Recognition: unknown
A paradox of AI fluency
Pith reviewed 2026-05-07 16:11 UTC · model grok-4.3
The pith
Fluent AI users achieve more on complex tasks by actively iterating with the system, but this leads to more visible failures compared to novices who often have undetected shortfalls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fluent users take on more complex tasks and adopt a collaborative interaction style involving iteration and critical assessment of outputs, which produces more visible failures that often allow partial recovery, alongside greater success on those complex tasks, whereas novices use a passive stance that more often results in invisible failures where conversations appear successful but miss the mark.
What carries the argument
The contrast in interactional modes between active collaborative iteration by fluent users and passive acceptance by novices, which determines whether failures are visible and recoverable or invisible and undetected.
If this is right
- Users should prioritize active engagement, such as iterating on goals and critiquing responses, to maximize benefits from AI on difficult tasks.
- AI product builders need to design interfaces that support and encourage deep user involvement instead of minimizing friction at all costs.
- Overall, active users will experience more apparent setbacks but achieve better outcomes on ambitious projects.
- Passive users risk completing interactions that look good but deliver less value without noticing the gap.
Where Pith is reading between the lines
- Similar dynamics could appear in other AI-assisted tools like code generation or data analysis, where engagement style affects outcome quality.
- Over time, encouraging active use might help close skill gaps by turning visible failures into learning opportunities.
- Design choices that promote passive use could inadvertently reduce the effective capabilities of the AI for many users.
- Measuring true success requires tracking not just completion rates but also alignment between stated goals and actual results.
Load-bearing premise
The detailed annotations on the large collection of chat transcripts can reliably categorize users as fluent or novice without bias, determine task complexity accurately, and classify failures correctly as visible or invisible.
What would settle it
A study that tracks actual task outcomes for users with independently verified skill levels on the same set of problems, checking whether visible failure rates and recovery correlate with fluency as described.
