Recognition: unknown
QCalEval: Benchmarking Vision-Language Models for Quantum Calibration Plot Understanding
Pith reviewed 2026-05-07 16:17 UTC · model grok-4.3
The pith
Vision-language models reach 72.3 percent accuracy on quantum calibration plots in the first dedicated benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
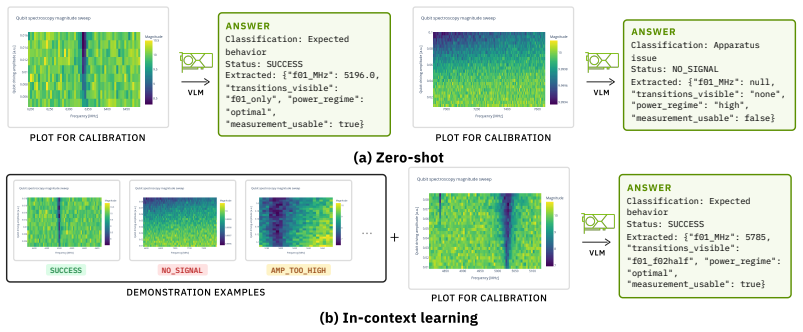
QCalEval supplies 243 calibration-plot samples spanning 87 scenario types from 22 experiment families that include superconducting qubits and neutral atoms. These samples are paired with six question types and evaluated on vision-language models in zero-shot and in-context settings. The best general-purpose zero-shot model attains a mean score of 72.3. Closed frontier models improve when given multiple images while open-weight models typically degrade; a nine-billion-parameter supervised fine-tuning run raises zero-shot scores yet fails to close the multimodal in-context gap. The released NVIDIA Ising Calibration 1 model, derived from Qwen3.5-35B-A3B, records 74.7 zero-shot average.
What carries the argument
QCalEval benchmark consisting of 243 samples, 87 scenario types from 22 experiment families, and six question types that probe VLM reading of quantum calibration plots in zero-shot and in-context regimes.
If this is right
- Improved VLMs could supply real-time guidance during quantum hardware calibration sessions.
- The observed performance drop in open-weight models under multi-image in-context learning identifies a concrete training target.
- Supervised fine-tuning at modest scale raises baseline accuracy but leaves room for architectural advances in multimodal context handling.
- The released 74.7-scoring open-weight model supplies a concrete starting point for community iteration on quantum-specific VLMs.
Where Pith is reading between the lines
- Such a benchmark could accelerate development of AI assistants that monitor and adjust quantum devices without constant human oversight.
- Extending the same evaluation protocol to other experimental outputs, such as tomography images or pulse sequences, would test whether the same models generalize beyond calibration plots.
- If models improve on QCalEval, they might also reduce the expertise barrier for running quantum experiments on cloud platforms.
Load-bearing premise
The 243 selected samples and 87 scenario types from 22 experiment families sufficiently represent the full range of human-interpretable calibration plot challenges across quantum hardware platforms.
What would settle it
A fresh collection of calibration plots from an unrepresented quantum platform or experiment family on which every tested model scores below 50 percent would show that the benchmark coverage is too narrow.
Figures


read the original abstract
Quantum computing calibration depends on interpreting experimental data, and calibration plots provide the most universal human-readable representation for this task, yet no systematic evaluation exists of how well vision-language models (VLMs) interpret them. We introduce QCalEval, the first VLM benchmark for quantum calibration plots: 243 samples across 87 scenario types from 22 experiment families, spanning superconducting qubits and neutral atoms, evaluated on six question types in both zero-shot and in-context learning settings. The best general-purpose zero-shot model reaches a mean score of 72.3, and many open-weight models degrade under multi-image in-context learning, whereas frontier closed models improve substantially. A supervised fine-tuning ablation at the 9-billion-parameter scale shows that SFT improves zero-shot performance but cannot close the multimodal in-context learning gap. As a reference case study, we release NVIDIA Ising Calibration 1, an open-weight model based on Qwen3.5-35B-A3B that reaches 74.7 zero-shot average score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QCalEval, the first VLM benchmark for quantum calibration plots, comprising 243 samples across 87 scenario types drawn from 22 experiment families (superconducting qubits and neutral atoms). It evaluates six question types on multiple models in zero-shot and in-context learning settings, reports a best general-purpose zero-shot mean score of 72.3, shows differential behavior between open-weight and frontier models under ICL, presents an SFT ablation at 9B scale, and releases an open-weight reference model (NVIDIA Ising Calibration 1 based on Qwen3.5-35B-A3B) achieving 74.7 zero-shot average.
