Recognition: unknown
TSN-Affinity: Similarity-Driven Parameter Reuse for Continual Offline Reinforcement Learning
Pith reviewed 2026-05-07 16:36 UTC · model grok-4.3
The pith
Similarity-guided routing of sparse subnetworks in decision transformers enables continual offline RL without replay buffers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TSN-Affinity enables task-specific parameterization and controlled knowledge sharing through an RL-aware reuse strategy that routes tasks according to action compatibility and latent similarity, using sparse subnetworks inside a decision transformer architecture. This produces strong retention on previous tasks and further gains in multi-task settings across both discrete and continuous control benchmarks.
What carries the argument
TinySubNetworks inside a Decision Transformer, with routing that matches tasks by action compatibility and latent similarity to control parameter reuse.
Load-bearing premise
Routing decisions based on action compatibility and latent similarity will reliably prevent negative interference between tasks without requiring task-specific hyperparameter tuning.
What would settle it
A new sequence of tasks where the method produces clear drops in performance on earlier tasks or fails to match replay-buffer baselines despite similar action statistics.
Figures
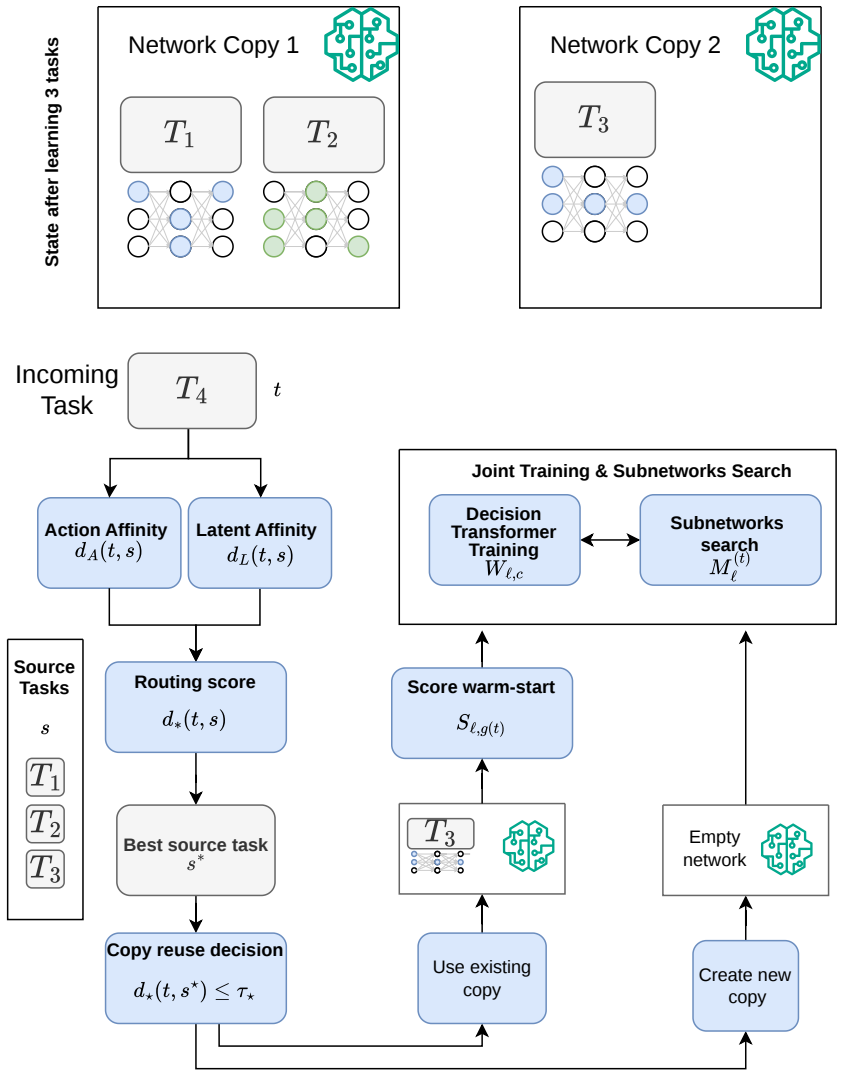

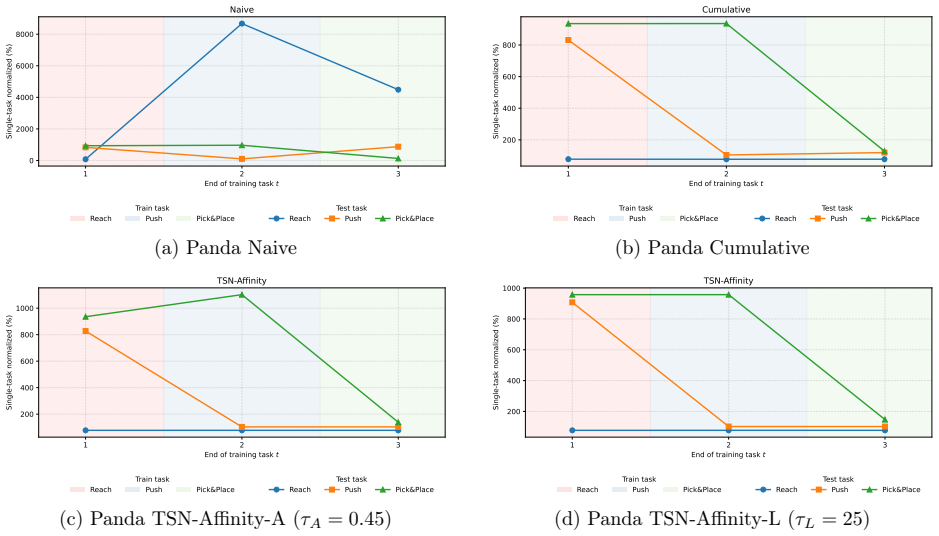
read the original abstract
Continual offline reinforcement learning (CORL) aims to learn a sequence of tasks from datasets collected over time while preserving performance on previously learned tasks. This setting corresponds to domains where new tasks arise over time, but adapting the model in live environment interactions is expensive, risky, or impossible. However, CORL inherits the dual difficulty of offline reinforcement learning and adapting while preventing catastrophic forgetting. Replay-based continual learning approaches remain a strong baseline but incur memory overhead and suffer from a distribution mismatch between replayed samples and newly learned policies. At the same time, architectural continual learning methods have shown strong potential in supervised learning but remain underexplored in CORL. In this work, we propose TSN-Affinity, a novel CORL method based on TinySubNetworks and Decision Transformer. The method enables task-specific parameterization and controlled knowledge sharing through a RL-aware reuse strategy that routes tasks according to action compatibility and latent similarity. We evaluate the approach on benchmarks based on Atari games and simulations of manipulation tasks with the Franka Emika Panda robotic