Recognition: unknown
Local tensor-train surrogates for quantum learning models
Pith reviewed 2026-05-07 16:54 UTC · model grok-4.3
The pith
Local patches of quantum machine learning models admit fast classical tensor-train surrogates with explicit error bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Taylor-TT construction serves as a deterministic error certificate proving that the TT hypothesis class contains a good approximation to the quantum model inside a local patch; empirical risk minimization then provably recovers a surrogate with controlled generalization error and explicit bounds on the risk. This yields three independently controllable error sources from Taylor truncation controlled by patch radius r and degree p, TT approximation controlled by bond dimension chi, and statistical estimation. Parameter count scales as N(p+1)chi squared rather than exponentially in N, cleanly separating representation complexity from the exponential constants induced by the tensor-product
What carries the argument
The Taylor-TT construction, which embeds a local Taylor polynomial approximation of the quantum model into a low-bond-dimension tensor-train representation for use as a hypothesis class in empirical risk minimization.
Load-bearing premise
The quantum model function is sufficiently smooth inside each local patch for a low-degree Taylor polynomial plus low-bond-dimension tensor-train to achieve useful accuracy, with the feature map permitting manageable tensor-product norms.
What would settle it
Collecting data inside a chosen local patch and training the TT surrogate; if the observed test error inside the patch does not decrease when the polynomial degree p or bond dimension chi is increased while keeping other parameters fixed, the error control claims would be falsified.
Figures


read the original abstract
A key bottleneck in quantum machine learning is the computational cost of repeated quantum circuit evaluations during the inference phase. To address this, we present a framework for constructing fast, cheap, provably accurate classical tensor-train surrogates of fully trained quantum machine learning models within local patches of their input data space. The approach combines Taylor polynomial approximation with a tensor-train (TT) representation and embeds it in a statistical learning paradigm via empirical risk minimization. In our analysis, the Taylor-TT construction serves as a deterministic error certificate proving that the TT hypothesis class contains a good approximation; empirical risk minimization then provably recovers a surrogate with controlled generalization error and explicit bounds. This translates into three independently controllable error sources: (i) Taylor truncation error controlled by the patch radius $r$ and polynomial degree $p$, (ii) TT approximation error controlled by the bond dimension $\chi$, and (iii) statistical estimation error. While the parameter count scales polynomially in the number of data dimensions $N$, i.e., $d_{\mathrm{eff}} = N(p+1)\chi^2$ rather than the naive $(p+1)^N$, the worst-case constants inherit an exponential factor through the tensor-product feature norm during Taylor polynomial embedding onto TT. This cleanly separates representation complexity from feature-induced constants. Our risk bounds and sample complexity depend explicitly on the local patch radius $r$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes constructing fast classical tensor-train (TT) surrogates for fully trained quantum machine learning models inside local patches of the input domain. It combines a Taylor polynomial expansion (controlled by patch radius r and degree p) with a low-bond-dimension TT representation (controlled by bond dimension χ) and embeds the construction in an empirical risk minimization (ERM) framework. The central claim is that the Taylor-TT approximant supplies a deterministic certificate that the TT hypothesis class contains a sufficiently accurate surrogate; standard uniform-convergence arguments then yield explicit generalization bounds whose three error terms (Taylor truncation, TT truncation, and statistical) are independently controllable. The effective parameter count scales as d_eff = N(p+1)χ² rather than exponentially in N, while the worst-case constants inherit an exponential factor from the tensor-product feature norm.
Significance. If the derivations and assumptions hold, the work supplies a concrete route to replace repeated quantum-circuit evaluations with cheap classical surrogates that come with explicit, tunable error certificates. The clean separation of representation complexity from feature-induced constants and the explicit dependence of sample complexity on the local radius r are useful features for practical QML deployment. The reliance on standard results from approximation theory and statistical learning theory keeps the argument modular and falsifiable.
major comments (2)
- [§3.2] §3.2, the statement that the TT approximation error is controlled solely by χ: the proof sketch must explicitly bound the TT truncation error for the multivariate Taylor polynomial under the tensor-product norm; without this quantitative link the claim that the three error sources are independently controllable is not yet load-bearing.