Significance. If the dataset construction and evaluation protocol are sound, this provides the first systematic resource for measuring VLM performance on a practically important scientific visualization task in quantum computing. The concrete scores, open/closed model comparisons, SFT results, and released model constitute a useful baseline and starting point for further work on multimodal scientific reasoning.
major comments (3)
- [Abstract / Dataset section] Abstract and presumed §3 (Dataset): No information is supplied on sample selection criteria, how the 87 scenario types were chosen to cover plot variations (axis scaling, noise signatures, multi-panel layouts), question/answer validation process, inter-rater reliability, or bias controls. These omissions directly affect the interpretability of the 72.3 mean score and all downstream claims.
- [Abstract / Dataset section] Abstract and presumed §3: The benchmark is restricted to superconducting qubits and neutral atoms. The manuscript provides no taxonomy, coverage metrics, or expert validation demonstrating that these 22 families capture the essential human-interpretable variations present on other platforms (e.g., ion-trap Ramsey fringes or photonic resonator sweeps). This is load-bearing for the claim that QCalEval constitutes a systematic benchmark.
- [Experiments section] Presumed §4 (Experiments): The paper reports performance differences between zero-shot, ICL, and SFT settings but supplies no details on prompt templates, how multi-image ICL is formatted, scoring rubric for the six question types, or statistical tests for the reported improvements/degradations.
minor comments (2)
- [Figures] Figure captions should explicitly state the source experiment family and question type for each example calibration plot.
- [Conclusion / Data availability] Clarify whether the released benchmark data and evaluation code will be made publicly available alongside the model weights.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each of the major comments point-by-point below. Revisions have been made to the manuscript to incorporate additional details on dataset construction, scope limitations, and experimental protocols as suggested.
read point-by-point responses
-
Referee: [Abstract / Dataset section] Abstract and presumed §3 (Dataset): No information is supplied on sample selection criteria, how the 87 scenario types were chosen to cover plot variations (axis scaling, noise signatures, multi-panel layouts), question/answer validation process, inter-rater reliability, or bias controls. These omissions directly affect the interpretability of the 72.3 mean score and all downstream claims.
Authors: We agree that these details are essential for the benchmark's credibility. In the revised version, we have expanded Section 3 (Dataset) with a new subsection on 'Dataset Construction and Validation'. This includes: (1) criteria for selecting the 243 samples and 87 scenario types, ensuring coverage of variations in axis scaling, noise signatures, and multi-panel layouts; (2) the process involving consultation with quantum computing experts from the 22 experiment families; (3) validation of questions and answers through multiple rounds of expert review; (4) inter-rater reliability statistics (e.g., Cohen's kappa); and (5) measures taken to control for biases such as selection bias and annotation bias. These additions should enhance the interpretability of the reported scores. revision: yes
-
Referee: [Abstract / Dataset section] Abstract and presumed §3: The benchmark is restricted to superconducting qubits and neutral atoms. The manuscript provides no taxonomy, coverage metrics, or expert validation demonstrating that these 22 families capture the essential human-interpretable variations present on other platforms (e.g., ion-trap Ramsey fringes or photonic resonator sweeps). This is load-bearing for the claim that QCalEval constitutes a systematic benchmark.
