Recognition: unknown
Bayesian Environment Invariant Regression
Pith reviewed 2026-05-07 15:29 UTC · model grok-4.3
The pith
A Bayesian competitive spike-and-slab prior identifies the predictors whose link to the response stays fixed across environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a tractable working model, the competitive spike-and-slab prior establishes invariant model selection consistency together with posterior contraction for the invariant coefficients. With irrelevant predictors present, the posterior concentrates on an equivalent invariant class, and a post-selection refinement consistently recovers the minimal invariant model.
What carries the argument
The competitive spike-and-slab prior that forces each predictor to compete between an invariant shared effect and an environment-specific or spurious effect.
If this is right
- The posterior selects the invariant predictor set with probability approaching one.
- Posterior mass contracts around the true values of the invariant coefficients.
- Irrelevant predictors are handled by posterior concentration on an equivalent invariant class.
- A simple post-selection step recovers the smallest invariant model with high probability.
Where Pith is reading between the lines
- The same competition idea could be tried in nonparametric or nonlinear settings once a suitable working model is available.
- The method shows how to turn observed heterogeneity into a tool for structure learning without requiring explicit causal assumptions.
- In practice the approach may be more robust to distribution shift than pooling all environments and running ordinary variable selection.
Load-bearing premise
The response is generated from a subset of predictors through a mechanism that remains unchanged across environments, and the overall data-generating process admits a tractable working model in which the prior can separate invariant from non-invariant effects.
What would settle it
Generate data from an invariant linear mechanism with known minimal set S; if the posterior probability on models containing exactly the predictors in S does not approach 1 as the number of environments and total sample size grow, the consistency claim is false.
Figures
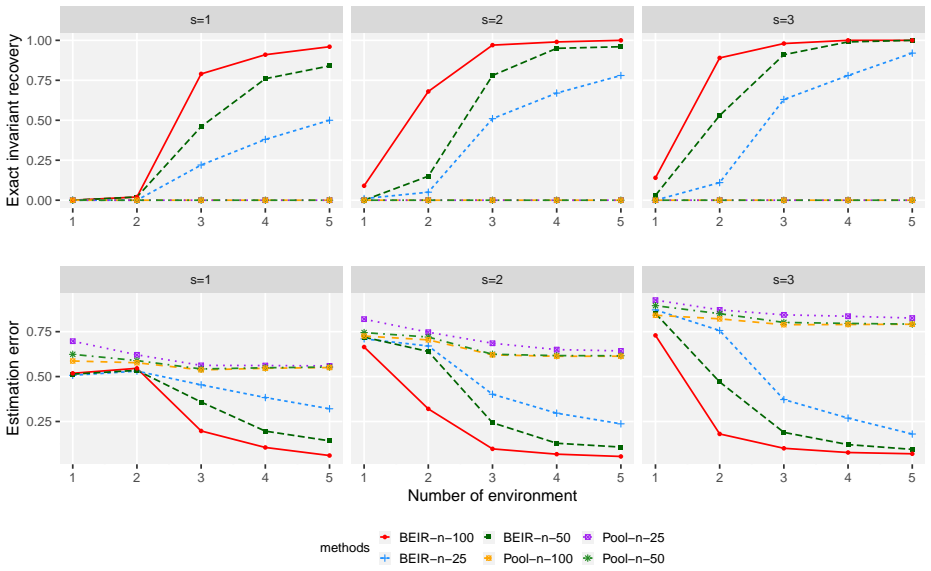
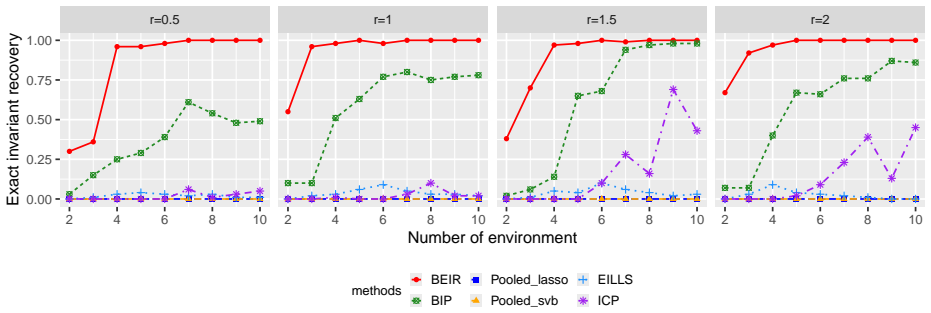



read the original abstract
The availability of data from multiple heterogeneous environments has motivated methods that remain reliable under distributional shifts. When the joint distribution of response and predictors varies across environments, the response may still depend on a subset of predictors through an invariant mechanism. Existing methods typically assess candidate invariant sets through pooled stability criteria, treating environmental variation as nuisance. In this paper, we propose a Bayesian framework that explicitly separates a shared response mechanism from environment-specific or response-dependent associations, exploiting heterogeneity as evidence for structure learning. A competitive spike-and-slab prior is designed to force each predictor to compete between invariant and non-invariant spurious effects. Under a tractable working model, we establish invariant model selection consistency and posterior contraction for invariant coefficients. We further study the presence of irrelevant predictors, characterize posterior concentration on an equivalent invariant class, and introduce a post-selection refinement that consistently recovers the minimal invariant model. Simulations and a real application illustrate the robustness and finite-sample efficiency of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Bayesian framework for learning environment-invariant regression models from heterogeneous multi-environment data. It introduces a competitive spike-and-slab prior that forces each predictor to compete between an invariant shared mechanism and environment-specific or spurious associations. Under an explicitly stated tractable working model, the authors prove invariant model selection consistency, posterior contraction for the invariant coefficients, posterior concentration on an equivalent invariant class in the presence of irrelevant predictors, and consistency of a post-selection refinement that recovers the minimal invariant model. The claims are supported by simulations and a real-data application demonstrating robustness and finite-sample performance.
