Recognition: unknown
Incremental Strongly Connected Components with Predictions
Pith reviewed 2026-05-07 14:45 UTC · model grok-4.3
The pith
An incremental SCC algorithm uses a predicted edge sequence to precompute partial solutions for fast updates that degrade smoothly with prediction errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The algorithm receives a possibly erroneous prediction of the edge insertion sequence and uses it to precompute partial solutions to support fast inserts. It achieves nearly optimal bounds with good predictions and its performance smoothly degrades with the prediction error. The data structure was also implemented and tested on real datasets, where the theory correctly predicted practical runtime improvements.
What carries the argument
Prediction-guided precomputation of partial SCC solutions that accelerates individual edge insertions.
If this is right
- Accurate predictions yield update times approaching the information-theoretic optimum for the sequence.
- The runtime bound varies continuously with a natural measure of prediction error.
- The same precomputation technique supports the standard model in which the entire sequence is predicted at the start.
- Empirical runtimes on real graphs track the theoretical improvement curves.
Where Pith is reading between the lines
- The same prediction style could be tried on other incremental graph problems such as connectivity or transitive closure.
- Even coarse ML forecasts of edge order may still be worth exploiting if precomputation overhead stays modest.
- Streaming applications with partially predictable edge arrival patterns offer a natural testbed for the structure.
Load-bearing premise
A usable prediction of the full edge insertion sequence is supplied in advance and its precomputation cost is offset by later speedups.
What would settle it
Measure per-insertion time when the supplied prediction is completely random or reversed; if times then match or exceed those of a standard non-predictive incremental SCC algorithm, the claimed benefit does not hold.
Figures

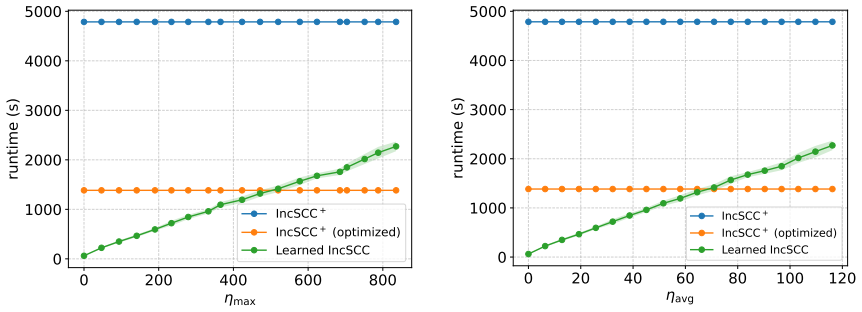

read the original abstract
Algorithms with predictions is a growing area that aims to leverage machine-learned predictions to design faster beyond-worst-case algorithms. In this paper, we use this framework to design a learned data structure for the incremental strongly connected components (SCC) problem. In this problem, the $n$ vertices of a graph are known a priori and the $m$ directed edges arrive over time. The goal is to efficiently maintain the strongly connected components of the graph after each insert. Our algorithm receives a possibly erroneous prediction of the edge sequence and uses it to precompute partial solutions to support fast inserts. We show that our algorithm achieves nearly optimal bounds with good predictions and its performance smoothly degrades with the prediction error. We also implement our data structure and perform experiments on real datasets. Our empirical results show that the theory is predictive of practical runtime improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a data structure for the incremental strongly connected components (SCC) problem on a directed graph with n known vertices and m edges arriving online. It receives a (possibly erroneous) prediction of the full edge-insertion sequence, uses it to precompute partial SCC information, and supports fast updates that are nearly optimal when the prediction is accurate and degrade smoothly with prediction error. Theoretical bounds are claimed, an implementation is described, and experiments on real datasets are reported to show practical runtime improvements.
