Recognition: unknown
Learning Neural Operator Surrogates for the Black Hole Accretion Code
Pith reviewed 2026-05-07 15:24 UTC · model grok-4.3
The pith
Embedding the governing equations as a loss term at finer time steps lets a neural operator recover plasmoid formation in relativistic MHD from sparse data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
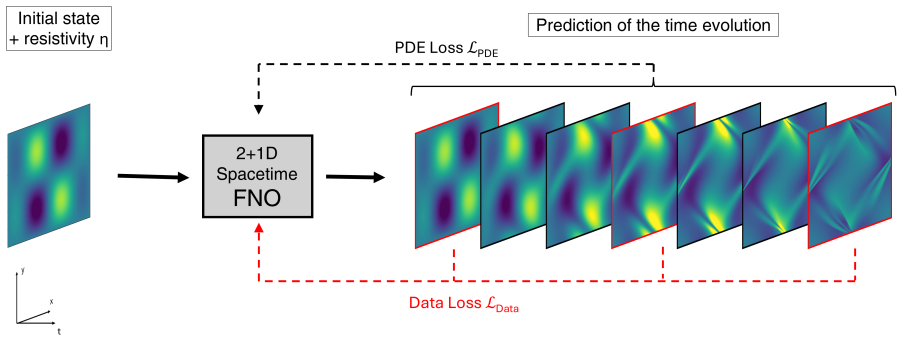
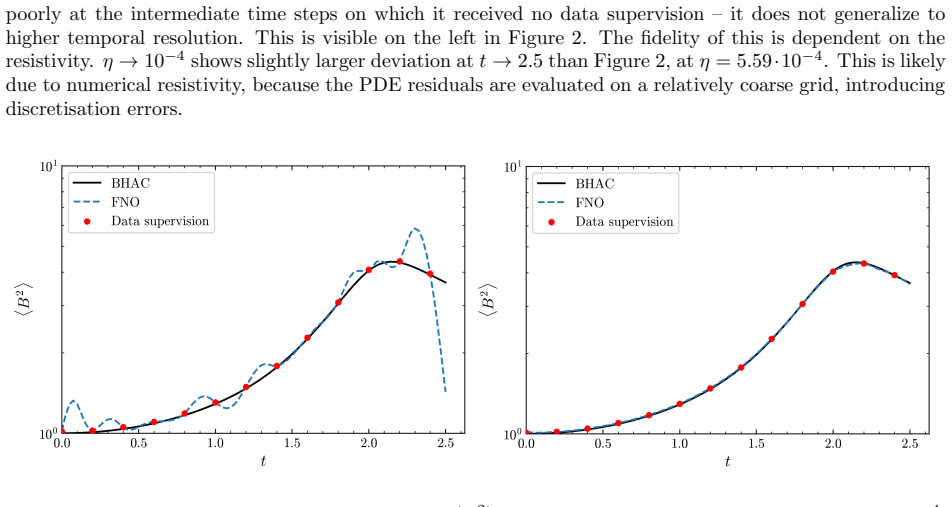
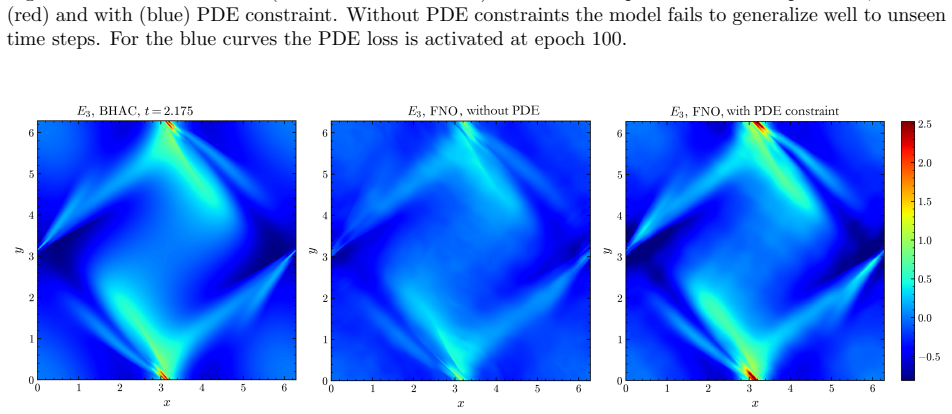