arm, covering both discrete and continuous control. Results show strong retention from sparse SubNetworks, with routing further improving multi-task performance. Our findings suggest that similarity-guided architectural reuse is a strong and viable alternative to replay-based strategies in a CORL setting. Our code is available at: https://github.com/anonymized-for-submission123/tsn-affinity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TSN-Affinity, a continual offline reinforcement learning method that combines TinySubNetworks with a Decision Transformer backbone. It introduces an RL-aware routing mechanism that reuses parameters across tasks by measuring action compatibility and latent similarity, aiming to enable controlled knowledge sharing while avoiding catastrophic forgetting. The approach is evaluated on Atari-based and Franka Emika Panda manipulation benchmarks for both discrete and continuous control, with claims of strong retention from sparse subnetworks and further gains from routing, positioning the method as a viable memory-efficient alternative to replay-based CORL strategies.
Significance. If the empirical results hold under scrutiny, the work provides a promising architectural route for CORL that sidesteps replay-buffer memory costs and distribution mismatch. The similarity-driven reuse of sparse subnetworks could scale better to long task sequences in settings where online adaptation is infeasible, and the open-sourced code link supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that 'similarity-guided architectural reuse is a strong and viable alternative to replay-based strategies' rests on the routing module reliably selecting compatible subnetworks. The manuscript must demonstrate that the latent/action similarity metric and reuse threshold are robust to low-similarity or anti-correlated task sequences; without explicit stress-test results on such sequences, negative transfer remains a risk and the 'no task-specific hyperparameter' aspect of the claim is not yet supported.
- [Evaluation] Evaluation section (Atari and Franka benchmarks): the reported retention and multi-task gains may be benchmark-specific. The paper should include ablations that vary task similarity (e.g., anti-correlated action spaces or dissimilar latent representations) and report whether routing still prevents interference or requires threshold retuning; otherwise the generalization of the routing strategy is not established.
minor comments (2)
- [Abstract] Abstract: the description of how similarity is computed (latent vs. action-based) and how the reuse threshold is chosen is absent; add a concise paragraph or reference to the method section.