- [Theorem 4.1] Theorem 4.1 (generalization bound): the exponential factor arising from the tensor-product feature norm appears in the final sample-complexity expression; the manuscript should state whether this factor can be absorbed into the choice of r or whether it remains an unavoidable dependence on the feature map.
minor comments (2)
- [§2.1] The notation for the local patch radius r is introduced in the abstract but first defined only in §2.1; a forward reference or early definition would improve readability.
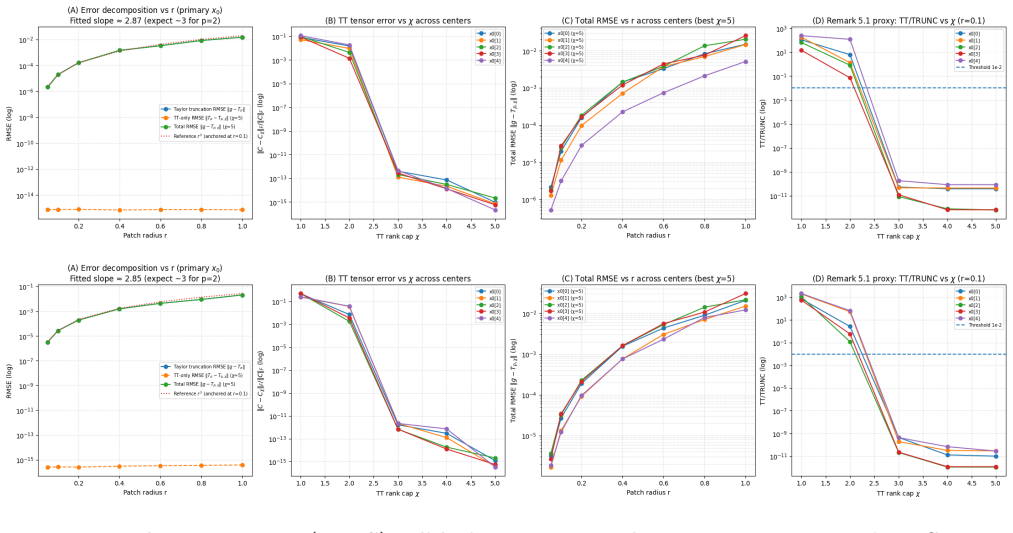
- [Figure 1] Figure 1 caption should clarify whether the plotted error curves are theoretical bounds or numerical realizations of the Taylor-TT surrogate.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the constructive comments. We appreciate the positive assessment of the overall approach and have revised the paper to address the points raised, strengthening the rigor of the error analysis and clarifying the dependence on the feature map.
read point-by-point responses
-
Referee: [§3.2] §3.2, the statement that the TT approximation error is controlled solely by χ: the proof sketch must explicitly bound the TT truncation error for the multivariate Taylor polynomial under the tensor-product norm; without this quantitative link the claim that the three error sources are independently controllable is not yet load-bearing.
Authors: We agree that an explicit quantitative link is required to fully substantiate the independent controllability of the three error terms. In the revised §3.2 we have augmented the proof sketch with a direct bound on the TT truncation error for the multivariate Taylor polynomial. The Taylor polynomial is first embedded into the tensor-product feature space; each monomial term admits an exact rank-1 TT representation, after which standard TT truncation results (e.g., via successive SVDs) yield an error controlled by χ, the polynomial degree p, and the tensor-product norm of the feature map. This bound depends only on representation parameters (χ, p) and the fixed feature norm, remaining independent of the statistical sample size. The revised text now states the three error sources explicitly and shows how each can be tuned separately. revision: yes
-
Referee: [Theorem 4.1] Theorem 4.1 (generalization bound): the exponential factor arising from the tensor-product feature norm appears in the final sample-complexity expression; the manuscript should state whether this factor can be absorbed into the choice of r or whether it remains an unavoidable dependence on the feature map.