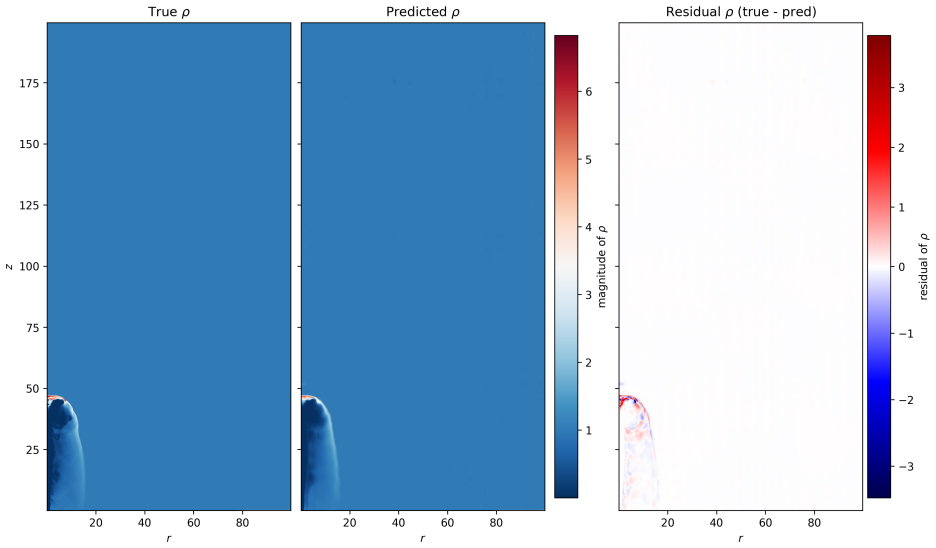
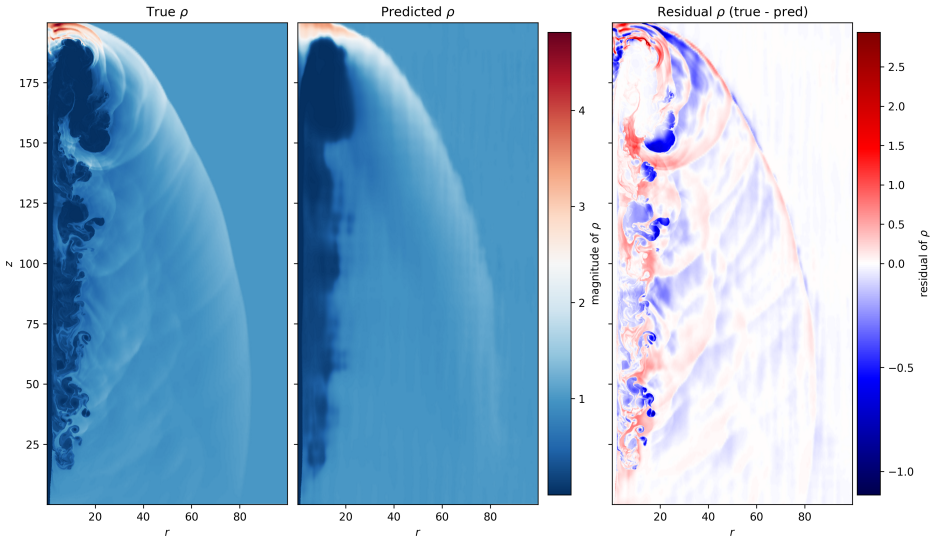
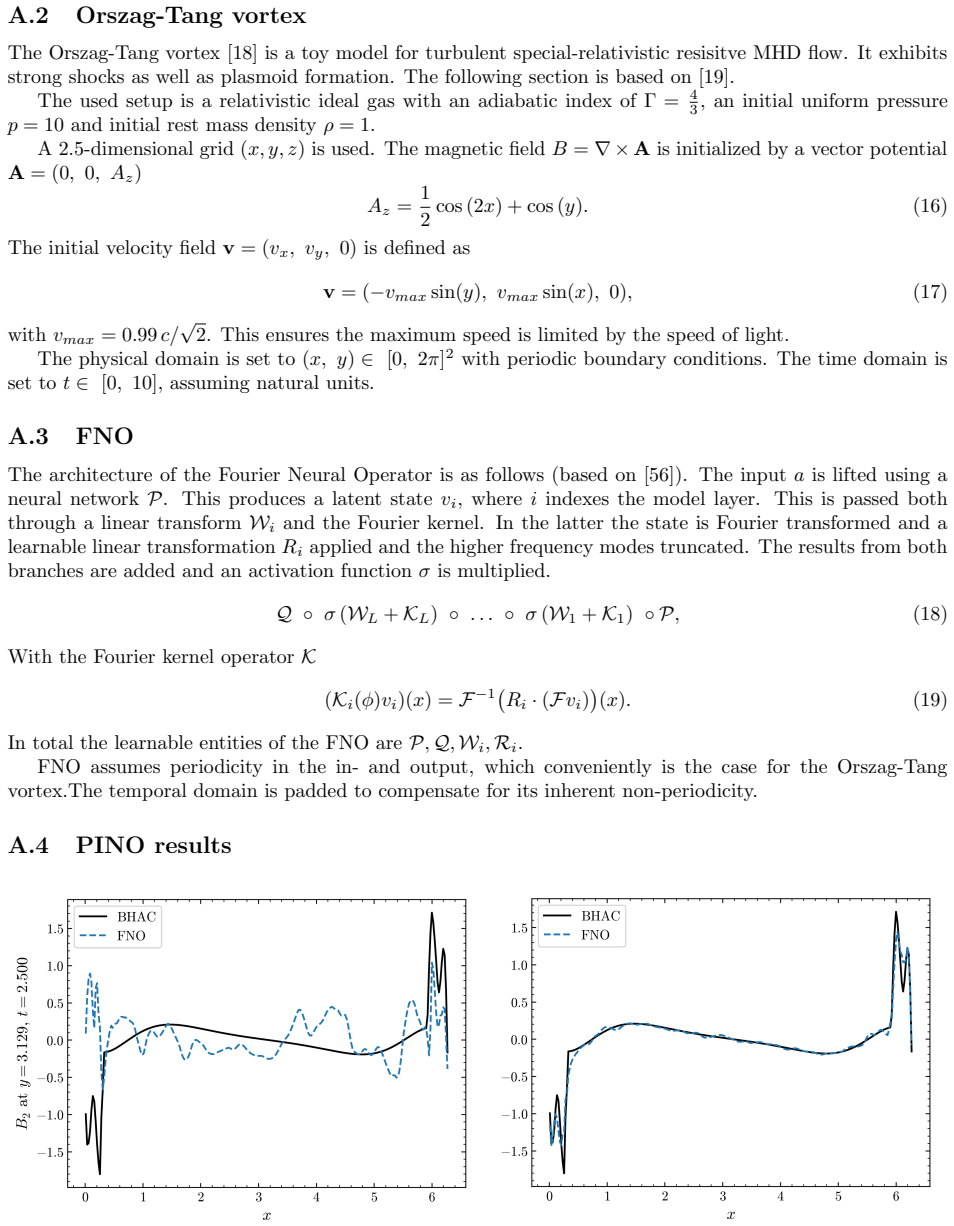
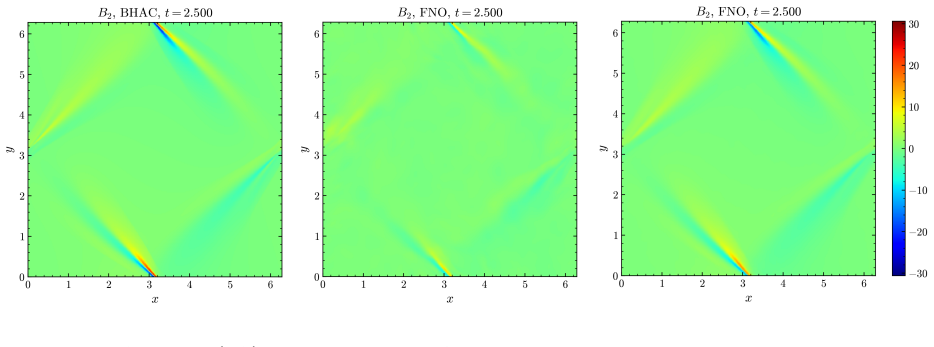
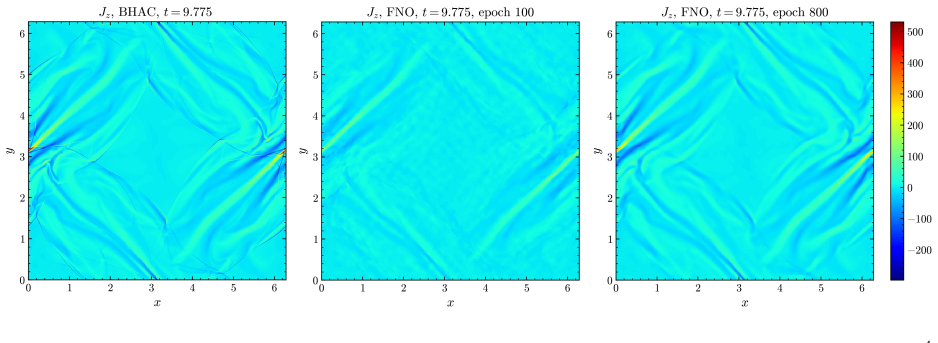
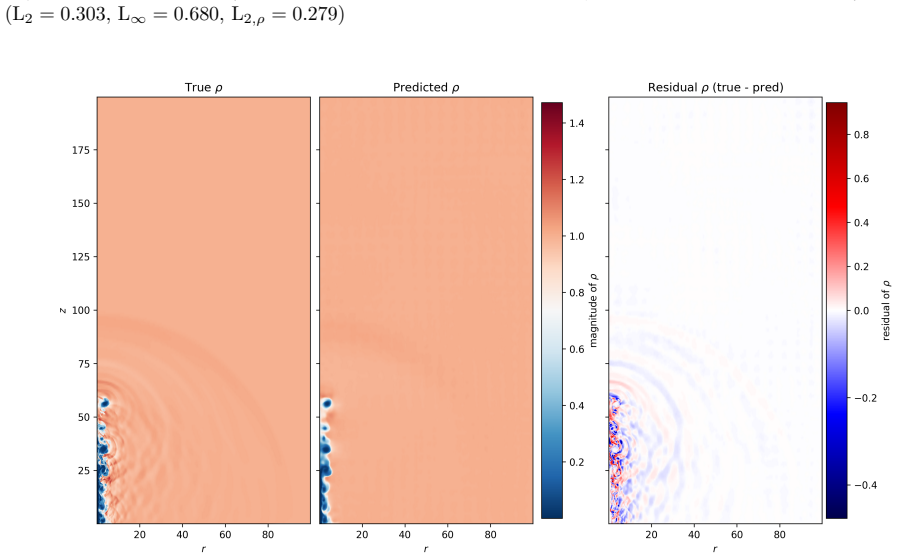
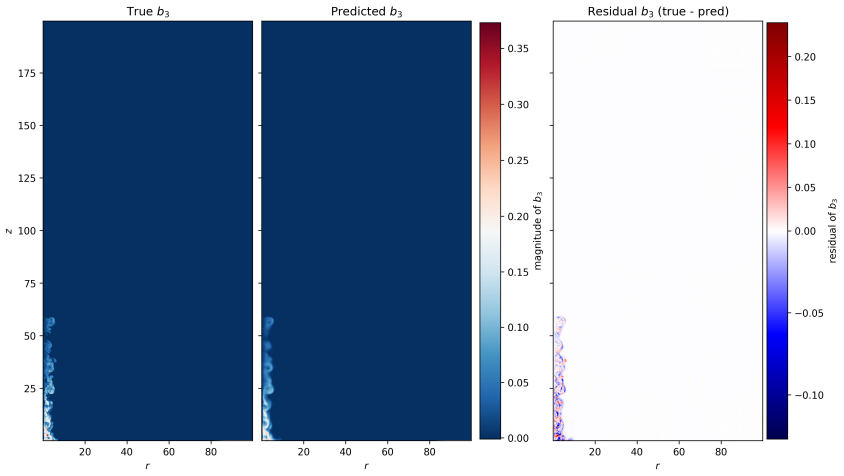
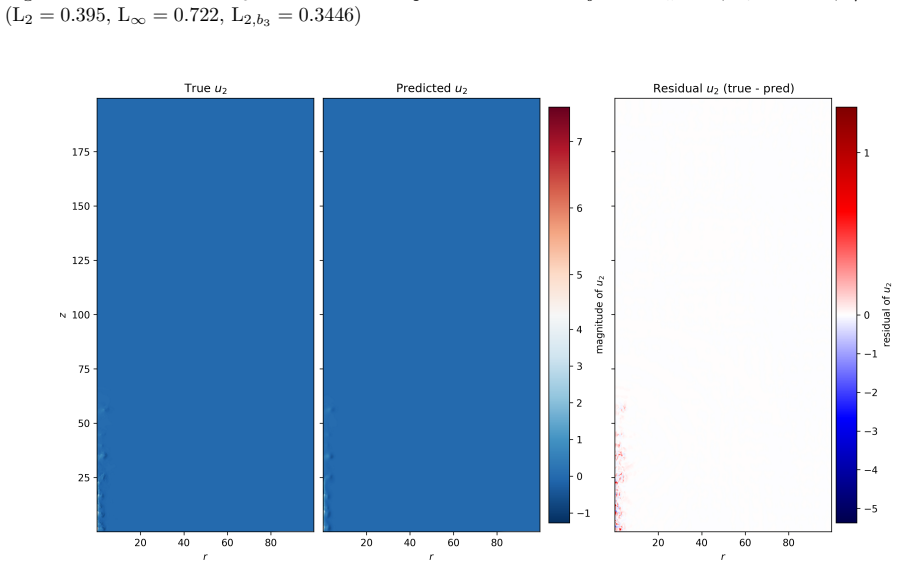
By training a Physics Informed Fourier Neural Operator on sparse snapshots of the Orszag-Tang vortex in special-relativistic resistive MHD while adding the governing equations as a loss term evaluated at finer time resolution, the surrogate learns to predict the formation of plasmoids that a data-only baseline cannot recover from the same data. This holds across a range of resistivities covering different reconnection regimes. Separately, an OFormer-style transformer neural operator applied directly to adaptive mesh refinement data from spine-sheath jet simulations reproduces major features of the evolution, particularly at early times.
