Recognition: unknown
RADIO-ViPE: Online Tightly Coupled Multi-Modal Fusion for Open-Vocabulary Semantic SLAM in Dynamic Environments
Pith reviewed 2026-05-07 16:34 UTC · model grok-4.3
The pith
An online system performs open-vocabulary semantic SLAM in dynamic environments from raw monocular RGB video by tightly coupling language and vision embeddings with geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
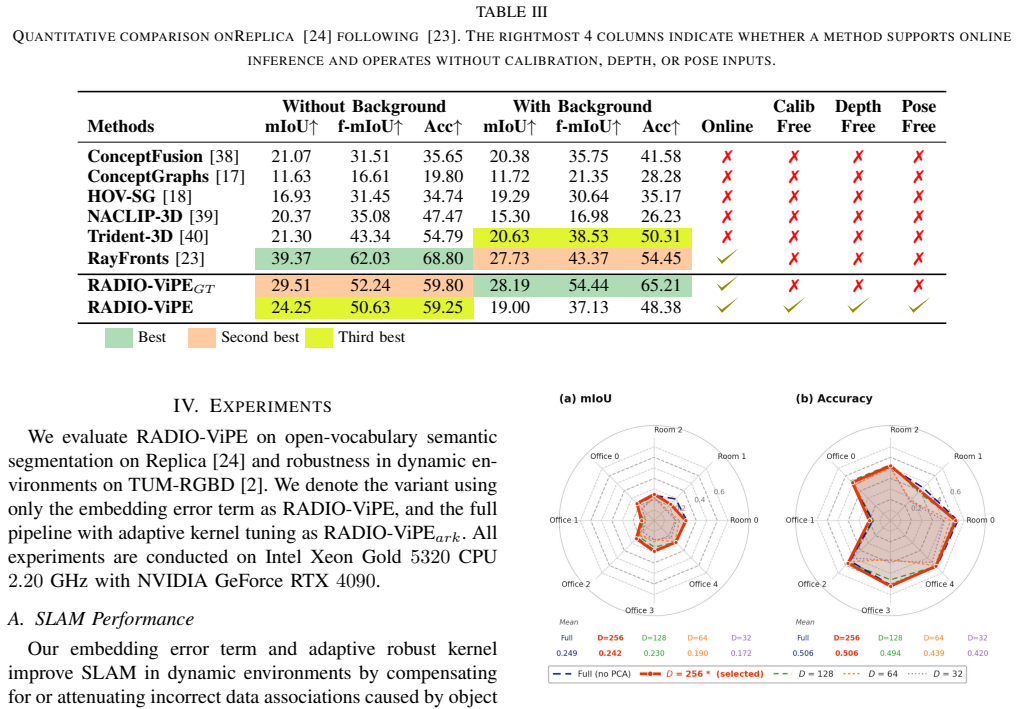
RADIO-ViPE is presented as an online semantic SLAM system for open-vocabulary grounding that tightly couples multi-modal embeddings from models such as RADIO with geometric scene information in initialization, optimization, and factor graph connections, employing adaptive robust kernels to handle dynamic objects and rearrangements, all while operating directly on raw monocular RGB streams without requiring camera intrinsics, depth, or pose initialization, and achieving state-of-the-art results on the dynamic TUM-RGBD benchmark.
What carries the argument
Tight multi-modal coupling of vision-language embeddings with geometric factors inside a factor graph using adaptive robust kernels for dynamic handling.
Load-bearing premise
Embeddings from agglomerative foundation models can be consistently and tightly integrated with geometric information across the entire SLAM pipeline without needing prior camera intrinsics, depth, or pose.
What would settle it
If the system is tested on the dynamic TUM-RGBD benchmark and does not outperform or match existing methods in semantic grounding accuracy or fails to handle moving objects as claimed, the effectiveness of the tight coupling would be disproven.
Figures




read the original abstract
We present RADIO-ViPE (Reduce All Domains Into One -- Video Pose Engine), an online semantic SLAM system that enables geometry-aware open-vocabulary grounding, associating arbitrary natural language queries with localized 3D regions and objects in dynamic environments. Unlike existing approaches that require calibrated, posed RGB-D input, RADIO-ViPE operates directly on raw monocular RGB video streams, requiring no prior camera intrinsics, depth sensors, or pose initialization. The system tightly couples multi-modal embeddings -- spanning vision and language -- derived from agglomerative foundation models (e.g., RADIO) with geometric scene information. This coupling takes place in initialization, optimization and factor graph connections to improve the consistency of the map from multiple modalities. The optimization is wrapped within adaptive robust kernels, designed to handle both actively moving objects and agent-displaced scene elements (e.g., furniture rearranged during ego-centric session). Experiments demonstrate that RADIO-ViPE achieves state-of-the-art results on the dynamic TUM-RGBD benchmark while maintaining competitive performance against offline open-vocabulary methods that rely on calibrated data and static scene assumptions. RADIO-ViPE bridges a critical gap in real-world deployment, enabling robust open-vocabulary semantic grounding for autonomous robotics and unconstrained in-the-wild video streams. Project page: https://be2rlab.github.io/radio_vipe
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RADIO-ViPE, an online tightly-coupled multi-modal semantic SLAM system that performs open-vocabulary grounding by fusing embeddings from agglomerative foundation models (e.g., RADIO) with geometric information. It operates directly on raw monocular RGB streams without camera intrinsics, depth sensors, or pose initialization, using adaptive robust kernels in a factor-graph optimization to handle dynamic objects and scene changes, and reports SOTA results on the dynamic TUM-RGBD benchmark while remaining competitive with offline calibrated methods.