Significance. If the stated bounds hold and the degradation property is tight, the work meaningfully extends the algorithms-with-predictions model to a canonical dynamic-graph problem with clear applications in network analysis and databases. The combination of a clean theoretical guarantee with empirical validation on real data is a strength; reproducible code or machine-checked proofs would further increase impact.
major comments (2)
- [§4.2, Theorem 4.1] §4.2, Theorem 4.1: the claimed 'nearly optimal' update time with perfect predictions is stated relative to an unspecified baseline; the proof sketch must explicitly compare against the best known worst-case incremental SCC bound (e.g., the O(m^{1/2} polylog n) or O(log n) per update results) and show that the precomputation overhead is amortized to o(1) per insertion.
- [§5, Definition 5.1 and Lemma 5.3] §5, Definition 5.1 and Lemma 5.3: the prediction-error measure (number of misordered edges or Kendall-tau distance) is used to bound the number of 'recomputed' components, but the analysis appears to assume that the error is known at preprocessing time; it is unclear how the algorithm detects or adapts to the actual error without additional logarithmic factors.
minor comments (3)
- [§6] The experimental section should report the exact prediction model used (e.g., how the 'predicted sequence' is generated from real data) and include a baseline that ignores the prediction entirely.
- [§3] Notation for the error parameter ε is introduced in the abstract but first defined only in §3; a forward reference or early definition would improve readability.
- [§2] Missing citation to the classic incremental SCC algorithms of Tarjan or the more recent dynamic connectivity results that the 'nearly optimal' claim is measured against.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and the constructive comments. We address the two major comments point by point below. Both points can be resolved with clarifications that we will incorporate in a minor revision.
read point-by-point responses
-
Referee: [§4.2, Theorem 4.1] the claimed 'nearly optimal' update time with perfect predictions is stated relative to an unspecified baseline; the proof sketch must explicitly compare against the best known worst-case incremental SCC bound (e.g., the O(m^{1/2} polylog n) or O(log n) per update results) and show that the precomputation overhead is amortized to o(1) per insertion.
Authors: We agree that an explicit comparison to the best-known unconditional worst-case bounds is needed for clarity. In the revised manuscript we will expand the discussion surrounding Theorem 4.1 to state the baseline explicitly and to show that, under perfect predictions, our per-update cost is asymptotically superior to the O(m^{1/2} polylog n) bound while the O(m log n) precomputation amortizes to o(1) per insertion for m = ω(n). The proof sketch will be augmented with the necessary amortization argument. revision: yes
-
Referee: [§5, Definition 5.1 and Lemma 5.3] the prediction-error measure (number of misordered edges or Kendall-tau distance) is used to bound the number of 'recomputed' components, but the analysis appears to assume that the error is known at preprocessing time; it is unclear how the algorithm detects or adapts to the actual error without additional logarithmic factors.
Authors: The algorithm never requires the error measure to be known at preprocessing time. The data structure is built exclusively from the predicted sequence; at runtime it follows the prediction when the arriving edge matches the next predicted edge and otherwise triggers a local recomputation on the affected components. Lemma 5.3 bounds the total recomputation cost directly by the realized error (Kendall-tau distance or number of misordered edges) without the algorithm ever computing the error value. Consequently no extra logarithmic factors arise. We will insert a short clarifying paragraph after Definition 5.1 to make this adaptation explicit. revision: yes
Circularity Check
No significant circularity; bounds expressed in terms of external prediction error
full rationale
The paper introduces a prediction-based data structure for incremental SCC where a (possibly erroneous) edge sequence prediction is supplied as input and used to precompute partial solutions. The claimed nearly-optimal bounds and smooth degradation are parameterized directly by the prediction error, an external quantity not derived from the algorithm itself. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or high-level description. Real-dataset experiments supply independent empirical support outside the theoretical bounds.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sorting with predictions