What carries the argument
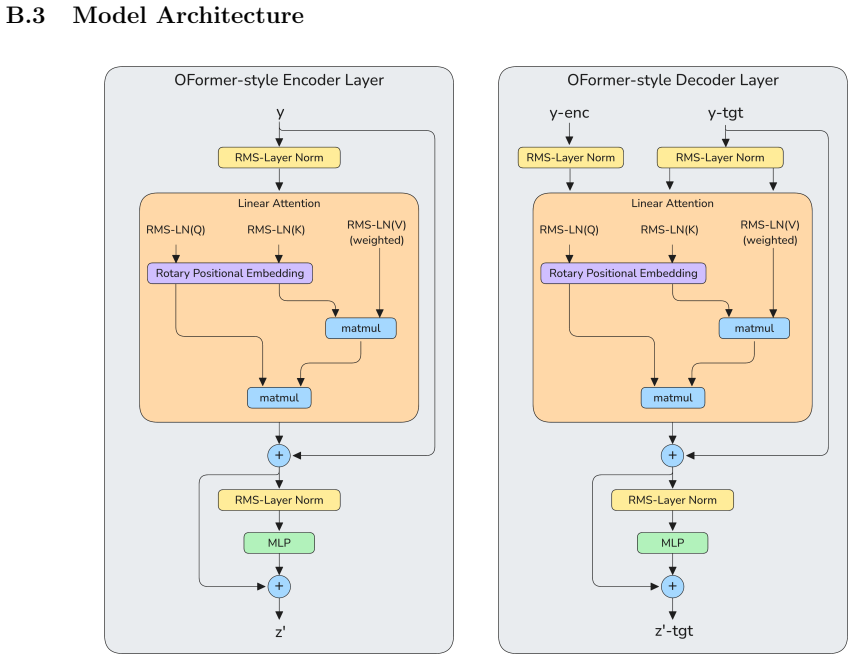
The physics-informed loss term from the SRRMHD equations evaluated at finer temporal resolution than the data supervision, which enables learning of intermediate dynamics.
Load-bearing premise
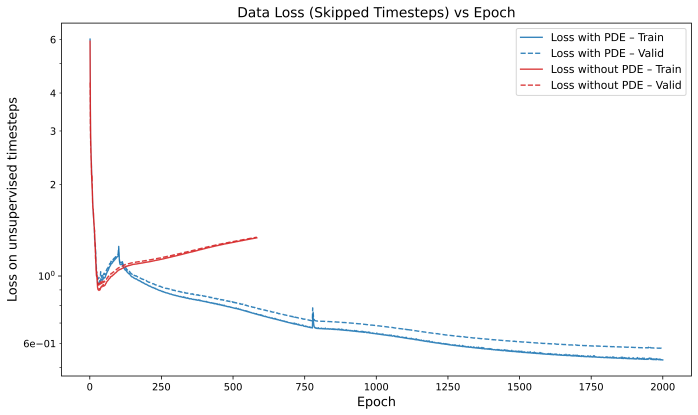
That enforcing the known equations at finer time steps is enough for the model to generalize to new resistivities and maintain accuracy over long times without extra constraints.
What would settle it
Running the trained PINO on a resistivity outside the training range and checking if it still correctly forms plasmoids as seen in a full simulation at that resistivity.