Significance. If the performance claims and scale-recovery mechanism hold under the stated assumptions, the work would be significant for enabling real-world deployment of open-vocabulary semantic SLAM in unconstrained dynamic environments using only monocular RGB, removing reliance on calibrated sensors or static-scene priors that limit prior systems.
major comments (2)
- The central claim that multi-modal embeddings can be tightly coupled into initialization, optimization, and factor-graph edges to recover consistent metric-scale 3D maps from raw monocular RGB in dynamic scenes is load-bearing; the skeptic note correctly identifies unresolved scale ambiguity, and without explicit demonstration (e.g., via scale-consistency metrics or comparison against known intrinsics) the SOTA result on TUM-RGBD may not generalize beyond the benchmark's motion statistics.
- Experiments section: the abstract asserts SOTA performance on dynamic TUM-RGBD and competitive results versus offline methods, yet supplies no quantitative metrics, error bars, ablation tables, or implementation details on how embedding consistency constrains bundle-adjustment scale or rejects moving elements; this absence prevents verification of the tight-coupling contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on RADIO-ViPE. We address each major comment below with clarifications on our scale-recovery approach and experimental reporting, and we commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The central claim that multi-modal embeddings can be tightly coupled into initialization, optimization, and factor-graph edges to recover consistent metric-scale 3D maps from raw monocular RGB in dynamic scenes is load-bearing; the skeptic note correctly identifies unresolved scale ambiguity, and without explicit demonstration (e.g., via scale-consistency metrics or comparison against known intrinsics) the SOTA result on TUM-RGBD may not generalize beyond the benchmark's motion statistics.
Authors: We acknowledge that the manuscript does not include dedicated scale-consistency metrics or direct comparisons against known intrinsics. The system recovers consistent scale through the tight integration of vision-language embeddings with geometric factors and adaptive robust kernels, which enforce multi-view and multi-modal consistency even in dynamic scenes; this is what enables competitive results against calibrated offline methods on TUM-RGBD without supplying intrinsics at runtime. To address the concern directly, the revised manuscript will add an explicit scale-consistency analysis subsection, including quantitative metrics and comparisons using the benchmark's ground-truth intrinsics. revision: yes
-
Referee: Experiments section: the abstract asserts SOTA performance on dynamic TUM-RGBD and competitive results versus offline methods, yet supplies no quantitative metrics, error bars, ablation tables, or implementation details on how embedding consistency constrains bundle-adjustment scale or rejects moving elements; this absence prevents verification of the tight-coupling contribution.
Authors: We agree that the current experiments section would benefit from expanded quantitative support. While the manuscript reports SOTA results on dynamic TUM-RGBD and competitive performance versus offline baselines, we will revise the experiments to include error bars, full ablation tables isolating the contribution of embedding consistency to scale constraint and dynamic rejection, and additional implementation details on the factor-graph edges and robust kernels. These additions will make the tight-coupling benefits verifiable. revision: yes
Circularity Check
No circularity detected; claims rest on external benchmarks
full rationale
The paper describes a monocular semantic SLAM architecture that couples RADIO embeddings with geometric factors in initialization, optimization, and factor graphs, but presents no equations, derivations, or parameter-fitting steps. All performance assertions are grounded in experiments on the independent dynamic TUM-RGBD benchmark rather than any self-referential reduction or self-citation chain that would force the result by construction. The system description is therefore self-contained against external validation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embeddings from foundation models such as RADIO are consistent enough to be tightly coupled with geometric scene information across initialization, optimization, and factor-graph stages.