Authors: We acknowledge the scope limitation noted by the referee. QCalEval is designed as an initial benchmark focusing on two widely used platforms—superconducting qubits and neutral atoms—which together represent a significant portion of current experimental quantum computing research. In the revised manuscript, we have added a taxonomy of the 22 experiment families in Section 3, along with coverage metrics (e.g., distribution across plot types). We have also included a dedicated 'Limitations and Future Work' section that discusses the absence of other platforms like ion traps and photonic systems, provides expert validation rationale for the chosen families based on their prevalence and plot complexity, and outlines plans for future extensions. We believe this clarifies the systematic nature within the defined scope without overclaiming generality. revision: yes
-
Referee: [Experiments section] Presumed §4 (Experiments): The paper reports performance differences between zero-shot, ICL, and SFT settings but supplies no details on prompt templates, how multi-image ICL is formatted, scoring rubric for the six question types, or statistical tests for the reported improvements/degradations.
Authors: We thank the referee for highlighting these omissions, which are important for reproducibility. In the revised manuscript, we have added an Appendix A detailing: (1) the exact prompt templates used for zero-shot and ICL evaluations; (2) the formatting for multi-image ICL, including how images are sequenced and labeled in the prompts; (3) the scoring rubric for each of the six question types, with examples of correct and incorrect responses; and (4) statistical analysis, including p-values from paired t-tests or Wilcoxon tests where applicable to assess the significance of performance differences across settings. These details will allow readers to better understand and replicate the experimental results. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are independent of fitted inputs or self-referential derivations
full rationale
The paper introduces QCalEval as a new benchmark with 243 samples drawn from 87 scenario types across 22 experiment families and reports direct VLM evaluation scores (e.g., best zero-shot mean of 72.3). No equations, parameter fits, or predictions appear in the provided text. The central claims rest on the explicit construction of the dataset and straightforward model testing in zero-shot and in-context settings, without any reduction of results to self-defined quantities or load-bearing self-citations that would make the reported performance equivalent to the inputs by construction. The SFT ablation and released model are presented as separate reference cases, not as derivations that loop back to the benchmark definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can meaningfully be evaluated on scientific plot understanding using fixed question templates across zero-shot and in-context regimes.
Reference graph
Works this paper leans on
-
[1]
Nicolas Wittler, Federico Roy, Kevin Pack, Max Werninghaus, Anurag Saha Roy, Daniel J. Egger, Stefan Filipp, Frank K. Wilhelm, and Shai Machnes. Integrated tool set for control, cal- ibration, and characterization of quantum devices applied to superconducting qubits.Physical Review Applied, 15(3):034080, March 2021. ISSN 2331-7019. doi: 10.1103/physrevapp...
-
[2]
Max Werninghaus, Daniel J Egger, Federico Roy, Shai Machnes, Frank K Wilhelm, and Stefan Filipp. High-speed calibration and characterization of superconducting quantum processors without qubit reset.PRX Quantum, 2(2):020324, May 2021. ISSN 2691-3399. doi: 10.1103/ PRXQuantum.2.020324. URLhttps://doi.org/10.1103/PRXQuantum.2.020324
-
[3]
Lindoy, Deep Lall, Sebastian E
Abhishek Agarwal, Lachlan P. Lindoy, Deep Lall, Sebastian E. de Graaf, Tobias Lind- str¨om, and Ivan Rungger. Fast-tracking and disentangling of qubit noise fluctuations using minimal-data averaging and hierarchical discrete fluctuation auto-segmentation.arXiv preprint arXiv:2505.23622, 2025. URLhttps://arxiv.org/abs/2505.23622
-
[4]
Andrea Pasquale, Stavros Efthymiou, Sergi Ramos-Calderer, Jadwiga Wilkens, Ingo Roth, and Stefano Carrazza. Towards an open-source framework to perform quantum calibration and characterization.arXiv preprint arXiv:2303.10397, 2023. URLhttps://arxiv.org/abs/ 2303.10397
-
[5]
Egger, Yael Ben-Haim, Helena Zhang, William E
Naoki Kanazawa, Daniel J. Egger, Yael Ben-Haim, Helena Zhang, William E. Shanks, Gadi Aleksandrowicz, and Christopher J. Wood. Qiskit experiments: A python package to charac- terize and calibrate quantum computers.Journal of Open Source Software, 8(84):5329, April
-
[6]
ISSN 2475-9066. doi: 10.21105/joss.05329. URLhttp://dx.doi.org/10.21105/ joss.05329
-
[7]
Deep Lall, Abhishek Agarwal, Weixi Zhang, Lachlan Lindoy, Tobias Lindstr ¨om, Stephanie Webster, Simon Hall, Nicholas Chancellor, Petros Wallden, Raul Garcia-Patron, Elham Kashefi, Viv Kendon, Jonathan Pritchard, Alessandro Rossi, Animesh Datta, Theodoros Kapourniotis, Konstantinos Georgopoulos, and Ivan Rungger. A review and collection of met- rics and b...