Figures



read the original abstract
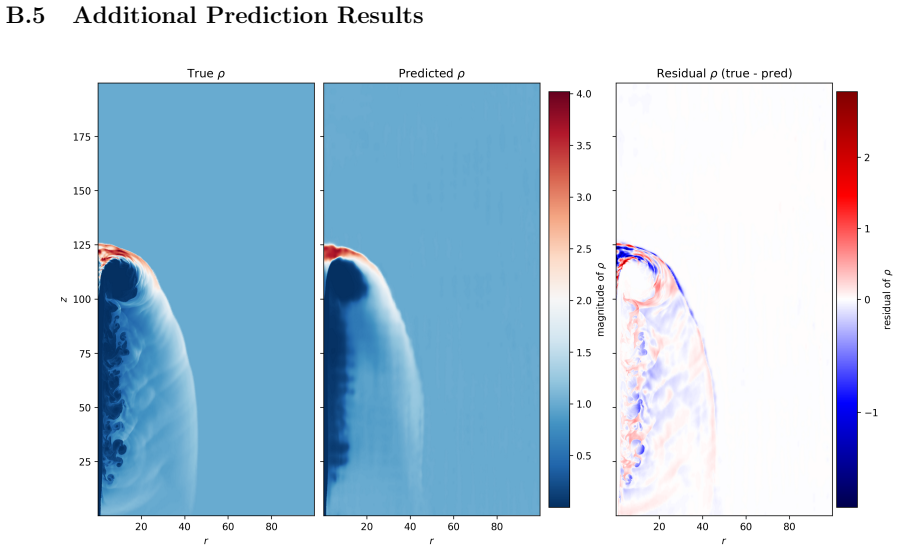
General-relativistic magnetohydrodynamic (GR-MHD) simulations are essential for studying black hole accretion, relativistic jets, and magnetic reconnection, yet their computational cost severely limits systematic parameter exploration. We investigate neural operator surrogates for two astrophysically relevant simulation scenarios produced by the Black Hole Accretion Code (\texttt{BHAC}). First, a Physics Informed Fourier Neural Operator (PINO) is trained on the special-relativistic resistive MHD (SRRMHD) evolution of the Orszag-Tang vortex over a range of resistivities spanning the Sweet-Parker and fast reconnection regimes. By embedding the governing equations as an additional loss term evaluated at finer temporal resolution than the available data supervision, the model learns dynamics at time steps where no simulation data is provided, enabling recovery of plasmoid formation that a data-only baseline trained on the same sparse snapshots fails to reproduce. To our knowledge, the present work is the first application of a physics informed neural operator to special relativistic resistive MHD, and the first to investigate the capability of such models to resolve plasmoid formation in SRRMHD. In a second line of investigation, an OFormer-style Transformer Neural Operator is trained on the evolution of spine-sheath relativistic jets created with \texttt{BHAC}, in special-relativistic MHD (SRMHD). The model is directly applied on the adaptive mesh, highlighting the need for linear attention due to long sequences. The neural surrogate model is capable of capturing most of the major details, especially in early predictions. To our knowledge, this constitutes the first application of a neural operator directly on a high resolution adaptive mesh refinement grid in the context of MHD simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces neural operator surrogates for black hole accretion simulations produced by the Black Hole Accretion Code (BHAC). A Physics-Informed Fourier Neural Operator (PINO) is trained on special-relativistic resistive MHD (SRRMHD) Orszag-Tang vortex evolution across a resistivity range, embedding the governing equations as a loss term evaluated at finer temporal resolution than the training snapshots; this is claimed to recover plasmoid formation that a data-only baseline fails to reproduce. Separately, an OFormer-style transformer neural operator is trained on spine-sheath relativistic jets in special-relativistic MHD (SRMHD) and applied directly on adaptive mesh refinement grids. The work positions itself as the first application of physics-informed neural operators to SRRMHD and the first neural operator on high-resolution AMR MHD grids.
Significance. If the central claims hold, the approach could substantially accelerate parameter studies of black hole accretion, jets, and magnetic reconnection by providing fast, physics-constrained surrogates that generalize beyond sparse training data. The explicit use of SRRMHD equations in the loss and the direct handling of AMR grids represent technical novelties that, if quantitatively validated, would strengthen the case for physics-informed neural operators in relativistic astrophysics.
major comments (3)
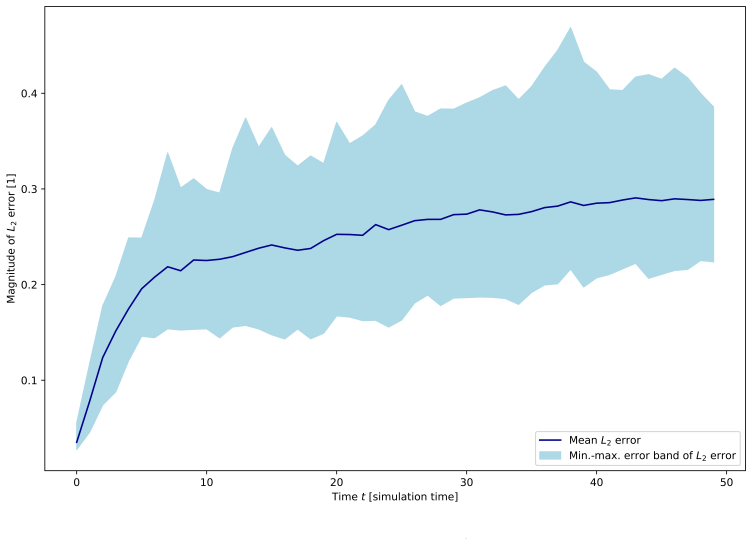
- [Abstract] Abstract: The claim that embedding the SRRMHD equations as a loss at finer temporal resolution enables recovery of plasmoid formation absent from the sparse snapshots is load-bearing for the central contribution, yet the abstract (and presumably the results section) supplies no quantitative metrics such as L2 residuals on the magnetic field, plasmoid growth rates, or long-horizon rollout errors relative to the data-only baseline or full BHAC runs. Without these, the superiority cannot be assessed and the weakest assumption (stable enforcement preventing error accumulation for unseen resistivities) remains untested.
- [Abstract] Abstract / Results (plasmoid section): Generalization to resistivities outside the training interval and autoregressive stability beyond the supervised horizon are asserted but not demonstrated; no ablation on resistivity range, no residual norms of the discrete SRRMHD equations at intermediate times, and no comparison of long-term evolution against reference simulations are reported. This directly affects whether the physics loss supplies sufficient inductive bias.
- [Abstract] Jet section: The statement that the OFormer 'captures most of the major details, especially in early predictions' on the AMR grid lacks supporting quantitative evidence (e.g., pointwise or integrated error norms, conservation diagnostics, or metrics at late times). Given the emphasis on linear attention for long sequences, the absence of sequence-length scaling or stability tests for extended rollouts is a load-bearing gap for the claimed applicability to realistic jet evolution.
minor comments (2)
- [Abstract] Notation for the resistivity parameter range and the precise form of the physics loss term should be defined explicitly (including how the finer temporal collocation points are chosen) to allow reproducibility.
