Recognition: unknown
Improving Diversity in Black-box Few-shot Knowledge Distillation
Pith reviewed 2026-05-07 16:39 UTC · model grok-4.3
The pith
Adaptively selecting high-confidence images under the black-box teacher's supervision expands the diversity of the distillation set and boosts student accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a novel training scheme for generative adversarial networks where we adaptively select high-confidence images under the teacher's supervision and introduce them to the adversarial learning on-the-fly. Our approach helps expand and improve the diversity of the distillation set, significantly boosting student accuracy.
What carries the argument
The on-the-fly adaptive selection of high-confidence images under black-box teacher supervision within the GAN adversarial training.
If this is right
- Student accuracy increases significantly due to the more diverse distillation set.
- The method achieves state-of-the-art performance among few-shot knowledge distillation approaches on seven image datasets.
- Knowledge can be effectively transferred from large models to smaller ones using limited data and no internal teacher access.
- Generative models for data synthesis become more effective when guided by teacher confidence signals.
Where Pith is reading between the lines
- This technique might help in scenarios where data privacy prevents sharing large datasets.
- Similar adaptive selection could be tested in other teacher-student setups beyond images.
- The reliance on teacher confidence suggests potential for combining with other uncertainty measures for better selection.
Load-bearing premise
Selecting images that the teacher is highly confident about will add meaningful diversity to the training data without introducing biases that reduce overall effectiveness.
What would settle it
Observing no improvement in student accuracy or no measurable increase in diversity metrics when the adaptive selection is used compared to non-adaptive generation.