-
[8]
Fasciati, Michele Piscitelli, Mustafa Bakr, Peter Leek, and Al ´an Aspuru-Guzik
Shuxiang Cao, Zijian Zhang, Mohammed Alghadeer, Simone D. Fasciati, Michele Piscitelli, Mustafa Bakr, Peter Leek, and Al ´an Aspuru-Guzik. Automating quantum computing labora- tory experiments with an agent-based AI framework.Patterns, 6(10):101372, October 2025. ISSN 2666-3899. doi: 10.1016/j.patter.2025.101372. URLhttps://doi.org/10.1016/j. patter.2025.101372
-
[9]
Abhishek Agarwal, Lachlan P Lindoy, Deep Lall, Franc ¸ois Jamet, and Ivan Rungger. Mod- elling non-Markovian noise in driven superconducting qubits.Quantum Science and Tech- nology, 9(3):035017, April 2024. ISSN 2058-9565. doi: 10.1088/2058-9565/ad3d7e. URL https://doi.org/10.1088/2058-9565/ad3d7e
-
[10]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. URLhttps: //arxiv.org/abs/2308.12966
work page internal anchor Pith review arXiv 2023
-
[11]
GPT-4V(ision) System Card
OpenAI. GPT-4V(ision) System Card. Technical report, OpenAI, September 2023. URL https://cdn.openai.com/papers/GPTV_System_Card.pdf. Published September 25, 2023
2023
-
[12]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, volume 36, pages 34892–34916, 2023. URLhttps://papers.nips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html
2023
-
[13]
Flamingo: a visual language model for few-shot learn- 11 ing
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Has- son, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sa- hand Sharifzadeh, Mikołaj Bi...
2022
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InPro- ceedings of the 38th International Conference on Machine Learning, volume 139 ofPro- ceedin...
2021
-
[15]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Ma- chine Learning Research, pages 19730–19742. PMLR, 2023. URLhttps://proceedings. mlr.press/v20...
2023
-
[16]
Instructblip: To- wards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: To- wards general-purpose vision-language models with instruction tuning. InAd- vances in Neural Information Processing Systems, volume 36, pages 49250–49267,
-
[17]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 9a6a435e75419a836fe47ab6793623e6-Abstract-Conference.html
2023
-
[18]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo: An open-source framework for training large autoregressive vision-language models, 2023. URLhttps://a...
work page internal anchor Pith review arXiv 2023
-
[19]
Yongshuo Zong, Ondrej Bohdal, and Timothy M. Hospedales. Vl-icl bench: The devil in the details of multimodal in-context learning. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2403.13164
-
[20]
Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shi- mon Ullman, and Leonid Karlinsky
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shi- mon Ullman, and Leonid Karlinsky. Towards multimodal in-context learning for vision & language models. InComputer Vision – ECCV 2024 Workshops, pages 250–267. Springer Na- ture Switzerland, 2025. ISBN 9783031938061. doi: 10.1007/978-3-031-93806-1 19. URL https://doi.o...
