Recognition: unknown
SpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Pith reviewed 2026-05-07 15:06 UTC · model grok-4.3
The pith
Speculative decoding paired with top-K compression reduces communication volume in federated LLM inference while keeping output quality high.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
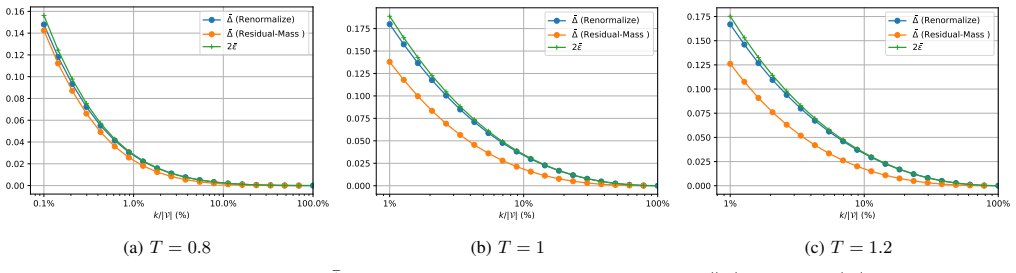
Integrating speculative decoding for parallel processing with a top-K compressed transmission scheme and two server-side reconstruction strategies allows federated LLM inference to run with substantially lower communication cost. The method is shown to introduce only bounded bias in reconstruction error, aggregation, and acceptance rate, and experiments confirm that generation quality remains high while communication overhead drops markedly.
What carries the argument
Speculative decoding combined with top-K compressed transmission and server-side reconstruction of probability distributions.
If this is right
- Workers transmit only top-K probabilities instead of full distributions, directly cutting per-step communication volume.
- Speculative decoding enables parallel draft-token evaluation across distributed workers.
- Bounded errors in reconstruction, aggregation, and acceptance rate keep overall generation fidelity close to the baseline.
- The same compression-plus-reconstruction pattern can be applied at every decoding step without changing the outer federated averaging loop.
Where Pith is reading between the lines
- The technique could extend to other distributed inference workloads that exchange probability vectors, such as federated ranking or recommendation models.
- Dynamic choice of K based on instantaneous bandwidth or model size might further improve the speed-quality trade-off.
- If reconstruction strategies can be made differentiable, the compression could be folded into end-to-end training of the federated system.
Load-bearing premise
The top-K compression and server-side reconstruction strategies introduce only bounded bias in acceptance rate and aggregation that does not materially degrade end-to-end generation quality under realistic federated conditions.
What would settle it
A controlled run on standard benchmarks in which the compressed federated system produces token sequences whose quality metrics (perplexity, BLEU, or human preference scores) fall noticeably below those of uncompressed federated averaging, or in which the measured reduction in bytes transferred fails to improve overall latency.
Figures


read the original abstract
Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpecFed for accelerating federated LLM inference. It integrates speculative decoding for parallel processing with a top-K compressed transmission scheme and server-side reconstruction strategies. The authors derive theoretical bounds on local reconstruction error, aggregation bias, and acceptance-rate bias, and report experiments claiming high generation fidelity with substantially reduced communication overhead.
Significance. If the theoretical bounds prove tight and the experiments confirm that compression-induced biases remain non-material under realistic federated conditions, the work could meaningfully advance efficient distributed inference for large models by alleviating the communication bottleneck in autoregressive decoding. The explicit derivation of bias bounds and focus on fidelity preservation are strengths that distinguish it from purely empirical compression approaches.
major comments (2)
- [Theoretical analysis and Experiments] The theoretical analysis derives bounds on acceptance-rate bias from top-K compression and reconstruction, yet the experiments section reports only aggregate throughput and fidelity metrics without per-step acceptance rates, measured bias values, or direct comparisons of observed bias to the derived bounds across K values or client heterogeneity levels. This gap is load-bearing for the central fidelity claim, as the manuscript states that the scheme achieves high fidelity while the skeptic note indicates no direct validation of the bias bounds against empirical observations.
- [Abstract and Experiments] No quantitative results, error bars, or detailed derivation steps for the reconstruction error, aggregation bias, or acceptance-rate bias bounds are visible in the provided description, leaving the claim that these biases do not materially degrade end-to-end quality without verifiable support.
minor comments (1)
- [Abstract] The abstract would benefit from including specific quantitative values for communication overhead reduction and fidelity metrics (e.g., exact percentages or token rates) to strengthen the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important aspects of validating our theoretical analysis through experiments, which we will address in the revision to strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical analysis and Experiments] The theoretical analysis derives bounds on acceptance-rate bias from top-K compression and reconstruction, yet the experiments section reports only aggregate throughput and fidelity metrics without per-step acceptance rates, measured bias values, or direct comparisons of observed bias to the derived bounds across K values or client heterogeneity levels. This gap is load-bearing for the central fidelity claim, as the manuscript states that the scheme achieves high fidelity while the skeptic note indicates no direct validation of the bias bounds against empirical observations.