Figures


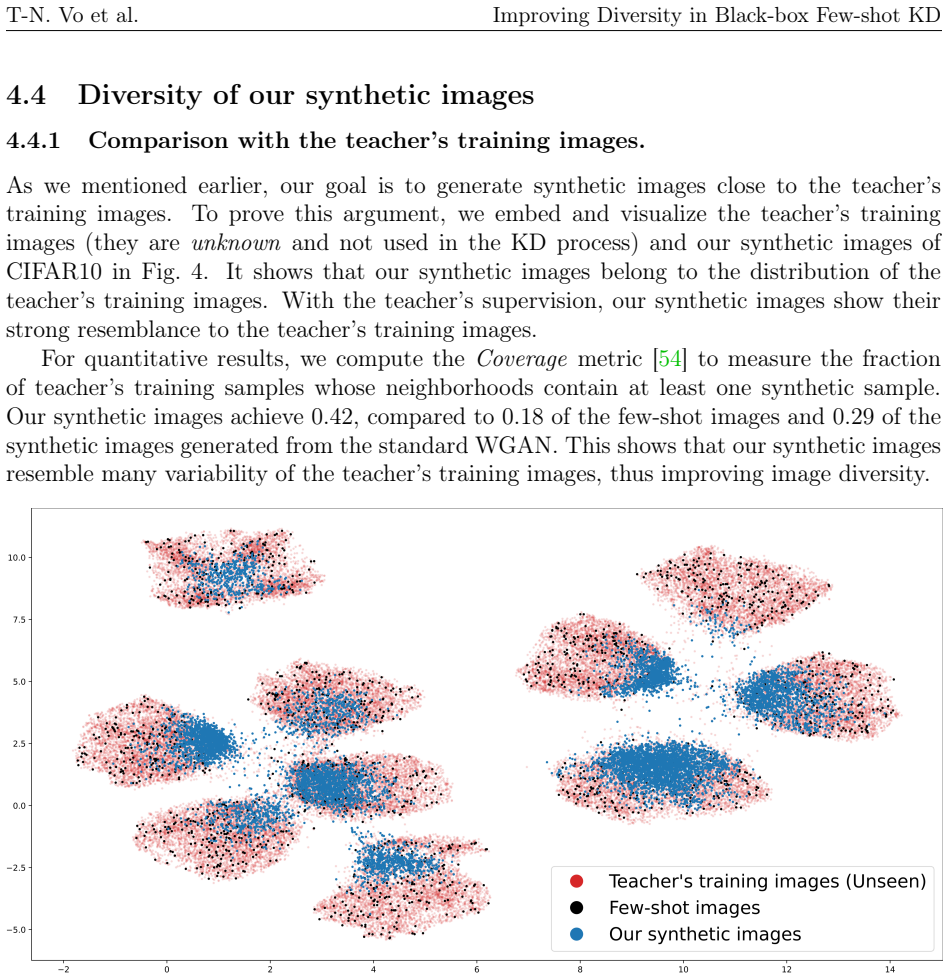

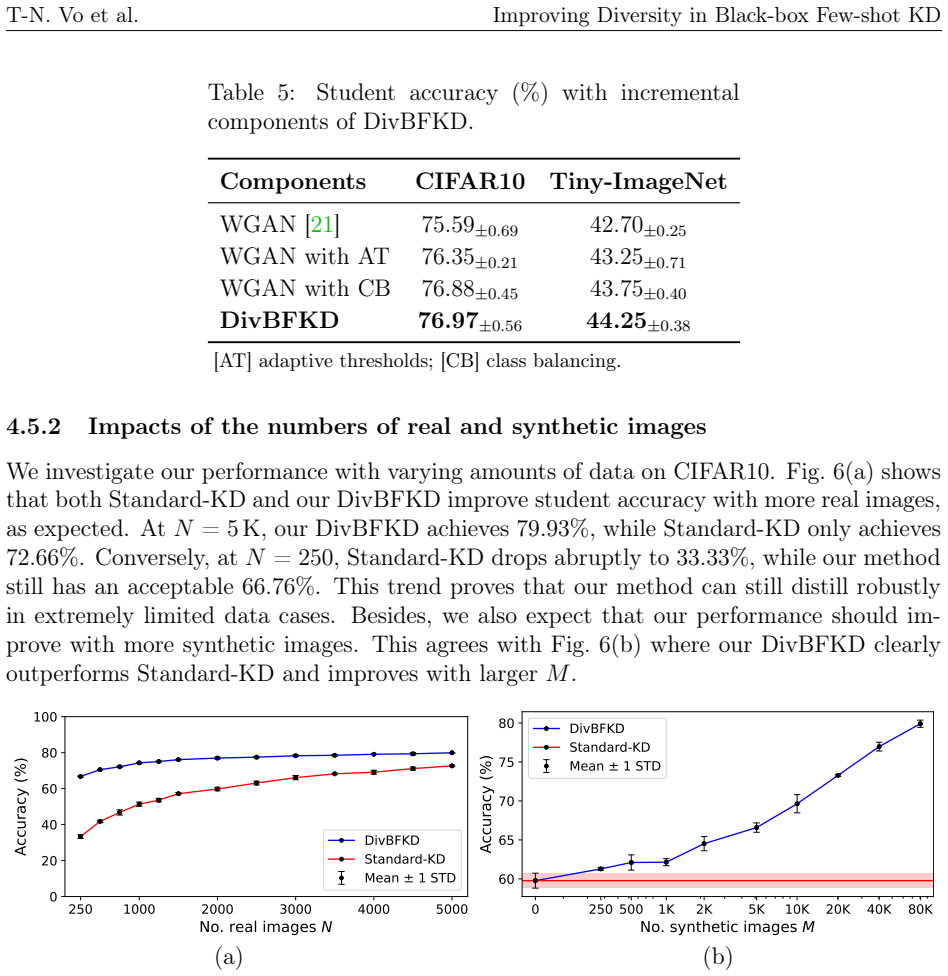

read the original abstract
Knowledge distillation (KD) is a well-known technique to effectively compress a large network (teacher) to a smaller network (student) with little sacrifice in performance. However, most KD methods require a large training set and internal access to the teacher, which are rarely available due to various restrictions. These challenges have originated a more practical setting known as black-box few-shot KD, where the student is trained with few images and a black-box teacher. Recent approaches typically generate additional synthetic images but lack an active strategy to promote their diversity, a crucial factor for student learning. To address these problems, we propose a novel training scheme for generative adversarial networks, where we adaptively select high-confidence images under the teacher's supervision and introduce them to the adversarial learning on-the-fly. Our approach helps expand and improve the diversity of the distillation set, significantly boosting student accuracy. Through extensive experiments, we achieve state-of-the-art results among other few-shot KD methods on seven image datasets. The code is available at https://github.com/votrinhan88/divbfkd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a novel training scheme for generative adversarial networks in the black-box few-shot knowledge distillation setting. High-confidence synthetic images are adaptively selected under the supervision of a black-box teacher and inserted into the adversarial learning loop on-the-fly. This is claimed to expand and improve the diversity of the distillation set, leading to significantly higher student accuracy. The authors report state-of-the-art results among few-shot KD methods across seven image datasets and release the code publicly.