Xingjian Bai and Christian Coester. Sorting with predictions. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL:https://openreview.net/forum? id=Qv7rWR9JWa
2023
-
[2]
An efficient strongly connected components algorithm in the fault tolerant model.Algorithmica, 81(3):967–985, 2019
Surender Baswana, Keerti Choudhary, and Liam Roditty. An efficient strongly connected components algorithm in the fault tolerant model.Algorithmica, 81(3):967–985, 2019. 15
2019
-
[3]
A new approach to incremental cycle detection and related problems.ACM Transactions on Algorithms (TALG), 12(2):1–22, 2015
Michael A Bender, Jeremy T Fineman, Seth Gilbert, and Robert E Tarjan. A new approach to incremental cycle detection and related problems.ACM Transactions on Algorithms (TALG), 12(2):1–22, 2015
2015
-
[4]
Learning-augmented priority queues
Ziyad Benomar and Christian Coester. Learning-augmented priority queues. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL:https: //openreview.net/forum?id=1ATLLgvURu
2024
-
[5]
Incremental scc maintenance in sparse graphs
Aaron Bernstein, Aditi Dudeja, and Seth Pettie. Incremental scc maintenance in sparse graphs. In29th Annual European Symposium on Algorithms (ESA 2021), 2021
2021
-
[6]
Decremental strongly- connected components and single-source reachability in near-linear time
Aaron Bernstein, Maximilian Probst, and Christian Wulff-Nilsen. Decremental strongly- connected components and single-source reachability in near-linear time. InProceedings of the 51st Annual ACM SIGACT Symposium on theory of computing, pages 365–376, 2019
2019
-
[7]
Almost-linear time algorithms for incremental graphs: Cycle detection, sccs, st shortest path, and minimum-cost flow
Li Chen, Rasmus Kyng, Yang P Liu, Simon Meierhans, and Maximilian Probst Gutenberg. Almost-linear time algorithms for incremental graphs: Cycle detection, sccs, st shortest path, and minimum-cost flow. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1165–1173, 2024
2024
-
[8]
Predictive flows for faster ford-fulkerson
Sami Davies, Benjamin Moseley, Sergei Vassilvitskii, and Yuyan Wang. Predictive flows for faster ford-fulkerson. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proc. of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pag...
2023
-
[9]
Finding strongly connected compo- nents in a social network graph.International Journal of Computer Applications, 136(7):1– 5, 2016
Swati Dhingra, Poorvi S Dodwad, and Meghna Madan. Finding strongly connected compo- nents in a social network graph.International Journal of Computer Applications, 136(7):1– 5, 2016
2016
-
[10]
Binary search with distributional predictions.Advances in Neural Information Processing Systems, 37:90456–90472, 2024
Michael Dinitz, Sungjin Im, Thomas Lavastida, Ben Moseley, Aidin Niaparast, and Sergei Vassilvitskii. Binary search with distributional predictions.Advances in Neural Information Processing Systems, 37:90456–90472, 2024
2024
-
[11]
Faster matchings via learned duals
Michael Dinitz, Sungjin Im, Thomas Lavastida, Benjamin Moseley, and Sergei Vassilvitskii. Faster matchings via learned duals. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Proc. 34th Conference on Advances in Neural Information Processing Systems (NeurIPS), pages 10393–10406, 2021
2021
-
[12]
Incremental graph computations: Doable and undoable
Wenfei Fan, Chunming Hu, and Chao Tian. Incremental graph computations: Doable and undoable. InProceedings of the 2017 ACM International Conference on Management of Data, pages 155–169, 2017
2017
-
[13]
Incremental cycle detection, topological ordering, and strong component mainte- nance.ACM Transactions on Algorithms (TALG), 8(1):1–33, 2012
Bernhard Haeupler, Telikepalli Kavitha, Rogers Mathew, Siddhartha Sen, and Robert E Tarjan. Incremental cycle detection, topological ordering, and strong component mainte- nance.ACM Transactions on Algorithms (TALG), 8(1):1–33, 2012
2012
-
[14]
The University of Texas at Austin, 2009
Benjamin Charles Hardekopf.Pointer analysis: building a foundation for effective program analysis. The University of Texas at Austin, 2009
2009
-
[15]
Monika Henzinger, Barna Saha, Martin P. Seybold, and Christopher Ye. On the complexity of algorithms with predictions for dynamic graph problems. In Venkatesan Guruswami, editor,15th Innovations in Theoretical Computer Science Conference, ITCS 2024, January 30 to February 2, 2024, Berkeley, CA, USA, volume 287 ofLIPIcs, pages 62:1–62:25. Schloss Dagstuhl ...