-
[21]
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, and Andrew Y . Ng. Many-shot in-context learning in multimodal foundation mod- els.arXiv preprint arXiv:2405.09798, 2024. doi: 10.48550/ARXIV .2405.09798. URL https://arxiv.org/abs/2405.09798
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[22]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Samira Ebrahimi Kahou, Adam Atkinson, Vincent Michalski, ´Akos K ´ad´ar, Adam Trischler, and Yoshua Bengio. FigureQA: An annotated figure dataset for visual reasoning. InInter- national Conference on Learning Representations, 2018. URLhttps://arxiv.org/abs/ 1710.07300. Workshop Track
work page Pith review arXiv 2018
-
[23]
In: CVPR (2018),https://doi.org/10.1109/CVPR.2018
Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5648–5656. IEEE, June 2018. doi: 10.1109/CVPR.2018. 00592. URLhttps://openaccess.thecvf.com/content_cvpr_2018/html/Kafle_ DVQA_Understanding_Data_CVPR_20...
-
[24]
Khapra, and Pratyush Kumar
Nitesh Methani, Pritha Ganguly, Mitesh M. Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision (WACV), pages 1527–1536, 2020. URL https://openaccess.thecvf.com/content_WACV_2020/html/Methani_PlotQA_ Reasoning_over_Scientific_Plots_WACV_2020_paper.html
2020
-
[25]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Asso- ciation for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, May 12
2022
-
[26]
doi: 10.18653/v1/2022.findings-acl.177
Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-acl.177. URLhttps://aclanthology.org/2022.findings-acl.177/
-
[27]
Enamul Hoque, Parsa Kavehzadeh, and Ahmed Masry. Chart question answering: State of the art and future directions.Computer Graphics Forum, 41(3):555–572, June 2022. ISSN 1467-8659. doi: 10.1111/cgf.14573. URLhttps://doi.org/10.1111/cgf.14573
-
[28]
Chartocr: Data extraction from charts images via a deep hybrid framework
Junyu Luo, Zekun Li, Jinpeng Wang, and Chin-Yew Lin. Chartocr: Data extraction from charts images via a deep hybrid framework. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1917–1925, 2021. URL https://openaccess.thecvf.com/content/WACV2021/html/Luo_ChartOCR_Data_ Extraction_From_Charts_Images_via_a_Deep_Hybrid_...
1917
-
[29]
M., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Chen, W., Collier, N., and Altun, Y
Fangyu Liu, Julian Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, and Yasemin Altun. DePlot: One-shot vi- sual language reasoning by plot-to-table translation. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2...
-
[30]
U ni C hart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
Ahmed Masry, Parsa Kavehzadeh, Xuan Long Do, Enamul Hoque, and Shafiq Joty. UniChart: A universal vision-language pretrained model for chart comprehension and reasoning. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14662–14684, Singapore, Decem- ber 2023...
-
[31]
Chartllama: A multimodal llm for chart understanding and generation
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. Chartllama: A multimodal llm for chart understanding and generation.arXiv preprint arXiv:2311.16483, 2023. URLhttps://arxiv.org/abs/2311.16483
-
[32]
C hart I nstruct: Instruction Tuning for Chart Comprehension and Reasoning
Ahmed Masry, Mehrad Shahmohammadi, Md Rizwan Parvez, Enamul Hoque, and Shafiq Joty. ChartInstruct: Instruction tuning for chart comprehension and reasoning. In Lun- Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Com- putational Linguistics: ACL 2024, pages 10387–10409, Bangkok, Thailand, August 2024. Association for Com...
-
[33]
ChartGemma: Visual instruction-tuning for chart reasoning in the wild
Ahmed Masry, Megh Thakkar, Aayush Bajaj, Aaryaman Kartha, Enamul Hoque, and Shafiq Joty. ChartGemma: Visual instruction-tuning for chart reasoning in the wild. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, Steven Schockaert, Kareem Darwish, and Apoorv Agarwal, editors,Proceedings of the 31st Inter- national Conferen...