Significance. If the empirical claims hold, the work provides a practical contribution to few-shot black-box KD by targeting the diversity bottleneck in synthetic data generation without requiring teacher internals or large datasets. The public code release aids reproducibility. Significance is limited by the absence of direct evidence that the selection step produces a net increase in useful diversity rather than mode reinforcement.
major comments (2)
- [Abstract / Proposed training scheme] Abstract and method description: The claim that 'adaptively select[ing] high-confidence images under the teacher's supervision' expands diversity is load-bearing for the accuracy and SOTA results, yet no diversity metric (e.g., FID, class-conditional coverage, or intra-set variance) or theoretical argument is supplied to show that high-confidence samples increase support rather than reinforcing teacher-familiar modes. This selection rule is definitionally biased toward peaked teacher predictions and requires explicit before/after quantification to support the central claim.
- [Experiments] Experiments section: The reported state-of-the-art accuracy gains on seven datasets rest on the diversity improvement, but no ablation isolates the on-the-fly adaptive selection from standard GAN generation or from non-adaptive high-confidence filtering. Without such controls or diversity statistics in the results, it is unclear whether the performance delta is attributable to the proposed mechanism.
minor comments (1)
- [Abstract] The abstract states results on 'seven image datasets' but does not name them; listing the datasets (e.g., CIFAR-10, etc.) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of validating our central claim regarding diversity improvement. We address each major comment below and commit to revisions that strengthen the empirical support without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract / Proposed training scheme] Abstract and method description: The claim that 'adaptively select[ing] high-confidence images under the teacher's supervision' expands diversity is load-bearing for the accuracy and SOTA results, yet no diversity metric (e.g., FID, class-conditional coverage, or intra-set variance) or theoretical argument is supplied to show that high-confidence samples increase support rather than reinforcing teacher-familiar modes. This selection rule is definitionally biased toward peaked teacher predictions and requires explicit before/after quantification to support the central claim.
Authors: We agree that the manuscript would benefit from explicit quantification to substantiate the diversity claim. In the revised version, we will add before/after diversity metrics including FID scores on the generated distillation set, intra-class variance, and class-conditional coverage statistics. We will also include a brief theoretical motivation section explaining that the adaptive, on-the-fly selection prioritizes samples aligned with the teacher's high-confidence regions to reduce low-quality noise while the continuous GAN training loop allows the generator to explore additional modes over iterations, counteracting potential reinforcement of familiar modes. We will explicitly discuss the bias toward peaked predictions and how the adaptive mechanism (re-evaluating and inserting during training) mitigates it compared to static filtering. revision: yes
-
Referee: [Experiments] Experiments section: The reported state-of-the-art accuracy gains on seven datasets rest on the diversity improvement, but no ablation isolates the on-the-fly adaptive selection from standard GAN generation or from non-adaptive high-confidence filtering. Without such controls or diversity statistics in the results, it is unclear whether the performance delta is attributable to the proposed mechanism.