Figures
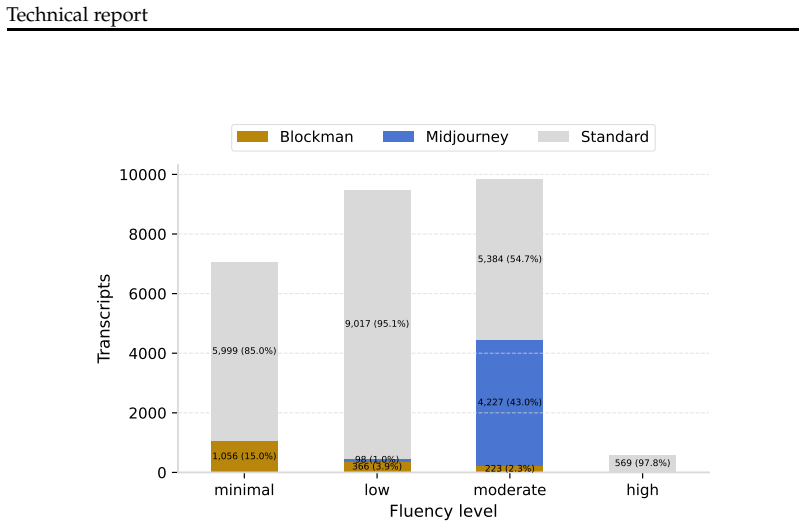


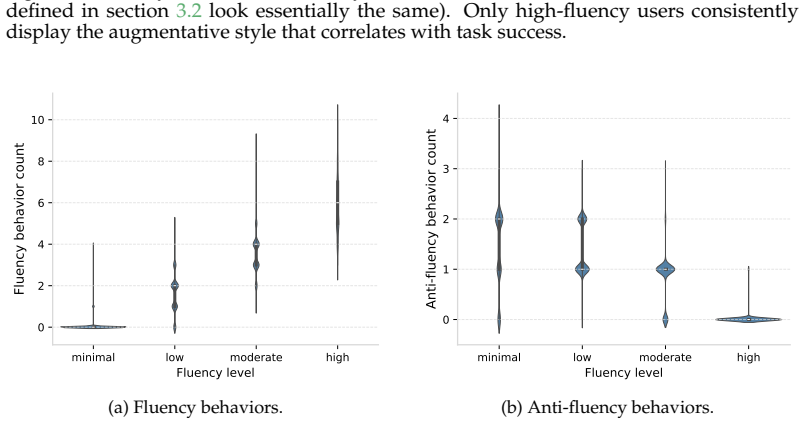
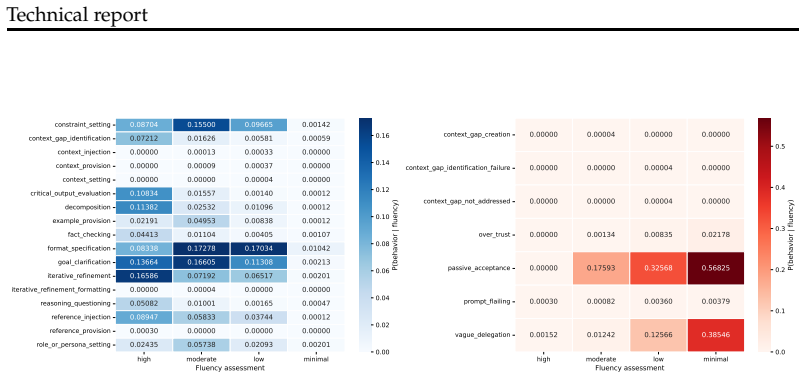
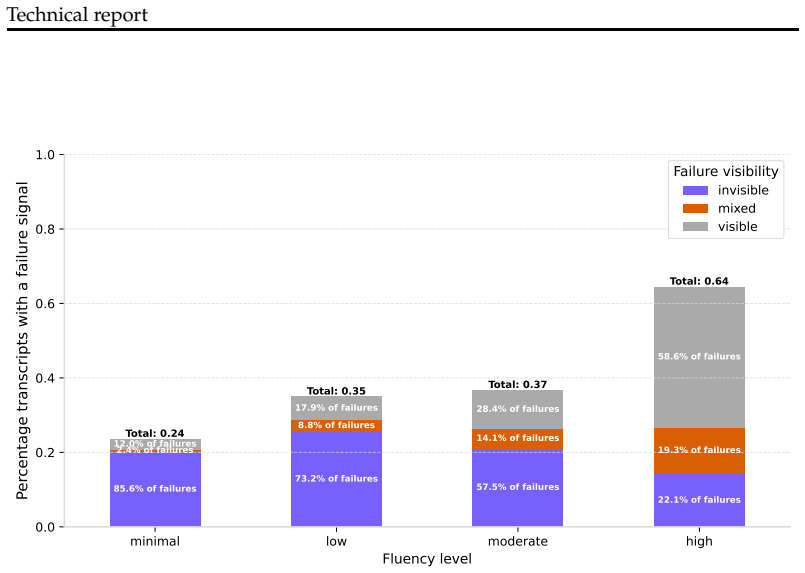


read the original abstract
How much does a user's skill with AI shape what AI actually delivers for them? This question is critical for users, AI product builders, and society at large, but it remains underexplored. Using a richly annotated sample of 27K transcripts from WildChat-4.8M, we show that fluent users take on more complex tasks than novices and adopt a fundamentally different interactional mode: they iterate collaboratively with the AI, refining goals and critically assessing outputs, whereas novices take a passive stance. These differences lead to a paradox of AI fluency: fluent users experience more failures than novices -- but their failures tend to be visible (a direct consequence of their engagement), they are more likely to lead to partial recovery, and they occur alongside greater success on complex tasks. Novices, by contrast, more often experience invisible failures: conversations that appear to end successfully but in fact miss the mark. Taken together, these results reframe what success with AI depends on. Individuals should adopt a stance of active engagement rather than passive acceptance. AI product builders should recognize that they are designing not just model behavior but user behavior; encouraging deep engagement, rather than friction-free experiences, will lead to more success overall. Our code and data are available at https://github.com/bigspinai/bigspin-fluency-outcomes
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes 27K annotated transcripts from the WildChat dataset to argue that fluent AI users undertake more complex tasks and engage in iterative, collaborative interactions with the model, whereas novices adopt a passive stance. This leads to a 'paradox of AI fluency': fluent users encounter more failures, but these are typically visible (prompting engagement and partial recovery) and occur alongside greater success on complex tasks; novices more often experience invisible failures where transcripts end successfully but the outcome misses the mark. The authors conclude that success depends on active user engagement and recommend that AI systems be designed to encourage deep interaction rather than friction-free experiences. Code and data are released.