Authors: We agree that direct empirical validation of the derived bounds would strengthen the central claims. The current experiments demonstrate high fidelity through end-to-end metrics such as generation quality and throughput, which indirectly reflect the impact of biases. However, to address this explicitly, we will add new figures and tables in the revised manuscript showing per-step acceptance rates, computed bias values (local reconstruction error, aggregation bias, acceptance-rate bias), and comparisons between observed values and the theoretical bounds for varying K and levels of client heterogeneity. This will provide the direct validation requested. revision: yes
-
Referee: [Abstract and Experiments] No quantitative results, error bars, or detailed derivation steps for the reconstruction error, aggregation bias, or acceptance-rate bias bounds are visible in the provided description, leaving the claim that these biases do not materially degrade end-to-end quality without verifiable support.
Authors: The abstract is intended as a concise summary and does not include quantitative details or derivations, which are provided in the main body. The experiments section reports fidelity and throughput results with supporting analysis. To improve clarity and verifiability, we will expand the presentation of the theoretical bounds by including detailed derivation steps in an appendix or main text, and ensure all experimental results include error bars and quantitative values for the bias metrics. We will also add explicit statements linking the observed fidelity to the bounded biases. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces speculative decoding and top-K compression for federated LLM inference, then derives theoretical bounds on reconstruction error, aggregation bias, and acceptance-rate bias. These bounds are presented as independent analysis rather than reductions to fitted parameters or self-referential definitions. No equations in the provided abstract or description reduce claimed performance gains to inputs by construction. The approach relies on external techniques without load-bearing self-citations or ansatzes smuggled via prior author work. Experiments emphasize throughput and fidelity metrics, but the derivation itself remains self-contained against external benchmarks and does not exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Collabora- tive inference via ensembles on the edge,
N. Shlezinger, E. Farhan, H. Morgenstern, and Y . C. Eldar, “Collabora- tive inference via ensembles on the edge,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 8478–8482
2021
-
[2]
Decentral- ized low-latency collaborative inference via ensembles on the edge,
M. Malka, E. Farhan, H. Morgenstern, and N. Shlezinger, “Decentral- ized low-latency collaborative inference via ensembles on the edge,” IEEE Transactions on Wireless Communications, 2024
2024
-
[3]
Towards federated inference: An online model ensemble framework for coopera- tive edge ai,
Z. Zhou, J. Xie, M. Huang, T. Ouyang, F. Liu, and X. Chen, “Towards federated inference: An online model ensemble framework for coopera- tive edge ai,” inIEEE INFOCOM 2025-IEEE Conference on Computer Communications. IEEE, 2025, pp. 1–10
2025
-
[4]
Over-the-air ensemble inference with model privacy,
S. F. Yilmaz, B. Hasırcıo ˘glu, and D. G ¨und¨uz, “Over-the-air ensemble inference with model privacy,” in2022 IEEE International Symposium on Information Theory (ISIT). IEEE, 2022, pp. 1265–1270
2022
-
[5]
Toward improving ensemble-based collaborative inference at the edge,
S. Kumazawa, J. Yu, K. Kawamura, T. Van Chu, and M. Moto- mura, “Toward improving ensemble-based collaborative inference at the edge,”IEEE Access, vol. 12, pp. 6926–6940, 2024
2024
-
[6]
Breaking the ceiling of the llm community by treating token generation as a classification for ensembling,
Y .-C. Yu, C. C. Kuo, Y . Ziqi, C. Yucheng, and Y .-S. Li, “Breaking the ceiling of the llm community by treating token generation as a classification for ensembling,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 1826–1839
2024
-
[7]
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Z. Chen, J. Li, P. Chen, Z. Li, K. Sun, Y . Luo, Q. Mao, M. Li, L. Xiao, D. Yanget al., “Harnessing multiple large language models: A survey on llm ensemble,”arXiv preprint arXiv:2502.18036, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
When to ensemble: Identifying token-level points for stable and fast llm ensembling,
