Recognition: unknown
BioGraphletQA: Knowledge-Anchored Generation of Complex QA Datasets
Pith reviewed 2026-05-07 16:22 UTC · model grok-4.3
The pith
Using small knowledge-graph subgraphs to anchor prompts lets large language models create large sets of complex QA data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
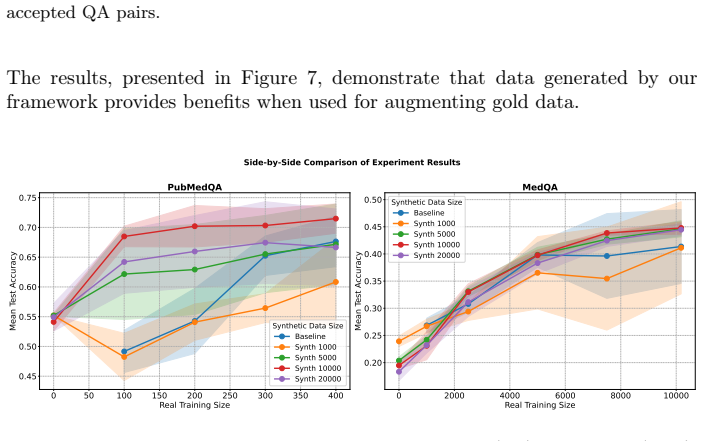
The central discovery is that a generation process anchored in small subgraphs from a knowledge graph can be used to direct large language models toward producing complex QA pairs that retain factual accuracy and appropriate difficulty. When applied, this yields a large collection of such pairs, whose quality is supported by domain expert assessment of a sample and by the observation that models trained with the addition of these pairs achieve higher accuracy on biomedical QA tasks.
What carries the argument
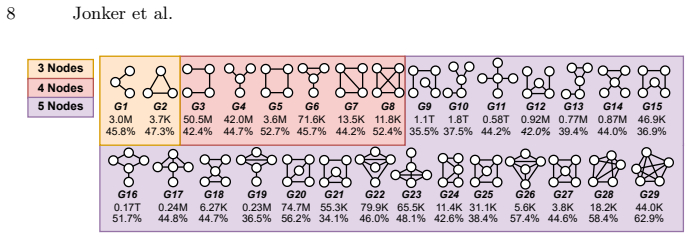
The graphlet-anchored generation process, defined as using small subgraphs of up to five nodes from a knowledge graph in structured prompts to control complexity and ensure factual grounding of generated questions.
If this is right
- Augmenting training data with the generated QA pairs increases accuracy on biomedical QA tasks in low-resource settings from 49.2% to 68.5% and in full-resource settings from 41.4% to 44.8%.
- The process scales to produce 119,856 QA pairs while preserving the desired properties.
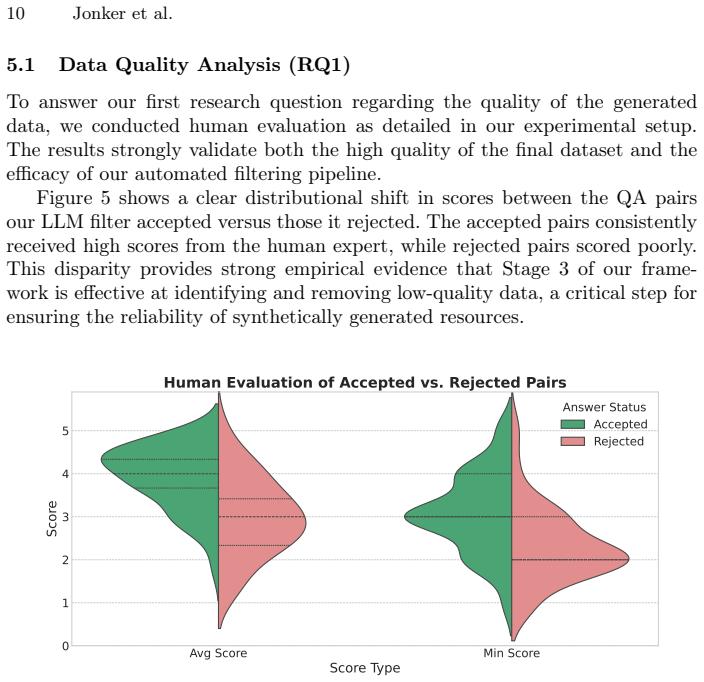
- Evaluation by a domain expert on a sample of 106 pairs confirms high scientific validity and complexity.