- The manuscript should include a brief comparison to prior neural operator applications in MHD (e.g., standard FNO or DeepONet baselines) to clarify the incremental benefit of the physics-informed and AMR-specific choices.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. The comments highlight important gaps in quantitative validation that we agree need to be addressed to strengthen the manuscript. We respond point-by-point below and will incorporate all suggested additions in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that embedding the SRRMHD equations as a loss at finer temporal resolution enables recovery of plasmoid formation absent from the sparse snapshots is load-bearing for the central contribution, yet the abstract (and presumably the results section) supplies no quantitative metrics such as L2 residuals on the magnetic field, plasmoid growth rates, or long-horizon rollout errors relative to the data-only baseline or full BHAC runs. Without these, the superiority cannot be assessed and the weakest assumption (stable enforcement preventing error accumulation for unseen resistivities) remains untested.
Authors: We agree that quantitative metrics are essential to substantiate the superiority claim. In the revised manuscript we will add L2 residuals on the magnetic field, plasmoid growth rates, and long-horizon rollout errors relative to both the data-only baseline and full BHAC reference runs. These metrics will be presented in the results section and referenced from the abstract, directly addressing the stability of the physics-informed enforcement for unseen resistivities. revision: yes
-
Referee: [Abstract] Abstract / Results (plasmoid section): Generalization to resistivities outside the training interval and autoregressive stability beyond the supervised horizon are asserted but not demonstrated; no ablation on resistivity range, no residual norms of the discrete SRRMHD equations at intermediate times, and no comparison of long-term evolution against reference simulations are reported. This directly affects whether the physics loss supplies sufficient inductive bias.
Authors: We acknowledge that generalization and long-term stability require explicit demonstration. The revised version will include ablations on resistivity range, residual norms of the discrete SRRMHD equations evaluated at intermediate times, and side-by-side long-term evolution comparisons against reference BHAC simulations. These additions will quantify the inductive bias supplied by the physics loss term. revision: yes
-
Referee: [Abstract] Jet section: The statement that the OFormer 'captures most of the major details, especially in early predictions' on the AMR grid lacks supporting quantitative evidence (e.g., pointwise or integrated error norms, conservation diagnostics, or metrics at late times). Given the emphasis on linear attention for long sequences, the absence of sequence-length scaling or stability tests for extended rollouts is a load-bearing gap for the claimed applicability to realistic jet evolution.
Authors: We agree that the jet results require quantitative backing. The revised manuscript will report pointwise and integrated error norms, conservation diagnostics, and metrics at late times. We will additionally include sequence-length scaling behavior and stability tests for extended autoregressive rollouts to support applicability to realistic jet evolution. revision: yes
Circularity Check
No significant circularity; training uses external data plus independent known equations
full rationale
The paper trains PINO and Transformer neural operators on external BHAC simulation snapshots while adding the established SRRMHD/SRMHD governing equations as a physics loss evaluated at finer timesteps. This is not circular: the data supervision comes from independent numerical simulations, the physics loss encodes pre-existing PDEs rather than any fitted parameter or self-referential definition, and the claimed recovery of plasmoid formation is an empirical result of the combined loss rather than a reduction to the inputs by construction. No self-citation chains, uniqueness theorems, or renamed known results appear as load-bearing steps in the abstract or described methodology.
Axiom & Free-Parameter Ledger
free parameters (1)
- resistivity range
axioms (1)
- domain assumption The resistive MHD equations can be discretized and evaluated as a loss term at arbitrary time steps
Reference graph
Works this paper leans on
-
[2]
Event Horizon Telescope Collaboration et al. “First M87 Event Horizon Telescope Results. V. Physical Origin of the Asymmetric Ring”. In:apjl875.1, L5 (Apr. 2019), p. L5.doi:10.3847/2041- 8213/ ab0f43. arXiv:1906.11242 [astro-ph.GA]
-
[3]
O. Porth et al. “The Black Hole Accretion Code”. In:Computational Astrophysics and Cosmology4.1 (2017), p. 1.doi:10.1186/s40668- 017- 0020- 2.url:https://doi.org/10.1186/s40668- 017- 0020-2
-
[4]
H. Olivares et al. “Constrained transport and adaptive mesh refinement in the Black Hole Accretion Code”. In:Astronomy & Astrophysics629 (2019), A61.doi:10.1051/0004- 6361/201935559.url: https://doi.org/10.1051/0004-6361/201935559
-
[5]
B. Ripperda et al. “General-relativistic Resistive Magnetohydrodynamics with Robust Primitive-variable Recovery for Accretion Disk Simulations”. In:The Astrophysical Journal Supplement Series244.1 (2019), p. 10.doi:10.3847/1538-4365/ab3922.url:https://doi.org/10.3847/1538-4365/ab3922
work page doi:10.3847/1538-4365/ab3922.url:https://doi.org/10.3847/1538-4365/ab3922 2019
-
[6]
2019, ApJS, 243, 26, doi: 10.3847/1538-4365/ab29fd
Oliver Porth et al. “The Event Horizon General Relativistic Magnetohydrodynamic Code Comparison Project”. In:apjs243.2, 26 (Aug. 2019), p. 26.doi:10.3847/1538-4365/ab29fd. arXiv:1904.04923 [astro-ph.HE]
- [7]
-
[8]
Zongyi Li et al.Fourier Neural Operator for Parametric Partial Differential Equations. 2021. arXiv: 2010.08895 [cs.LG].url:https://arxiv.org/abs/2010.08895
work page internal anchor Pith review arXiv 2021
- [9]
-
[10]
Magnetohydrodynamics with physics informed neural operators
Shawn G Rosofsky and E A Huerta. “Magnetohydrodynamics with physics informed neural operators”. In:Machine Learning: Science and Technology4.3 (June 2023), p. 035002.doi:10 . 1088 / 2632 - 2153/ace30a.url:https://doi.org/10.1088/2632-2153/ace30a
- [11]
-
[12]
Parallel, grid-adaptive approaches for relativistic hydro and magnetohydrody- namics
Rony Keppens et al. “Parallel, grid-adaptive approaches for relativistic hydro and magnetohydrody- namics”. In:Journal of Computational Physics231.3 (2012), pp. 718–744
2012
-
[13]
MPI-AMRVAC for solar and astrophysics
O Porth et al. “MPI-AMRVAC for solar and astrophysics”. In:The Astrophysical Journal Supplement Series214.1 (2014), p. 4. 14
2014
-
[14]
A. Bormanis, C. A. Leon, and A. Scheinker. “Solving the Orszag–Tang vortex magnetohydrodynamics problem with physics-constrained convolutional neural networks”. In:Physics of Plasmas31.1 (Jan. 2024), p. 012101.issn: 1070-664X.doi:10 . 1063 / 5 . 0172075. eprint:https : / / pubs . aip . org / aip / pop / article - pdf / doi / 10 . 1063 / 5 . 0172075 / 1972...