Significance. If the theoretical results hold under the stated working model, the work provides a principled Bayesian alternative to stability-based invariant learning methods by explicitly modeling and exploiting environmental heterogeneity for structure discovery. The competitive prior construction and the post-selection refinement for minimal invariant recovery are technically interesting contributions that could influence robust prediction and causal discovery under shifts.
minor comments (3)
- [Abstract and §2] The abstract and introduction refer to a 'tractable working model' without listing its core assumptions (e.g., linearity, error structure, or environment-specific variation form) in a single location; adding an explicit enumerated list early in the paper would improve readability for readers who wish to assess the scope of the consistency theorems.
- [Simulations] In the simulation section, the design matrices and environment-specific parameters should be reported with sufficient numerical detail (e.g., exact values of environment-specific coefficients or noise variances) so that the separation between invariant and non-invariant effects can be reproduced exactly.
- [Method] Notation for the competitive spike-and-slab prior (indicator variables, slab variances, and competition mechanism) is introduced gradually; a consolidated table or display equation collecting all prior hyperparameters would reduce cross-referencing.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our manuscript on Bayesian Environment Invariant Regression and for recommending minor revision. We appreciate the recognition of the competitive spike-and-slab prior, the theoretical results under the working model, and the potential contributions to robust prediction and causal discovery. No specific major comments were raised in the report, so we have no point-by-point rebuttals to provide. We will incorporate any minor editorial or presentational suggestions during revision.
Circularity Check
No significant circularity detected
full rationale
The paper's central results—invariant model selection consistency, posterior contraction for invariant coefficients, and post-selection recovery of the minimal invariant model—are all explicitly derived as theorems under a stated tractable working model in which the competitive spike-and-slab prior separates invariant from non-invariant effects. The abstract and description provide no equations or steps in which a target quantity is defined in terms of itself, a fitted parameter is relabeled as a prediction, or a load-bearing premise reduces to a self-citation whose content is unverified. The working model is presented as an assumption that scopes the theorems rather than as a tautology constructed from the outputs. The derivation chain therefore remains self-contained with independent mathematical content.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Response depends on a subset of predictors through an invariant mechanism
- domain assumption Existence of a tractable working model under which the competitive prior separates invariant and non-invariant effects
Reference graph
Works this paper leans on
-
[1]
Arjovsky, L
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz. Invariant risk minimization,
-
[2]
URLhttps://arxiv.org/abs/1907.02893
work page internal anchor Pith review arXiv 1907
-
[3]
H. D. Bondell and B. J. Reich. Consistent high-dimensional Bayesian variable selection 28 via penalized credible regions.Journal of the American Statistical Association, 107 (500):1610–1624, 2012
2012
-
[4]
B¨ uhlmann and S
P. B¨ uhlmann and S. Van De Geer.Statistics for high-dimensional data: methods, theory and applications. Springer Science & Business Media, 2011
2011
-
[5]
Duan and K
Y. Duan and K. Wang. Adaptive and robust multi-task learning.The Annals of Statis- tics, 51(5):2015 – 2039, 2023
2015
-
[6]
J. Fan, C. Fang, Y. Gu, and T. Zhang. Environment invariant linear least squares.The Annals of Statistics, 52(5):2268 – 2292, 2024
2024
-
[7]
E. I. George and R. E. McCulloch. Variable selection via Gibbs sampling.Journal of the American Statistical Association, 88(423):881–889, 1993