- [Abstract] The code repository link is anonymized; replace with the final public URL in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of robustness and generalization that warrant further clarification and support. We address each major comment in detail below, outlining the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'similarity-guided architectural reuse is a strong and viable alternative to replay-based strategies' rests on the routing module reliably selecting compatible subnetworks. The manuscript must demonstrate that the latent/action similarity metric and reuse threshold are robust to low-similarity or anti-correlated task sequences; without explicit stress-test results on such sequences, negative transfer remains a risk and the 'no task-specific hyperparameter' aspect of the claim is not yet supported.
Authors: We agree that explicit evidence of robustness to low-similarity and anti-correlated sequences is required to fully support the routing mechanism's reliability and the lack of task-specific tuning. Our Atari and Franka benchmarks already encompass task sequences with a spectrum of action compatibility and latent similarities, and the RL-aware routing explicitly gates reuse via a fixed similarity threshold to limit negative transfer. To directly address the concern, the revised manuscript will add a dedicated stress-test subsection featuring deliberately anti-correlated sequences (e.g., opposing action directions in the Panda arm and mechanically dissimilar Atari games). These experiments will report retention, interference, and multi-task metrics under the same fixed threshold, confirming that no per-task retuning is needed. This addition will substantiate the central claim without altering the method's core design. revision: yes
-
Referee: [Evaluation] Evaluation section (Atari and Franka benchmarks): the reported retention and multi-task gains may be benchmark-specific. The paper should include ablations that vary task similarity (e.g., anti-correlated action spaces or dissimilar latent representations) and report whether routing still prevents interference or requires threshold retuning; otherwise the generalization of the routing strategy is not established.
Authors: We acknowledge that the current evaluation, while covering both discrete and continuous control, does not exhaustively isolate the effect of task similarity. The existing results already show that routing improves retention over non-routed sparse subnetworks across the chosen task orders. In the revision we will insert a new ablation study that systematically varies similarity by constructing task sequences with controlled anti-correlation in action spaces and latent representations. For each configuration we will report (i) whether interference is prevented, (ii) the resulting retention and multi-task performance, and (iii) whether the similarity threshold requires any adjustment. These results will clarify the operating regime of the routing strategy and any associated limitations, thereby establishing its generalization beyond the primary benchmarks. revision: yes
Circularity Check
No significant circularity: empirical method with no load-bearing derivations or self-referential reductions
full rationale
The paper proposes TSN-Affinity as an empirical CORL architecture combining TinySubNetworks with Decision Transformer and a routing module based on action compatibility and latent similarity. Evaluation relies on benchmark experiments (Atari, Franka) rather than any claimed first-principles derivation chain. No equations, uniqueness theorems, or fitted-parameter predictions are presented that reduce the central performance claims to the method's own inputs by construction. External code link further supports independent reproducibility. This is the normal non-circular outcome for an applied ML methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline datasets remain representative of the tasks even after policy updates during continual learning.