Significance. If the core classifications hold, the work would usefully reframe AI outcomes as jointly determined by model behavior and user interaction style, with practical implications for interface design and user training. The public release of code and data is a clear strength that supports verification and extension. The distinction between visible and invisible failures offers a novel lens on what counts as 'success' in conversational AI.
major comments (3)
- [§3] §3 (Data and Annotation): The central claim rests on annotations that classify users as fluent versus novice, grade task complexity, and label failures as visible versus invisible. No inter-annotator agreement statistics, annotation guidelines, number of annotators, or external validation procedure are reported. Because transcripts alone contain no ground truth for unstated user goals, the visible/invisible distinction and resulting paradox cannot be verified from the provided description.
- [§4] §4 (Results): The finding that fluent users experience more failures is presented without statistical controls for task complexity. Since the same section shows fluent users select more complex tasks, the elevated failure rate may be driven by task difficulty rather than fluency per se; this threatens the interpretation that fluency itself produces the reported pattern of visible failures and recoveries.
- [§4.3] §4.3 (Failure Recovery Analysis): Claims that visible failures 'are more likely to lead to partial recovery' require explicit operational definitions of recovery and quantitative comparisons (e.g., success rates post-failure for fluent vs. novice cohorts). Without these, the differential-recovery component of the paradox remains unsupported.
minor comments (2)
- The abstract states that the sample is 'richly annotated' but does not preview the annotation schema or reliability checks; adding one sentence on these points would improve readability.
- [Figures] Figure captions should include sample sizes and any statistical tests used for the visible/invisible failure comparisons.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the reporting and analysis. Our responses focus on clarifying the annotation process, adding statistical controls, and providing explicit definitions and comparisons as requested.
read point-by-point responses
-
Referee: [§3] §3 (Data and Annotation): The central claim rests on annotations that classify users as fluent versus novice, grade task complexity, and label failures as visible versus invisible. No inter-annotator agreement statistics, annotation guidelines, number of annotators, or external validation procedure are reported. Because transcripts alone contain no ground truth for unstated user goals, the visible/invisible distinction and resulting paradox cannot be verified from the provided description.
Authors: We agree these details require expansion. The annotations were conducted by three researchers using guidelines that operationalize fluency via observable interaction patterns (e.g., iterative refinement and critical assessment), task complexity on a 1-5 scale derived from transcript content, and visible failures as those explicitly referenced or corrected in subsequent turns. We will add the full annotation guidelines as supplementary material, report the number of annotators, compute and include inter-annotator agreement statistics, and describe our internal validation procedure. For the ground-truth concern, the visible/invisible distinction is defined strictly from transcript evidence rather than inferred external goals; we will clarify this operationalization to allow verification from the data. revision: yes
-
Referee: [§4] §4 (Results): The finding that fluent users experience more failures is presented without statistical controls for task complexity. Since the same section shows fluent users select more complex tasks, the elevated failure rate may be driven by task difficulty rather than fluency per se; this threatens the interpretation that fluency itself produces the reported pattern of visible failures and recoveries.
Authors: We acknowledge that task complexity confounds the raw failure rate. Our core claim concerns the interaction mode (active iteration vs. passive acceptance) rather than fluency in isolation, but we will add a controlled analysis in the revision. This will include a logistic regression predicting failure type and recovery outcomes with user fluency as the predictor and task complexity as a covariate, plus stratified comparisons within complexity levels. These additions will test whether the visible-failure and recovery patterns persist beyond difficulty differences. revision: yes
-
Referee: [§4.3] §4.3 (Failure Recovery Analysis): Claims that visible failures 'are more likely to lead to partial recovery' require explicit operational definitions of recovery and quantitative comparisons (e.g., success rates post-failure for fluent vs. novice cohorts). Without these, the differential-recovery component of the paradox remains unsupported.