Where Pith is reading between the lines
- Similar subgraph-anchoring techniques could be applied in other knowledge-intensive domains to generate tailored QA datasets.
- This method might help mitigate the challenges of data scarcity for training models on complex reasoning by providing a structured way to synthesize examples.
- Extending the framework to include more types of graph structures or different large language models could further improve the diversity and utility of the generated data.
Load-bearing premise
That the use of small knowledge-graph subgraphs in prompts will continue to produce questions with preserved factual grounding and complexity when generating a full dataset of over one hundred thousand pairs, and that a review of just over one hundred samples is sufficient to represent the quality of the whole.
What would settle it
Finding that a larger sample of the generated QA pairs contains many factual errors or lacks the claimed complexity, or that augmenting models with this data fails to improve or even decreases performance on independent QA benchmarks.
Figures




read the original abstract
This paper presents a principled and scalable framework for systematically generating complex Question Answering (QA) data. In the core of this framework is a graphlet-anchored generation process, where small subgraphs from a Knowledge Graph (KG) are used in a structured prompt to control the complexity and ensure the factual grounding of questions generated by Large Language Models. The first instantiation of this framework is BioGraphletQA, a new biomedical KGQA dataset of 119,856 QA pairs. Each entry is grounded in a graphlet of up to five nodes from the OREGANO KG, with most of the pairs being enriched with relevant document snippets from PubMed. We start by demonstrating the framework's value and the dataset's quality through evaluation by a domain expert on 106 QA pairs, confirming the high scientific validity and complexity of the generated data. Secondly, we establish its practical utility by showing that augmenting downstream benchmarks with our data improves accuracy on PubMedQA from 49.2% to 68.5% in a low-resource setting, and on MedQA from a 41.4% baseline to 44.8% in a full-resource setting. Our framework provides a robust and generalizable solution for creating critical resources to advance complex QA tasks, including MCQA and KGQA. All resources supporting this work, including the dataset (https://zenodo.org/records/17381119) and framework code (https://github.com/ieeta-pt/BioGraphletQA), are publicly available to facilitate use, reproducibility and extension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a graphlet-anchored framework for generating complex QA datasets from knowledge graphs. Its primary instantiation, BioGraphletQA, consists of 119,856 biomedical QA pairs derived from subgraphs of up to five nodes in the OREGANO KG, with most pairs augmented by PubMed snippets. Quality is supported by domain-expert review of 106 pairs confirming scientific validity and complexity; utility is shown via downstream augmentation experiments that raise PubMedQA accuracy from 49.2% to 68.5% (low-resource) and MedQA from 41.4% to 44.8% (full-resource). Code and data are released publicly.
Significance. If the generation process preserves factual grounding and complexity at scale, the work supplies a reproducible, extensible resource for complex biomedical QA that could improve training of models on multi-hop and factually anchored reasoning. The public Zenodo dataset and GitHub framework code are explicit strengths that enable direct reuse and extension beyond biomedicine.
major comments (2)
- [Evaluation / expert review] Expert validation is reported only on 106 pairs (abstract and evaluation section). No selection protocol, stratification by graphlet size, or power analysis is described, so it is unclear whether the observed high validity generalizes to the full 119,856 pairs, especially for larger graphlets where incomplete grounding or LLM inconsistencies could be more prevalent.