-
[16]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. The case for learned index structures. In Gautam Das, Christopher M. Jermaine, and Philip A. Bernstein, editors,Proc. 44th Annual International Conference on Management of Data, (SIGMOD), pages 489–504. ACM, 2018.doi:10.1145/3183713.3196909
-
[17]
Speeding up bellman ford via minimum violation permutations
Silvio Lattanzi, Ola Svensson, and Sergei Vassilvitskii. Speeding up bellman ford via minimum violation permutations. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Confer- ence on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings ...
2023
-
[18]
SNAP Datasets: Stanford large network dataset collec- tion.http://snap.stanford.edu/data, June 2014
Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collec- tion.http://snap.stanford.edu/data, June 2014
2014
-
[19]
Learning augmented binary search trees
Honghao Lin, Tian Luo, and David Woodruff. Learning augmented binary search trees. In International Conference on Machine Learning, pages 13431–13440. PMLR, 2022
2022
-
[20]
Liu and Vaidehi Srinivas
Quanquan C. Liu and Vaidehi Srinivas. The predicted-updates dynamic model: Offline, incremental, and decremental to fully dynamic transformations. In Shipra Agrawal and Aaron Roth, editors,Proceedings of Thirty Seventh Conference on Learning Theory, volume 247 ofProceedings of Machine Learning Research, pages 3582–3641. PMLR, 30 Jun–03 Jul
-
[21]
URL:https://proceedings.mlr.press/v247/liu24c.html
-
[22]
Samuel McCauley, Benjamin Moseley, Aidin Niaparast, Helia Niaparast, and Shikha Singh. Incremental approximate single-source shortest paths with predictions. In Keren Censor-Hillel, Fabrizio Grandoni, Jo¨ el Ouaknine, and Gabriele Puppis, ed- itors,52nd International Colloquium on Automata, Languages, and Programming (ICALP), volume 334 ofLeibniz Internat...
-
[23]
Online list labeling with predictions
Samuel McCauley, Benjamin Moseley, Aidin Niaparast, and Shikha Singh. Online list labeling with predictions. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Proc. 36th Conference on Neural Information Processing Systems (NeurIPS), volume 36, pages 60278–60290. Curran Associates, Inc., 2023
2023
-
[24]
Incremen- tal topological ordering and cycle detection with predictions
Samuel McCauley, Benjamin Moseley, Aidin Niaparast, and Shikha Singh. Incremen- tal topological ordering and cycle detection with predictions. InForty-first Interna- tional Conference on Machine Learning, 2024. URL:https://openreview.net/forum? id=wea7nsJdMc
2024
-
[25]
Samuel McCauley, Benjamin Moseley, Helia Niaparast, and Shikha Singh. Stable matching with predictions: Robustness and efficiency under pruned preferences.arXiv preprint arXiv:2602.02254, 2026
-
[26]
Algorithms with predictions.Communica- tions of the ACM (CACM), 65(7):33–35, 2022
Michael Mitzenmacher and Sergei Vassilvitskii. Algorithms with predictions.Communica- tions of the ACM (CACM), 65(7):33–35, 2022