Authors: We will revise this section to supply the requested details. Visible failure will be defined as any turn where the user explicitly signals dissatisfaction, requests changes, or notes an error. Recovery will be operationalized as continuation to a subsequent turn where the user indicates satisfaction or the task reaches apparent completion. We will add quantitative results comparing post-failure success/recovery rates between fluent and novice cohorts, including effect sizes and statistical tests. This will directly support the differential-recovery element of the paradox. revision: yes
Circularity Check
No circularity: empirical patterns observed in independently annotated transcripts
full rationale
The paper reports observational findings from a sample of 27K WildChat transcripts that the authors annotate for user fluency (fluent vs. novice), task complexity, and failure visibility (visible vs. invisible). The claimed paradox is simply the co-occurrence of these labels in the data: fluent users show more visible failures alongside complex-task success, while novices show more invisible failures. No equations, fitted parameters, predictions, or self-citations are invoked to derive the result; the outcome is not equivalent to the input classifications by construction. The analysis is self-contained once the annotations are accepted as given, with no reduction of the central claim to a definitional or statistical tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Annotations of the 27K transcripts can reliably classify users as fluent versus novice and label task complexity and failure types.
- domain assumption The 27K sample is representative of broader user behaviors in AI chat interactions.
Reference graph
Works this paper leans on
-
[1]
Anthropic education report: The AI fluency index
Anthropic . Anthropic education report: The AI fluency index. https://www.anthropic.com/research/AI-fluency-index, February 2026. Accessed: 2026-03-11
2026
-
[2]
Barr, Roger Levy, Christoph Scheepers, and Harry J
Dale J. Barr, Roger Levy, Christoph Scheepers, and Harry J. Tily. Random effects structure in mixed-effects models: Keep it maximal. Journal of Memory and Language, 68 0 (3): 0 255--278, August 2011
2011
-
[3]
Douglas Bates, Martin M \"a chler, Ben Bolker, and Steve Walker. Fitting linear mixed-effects models using lme4 . Journal of Statistical Software, 67 0 (1): 0 1--48, 2015. doi:10.18637/jss.v067.i01
-
[4]
Canaries in the coal mine? Six facts about the recent employment effects of artificial intelligence
Erik Brynjolfsson, Bharat Chandar, and Ruyu Chen. Canaries in the coal mine? Six facts about the recent employment effects of artificial intelligence. Working paper, Stanford Digital Economy Lab, November 2025 a . URL https://digitaleconomy.stanford.edu/app/uploads/2025/11/CanariesintheCoalMine_Nov25.pdf. Accessed: 2026-03-11
2025
-
[5]
The Quarterly Journal of Economics , author =
Erik Brynjolfsson, Danielle Li, and Lindsey Raymond. Generative AI at work*. The Quarterly Journal of Economics, 140 0 (2): 0 889--942, 02 2025 b . ISSN 0033-5533. doi:10.1093/qje/qjae044. URL https://doi.org/10.1093/qje/qjae044
-
[6]
Bullinaria and Joseph P
John A. Bullinaria and Joseph P. Levy. Extracting semantic representations from word co-occurrence statistics: A computational study. Behavior Research Methods, 39 0 (3): 0 510--526, 2007
2007
-
[7]
Deming, Zo \"e Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman
Aaron Chatterji, Thomas Cunningham, David J. Deming, Zo \"e Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use ChatGPT . Working Paper 34255, National Bureau of Economic Research, September 2025. URL https://www.nber.org/papers/w34255
2025
-
[8]
Word association norms, mutual information, and lexicography
Kenneth Ward Church and Patrick Hanks. Word association norms, mutual information, and lexicography. Computational Linguistics, 16 0 (1): 0 22--29, 1990. URL https://aclanthology.org/J90-1003/
1990
-
[9]
Clark, Robert Schreuder, and Samuel Buttrick
Herbert H. Clark, Robert Schreuder, and Samuel Buttrick. Common ground and the understanding of demonstrative reference. Journal of Verbal Learning and Verbal Behavior, 22 0 (2): 0 245--258, 1983
1983
-
[10]
Zheyuan Kevin Cui, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers. Management Science, 2026. doi:10.1287/mnsc.2025.00535. URL https://doi.org/10.1287/mnsc.2025.00535. Articles in Advance, published February 2026
-
[11]
Framework for AI fluency (practical summary document), 2025
Rick Dakan and Joseph Feller. Framework for AI fluency (practical summary document), 2025. URL https://ringling.libguides.com/ai/framework. Version 1.1, Ringling.edu/ai/. Retrieved on April 20, 2026
2025
-
[12]
GPTs Are GPTs: Labor Market Impact Potential of LLMs
Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. GPTs are GPTs : Labor market impact potential of LLMs . Science, 384 0 (6702): 0 1306--1308, 2024. doi:10.1126/science.adj0998. URL https://www.science.org/doi/abs/10.1126/science.adj0998
-
[13]
Pragmatics in language grounding: Phenomena, tasks, and modeling approaches
Daniel Fried, Nicholas Tomlin, Jennifer Hu, Roma Patel, and Aida Nematzadeh. Pragmatics in language grounding: Phenomena, tasks, and modeling approaches. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 12619--12640, Singapore, December 2023. Association for Computational Ling...
