang, Xutong Guo, Yumin Tian, Jinhui Liu, Lihuo He, and Xuemei Luo. 2023. TETFN: A Text Enhanced Transformer Fusion Network for Multimodal Sentiment Analysis.Pattern Recognition136 (2023), 109259. doi:10.1016/j.patcog.2022.109259
-
[56]
Pan Wang, Qiang Zhou, Yawen Wu, Tianlong Chen, and Jingtong Hu. 2025. DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 21180–21188. doi:10. 1609/aaai.v39i20.35416
2025
-
[57]
Yiwei Wei, Maomao Duan, Hengyang Zhou, Zhiyang Jia, Zengwei Gao, and Longbiao Wang. 2024. Towards multimodal sarcasm detection via label-aware graph contrastive learning with back-translation augmentation.Knowledge-Based Systems300 (2024), 112109
2024
-
[58]
Yiwei Wei, Shaozu Yuan, Hengyang Zhou, Longbiao Wang, Zhiling Yan, Ruosong Yang, and Meng Chen. 2024. Gˆ 2SAM: Graph-Based Global Semantic Awareness Method for Multimodal Sarcasm Detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 9151–9159
2024
-
[59]
Yiwei Wei, Hengyang Zhou, Shaozu Yuan, Meng Chen, Haitao Shi, Zhiyang Jia, Longbiao Wang, and Xiaodong He. 2025. DeepMSD: Advancing Multimodal Sarcasm Detection through Knowledge-augmented Graph Reasoning.IEEE Transactions on Circuits and Systems for Video Technology(2025)
2025
-
[60]
Yunhe Xie, Chengjie Sun, Ziyi Cao, Bingquan Liu, Zhenzhou Ji, Yuanchao Liu, and Lili Shan. 2025. A Dual Contrastive Learning Framework for Enhanced Multimodal Conversational Emotion Recognition. InProceedings of the 31st Inter- national Conference on Computational Linguistics. Association for Computational Linguistics, Abu Dhabi, UAE, 4055–4065. https://a...
2025
-
[61]
Qinfu Xu, Yiwei Wei, Chunlei Wu, Leiquan Wang, Shaozu Yuan, Jie Wu, Jing Lu, and Hengyang Zhou. 2025. Towards Multimodal Sentiment Analysis via Hierarchical Correlation Modeling with Semantic Distribution Constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 21788–21796
2025
-
[62]
Hongfei Xue, Linyan Xu, Yu Tong, Rui Li, Jiali Lin, and Dazhi Jiang. 2024. Break- through from Nuance and Inconsistency: Enhancing Multimodal Sarcasm Detec- tion with Context-Aware Self-Attention Fusion and Word Weight Calculation.. In Proceedings of the 2024 Joint International Conference on Computational Linguis- tics, Language Resources and Evaluation ...
2024
-
[63]
Shaozu Yuan, Yiwei Wei, Hengyang Zhou, Qinfu Xu, Meng Chen, and Xiaodong He. 2025. Enhancing Semantic Awareness by Sentimental Constraint with Auto- matic Outlier Masking for Multimodal Sarcasm Detection.IEEE Transactions on Multimedia(2025)
2025
-
[64]
Taeyang Yun, Hyunkuk Lim, Jeonghwan Lee, and Min Song. 2024. TelME: Teacher-leading Multimodal Fusion Network for Emotion Recognition in Con- versation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Ling...
-
[65]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 1103–1114. doi:10.18653/ v1/D17-1115
2017
-
[66]
Duzhen Zhang, Feilong Chen, and Xiuyi Chen. 2023. DualGATs: Dual Graph Attention Networks for Emotion Recognition in Conversations. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 7395–7408. doi:10.18653/v1/2023.acl-long.408
-
[67]
Tao Zhang and Zhenhua Tan. 2025. ECERC: Evidence-Cause Attention Network for Multi-Modal Emotion Recognition in Conversation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 2064–2077. doi:10.18653/v1/2025.acl-long.102
-
[68]
Xiaoheng Zhang and Yang Li. 2023. A Cross-Modality Context Fusion and Seman- tic Refinement Network for Emotion Recognition in Conversation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 13099–13110. doi:10.18653/v1/2023.acl-long.732
-
[69]
Wenjie Zheng, Jianfei Yu, Rui Xia, and Shijin Wang. 2023. A Facial Expression- Aware Multimodal Multi-task Learning Framework for Emotion Recognition in Multi-party Conversations. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 15...
-
[70]
Peixiang Zhong, Di Wang, and Chunyan Miao. 2019. Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP). Association for Computational Linguistics, Hong K...
- [71]
-
[72]
Hengyang Zhou, Jinwu Yan, Yaqing Chen, Rongman Hong, Wenbo Zuo, and Keyan Jin. 2025. LDGNet: LLMs Debate-Guided Network for Multimodal Sarcasm Detection. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[73]
Weilin Zhou, Zonghao Ying, Chunlei Meng, Jiahui Liu, Hengyang Zhou, Quanchen Zou, Deyue Zhang, Dongdong Yang, and Xiangzheng Zhang. 2026. DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection. arXiv:2601.07178 [cs.CV] https://arxiv.org/abs/2601.07178
-
[74]
Lixing Zhu, Gabriele Pergola, Lin Gui, Deyu Zhou, and Yulan He. 2021. Topic- Driven and Knowledge-Aware Transformer for Dialogue Emotion Detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Lin- guistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for ...
2021
-
[75]
doi:10.18653/v1/2021.acl-long.125
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.