Authors: We acknowledge that the current experiments section lacks dedicated ablations isolating the adaptive on-the-fly component. In the revision, we will add two new ablation studies: (1) full method versus a baseline using standard GAN generation without any high-confidence selection, and (2) adaptive on-the-fly selection versus non-adaptive (fixed-threshold) high-confidence filtering applied post-generation. These will be reported alongside the diversity metrics (FID, variance, coverage) on the seven datasets to directly attribute performance gains to the proposed mechanism. The code release will be updated to include these controls for reproducibility. revision: yes
Circularity Check
No circularity; empirical heuristic validated externally
full rationale
The paper proposes an adaptive high-confidence image selection rule inserted into a standard GAN adversarial loop for black-box few-shot KD. The claim that this rule expands distillation-set diversity is presented as an empirical consequence tested on seven datasets, not as a quantity defined by or fitted to the selection itself. No equations, uniqueness theorems, or self-citations are invoked to force the diversity gain by construction; the method remains a practical extension of existing GAN/KD components whose net effect is measured against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Imagenet large scale visual recognition challenge.IJCV, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.IJCV, 2015
2015
-
[2]
Distilling the knowledge in a neural network.NeurIPS Workshop, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.NeurIPS Workshop, 2015
2015
-
[3]
Learn- ing efficient object detection models with knowledge distillation.NeurIPS, 2017
Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, and Manmohan Chandraker. Learn- ing efficient object detection models with knowledge distillation.NeurIPS, 2017
2017
-
[4]
Conditional teacher-student learn- ing
Zhong Meng, Jinyu Li, Yong Zhao, and Yifan Gong. Conditional teacher-student learn- ing. InICASSP, 2019
2019
-
[5]
Knowledge distillation with distribution mismatch
Dang Nguyen, Sunil Gupta, Trong Nguyen, Santu Rana, Phuoc Nguyen, Truyen Tran, Ky Le, Shannon Ryan, and Svetha Venkatesh. Knowledge distillation with distribution mismatch. InECML-PKDD. Springer, 2021
2021
-
[6]
Paraphrasingcomplexnetwork: Network compression via factor transfer.NeurIPS, 2018
JanghoKim, SeongUkPark, andNojunKwak. Paraphrasingcomplexnetwork: Network compression via factor transfer.NeurIPS, 2018
2018
-
[7]
Variational information distillation for knowledge transfer
Sungsoo Ahn, Shell Xu Hu, Andreas Damianou, Neil D Lawrence, and Zhenwen Dai. Variational information distillation for knowledge transfer. InCVPR, 2019
2019
-
[8]
Contrastiverepresentationdistillation
YonglongTian, DilipKrishnan, andPhillipIsola. Contrastiverepresentationdistillation. InICLR, 2020
2020
-
[9]
Facenet: A unified embed- ding for face recognition and clustering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embed- ding for face recognition and clustering. InCVPR, 2015
2015
-
[10]
FitNets: Hints for Thin Deep Nets
Romero et al. FitNets: Hints for thin deep nets.arXiv preprint arXiv:1412.6550, 2014
work page internal anchor Pith review arXiv 2014
-
[11]
A gift from knowledge dis- tillation: Fast optimization, network minimization and transfer learning
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge dis- tillation: Fast optimization, network minimization and transfer learning. InCVPR, 2017. 17 T-N. Vo et al. Improving Diversity in Black-box Few-shot KD
2017
-
[12]
Few-shot learning of neural networks from scratch by pseudo example optimiza- tion
Akisato Kimura, Zoubin Ghahramani, Koh Takeuchi, Tomoharu Iwata, and Naonori Ueda. Few-shot learning of neural networks from scratch by pseudo example optimiza- tion. InBMVC, 2018
2018
-
[13]
Data-free learning of student networks
Hanting Chen, Yunhe Wang, Chang Xu, Zhaohui Yang, Chuanjian Liu, Boxin Shi, Chunjing Xu, Chao Xu, and Qi Tian. Data-free learning of student networks. InICCV, 2019
2019
-
[14]
Introducing ChatGPT, 2022
OpenAI. Introducing ChatGPT, 2022
2022
-
[15]
Learning student networks with few data
Shumin Kong, Tianyu Guo, Shan You, and Chang Xu. Learning student networks with few data. InAAAI, 2020
2020
-
[16]
Neural networks are more productive teachers than human raters: Active mixup for data-efficient knowledge distillation from a blackbox model