-
[14]
Paul Grice
H. Paul Grice. Logic and conversation. In Peter Cole and Jerry Morgan (eds.), Syntax and Semantics, volume 3: Speech Acts, pp.\ 43--58. Academic Press, New York, 1975
1975
-
[15]
Language models represent space and time.arXiv preprint arXiv:2310.02207,
Wes Gurnee and Max Tegmark. Language models represent space and time, 2024. URL https://arxiv.org/abs/2310.02207
-
[16]
AI safety should prioritize the future of work, 2025
Sanchaita Hazra, Bodhisattwa Prasad Majumder, and Tuhin Chakrabarty. AI safety should prioritize the future of work, 2025. URL https://arxiv.org/abs/2504.13959
-
[17]
GLAT : The generative AI literacy assessment test, 2024
Yueqiao Jin, Roberto Martinez-Maldonado, Dragan Gašević, and Lixiang Yan. GLAT : The generative AI literacy assessment test, 2024. URL https://arxiv.org/abs/2411.00283
-
[18]
The agency gap: How generative AI literacy shapes independent writing after AI support, 2025
Yueqiao Jin, Kaixun Yang, Roberto Martinez-Maldonado, Dragan Gašević, and Lixiang Yan. The agency gap: How generative AI literacy shapes independent writing after AI support, 2025. URL https://arxiv.org/abs/2507.04398
-
[19]
On the measurement of ai literacy among students in higher education: A scoping review
Jeffrey Jones. On the measurement of ai literacy among students in higher education: A scoping review. International Journal of AI in Pedagogy, Innovation, and Learning Futures, 2026 0 (1), Feb. 2026. doi:10.46787/ijaipil.v2026i1.6920. URL https://journals.calstate.edu/ijaipil/article/view/6920
-
[20]
Hao-Ping (Hank) Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, and Nicholas Wilson. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI '25...
-
[21]
arXiv preprint arXiv:2210.13382 , year=
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a synthetic task, 2024. URL https://arxiv.org/abs/2210.13382
-
[22]
From G-Factor to A-Factor : Establishing a psychometric framework for AI literacy, 2025
Ning Li, Wenming Deng, and Jiatan Chen. From G-Factor to A-Factor : Establishing a psychometric framework for AI literacy, 2025. URL https://arxiv.org/abs/2503.16517
-
[23]
Generative artificial intelligence literacy: Scale development and its effect on job performance
Xin Liu, Longxin Zhang, and Xiaochong Wei. Generative artificial intelligence literacy: Scale development and its effect on job performance. Behavioral Sciences, 15 0 (6), 2025. ISSN 2076-328X. doi:10.3390/bs15060811. URL https://www.mdpi.com/2076-328X/15/6/811
-
[24]
Ryan Louie, Raj Sanjay Shah, Ifdita Hasan Orney, Juan Pablo Pacheco, Emma Brunskill, and Diyi Yang. Can LLM-Simulated practice and feedback upskill human counselors? A randomized study with 90+ novice counselors. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 2026. Association for Computing Machinery. I...