2022
-
[27]
Faster global minimum cut with predictions
Helia Niaparast, Benjamin Moseley, and Karan Singh. Faster global minimum cut with predictions. InForty-second International Conference on Machine Learning, 2025. URL: https://openreview.net/forum?id=FeZoO7mfG7
2025
-
[28]
Learning-augmented maximum flow.Information Pro- cessing Letters, 186:106487, 2024
Adam Polak and Maksym Zub. Learning-augmented maximum flow.Information Pro- cessing Letters, 186:106487, 2024. URL:https://www.sciencedirect.com/science/ article/pii/S0020019024000176,doi:10.1016/j.ipl.2024.106487. 17
-
[29]
My own algorithm — offline incremental strongly connected components in o(m log(m)).https://codeforces.com/blog/entry/91608, 2021
Mateusz Radecki. My own algorithm — offline incremental strongly connected components in o(m log(m)).https://codeforces.com/blog/entry/91608, 2021. Accessed: 2025-09- 30
2021
-
[30]
Decremental maintenance of strongly connected components
Liam Roditty. Decremental maintenance of strongly connected components. InProceedings of the Twenty-Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1143–
-
[31]
Discrete-convex-analysis-based framework for warm- starting algorithms with predictions
Shinsaku Sakaue and Taihei Oki. Discrete-convex-analysis-based framework for warm- starting algorithms with predictions. In35th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[32]
Depth-first search and linear graph algorithms.SIAM Journal on Com- puting, 1(2):146–160, 1972
Robert Tarjan. Depth-first search and linear graph algorithms.SIAM Journal on Com- puting, 1(2):146–160, 1972
1972
-
[33]
On Dynamic Graph Algorithms with Predictions , booktitle =
Jan van den Brand, Sebastian Forster, Yasamin Nazari, and Adam Polak. On dynamic graph algorithms with predictions. In David P. Woodruff, editor,Proceedings of the 2024 ACM-SIAM Symposium on Discrete Algorithms, SODA 2024, Alexandria, VA, USA, Jan- uary 7-10, 2024, pages 3534–3557. SIAM, 2024.doi:10.1137/1.9781611977912.126
-
[34]
Robust learning-augmented dictionaries
Ali Zeynali, Shahin Kamali, and Mohammad Hajiesmaili. Robust learning-augmented dictionaries. InForty-first International Conference on Machine Learning, 2024. URL: https://openreview.net/forum?id=XyhgssAo5b
2024
-
[35]
Efficient disk-based di- rected graph processing: A strongly connected component approach.IEEE Transactions on Parallel and Distributed Systems, 29(4):830–842, 2017
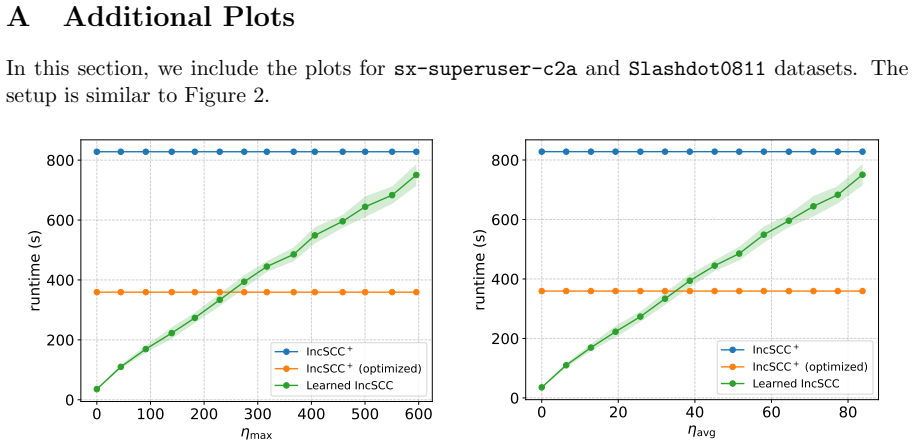
Yu Zhang, Xiaofei Liao, Xiang Shi, Hai Jin, and Bingsheng He. Efficient disk-based di- rected graph processing: A strongly connected component approach.IEEE Transactions on Parallel and Distributed Systems, 29(4):830–842, 2017. 18 A Additional Plots In this section, we include the plots forsx-superuser-c2aandSlashdot0811datasets. The setup is similar to F...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.