Authors: The exponential factor arises from the tensor-product structure of the feature map norm evaluated inside the local patch; it scales as O(C^N) for a constant C determined by the feature map and the ambient input domain. While a smaller patch radius r reduces the Taylor truncation error (by suppressing higher-order remainder terms), it does not cancel or absorb the feature-norm prefactor, which is independent of r and stems directly from the product structure of the embedding. Consequently the factor remains an unavoidable dependence on the choice of feature map. We have added a clarifying remark immediately after the statement of Theorem 4.1 that makes this dependence explicit and notes that, for many physically motivated feature maps, the constant C can be moderate or further controlled by normalization. revision: yes
Circularity Check
No significant circularity; derivation is self-contained against external benchmarks
full rationale
The paper's central argument constructs a Taylor-TT surrogate as an existence certificate drawn from classical multivariate approximation theory (Taylor expansion with remainder controlled by patch radius r and degree p) and then invokes standard uniform convergence results from statistical learning theory to bound the generalization error of ERM over the TT hypothesis class. The effective dimension d_eff = N(p+1)χ² is derived directly from the TT parameterization without fitting to the target data, and the three error sources (truncation, TT compression, statistical) are controlled by independent parameters whose bounds do not reduce to any quantity defined by the same empirical risk minimization step. No self-citation is load-bearing for the existence or bound statements, and the tensor-product norm exponential factor is acknowledged as a worst-case constant inherited from the feature map rather than a fitted or redefined quantity. The derivation therefore remains independent of the quantum model specifics beyond the smoothness assumption inside each local patch.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Taylor's theorem applies to the quantum model function inside each local patch of radius r
- domain assumption A tensor-train decomposition of controlled bond dimension can approximate the embedded Taylor polynomial to arbitrary accuracy
Reference graph
Works this paper leans on
- [1]
-
[2]
Pradeep Lamichhane and Danda B. Rawat. Quantum machine learning: Recent advances, challenges, and perspectives.IEEE Access, 13:94057–94105, 2025.doi:10.1109/ACCESS.2025.3573244
-
[3]
Giovanni Acampora, Andris Ambainis, Natalia Ares, Leonardo Banchi, Pallavi Bhardwaj, Daniele Binosi, G. Andrew D. Briggs, Tommaso Calarco, Vedran Dunjko, Jens Eisert, Olivier Ezratty, Paul Erker, Federico Fedele, Elies Gil-Fuster, Martin G¨ arttner, Mats Granath, Markus Heyl, Iordanis Kerenidis, Matthias Klusch, Anton Frisk Kockum, Richard Kueng, Mario Kr...
-
[4]
A survey of quantum learning theory, 2017
Srinivasan Arunachalam and Ronald de Wolf. A survey of quantum learning theory, 2017. URL: https://arxiv.org/abs/1701.06806,arXiv:1701.06806
-
[5]
The theory of variational hybrid quantum-classical algorithms.New Journal of Physics, 18(2):023023, February
Jarrod R McClean, Jonathan Romero, Ryan Babbush, and Al´ an Aspuru-Guzik. The theory of variational hybrid quantum-classical algorithms.New Journal of Physics, 18(2):023023, February
-
[6]
URL:http://dx.doi.org/10.1088/1367-2630/18/2/023023,doi:10.1088/1367-2630/18/ 2/023023
-
[7]
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii. Quantum circuit learning.Phys. Rev. A, 98:032309, Sep 2018. URL:https://link.aps.org/doi/10.1103/PhysRevA.98.032309,doi: 10.1103/PhysRevA.98.032309
-
[8]
Vedran Dunjko and Hans J. Briegel. Machine learning & artificial intelligence in the quantum domain,
- [9]
-
[10]
Yunfei Wang and Junyu Liu. A comprehensive review of quantum machine learning: from nisq to fault tolerance.Reports on Progress in Physics, 87(11):116402, October 2024. URL:http://dx.doi. org/10.1088/1361-6633/ad7f69,doi:10.1088/1361-6633/ad7f69
-
[11]
Quantum computing in the NISQ era and beyond.Quantum, 2:79, 2018
John Preskill. Quantum computing in the nisq era and beyond.Quantum, 2:79, August 2018. URL: http://dx.doi.org/10.22331/q-2018-08-06-79,doi:10.22331/q-2018-08-06-79
-
[12]
Kottmann, Tim Menke, Wai-Keong Mok, Sukin Sim, Leong-Chuan Kwek, and Al´ an Aspuru-Guzik
Kishor Bharti, Alba Cervera-Lierta, Thi Ha Kyaw, Tobias Haug, Sumner Alperin-Lea, Abhinav Anand, Matthias Degroote, Hermanni Heimonen, Jakob S. Kottmann, Tim Menke, Wai-Keong Mok, Sukin Sim, Leong-Chuan Kwek, and Al´ an Aspuru-Guzik. Noisy intermediate-scale quantum 21 algorithms.Rev. Mod. Phys., 94:015004, Feb 2022. URL:https://link.aps.org/doi/10.1103/ ...