1993
-
[8]
Y. Gu, C. Fang, P. B¨ uhlmann, and J. Fan. Causality pursuit from heterogeneous environments via neural adversarial invariance learning.The Annals of Statistics, 53 (5):2230 – 2257, 2025
2025
-
[9]
Z. Guo. Statistical inference for maximin effects: Identifying stable associations across multiple studies.Journal of the American Statistical Association, 119(547):1968–1984, 2024
1968
-
[10]
Heinze-Deml, J
C. Heinze-Deml, J. Peters, and N. Meinshausen. Invariant causal prediction for nonlin- ear models.Journal of Causal Inference, 6(2):20170016, 2018
2018
-
[11]
Ishwaran and J
H. Ishwaran and J. S. Rao. Spike and slab variable selection: Frequentist and Bayesian strategies.The Annals of Statistics, 33(2):730 – 773, 2005
2005
-
[12]
Meinshausen and P
N. Meinshausen and P. B¨ uhlmann. Maximin effects in inhomogeneous large-scale data. The Annals of Statistics, 43(4):1801 – 1830, 2015. 29
2015
-
[13]
N. N. Narisetty, J. Shen, and X. He. Skinny Gibbs: A consistent and scalable Gibbs sampler for model selection.Journal of the American Statistical Association, 114(527): 1205–1217, 2019
2019
-
[14]
G. Park. Identifiability of additive noise models using conditional variances.Journal of Machine Learning Research, 21(75):1–34, 2020
2020
-
[15]
Peters and P
J. Peters and P. B¨ uhlmann. Identifiability of gaussian structural equation models with equal error variances.Biometrika, 101(1):219–228, 2013
2013
-
[16]
Peters, P
J. Peters, P. B¨ uhlmann, and N. Meinshausen. Causal inference by using invariant pre- diction: Identification and confidence intervals.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):947–1012, 2016
2016
-
[17]
Pfister, P
N. Pfister, P. B¨ uhlmann, and J. Peters. Invariant causal prediction for sequential data. Journal of the American Statistical Association, 114(527):1264–1276, 2019
2019
-
[18]
Raskutti, M
G. Raskutti, M. J. Wainwright, and B. Yu. Minimax rates of estimation for high- dimensional linear regression overℓ q -balls.IEEE Transactions on Information Theory, 57(10):6976–6994, 2011
2011
-
[19]
Ray and B
K. Ray and B. Szab´ o. Variational Bayes for high-dimensional linear regression with sparse priors.Journal of the American Statistical Association, 117(539):1270–1281, 2022
2022
-
[20]
Rothenh¨ ausler, N
D. Rothenh¨ ausler, N. Meinshausen, P. B¨ uhlmann, and J. Peters. Anchor regression: Heterogeneous data meet causality.Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(2):215–246, 2021
2021
-
[21]
Sachs, O
K. Sachs, O. Perez, D. Pe’er, D. A. Lauffenburger, and G. P. Nolan. Causal protein- signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005. 30
2005
-
[22]
X. Shen, P. B¨ uhlmann, and A. Taeb. Causality-oriented robustness: Exploiting general noise interventions.Journal of the American Statistical Association, 0(0):1–12, 2026
2026
-
[23]
Tibshirani
R. Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996
1996
-
[24]
Y. Wang, L. Solus, K. Yang, and C. Uhler. Permutation-based causal inference al- gorithms with interventions. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[25]
L. Wu, M. Yin, Y. Wang, J. P. Cunningham, and D. Blei. Bayesian invariance mod- eling of multi-environment data. InWorkshop on Spurious Correlation and Shortcut Learning: Foundations and Solutions, 2025
2025
-
[26]
Y. Yang, M. J. Wainwright, and M. I. Jordan. On the computational complexity of high-dimensional Bayesian variable selection.The Annals of Statistics, 44(6):2497 – 2532, 2016
2016
-
[27]
Y. Yuan, X. Shen, W. Pan, and Z. Wang. Constrained likelihood for reconstructing a directed acyclic gaussian graph.Biometrika, 106(1):109–125, 12 2018
2018
-
[28]
Zhang, Y
R. Zhang, Y. Zhang, J. Shen, Z. Zhu, and A. Qu. Covariate-elaborated robust partial information transfer with conditional spike-and-slab prior.Journal of the American Statistical Association, 0(0):1–13, 2026
2026
-
[29]
Zhao and B
P. Zhao and B. Yu. On model selection consistency of lasso.Journal of Machine Learning Research, 7(90):2541–2563, 2006. 31
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.