-
[15]
Resolving turbulent magnetohydrodynamics: a hy- brid operator-diffusion framework
Semih Kacmaz, E A Huerta, and Roland Haas. “Resolving turbulent magnetohydrodynamics: a hy- brid operator-diffusion framework”. In:Machine Learning: Science and Technology6.3 (Sept. 2025), p. 035057.issn: 2632-2153.doi:10.1088/2632-2153/ae054c.url:http://dx.doi.org/10.1088/ 2632-2153/ae054c
work page doi:10.1088/2632-2153/ae054c.url:http://dx.doi.org/10.1088/ 2025
- [16]
- [17]
-
[18]
Small-scale structure of two-dimensional magnetohydrodynamic turbulence
Steven A. Orszag and Cha-Mei Tang. “Small-scale structure of two-dimensional magnetohydrodynamic turbulence”. In:Journal of Fluid Mechanics90.1 (1979), pp. 129–143.doi:10.1017/S002211207900210X
-
[19]
Magnetic Reconnection and Hot Spot Formation in Black Hole Accretion Disks
Bart Ripperda, Fabio Bacchini, and Alexander A. Philippov. “Magnetic Reconnection and Hot Spot Formation in Black Hole Accretion Disks”. In:The Astrophysical Journal900.2 (Sept. 2020), p. 100. issn: 1538-4357.doi:10 . 3847 / 1538 - 4357 / ababab.url:http : / / dx . doi . org / 10 . 3847 / 1538 - 4357/ababab
2020
-
[20]
Version 1.2.0
PhysicsNeMo Contributors.NVIDIA PhysicsNeMo: An open-source framework for physics-based deep learning in science and engineering. Version 1.2.0. Feb. 2023.url:https://github.com/NVIDIA/ physicsnemo
2023
- [21]
-
[22]
Jassem Abbasi et al. “Challenges and advancements in modeling shock fronts with physics-informed neu- ral networks: A review and benchmarking study”. In:Neurocomputing657 (2025), p. 131440.issn: 0925- 2312.doi:https://doi.org/10.1016/j.neucom.2025.131440.url:https://www.sciencedirect. com/science/article/pii/S0925231225021125
work page doi:10.1016/j.neucom.2025.131440.url:https://www.sciencedirect 2025
-
[23]
INTEGRAL PINNS FOR HYPERBOLIC CON- SERVATION LAWS
Manvendra P. Rajvanshi and David I Ketcheson. “INTEGRAL PINNS FOR HYPERBOLIC CON- SERVATION LAWS”. In:ICLR 2024 Workshop on AI4DifferentialEquations In Science. 2024.url: https://openreview.net/forum?id=Uuu6HWe6dF
2024
-
[24]
Kharma: Flexible, portable performance for grmhd
Ben S Prather. “Kharma: Flexible, portable performance for grmhd”. In:New Frontiers in GRMHD Simulations. Springer, 2025, pp. 167–201
2025
-
[25]
OpenFOAM: A C++ library for complex physics simulations
Hrvoje Jasak, Aleksandar Jemcov, Zeljko Tukovic, et al. “OpenFOAM: A C++ library for complex physics simulations”. In:International workshop on coupled methods in numerical dynamics. Vol. 1000. Dubrovnik, Croatia). 2007, pp. 1–20
2007
-
[26]
Dynamic mesh handling in OpenFOAM
Hrvoje Jasak. “Dynamic mesh handling in OpenFOAM”. In:47th AIAA aerospace sciences meeting including the new horizons forum and aerospace exposition. 2009, p. 341
2009
-
[27]
Spherical fourier neural operators: Learning stable dynamics on the sphere
Boris Bonev et al. “Spherical fourier neural operators: Learning stable dynamics on the sphere”. In: International conference on machine learning. PMLR. 2023, pp. 2806–2823
2023
-
[28]
Computing Fourier transforms and convolutions on the 2- sphere
James R Driscoll and Dennis M Healy. “Computing Fourier transforms and convolutions on the 2- sphere”. In:Advances in applied mathematics15.2 (1994), pp. 202–250
1994
-
[29]
Fourier neural operator with learned deformations for pdes on general geometries
Zongyi Li et al. “Fourier neural operator with learned deformations for pdes on general geometries”. In:Journal of Machine Learning Research24.388 (2023), pp. 1–26
2023
-
[30]
Zongyi Li et al. “Neural operator: Graph kernel network for partial differential equations”. In:arXiv preprint arXiv:2003.03485(2020). 15
-
[31]
The graph neural network model
Franco Scarselli et al. “The graph neural network model”. In:IEEE transactions on neural networks 20.1 (2008), pp. 61–80
2008
-
[32]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. “Semi-supervised classification with graph convolutional networks”. In:arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review arXiv 2016
-
[33]
Geometry-informed neural operator for large-scale 3d pdes
Zongyi Li et al. “Geometry-informed neural operator for large-scale 3d pdes”. In:Advances in Neural Information Processing Systems36 (2023), pp. 35836–35854
2023
-
[34]
¨Uber die praktische Aufl¨ osung von Integralgleichungen mit Anwendungen auf Randwertaufgaben
Evert J Nystr¨ om. “ ¨Uber die praktische Aufl¨ osung von Integralgleichungen mit Anwendungen auf Randwertaufgaben”. In:Acta Mathematica(1930)
1930
-
[35]
Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries,
Hang Zhou et al. “Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries”. In: arXiv preprint arXiv:2602.04940(2026)
-
[36]
Pretraining codomain attention neural operators for solving multiphysics pdes
Ashiqur Rahman et al. “Pretraining codomain attention neural operators for solving multiphysics pdes”. In:Advances in Neural Information Processing Systems37 (2024), pp. 104035–104064
2024
-
[37]
Continuum attention for neural operators
Edoardo Calvello et al. “Continuum attention for neural operators”. In:Journal of Machine Learning Research26.300 (2025), pp. 1–52