-
[13]
Quantum machine learning on near-term quantum devices: Current state of supervised and unsupervised techniques for real-world applications,
Yaswitha Gujju, Atsushi Matsuo, and Rudy Raymond. Quantum machine learning on near-term quantum devices: Current state of supervised and unsupervised techniques for real-world applications,
- [14]
-
[15]
Quantum machine learning: from physics to software engineering.Advances in Physics: X, 8(1), February
Alexey Melnikov, Mohammad Kordzanganeh, Alexander Alodjants, and Ray-Kuang Lee. Quantum machine learning: from physics to software engineering.Advances in Physics: X, 8(1), February
-
[16]
URL:http://dx.doi.org/10.1080/23746149.2023.2165452,doi:10.1080/23746149.2023. 2165452
-
[17]
Mart´ ın Larocca, Supanut Thanasilp, Samson Wang, Kunal Sharma, Jacob Biamonte, Patrick J. Coles, Lukasz Cincio, Jarrod R. McClean, Zo¨ e Holmes, and M. Cerezo. Barren plateaus in variational quantum computing.Nature Reviews Physics, 7(4):174–189, March 2025. URL:http://dx.doi. org/10.1038/s42254-025-00813-9,doi:10.1038/s42254-025-00813-9
-
[18]
Cerezo, Martin Larocca, Diego Garc´ ıa-Mart´ ın, N
M. Cerezo, Martin Larocca, Diego Garc´ ıa-Mart´ ın, N. L. Diaz, Paolo Braccia, Enrico Fontana, Manuel S. Rudolph, Pablo Bermejo, Aroosa Ijaz, Supanut Thanasilp, Eric R. Anschuetz, and Zo¨ e Holmes. Does provable absence of barren plateaus imply classical simulability? or, why we need to rethink variational quantum computing, 2024. URL:https://arxiv.org/ab...
-
[19]
Mind the gaps: The fraught road to quantum advantage
Jens Eisert and John Preskill. Mind the gaps: The fraught road to quantum advantage, 2025. URL: https://arxiv.org/abs/2510.19928,arXiv:2510.19928
-
[20]
ACM Transactions on Quantum Computing , year=
John Preskill. Beyond nisq: The megaquop machine, 2025. URL:https://arxiv.org/abs/2502. 17368,arXiv:2502.17368,doi:10.1145/3723153
-
[21]
Zolt´ an Zimbor´ as, B´ alint Koczor, Zo¨ e Holmes, Elsi-Mari Borrelli, Andr´ as Gily´ en, Hsin-Yuan Huang, Zhenyu Cai, Antonio Ac´ ın, Leandro Aolita, Leonardo Banchi, Fernando G. S. L. Brand˜ ao, Daniel Cavalcanti, Toby Cubitt, Sergey N. Filippov, Guillermo Garc´ ıa-P´ erez, John Goold, Orsolya K´ alm´ an, Elica Kyoseva, Matteo A. C. Rossi, Boris Sokolo...