-
[25]
Christine Machovec, Michael J. Rieley, and Emily Rolen. Incorporating AI impacts in BLS employment projections: Occupational case studies. Monthly Labor Review, February 2025. doi:10.21916/mlr.2025.1. URL https://www.bls.gov/opub/mlr/2025/article/incorporating-ai-impacts-in-bls-employment-projections.htm. Accessed: 2026-03-11
-
[26]
Potemkin understanding in large language models, 2025
Marina Mancoridis, Bec Weeks, Keyon Vafa, and Sendhil Mullainathan. Potemkin understanding in large language models, 2025. URL https://arxiv.org/abs/2506.21521
-
[27]
Invisible failures in human-- AI interactions
Christopher Potts and Moritz Sudhof. Invisible failures in human-- AI interactions. arXiv:2603.15423, 2026. URL https://arxiv.org/abs/2603.15423
work page internal anchor Pith review arXiv 2026
-
[28]
Randrianasolo, Brett Becker, Bailey Kimmel, Jared Wright, and Ben Briggs
James Prather, Brent Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S. Randrianasolo, Brett Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. The widening gap: The benefits and harms of generative AI for novice programmers, 2024. URL https://arxiv.org/abs/2405.17739
-
[29]
How AI literacy shapes GenAI use
Maria Rosala. How AI literacy shapes GenAI use. Nielsen Norman Group, February 2026. URL https://www.nngroup.com/articles/ai-literacy/. Retrieved April 22, 2026
2026
-
[30]
Calibrated trust in dealing with LLM hallucinations: A qualitative study, 2025
Adrian Ryser, Florian Allwein, and Tim Schlippe. Calibrated trust in dealing with LLM hallucinations: A qualitative study, 2025. URL https://arxiv.org/abs/2512.09088
-
[31]
InThe F ourteenth International Conference on Learning Representations
Yijia Shao, Vinay Samuel, Yucheng Jiang, John Yang, and Diyi Yang. Collaborative Gym : A framework for enabling and evaluating human-agent collaboration, 2025. URL https://arxiv.org/abs/2412.15701
-
[32]
Future of work with AI agents: Auditing automation and augmentation potential across the U.S
Yijia Shao, Humishka Zope, Yucheng Jiang, Jiaxin Pei, David Nguyen, Erik Brynjolfsson, and Diyi Yang. Future of work with AI agents: Auditing automation and augmentation potential across the U.S. \ workforce, 2026. URL https://arxiv.org/abs/2506.06576
-
[33]
Polina Tsvilodub, Jan-Felix Klumpp, Amir Mohammadpour, Jennifer Hu, and Michael Franke. On Emergent Social World Models - Evidence for Functional Integration of Theory of Mind and Pragmatic Reasoning in Language Models . In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics, 2026. URL https://arxiv.org/abs/2602.10298
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan
Keyon Vafa, Justin Y. Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan. Evaluating the world model implicit in a generative model. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 26941--26975. Curran Associates, Inc., 2024. doi:10...
-
[35]
Chang, Ashesh Rambachan, and Sendhil Mullainathan
Keyon Vafa, Peter G. Chang, Ashesh Rambachan, and Sendhil Mullainathan. What has a foundation model found? Using inductive bias to probe for world models, 2025. URL https://arxiv.org/abs/2507.06952
-
[36]
2025 AI tools usage statistics: ChatGPT , Claude , Grok , Perplexity , DeepSeek & Gemini , 2025
Views4You . 2025 AI tools usage statistics: ChatGPT , Claude , Grok , Perplexity , DeepSeek & Gemini , 2025. URL https://views4you.com/ai-tools-usage-statistics-report-2025/. Accessed: 2026-03-07
2025
-
[37]
How do AI agents do human work? comparing AI and human workflows across diverse occupations
Zora Zhiruo Wang, Yijia Shao, Omar Shaikh, Daniel Fried, Graham Neubig, and Diyi Yang. How do AI agents do human work? comparing AI and human workflows across diverse occupations. arXiv preprint arXiv:2510.22780, 2025
-
[38]
Veith Weilnhammer, Kevin YC Hou, Lennart Luettgau, Christopher Summerfield, Raymond Dolan, and Matthew M Nour. Vulnerability-amplifying interaction loops: a systematic failure mode in AI chatbot mental-health interactions, 2026. URL https://arxiv.org/abs/2602.01347
-
[39]
Wenjia Yan, Yu li Liu, Valeriia Mamaeva, Fang Dong, Guannan Tao, Rubing Li, and Heng Yang. Generative AI literacy: Scale development and its influence on privacy protection behaviors and information verification behaviors. Telecommunications Policy, 50 0 (2): 0 103117, 2026. ISSN 0308-5961. doi:https://doi.org/10.1016/j.telpol.2025.103117. URL https://www...
-
[40]
WildChat : 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. WildChat : 1M ChatGPT interaction logs in the wild, 2024. URL https://arxiv.org/abs/2405.01470
-
[41]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[42]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[43]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[44]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.