- [Method / graphlet-anchored generation] The generation pipeline (method section) supplies no concrete prompt templates, graphlet sampling procedure, or hallucination-mitigation steps. Without these, the central claim that graphlet anchoring reliably controls complexity and factual grounding cannot be independently verified or reproduced from the manuscript alone.
minor comments (2)
- [Abstract] The abstract states that 'most' pairs are enriched with PubMed snippets but does not report the exact fraction or the enrichment procedure.
- [Experiments] Downstream experiment details (e.g., how BioGraphletQA pairs are mixed with original training data, exact model checkpoints, and hyper-parameter settings) are referenced only at high level; a table or appendix listing these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that enhance the clarity, reproducibility, and transparency of the work without altering its core contributions.
read point-by-point responses
-
Referee: [Evaluation / expert review] Expert validation is reported only on 106 pairs (abstract and evaluation section). No selection protocol, stratification by graphlet size, or power analysis is described, so it is unclear whether the observed high validity generalizes to the full 119,856 pairs, especially for larger graphlets where incomplete grounding or LLM inconsistencies could be more prevalent.
Authors: We agree that the manuscript would benefit from greater detail on the expert validation process. The 106 pairs were chosen via stratified random sampling across graphlet sizes (1–5 nodes) to ensure representation of varying complexities; we will explicitly document this protocol, the expert assessment criteria, and the exact validity results in the revised evaluation section. A formal statistical power analysis was not performed, as expert review is resource-intensive, but we will add a limitations paragraph acknowledging that the sample size limits strong claims of generalization to the full dataset, particularly for 5-node graphlets. The downstream benchmark gains provide complementary evidence of utility at scale, and we will emphasize this as supporting (rather than definitive) validation. revision: yes
-
Referee: [Method / graphlet-anchored generation] The generation pipeline (method section) supplies no concrete prompt templates, graphlet sampling procedure, or hallucination-mitigation steps. Without these, the central claim that graphlet anchoring reliably controls complexity and factual grounding cannot be independently verified or reproduced from the manuscript alone.
Authors: We acknowledge that the method section lacks the concrete implementation details needed for standalone reproduction. The full graphlet sampling logic, prompt templates, and hallucination-mitigation steps (KG verification plus PubMed snippet grounding) are present in the released code at https://github.com/ieeta-pt/BioGraphletQA. To make the manuscript self-contained, we will insert the key prompt templates, a precise description of the sampling procedure, and the mitigation steps into a new appendix in the revised version. This will enable verification directly from the paper while retaining the open-source repository for executable code. revision: yes
Circularity Check
No circularity: empirical dataset construction without derivation chain
full rationale
The paper presents a constructive framework for generating QA pairs by anchoring LLM prompts to small subgraphs (graphlets) extracted from the OREGANO KG, producing the BioGraphletQA dataset of 119,856 pairs. Quality is checked by domain-expert review of 106 samples and utility is measured by empirical augmentation experiments on PubMedQA (49.2% to 68.5%) and MedQA (41.4% to 44.8%). No equations, fitted parameters, self-referential definitions, or first-principles derivations appear; the generation process is a procedural pipeline whose outputs are tested against external benchmarks and human judgment rather than reduced to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing justification for the central claims. The work is therefore self-contained as an empirical resource-creation effort.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs remain factually consistent with the provided graphlet when prompted appropriately
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.13351 (2023)
Banerjee, D., Awale, S., Usbeck, R., Biemann, C.: Dblp-quad: A question answering dataset over the dblp scholarly knowledge graph. arXiv preprint arXiv:2303.13351 (2023)
-
[2]
In: Matsumoto, Y., Prasad, R
Bao, J., Duan, N., Yan, Z., Zhou, M., Zhao, T.: Constraint-based question an- swering with knowledge graph. In: Matsumoto, Y., Prasad, R. (eds.) Proceedings of COLING 2016, the 26th International Conference on Computational Linguis- tics: Technical Papers. pp. 2503–2514. The COLING 2016 Organizing Committee, Osaka, Japan (Dec 2016), https://aclanthology.o...