-
[22]
Generalization in quantum machine learning from few training data
Manuel Caro, Hsin-Yuan Huang, M. Cerezo, Kunal Sharma, Andrew Sornborger, Lukasz Cincio, and Patrick J. Coles. Generalization in quantum machine learning from few training data.Nature Communications, 13:4919, 2022.doi:10.1038/s41467-022-32550-3
-
[23]
Riccardo Molteni, Simon C. Marshall, and Vedran Dunjko. Quantum machine learning advantages be- yond hardness of evaluation, 2025. URL:https://arxiv.org/abs/2504.15964,arXiv:2504.15964
-
[24]
Sarvapriya Tripathi, Himanshu Upadhyay, and Jayesh Soni. Carbon efficient quantum AI: an empirical study of ans¨ atz design trade-offs in QNN and QLSTM models.Sci. Rep., 15(1):44936, 2025.doi: 10.1038/s41598-025-28582-6
-
[25]
The resource cost of large scale quantum computing, 2022
Marco Fellous-Asiani. The resource cost of large scale quantum computing, 2022. URL:https: //arxiv.org/abs/2112.04022,arXiv:2112.04022
-
[26]
Has quantum advantage been achieved?, 2026
Dominik Hangleiter. Has quantum advantage been achieved?, 2026. URL:https://arxiv.org/abs/ 2603.09901,arXiv:2603.09901
-
[27]
Provable advantage in quantum pac learning, 2023
Wilfred Salmon, Sergii Strelchuk, and Tom Gur. Provable advantage in quantum pac learning, 2023. URL:https://arxiv.org/abs/2309.10887,arXiv:2309.10887. 22
-
[28]
Hsin-Yuan Huang, Soonwon Choi, Jarrod R. McClean, and John Preskill. The vast world of quantum advantage, 2025. URL:https://arxiv.org/abs/2508.05720,arXiv:2508.05720
-
[29]
Is quantum advantage the right goal for quantum machine learn- ing?PRX Quantum, 3(3), July 2022
Maria Schuld and Nathan Killoran. Is quantum advantage the right goal for quantum machine learn- ing?PRX Quantum, 3(3), July 2022. URL:http://dx.doi.org/10.1103/PRXQuantum.3.030101, doi:10.1103/prxquantum.3.030101
- [30]
-
[31]
Adri´ an P´ erez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and Jos´ e I. Latorre. Data re-uploading for a universal quantum classifier.Quantum, 4:226, February 2020. URL:http://dx.doi.org/10. 22331/q-2020-02-06-226,doi:10.22331/q-2020-02-06-226
-
[32]
Adri´ an P´ erez-Salinas, David L´ opez-N´ u˜ nez, Artur Garc´ ıa-S´ aez, P. Forn-D´ ıaz, and Jos´ e I. Latorre. One qubit as a universal approximant.Physical Review A, 104(1), July 2021. URL:http://dx.doi.org/ 10.1103/PhysRevA.104.012405,doi:10.1103/physreva.104.012405
-
[33]
doi:10.1103/physreva.103.032430
Maria Schuld, Ryan Sweke, and Johannes Jakob Meyer. Effect of data encoding on the expressive power of variational quantum-machine-learning models.Phys. Rev. A, 103:032430, Mar 2021. URL:https: //link.aps.org/doi/10.1103/PhysRevA.103.032430,doi:10.1103/PhysRevA.103.032430
-
[34]
Multidimensional fourier series with quantum circuits.Phys
Berta Casas and Alba Cervera-Lierta. Multidimensional fourier series with quantum circuits.Phys. Rev. A, 107:062612, Jun 2023. URL:https://link.aps.org/doi/10.1103/PhysRevA.107.062612, doi:10.1103/PhysRevA.107.062612
-
[35]
Schreiber, Jens Eisert, and Johannes Jakob Meyer
Franz J. Schreiber, Jens Eisert, and Johannes Jakob Meyer. Classical surrogates for quantum learning models.Physical Review Letters, 131(10), September 2023. URL:http://dx.doi.org/10.1103/ PhysRevLett.131.100803,doi:10.1103/physrevlett.131.100803
-
[36]
Philip Anton Hernicht, Alona Sakhnenko, Corey O’Meara, Giorgio Cortiana, and Jeanette Miriam Lorenz. Enhancing the scalability of classical surrogates for real-world quantum machine learning applications, 2025. URL:https://arxiv.org/abs/2508.06131,arXiv:2508.06131