2025
-
[38]
Attention is all you need
Ashish Vaswani et al. “Attention is all you need”. In:Advances in neural information processing systems 30 (2017)
2017
-
[39]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy et al. “An image is worth 16x16 words: Transformers for image recognition at scale”. In:arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review arXiv 2010
-
[40]
Universal physics transformers: A framework for efficiently scaling neural oper- ators
Benedikt Alkin et al. “Universal physics transformers: A framework for efficiently scaling neural oper- ators”. In:Advances in Neural Information Processing Systems37 (2024), pp. 25152–25194
2024
-
[41]
Mesh-informed neural operator: A transformer generative approach
Yaozhong Shi et al. “Mesh-informed neural operator: A transformer generative approach”. In:arXiv preprint arXiv:2506.16656(2025)
-
[42]
Shizheng Wen et al. “Geometry aware operator transformer as an efficient and accurate neural surrogate for pdes on arbitrary domains”. In:arXiv preprint arXiv:2505.18781(2025)
-
[43]
Transolver: A Fast Transformer Solver for PDEs on General Geometries,
Haixu Wu et al. “Transolver: A fast transformer solver for pdes on general geometries”. In:arXiv preprint arXiv:2402.02366(2024)
-
[44]
Huakun Luo et al. “Transolver++: An accurate neural solver for pdes on million-scale geometries”. In: arXiv preprint arXiv:2502.02414(2025)
-
[45]
AMR-Transformer: enabling efficient long-range interaction for complex neural fluid sim- ulation
Zeyi Xu et al. “AMR-Transformer: enabling efficient long-range interaction for complex neural fluid sim- ulation”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 5804– 5813
2025
-
[46]
Choose a transformer: Fourier or galerkin
Shuhao Cao. “Choose a transformer: Fourier or galerkin”. In:Advances in neural information processing systems34 (2021), pp. 24924–24940
2021
-
[47]
Transformer for partial differential equations’ operator learning, 2023
Zijie Li, Kazem Meidani, and Amir Barati Farimani. “Transformer for partial differential equations’ operator learning”. In:arXiv preprint arXiv:2205.13671(2022)
-
[48]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. “Layer normalization”. In:arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review arXiv 2016
-
[49]
Principled approaches for extending neural architectures to function spaces for operator learning
Julius Berner et al. “Principled approaches for extending neural architectures to function spaces for operator learning”. In:arXiv preprint arXiv:2506.10973(2025)
-
[50]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. “Root mean square layer normalization”. In:Advances in neural infor- mation processing systems32 (2019)
2019
-
[51]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. “Gaussian error linear units (gelus)”. In:arXiv preprint arXiv:1606.08415 (2016)
work page internal anchor Pith review arXiv 2016
-
[52]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su et al. “Roformer: Enhanced transformer with rotary position embedding”. In:Neurocomput- ing568 (2024), p. 127063
2024
-
[53]
Neural operator: Learning maps between function spaces with applications to pdes
Nikola Kovachki et al. “Neural operator: Learning maps between function spaces with applications to pdes”. In:Journal of Machine Learning Research24.89 (2023), pp. 1–97. 16
2023
-
[54]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. “Decoupled weight decay regularization”. In:arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review arXiv 2017
-
[55]
Serguei S. Komissarov. “Multidimensional numerical scheme for resistive relativistic magnetohydrody- namics: Multidimensional numerical scheme for resistive relativistic MHD”. In:Monthly Notices of the Royal Astronomical Society382.3 (Nov. 2007), pp. 995–1004.issn: 0035-8711.doi:10.1111/j.1365- 2966.2007.12448.x.url:http://dx.doi.org/10.1111/j.1365-2966.2...
- [56]
-
[57]
Stationary relativistic jets
Serguei S Komissarov, Oliver Porth, and Maxim Lyutikov. “Stationary relativistic jets”. In:Computa- tional astrophysics and cosmology2.1 (2015), p. 9
2015
-
[58]
Radiative signatures of Parsec-Scale magnetised jets
Christian M Fromm et al. “Radiative signatures of Parsec-Scale magnetised jets”. In:Galaxies5.4 (2017), p. 73. Appendix A Details about the PINO for resistive SRMHD A.1 Special-Relativistic Resistive MHD equations Maxwell’s equations ∇ ·B= 0 (4) ∂tB+∇ ×E= 0 (5) ∇ ·E=q(6) −∂tE+∇ ×B=J(7) Ohm’s law in the general inertial frame is given by J= γ η [E+v×B−(E·v...
2017
-
[59]
The physical domain is set to (x, y)∈[0,2π] 2 with periodic boundary conditions
This ensures the maximum speed is limited by the speed of light. The physical domain is set to (x, y)∈[0,2π] 2 with periodic boundary conditions. The time domain is set tot∈[0,10], assuming natural units. A.3 FNO The architecture of the Fourier Neural Operator is as follows (based on [56]). The inputais lifted using a neural networkP. This produces a late...
2091
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.