2016
-
[3]
In: Proceedings of the 2008 ACM SIGMOD international conference on Management of data
Bollacker, K., Evans, C., Paritosh, P., Sturge, T., Taylor, J.: Freebase: a collabo- ratively created graph database for structuring human knowledge. In: Proceedings of the 2008 ACM SIGMOD international conference on Management of data. pp. 1247–1250 (2008)
2008
-
[4]
Scientific data10(1), 871 (2023)
Boudin, M., Diallo, G., Drancé, M., Mougin, F.: The oregano knowledge graph for computational drug repurposing. Scientific data10(1), 871 (2023)
2023
-
[5]
arXiv preprint arXiv:2410.22182 (2024)
Braga, M., Kasela, P., Raganato, A., Pasi, G.: Synthetic data generation with large language models for personalized community question answering. arXiv preprint arXiv:2410.22182 (2024)
-
[6]
Nature Scientific Data (2023)
Chandak, P., Huang, K., Zitnik, M.: Building a knowledge graph to en- able precision medicine. Nature Scientific Data (2023). https://doi.org/10.1038/ s41597-023-01960-3
2023
-
[7]
In: The Semantic Web– ISWC2019:18thInternationalSemanticWebConference,Auckland,NewZealand, October 26–30, 2019, Proceedings, Part II 18
Dubey, M., Banerjee, D., Abdelkawi, A., Lehmann, J.: Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia. In: The Semantic Web– ISWC2019:18thInternationalSemanticWebConference,Auckland,NewZealand, October 26–30, 2019, Proceedings, Part II 18. pp. 69–78. Springer (2019)
2019
-
[8]
In: Proceedings of the 13th IJCNLP
Dutt, R., Khosla, S., Kumar, V.B., Gangadharaiah, R.: Grailqa++: A challenging zero-shot benchmark for knowledge base question answering. In: Proceedings of the 13th IJCNLP. pp. 897–909 (2023)
2023
-
[9]
In: Proceedings of the Web Conference 2021
Gu, Y., Kase, S., Vanni, M., Sadler, B., Liang, P., Yan, X., Su, Y.: Beyond iid: three levels of generalization for question answering on knowledge bases. In: Proceedings of the Web Conference 2021. pp. 3477–3488 (2021)
2021
-
[10]
Haas, R.: A survey of biomedical knowledge graphs and of resources for their construction (February 6 2024), https://robert-haas.github.io/ awesome-biomedical-knowledge-graphs/
2024
-
[11]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., Liu, T.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst.43(2) (Jan 2025). https://doi.org/10.1145/3703155
-
[12]
Survey of hallucination in natural language generation,
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM Comput. Surv.55(12) (Mar 2023). https://doi.org/10.1145/3571730
-
[13]
Jiang, L., Usbeck, R.: Knowledge graph question answering datasets and their generalizability: Are they enough for future research? In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Informa- tion Retrieval. pp. 3209–3218 (2022) 14 Jonker et al
2022
- [14]
-
[15]
Pub- MedQA: A dataset for biomedical research question answering
Jin,Q.,Dhingra,B.,Liu,Z.,Cohen,W.,Lu,X.:PubMedQA:Adatasetforbiomed- ical research question answering. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP). pp. 2567–2577. Association f...
-
[16]
arXiv preprint arXiv:2404.09163 (2024)
Namboori, A., Mangale, S., Rosenbaum, A., Soltan, S.: Gemquad: Generating mul- tilingual question answering datasets from large language models using few shot learning. arXiv preprint arXiv:2404.09163 (2024)
-
[17]
Peixoto, T.P.: The graph-tool python library. figshare (2014). https://doi.org/10. 6084/m9.figshare.1164194, http://figshare.com/articles/graph_tool/1164194
-
[18]
In: Dernon- court, F., Preoţiuc-Pietro, D., Shimorina, A
Pradeep, R., Lee, D., Mousavi, A., Pound, J., Sang, Y., Lin, J., Ilyas, I., Potdar, S., Arefiyan, M., Li, Y.: ConvKGYarn: Spinning configurable and scalable conver- sational knowledge graph QA datasets with large language models. In: Dernon- court, F., Preoţiuc-Pietro, D., Shimorina, A. (eds.) Proceedings of the 2024 Con- ference on Empirical Methods in N...