-
[37]
Marshall, Riccardo Molteni, and Vedran Dunjko
Sofiene Jerbi, Casper Gyurik, Simon C. Marshall, Riccardo Molteni, and Vedran Dunjko. Shadows of quantum machine learning.Nature Communications, 15(1), July 2024. URL:http://dx.doi.org/ 10.1038/s41467-024-49877-8,doi:10.1038/s41467-024-49877-8
-
[38]
Tensor network surrogate models for variational quantum computation
Ryo Watanabe, Dries Sels, and Joseph Tindall. Tensor network surrogate models for variational quantum computation, 2026. URL:https://arxiv.org/abs/2604.20180,arXiv:2604.20180
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Local surrogates for quantum machine learning, 2025
Sreeraj Rajindran Nair and Christopher Ferrie. Local surrogates for quantum machine learning, 2025. URL:https://arxiv.org/abs/2506.09425,arXiv:2506.09425
-
[40]
3 edition, 2025
Christoph Molnar.Interpretable Machine Learning. 3 edition, 2025. URL:https://christophm. github.io/interpretable-ml-book
2025
-
[41]
Luca Longo, Mario Brcic, Federico Cabitza, Jaesik Choi, Roberto Confalonieri, Javier Del Ser, Ric- cardo Guidotti, Yoichi Hayashi, Francisco Herrera, Andreas Holzinger, Richard Jiang, Hassan Khos- ravi, Freddy Lecue, Gianclaudio Malgieri, Andr´ es P´ aez, Wojciech Samek, Johannes Schneider, Timo Speith, and Simone Stumpf. Explainable artificial intelligen...
-
[42]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ”why should i trust you?”: Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 1135–1144, New York, NY, USA, 2016. Association for Computing Machinery.doi:10.1145/2939672.2939778
-
[43]
On the interpretability of quantum neural networks.Quantum Machine Intelligence, 6(2), August 2024
Lirand¨ e Pira and Chris Ferrie. On the interpretability of quantum neural networks.Quantum Machine Intelligence, 6(2), August 2024. URL:http://dx.doi.org/10.1007/s42484-024-00191-y,doi: 10.1007/s42484-024-00191-y
-
[44]
Rudolph, Armando Angrisani, Tyson Jones, M
Sacha Lerch, Ricard Puig, Manuel S. Rudolph, Armando Angrisani, Tyson Jones, M. Cerezo, Supanut Thanasilp, and Zo¨ e Holmes. Efficient quantum-enhanced classical simulation for patches of quantum landscapes, 2024.arXiv:2411.19896
-
[45]
Rudolph, Thiparat Chotibut, Supanut Thanasilp, and Zo¨ e Holmes
Hela Mhiri, Ricard Puig, Sacha Lerch, Manuel S. Rudolph, Thiparat Chotibut, Supanut Thanasilp, and Zo¨ e Holmes. A unifying account of warm start guarantees for patches of quantum landscapes,
- [46]
-
[47]
Towards quantum machine learning with tensor networks
William Huggins, Piyush Patil, Bradley Mitchell, K Birgitta Whaley, and E Miles Stoudenmire. To- wards quantum machine learning with tensor networks.Quantum Science and Technology, 4(2):024001, January 2019. URL:http://dx.doi.org/10.1088/2058-9565/aaea94,doi:10.1088/2058-9565/ aaea94
-
[48]
Deep tensor networks with matrix product operators.Quantum Machine In- telligence, 4(2), August 2022
Bojan ˇZunkoviˇ c. Deep tensor networks with matrix product operators.Quantum Machine In- telligence, 4(2), August 2022. URL:http://dx.doi.org/10.1007/s42484-022-00081-1,doi: 10.1007/s42484-022-00081-1
-
[49]
Hans-Martin Rieser, Frank K¨ oster, and Arne Peter Raulf. Tensor networks for quantum machine learn- ing.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 479(2275), July 2023. URL:http://dx.doi.org/10.1098/rspa.2023.0218,doi:10.1098/rspa.2023.0218
-
[50]
Hand-waving and interpretive dance: an introductory course on tensor networks.Journal of Physics A: Mathematical and Theoretical, 50(22):223001, May