H. Yun, K. Ki, J. Lee, and E. Yang, “When to ensemble: Identifying token-level points for stable and fast llm ensembling,”arXiv preprint arXiv:2510.15346, 2025
-
[9]
Determine-then-ensemble: Necessity of top-k union for large language model ensembling,
Y . Yao, H. Wu, S. Luo, X. Han, J. Liu, Z. Guo, L. Songet al., “Determine-then-ensemble: Necessity of top-k union for large language model ensembling,” inThe Thirteenth International Conference on Learning Representations
-
[10]
Fast large language model collaborative decoding via speculation,
J. Fu, Y . Jiang, J. Chen, J. Fan, X. Geng, and X. Yang, “Fast large language model collaborative decoding via speculation,”arXiv preprint arXiv:2502.01662, 2025
-
[11]
Fast inference from trans- formers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from trans- formers via speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 274–19 286
2023
-
[12]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Edge and terminal cooper- ation enabled llm deployment optimization in wireless network,
W. Zhao, W. Jing, Z. Lu, and X. Wen, “Edge and terminal cooper- ation enabled llm deployment optimization in wireless network,” in 2024 IEEE/CIC International Conference on Communications in China (ICCC Workshops). IEEE, 2024, pp. 220–225
2024
-
[14]
Efficient llm inference over heterogeneous edge networks with speculative decoding,
B. Zhu, Z. Chen, L. Zhao, H. Shin, and A. Nallanathan, “Efficient llm inference over heterogeneous edge networks with speculative decoding,”arXiv preprint arXiv:2510.11331, 2025
-
[15]
Dssd: Efficient edge-device deployment and collaborative inference via distributed split speculative decoding,
J. NING, C. ZHENG, and T. Yang, “Dssd: Efficient edge-device deployment and collaborative inference via distributed split speculative decoding,” inICML 2025 Workshop on Machine Learning for Wireless Communication and Networks (ML4Wireless)
2025
-
[16]
Quantize- sample-and-verify: Llm acceleration via adaptive edge-cloud specula- tive decoding,
G. Zhang, Y . Cai, G. Yu, P. Popovski, and O. Simeone, “Quantize- sample-and-verify: Llm acceleration via adaptive edge-cloud specula- tive decoding,”arXiv preprint arXiv:2507.00605, 2025
-
[17]
Uncertainty-aware hybrid inference with on-device small and remote large language models,
S. Oh, J. Kim, J. Park, S.-W. Ko, T. Q. Quek, and S.-L. Kim, “Uncertainty-aware hybrid inference with on-device small and remote large language models,” in2025 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN). IEEE, 2025, pp. 1–7
2025
-
[18]
Communication-efficient collaborative llm inference via distributed speculative decoding,
C. Zheng and T. Yang, “Communication-efficient collaborative llm inference via distributed speculative decoding,”arXiv preprint arXiv:2509.04576, 2025
-
[19]
Fast collaborative inference via distributed speculative decoding,
C. Zheng, K. Zhang, W. ZHANG, Q. LIU, A. A. Tesfayet al., “Fast collaborative inference via distributed speculative decoding,”Journal of Information and Intelligence, 2026
2026
-
[20]
Non-quadratic distances in model assess- ment,
M. Markatou and Y . Chen, “Non-quadratic distances in model assess- ment,”Entropy, vol. 20, no. 6, p. 464, 2018
2018
-
[21]
Judge decoding: Faster speculative sampling requires going beyond model alignment,
G. Bachmann, S. Anagnostidis, A. Pumarola, M. Georgopoulos, A. Sanakoyeu, Y . Du, E. Sch ¨onfeld, A. Thabet, and J. Kohler, “Judge decoding: Faster speculative sampling requires going beyond model alignment,”arXiv preprint arXiv:2501.19309, 2025
-
[22]
Findings of the 2014 workshop on statistical machine translation,
O. Bojar, C. Buck, C. Federmann, B. Haddow, P. Koehn, J. Leveling, C. Monz, P. Pecina, M. Post, H. Saint-Amand, R. Soricut, L. Specia, and A. s. Tamchyna, “Findings of the 2014 workshop on statistical machine translation,” inProceedings of the Ninth Workshop on Statistical Machine Translation. Baltimore, Maryland, USA: Association for Computational Lingui...
2014
-
[23]
The effect of sampling temperature on problem solving in large language models,
M. Renze, “The effect of sampling temperature on problem solving in large language models,” inFindings of the association for computa- tional linguistics: EMNLP 2024, 2024, pp. 7346–7356
2024
-
[24]
Exploring the impact of temperature on large language models: Hot or cold?
L. Li, L. Sleem, G. Nichil, R. Stateet al., “Exploring the impact of temperature on large language models: Hot or cold?”Procedia Computer Science, vol. 264, pp. 242–251, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.