2025
-
[34]
Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning
Mohammed Saidul Islam, Raian Rahman, Ahmed Masry, Md Tahmid Rahman Laskar, Mir Tafseer Nayeem, and Enamul Hoque. Are large vision language models up to the chal- lenge of chart comprehension and reasoning? an extensive investigation into the capabili- ties and limitations of lvlms. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of ...
-
[35]
Scifibench: Benchmarking large multimodal models for scientific figure interpretation
Jonathan Roberts, Kai Han, Neil Houlsby, and Samuel Albanie. Scifibench: Benchmarking large multimodal models for scientific figure interpretation. InAdvances in Neural Information Processing Systems 37, NeurIPS 2024, pages 18695–18728. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017-0593. URLhttps:// arxiv.org...
-
[36]
SciCap: Generating captions for scientific figures
Ting-Yao Hsu, C Lee Giles, and Ting-Hao Huang. SciCap: Generating captions for scientific figures. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, ed- itors,Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3258– 3264, Punta Cana, Dominican Republic, November 2021. Association for Computational Lin-...
-
[37]
Lei Li, Yuqi Wang, Runxin Xu, Peiyi Wang, Xiachong Feng, Lingpeng Kong, and Qi Liu. Multimodal ArXiv: A dataset for improving scientific comprehension of large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 14369–14387, Bangkok, Thailand, August 2024. Assoc...
-
[38]
M. A. Rol, C. C. Bultink, T. E. O’Brien, S. R. de Jong, L. S. Theis, X. Fu, F. Luthi, R. F. L. Vermeulen, J. C. de Sterke, A. Bruno, D. Deurloo, R. N. Schouten, F. K. Wilhelm, and L. DiCarlo. Restless tuneup of high-fidelity qubit gates.Physical Review Applied, 7 (4):041001, April 2017. ISSN 2331-7019. doi: 10.1103/PhysRevApplied.7.041001. URL https://doi...
- [40]
-
[41]
Artificial intelligence for quantum computing,
Yuri Alexeev, Marwa H. Farag, Taylor L. Patti, Mark E. Wolf, Natalia Ares, Al ´an Aspuru- Guzik, Simon C. Benjamin, Zhenyu Cai, Shuxiang Cao, Christopher Chamberland, Zohim Chandani, Federico Fedele, Ikko Hamamura, Nicholas Harrigan, Jin-Sung Kim, Elica Kyo- seva, Justin G. Lietz, Tom Lubowe, Alexander McCaskey, Roger G. Melko, Kouhei Nakaji, Alberto Peru...
-
[42]
Marta Skreta, Naruki Yoshikawa, Sebastian Arellano-Rubach, Zhi Ji, Lasse Bjørn Kristensen, Kourosh Darvish, Al´an Aspuru-Guzik, Florian Shkurti, and Animesh Garg. Errors are useful prompts: Instruction guided task programming with verifier-assisted iterative prompting.arXiv preprint arXiv:2303.14100, 2023. URLhttps://arxiv.org/abs/2303.14100
-
[43]
Autonomous chemical research with large language models
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chem- ical research with large language models.Nature, 624(7992):570–578, December 2023. ISSN 1476-4687. doi: 10.1038/s41586-023-06792-0. URLhttps://doi.org/10.1038/ s41586-023-06792-0
-
[44]
Kourosh Darvish, Marta Skreta, Yuchi Zhao, Naruki Yoshikawa, Sagnik Som, Miroslav Bog- danovic, Yang Cao, Han Hao, Haoping Xu, Al ´an Aspuru-Guzik, Animesh Garg, and Florian Shkurti. Organa: A robotic assistant for automated chemistry experimentation and charac- terization.arXiv preprint arXiv:2401.06949, 2024. URLhttps://arxiv.org/abs/2401. 06949
-
[45]
Yixiang Ruan, Chenyin Lu, Ning Xu, Yuchen He, Yixin Chen, Jian Zhang, Jun Xuan, Jianzhang Pan, Qun Fang, Hanyu Gao, Xiaodong Shen, Ning Ye, Qiang Zhang, and Yim- ing Mo. An automatic end-to-end chemical synthesis development platform powered by large language models.Nature Communications, 15(1), November 2024. ISSN 2041-1723. doi: 10.1038/s41467-024-54457...