Jacob C Bridgeman and Christopher T Chubb. Hand-waving and interpretive dance: an introductory course on tensor networks.Journal of Physics A: Mathematical and Theoretical, 50(22):223001, May
-
[51]
URL:http://dx.doi.org/10.1088/1751-8121/aa6dc3,doi:10.1088/1751-8121/aa6dc3
-
[52]
J. Eisert. Entanglement and tensor network states, 2013. URL:https://arxiv.org/abs/1308.3318, arXiv:1308.3318
work page Pith review arXiv 2013
-
[53]
Ivan V. Oseledets. Tensor-train decomposition.SIAM Journal on Scientific Computing, 33(5):2295– 2317, 2011.doi:10.1137/090752286
-
[54]
Perez-Garcia, F
D. Perez-Garcia, F. Verstraete, M. M. Wolf, and J. I. Cirac. Matrix product state representations,
-
[55]
URL:https://arxiv.org/abs/quant-ph/0608197,arXiv:quant-ph/0608197
-
[56]
Understanding Machine Learning
Shai Shalev-Shwartz and Shai Ben-David.Understanding Machine Learning: From Theory to Algo- rithms. Cambridge University Press, 2014.doi:10.1017/CBO9781107298019
-
[57]
Juan Jos´ e Rodr´ ıguez-Aldavero, Paula Garc´ ıa-Molina, Luca Tagliacozzo, and Juan Jos´ e Garc´ ıa-Ripoll. Chebyshev approximation and composition of functions in matrix product states for quantum-inspired numerical analysis, 2025. URL:https://arxiv.org/abs/2407.09609,arXiv:2407.09609
-
[58]
V.N. Vapnik. An overview of statistical learning theory.IEEE Transactions on Neural Networks, 10(5):988–999, 1999.doi:10.1109/72.788640
-
[59]
Lower and upper bounds on the pseudo-dimension of tensor network models
Behnoush Khavari and Guillaume Rabusseau. Lower and upper bounds on the pseudo-dimension of tensor network models. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman 24 Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 10931–10943. Curran Associates, Inc., 2021. URL:https://proceedings.neurips.cc/paper...
2021
-
[60]
Learnability, stability and uniform convergence.Journal of Machine Learning Research, 11(90):2635–2670, 2010
Shai Shalev-Shwartz, Ohad Shamir, Nathan Srebro, and Karthik Sridharan. Learnability, stability and uniform convergence.Journal of Machine Learning Research, 11(90):2635–2670, 2010. URL: http://jmlr.org/papers/v11/shalev-shwartz10a.html
2010
-
[61]
MIT Press, 2 edition, 2018
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar.Foundations of Machine Learning. MIT Press, 2 edition, 2018
2018
-
[62]
Springer: New York, 1999
Vladimir Vapnik.The Nature of Statistical Learning Theory. Springer: New York, 1999
1999
-
[63]
A variational approach of the rank function.TOP, 21(2):207–240, 2013.doi:10.1007/s11750-012-0234-4
Jean-Baptiste Hiriart-Urruty and Hoang Tuy Le. A variational approach of the rank function.TOP, 21(2):207–240, 2013.doi:10.1007/s11750-012-0234-4
-
[64]
Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K. Warmuth. Learnability and the Vapnik-Chervonenkis dimension.Journal of the ACM, 36(4):929–965, 1989.doi:10.1145/76359. 76371
-
[65]
UCI Machine Learning Repository (2012)
Volker Lohweg. Banknote Authentication. UCI Machine Learning Repository, 2012. DOI: https://doi.org/10.24432/C55P57
-
[66]
N. Sauer. On the density of families of sets.Journal of Combinatorial Theory, Series A, 13(1):145–147, 1972.doi:10.1016/0097-3165(72)90019-2. A Appendix: VC Dimension Union Bound We provide a self-contained proof of the union bound for VC dimension used in Lemma 7.1. Lemma A.1(VC Dimension of Union).LetC 1,C 2 be set families over a domainXwithVCdim(C 1) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.