Dongdong Wang, Yandong Li, Liqiang Wang, and Boqing Gong. Neural networks are more productive teachers than human raters: Active mixup for data-efficient knowledge distillation from a blackbox model. InCVPR, 2020
2020
-
[17]
Black-box few-shot knowl- edge distillation
Dang Nguyen, Sunil Gupta, Kien Do, and Svetha Venkatesh. Black-box few-shot knowl- edge distillation. InECCV. Springer, 2022
2022
-
[18]
mixup: Beyond empirical risk minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InICLR, 2018
2018
-
[19]
Learning structured output representa- tion using deep conditional generative models.NeurIPS, 2015
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representa- tion using deep conditional generative models.NeurIPS, 2015
2015
-
[20]
Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models.PAMI, 2021
Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G Willcocks. Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models.PAMI, 2021
2021
-
[21]
Wasserstein generative adver- sarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adver- sarial networks. InICML. Pmlr, 2017
2017
-
[22]
Model compression
Cristian Bucila, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In KDD, 2006
2006
-
[23]
Knowledge distil- lation: A survey.IJCV, 2021
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distil- lation: A survey.IJCV, 2021
2021
-
[24]
Do deep nets really need to be deep?NeurIPS, 2014
Lei J Ba and Rich Caruana. Do deep nets really need to be deep?NeurIPS, 2014
2014
-
[25]
Curriculum temperature for knowledge distillation
Zheng Li, Xiang Li, Lingfeng Yang, Borui Zhao, Renjie Song, Lei Luo, Jun Li, and Jian Yang. Curriculum temperature for knowledge distillation. InAAAI, 2023
2023
-
[26]
Online knowledge distillation via collaborative learning
Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, and Ping Luo. Online knowledge distillation via collaborative learning. InCVPR, 2020
2020
-
[27]
Knowledge representing: Efficient, sparse representation of prior knowl- edge for knowledge distillation
Junjie Liu, Dongchao Wen, Hongxing Gao, Wei Tao, Tse-Wei Chen, Kinya Osa, and Masami Kato. Knowledge representing: Efficient, sparse representation of prior knowl- edge for knowledge distillation. InCVPR Workshop, 2019. 18 T-N. Vo et al. Improving Diversity in Black-box Few-shot KD
2019
-
[28]
SergeyZagoruykoandNikosKomodakis. Payingmoreattentiontoattention: Improving the performance of convolutional neural networks via attention transfer.arXiv preprint arXiv:1612.03928, 2016
-
[29]
Learning deep representations with probabilistic knowledge transfer
Nikolaos Passalis and Anastasios Tefas. Learning deep representations with probabilistic knowledge transfer. InECCV, 2018
2018
-
[30]
Relational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. InCVPR, 2019
2019
-
[31]
Learning student networks via feature embedding.IEEE Transactions on Neural Networks and Learning Systems, 2020
Hanting Chen, Yunhe Wang, Chang Xu, Chao Xu, and Dacheng Tao. Learning student networks via feature embedding.IEEE Transactions on Neural Networks and Learning Systems, 2020
2020
-
[32]
Data-free knowledge distilla- tion for deep neural networks.arXiv preprint arXiv:1710.07535, 2017
Raphael Gontijo Lopes, Stefano Fenu, and Thad Starner. Data-free knowledge distilla- tion for deep neural networks.arXiv preprint arXiv:1710.07535, 2017
-
[33]
Zero-shot knowledge distillation in deep networks
Gaurav Kumar Nayak, Konda Reddy Mopuri, Vaisakh Shaj, Venkatesh Babu Radhakr- ishnan, and Anirban Chakraborty. Zero-shot knowledge distillation in deep networks. InICML, 2019
2019
-
[34]
Dreaming to distill: Data-free knowledge transfer via deepinversion
Hongxu Yin, Pavlo Molchanov, Jose M Alvarez, Zhizhong Li, Arun Mallya, Derek Hoiem, Niraj K Jha, and Jan Kautz. Dreaming to distill: Data-free knowledge transfer via deepinversion. InCVPR, 2020
2020
-
[35]
Zero-shot knowledge distillation from a decision-based black-box model
Zi Wang. Zero-shot knowledge distillation from a decision-based black-box model. In ICML. PMLR, 2021
2021
-
[36]
Ideal: Query-efficient data-free learning from black-box models
Jie Zhang, Chen Chen, and Lingjuan Lyu. Ideal: Query-efficient data-free learning from black-box models. InICLR, 2023
2023
-
[37]
The secret revealer: Generative model-inversion attacks against deep neural networks