invented entities (1)
-
TSN-Affinity routing strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D. Abel, A. Barreto, B. Van Roy, D. Precup, H. P. van Hasselt, and S. Singh , A definition of continual reinforcement learning , Advances in Neural Information Processing Systems, 36 (2023), pp. 50377--50407
2023
-
[2]
Agarwal, D
R. Agarwal, D. Schuurmans, and M. Norouzi , An optimistic perspective on offline reinforcement learning , in Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, eds., vol. 119 of Proceedings of Machine Learning Research, PMLR, 13--18 Jul 2020, pp. 104--114
2020
-
[3]
G. An, S. Moon, J.-H. Kim, and H. O. Song , Uncertainty-based offline reinforcement learning with diversified q-ensemble , Advances in neural information processing systems, 34 (2021), pp. 7436--7447
2021
-
[4]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch , Decision transformer: Reinforcement learning via sequence modeling , in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 15084--15097
2021
-
[5]
K. Faber, C. Kanan, V. Lomonaco, and R. Corizzo , Continual anomaly detection: A comprehensive survey and research roadmap , Preprints, (2026), https://doi.org/10.20944/preprints202601.1931.v1, https://doi.org/10.20944/preprints202601.1931.v1
-
[6]
K. Faber, D. Zurek, M. Pietron, N. Japkowicz, A. Vergari, and R. Corizzo , From MNIST to ImageNet and back: benchmarking continual curriculum learning , Machine Learning, 113 (2024), pp. 8137--8164, https://doi.org/10.1007/s10994-024-06524-z
-
[7]
S. Gai, D. Wang, and L. He , OER : Offline experience replay for continual offline reinforcement learning , in Proceedings of the 26th European Conference on Artificial Intelligence (ECAI 2023), IOS Press, 2023, pp. 772--779, https://doi.org/10.3233/FAIA230343
-
[8]
J. Hu, S. Huang, L. Shen, Z. Yang, S. Hu, S. Tang, H. Chen, L. Sun, Y. Chang, and D. Tao , Tackling continual offline rl through selective weights activation on aligned spaces , in Advances in Neural Information Processing Systems, 2025
2025
-
[9]
Janner, Q
M. Janner, Q. Li, and S. Levine , Offline reinforcement learning as one big sequence modeling problem , in Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[10]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, and S. Levine , Conservative Q -learning for offline reinforcement learning , in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 1179--1191
2020
-
[11]
K.-H. Lee, O. Nachum, M. S. Yang, L. Lee, D. Freeman, S. Guadarrama, I. Fischer, W. Xu, E. Jang, H. Michalewski, et al. , Multi-game decision transformers , Advances in neural information processing systems, 35 (2022), pp. 27921--27936
2022
-
[12]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu , Offline reinforcement learning: Tutorial, review, and perspectives on open problems , arXiv preprint arXiv:2005.01643, (2020)
work page internal anchor Pith review arXiv 2005
-
[13]
Mallya, D
A. Mallya, D. Davis, and S. Lazebnik , Piggyback: Adapting a single network to multiple tasks by learning to mask weights , in Proceedings of the European Conference on Computer Vision (ECCV), 2018
2018
-
[14]
Mallya and S
A. Mallya and S. Lazebnik , Packnet: Adding multiple tasks to a single network by iterative pruning , in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[15]
M. Pietron, K. Faber, D. Zurek, and R. Corizzo , TinySubNets : An efficient and low capacity continual learning strategy , Proceedings of the AAAI Conference on Artificial Intelligence, 39 (2025), pp. 19913--19920, https://doi.org/10.1609/aaai.v39i19.34193
-
[16]
Pietron, D
M. Pietron, D. Zurek, K. Faber, and R. Corizzo , Ada-qpacknet - multi-task forget-free continual learning with quantization driven adaptive pruning , in Proceedings of the 26th European Conference on Artificial Intelligence (ECAI 2023), 2023, pp. 1882--1889
2023
-
[17]
Rolnick, A
D. Rolnick, A. Ahuja, J. Schwarz, T. P. Lillicrap, and G. Wayne , Experience replay for continual learning , in Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[18]
Schmied, M
T. Schmied, M. Hofmarcher, F. Paischer, R. Pascanu, and S. Hochreiter , Learning to modulate pre-trained models in rl , in Advances in Neural Information Processing Systems, 2023
2023
-
[19]
Serra, D
J. Serra, D. Suris, M. Miron, and A. Karatzoglou , Overcoming catastrophic forgetting with hard attention to the task , in Proceedings of the 35th International Conference on Machine Learning, vol. 80 of Proceedings of Machine Learning Research, 2018, pp. 4548--4557
2018
-
[20]
L. Wang, X. Zhang, H. Su, and J. Zhu , A comprehensive survey of continual learning: Theory, method and application , IEEE transactions on pattern analysis and machine intelligence, 46 (2024), pp. 5362--5383
2024
-
[21]
Z. Wang, X. Qu, J. Xiao, B. Chen, and J. Wang , P2dt: Mitigating forgetting in task-incremental learning with progressive prompt decision transformer , in 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 7265--7269, https://doi.org/10.1109/ICASSP48485.2024.10447775
-
[22]
Zhang, K
T. Zhang, K. Z. Shen, Z. Lin, B. Yuan, X. Wang, X. Li, and D. Ye , Replay-enhanced continual reinforcement learning , Transactions on Machine Learning Research, (2023)
2023
-
[23]
write newline
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTION or pop #1 'skip if FUNCTION new.block.checka empty 'skip 'new.block if FUNCTION field.or.null duplicate empty pop "" 'skip ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.