-
[19]
Nucleic Acids Research52(D1), D938–D949 (11 2023)
Putman, T.E., Schaper, K., Matentzoglu, N., Rubinetti, V., Alquaddoomi, F., Cox, C., Caufield, J.H., Elsarboukh, G., Gehrke, S., Hegde, H., Reese, J., Braun, I., Bruskiewich, R., Cappelletti, L., Carbon, S., Caron, A., Chan, L., Chute, C., Cortes, K., De Souza, V., Fontana, T., Harris, N., Hartley, E., Hurwitz, E., Jacob- sen, J.B., Krishnamurthy, M., Lar...
-
[20]
ACM computing surveys (csur)54(2), 1–36 (2021)
Ribeiro, P., Paredes, P., Silva, M.E., Aparicio, D., Silva, F.: A survey on subgraph counting: concepts, algorithms, and applications to network motifs and graphlets. ACM computing surveys (csur)54(2), 1–36 (2021)
2021
-
[21]
Foundations and Trends®in Information Retrieval3(4), 333–389 (2009)
Robertson, S., Zaragoza, H., et al.: The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends®in Information Retrieval3(4), 333–389 (2009)
2009
-
[22]
Nature biotechnology40(5), 692–702 (2022)
Santos, A., Colaço, A.R., Nielsen, A.B., Niu, L., Strauss, M., Geyer, P.E., Coscia, F., Albrechtsen, N.J.W., Mundt, F., Jensen, L.J., et al.: A knowledge graph to interpret clinical proteomics data. Nature biotechnology40(5), 692–702 (2022)
2022
-
[23]
Nucleic Acids Research49(D1), D10–D17 (10 2020)
Sayers, E.W., Beck, J., Bolton, E.E., Bourexis, D., Brister, J.R., Canese, K., Comeau, D.C., Funk, K., Kim, S., Klimke, W., Marchler-Bauer, A., Landrum, M., Lathrop, S., Lu, Z., Madden, T.L., O’Leary, N., Phan, L., Rangwala, S.H., Schneider, V.A., Skripchenko, Y., Wang, J., Ye, J., Trawick, B.W., Pruitt, K.D., Sherry, S.T.: Database resources of the natio...
- [24]
-
[25]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30 (2017)
2017
-
[26]
Com- munications of the ACM57(10), 78–85 (2014)
Vrandečić, D., Krötzsch, M.: Wikidata: a free collaborative knowledgebase. Com- munications of the ACM57(10), 78–85 (2014)
2014
-
[27]
IEEE/ACM Transactions on Computational Biology and Bioinformatics3(4), 347–359 (2006)
Wernicke, S.: Efficient detection of network motifs. IEEE/ACM Transactions on Computational Biology and Bioinformatics3(4), 347–359 (2006). https://doi.org/ 10.1109/TCBB.2006.51
-
[28]
arXiv preprint arXiv:2407.02233 (2024)
Wu, I., Jayanthi, S., Viswanathan, V., Rosenberg, S., Pakazad, S., Wu, T., Neubig, G.: Synthetic multimodal question generation. arXiv preprint arXiv:2407.02233 (2024)
- [29]
-
[30]
In: ECAI 2024, pp
Yan, X., Westphal, P., Seliger, J., Usbeck, R.: Bridging the gap: Generating a comprehensive biomedical knowledge graph question answering dataset. In: ECAI 2024, pp. 1198–1205. IOS Press (2024)
2024
-
[31]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review arXiv 2025
-
[32]
In: Association for Computational Linguistics (ACL) (2022)
Yasunaga, M., Leskovec, J., Liang, P.: Linkbert: Pretraining language models with document links. In: Association for Computational Linguistics (ACL) (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.