Yuheng Zhang, Ruoxi Jia, Hengzhi Pei, Wenxiao Wang, Bo Li, and Dawn Song. The secret revealer: Generative model-inversion attacks against deep neural networks. In CVPR, 2020
2020
-
[38]
Degan: Data-enriching gan for retrieving representative samples from a trained classifier
Sravanti Addepalli, Gaurav Kumar Nayak, Anirban Chakraborty, and Venkatesh Babu Radhakrishnan. Degan: Data-enriching gan for retrieving representative samples from a trained classifier. InAAAI, 2020
2020
-
[39]
Momentum adversarial distillation: Handling large distribution shifts in data-free knowledge distillation.NeurIPS, 2022
Kien Do, Thai Hung Le, Dung Nguyen, Dang Nguyen, Haripriya Harikumar, Truyen Tran, Santu Rana, and Svetha Venkatesh. Momentum adversarial distillation: Handling large distribution shifts in data-free knowledge distillation.NeurIPS, 2022
2022
-
[40]
Improved training of wasserstein gans.NeurIPS, 2017
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans.NeurIPS, 2017
2017
-
[41]
Training generative adversarial networks with limited data.NeurIPS, 2020
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data.NeurIPS, 2020. 19 T-N. Vo et al. Improving Diversity in Black-box Few-shot KD
2020
-
[42]
Data-efficient instance gener- ation from instance discrimination.NeurIPS, 2021
Ceyuan Yang, Yujun Shen, Yinghao Xu, and Bolei Zhou. Data-efficient instance gener- ation from instance discrimination.NeurIPS, 2021
2021
-
[43]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review arXiv 2017
-
[44]
Gradient-based learn- ing applied to document recognition.Proceedings of the IEEE, 2002
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learn- ing applied to document recognition.Proceedings of the IEEE, 2002
2002
-
[45]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNeurIPS Workshop, 2011
2011
-
[46]
Learningmultiplelayersoffeaturesfromtinyimages
AlexKrizhevsky. Learningmultiplelayersoffeaturesfromtinyimages. Technicalreport, MIT, NYU, 2009. CIFAR10 and CIFAR100 were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton
2009
-
[47]
Tiny imagenet visual recognition challenge.CS 231N, 2015
Yann Le, Xuan Yang, et al. Tiny imagenet visual recognition challenge.CS 231N, 2015
2015
-
[48]
Imagenette: A subset of 10 easily classified classes from imagenet
Jeremy Howard. Imagenette: A subset of 10 easily classified classes from imagenet. https://github.com/fastai/imagenette, 2020
2020
-
[49]
Imagenet classification with deep convolutional neural networks.NeurIPS, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.NeurIPS, 2012
2012
-
[50]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, 2016
2016
-
[51]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large- scale image recognition.arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review arXiv 2014
-
[52]
Revisiting knowledge distillation via label smoothing regularization
Li Yuan, Francis EH Tay, Guilin Li, Tao Wang, and Jiashi Feng. Revisiting knowledge distillation via label smoothing regularization. InCVPR, 2020
2020
-
[53]
Undistillable: Making a nasty teacher that cannot teach students
Haoyu Ma and Tianlong Chen. Undistillable: Making a nasty teacher that cannot teach students. InICLR, 2021
2021
-
[54]
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. InICML. PMLR, 2022
2022
-
[55]
Improved techniques for training gans.NeurIPS, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.NeurIPS, 2016
2016
-
[56]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS, 2017
2017
-
[57]
Data-free knowledge distillation with soft targeted transfer set synthesis
Zi Wang. Data-free knowledge distillation with soft targeted transfer set synthesis. In AAAI, 2021. 20 T-N. Vo et al. Improving Diversity in Black-box Few-shot KD
2021
-
[58]
Algorithmic assurance: An active approach to algorithmic testing using bayesian opti- misation.NeurIPS, 2018
Shivapratap Gopakumar, Sunil Gupta, Santu Rana, Vu Nguyen, and Svetha Venkatesh. Algorithmic assurance: An active approach to algorithmic testing using bayesian opti- misation.NeurIPS, 2018
2018
-
[59]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434, 2015. 21 T-N. Vo et al. Supplementary Material: DivBFKD [Supplementary Material] Improving Diversity in Black-box Few-shot Knowledge Distillation In this supplementary, we provide the ...
work page internal anchor Pith review arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.