-
[46]
Smedskjaer, Katrin Wondraczek, Lothar Wondraczek, Nitya Nand Gosvami, and N
Indrajeet Mandal, Jitendra Soni, Mohd Zaki, Morten M. Smedskjaer, Katrin Wondraczek, Lothar Wondraczek, Nitya Nand Gosvami, and N. M. Anoop Krishnan. Evaluating large language model agents for automation of atomic force microscopy.Nature Communica- tions, 16(1), October 2025. ISSN 2041-1723. doi: 10.1038/s41467-025-64105-7. URL https://doi.org/10.1038/s41...
-
[47]
Yong Xie, Kexin He, and Andres Castellanos-Gomez. Toward full autonomous labora- tory instrumentation control with large language models.Small Structures, 6(8), July 2025. ISSN 2688-4062. doi: 10.1002/sstr.202500173. URLhttps://doi.org/10.1002/sstr. 202500173
-
[48]
Prince, Tao Zhou, Henry Chan, and Mathew J
Aikaterini Vriza, Michael H. Prince, Tao Zhou, Henry Chan, and Mathew J. Cherukara. Op- erating advanced scientific instruments with ai agents that learn on the job.npj Computa- 14 tional Materials, March 2026. ISSN 2057-3960. doi: 10.1038/s41524-026-02005-0. URL https://www.nature.com/articles/s41524-026-02005-0
-
[49]
Leonid Abdurakhimov et al. Technology and performance benchmarks of IQM’s 20-qubit quantum computer. 2024. URLhttps://arxiv.org/abs/2408.12433
-
[50]
G. Bratrud, S. Lewis, K. Anyang, A. Col ´on Cesan ´ı, T. Dyson, H. Magoon, D. Sabhari, G. Spahn, G. Wagner, R. Gualtieri, N. A. Kurinsky, R. Linehan, R. McDermott, S. Sussman, D. J. Temples, S. Uemura, C. Bathurst, G. Cancelo, R. Chen, A. Chou, I. Hernandez, M. Hol- lister, L. Hsu, C. James, K. Kennard, R. Khatiwada, P. Lukens, V . Novati, N. Raha, S. Ray...
-
[51]
Introducing gpt-5.4.https://openai.com/index/introducing-gpt-5-4/
OpenAI. Introducing gpt-5.4.https://openai.com/index/introducing-gpt-5-4/. Accessed: 2026-04-10
2026
-
[52]
Gemini 3.1 Pro model card
Google DeepMind. Gemini 3.1 Pro model card. Technical report, Google DeepMind, Febru- ary 2026. URLhttps://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-1-Pro-Model-Card.pdf. Published February 2026. Model card for Gemini 3.1 Pro, Google’s most advanced multimodal reasoning model as of publication date
2026
-
[53]
Introducing claude opus 4.6.https://www.anthropic.com/news/ claude-opus-4-6
Anthropic. Introducing claude opus 4.6.https://www.anthropic.com/news/ claude-opus-4-6. Accessed: 2026-04-10
2026
-
[54]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URLhttps: //qwen.ai/blog?id=qwen3.5
2026
-
[55]
Gemma 4 model card
Google DeepMind. Gemma 4 model card. Google DeepMind, April 2026. URLhttps:// ai.google.dev/gemma/docs/core/model_card_4. Released April 2, 2026. Open-weight multimodal model family (E2B, E4B, 26B A4B MoE, 31B Dense) supporting text, image, audio, and video input with up to 256K context window. Licensed under Apache 2.0
2026
-
[56]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review arXiv 2025
-
[57]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review arXiv 2025
-
[58]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review arXiv 2024
-
[59]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with PagedAttention. InProceedings of the 29th Symposium on Op- erating Systems Principles, SOSP ’23, pages 611–626. ACM, October 2023. doi: 10.1145/ 3600006.3613165. URL...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.