Reference graph
Works this paper leans on
-
[1]
Am-radio: Agglomerative vision foundation model reduce all domains into one,
M. Ranzinger and G. e. a. Heinrich, “Am-radio: Agglomerative vision foundation model reduce all domains into one,” inIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, June 2024, pp. 12 490–12 500
2024
-
[2]
A benchmark for the evaluation of rgb-d slam systems,
J. Sturm and e. a. N. Engelhard, “A benchmark for the evaluation of rgb-d slam systems,” inThe International Conference on Intelligent Robot Systems, October 2012
2012
-
[3]
Ego4d: Around the World in 3,000 Hours of Egocentric Video,
K. Grauman, A. Westbury, and E. a. Byrne, “Ego4d: Around the World in 3,000 Hours of Egocentric Video,” inIEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[4]
Aria digital twin: A new bench- mark dataset for egocentric 3d machine perception,
X. Pan and e. a. Charron, Nicholas, “Aria digital twin: A new bench- mark dataset for egocentric 3d machine perception,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 20 133–20 143
2023
-
[5]
arXiv preprint arXiv:2508.10934 (2025)
J. Huang and e. a. Zhou, “Vipe: Video pose engine for 3d geomet- ric perception,” inNVIDIA Research Whitepapers arXiv:2508.10934, 2025
-
[6]
O. Alama and e. a. Jariwala, Darshil, “Radseg: Unleashing parameter and compute efficient zero-shot open-vocabulary segmentation using agglomerative models,”arXiv preprint arXiv:2511.19704, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Rvwo: A robust visual-wheel slam system for mobile robots in dynamic environments,
J. Mahmoud, A. Penkovskiy, H. T. Long Vuong, A. Burkov, and S. Kolyubin, “Rvwo: A robust visual-wheel slam system for mobile robots in dynamic environments,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023, pp. 3468–3474
2023
-
[8]
A general and adaptive robust loss function,
J. T. Barron, “A general and adaptive robust loss function,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4326–4334
2019
-
[9]
Mast3r-slam: Real- time dense slam with 3d reconstruction priors,
R. Murai, E. Dexheimer, and A. J. Davison, “Mast3r-slam: Real- time dense slam with 3d reconstruction priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 695–16 705
2025
-
[10]
arXiv preprint arXiv:2505.12549 (2025)
D. Maggio, H. Lim, and L. Carlone, “Vggt-slam: Dense rgb slam optimized on the sl (4) manifold,”arXiv preprint arXiv:2505.12549, 2025
-
[11]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inCVPR, 2024
2024
-
[12]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,
E. a. Campos, Carlos, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE Transactions on Robotics, vol. 37, no. 6, p. 1874–1890, Dec. 2021
2021
-
[13]
Kimera: an open-source library for real-time metric-semantic localization and mapping,
A. Rosinol and e. a. Abate, Marcus, “Kimera: an open-source library for real-time metric-semantic localization and mapping,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 1689–1696
2020
-
[14]
Rgbds-slam: A rgb-d semantic dense slam based on 3d multi level pyramid gaussian splatting,
Z. C. et al, “Rgbds-slam: A rgb-d semantic dense slam based on 3d multi level pyramid gaussian splatting,” 2024
2024
-
[15]
Samslam: A visual slam based on segment anything model for dynamic environment,
X. Chen, T. Wang, H. Mai, and L. Yang, “Samslam: A visual slam based on segment anything model for dynamic environment,” in2024 8th International Conference on Robotics, Control and Automation (ICRCA), 2024, pp. 91–97
2024
-
[16]
Beyond bare queries: Open- vocabulary object grounding with 3d scene graph,
S. Linok, T. Zemskova, S. Ladanova, R. Titkov, D. Yudin, M. Monastyrny, and A. Valenkov, “Beyond bare queries: Open- vocabulary object grounding with 3d scene graph,” 2024
2024
-
[17]
Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning,
Q. Gu and E. a. Alihusein Kuwajerwala, “Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning,” 2023
2023
-
[18]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby and e. a. Huang, Chenguang, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inRobotics: Science and Systems XX, ser. RSS2024. Robotics: Science and Systems Foundation, July 2024
2024
-
[19]
Openscene: 3d scene understanding with open vocabularies,
S. Peng, K. Genova, C. M. Jiang, A. Tagliasacchi, M. Pollefeys, and T. Funkhouser, “Openscene: 3d scene understanding with open vocabularies,” 2023
2023
-
[20]
Openmask3d: Open-vocabulary 3d instance segmen- tation,
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “Openmask3d: Open-vocabulary 3d instance segmen- tation,” 2023
2023
-
[21]
Clio: Real-time task-driven open-set 3d scene graphs,
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone, “Clio: Real-time task-driven open-set 3d scene graphs,” 2024
2024
-
[22]
Ovo-slam: Open- vocabulary online simultaneous localization and mapping,
T. B. Martins, M. R. Oswald, and J. Civera, “Ovo-slam: Open- vocabulary online simultaneous localization and mapping,” 2024
2024
-
[23]
Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,
O. Alama and e. a. Bhattacharya, Avigyan, “Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 5930–5937
2025
-
[24]
The replica dataset: A digital replica of indoor spaces,
J. Straub and E. a. Thomas Whelan, “The replica dataset: A digital replica of indoor spaces,” 2019
2019
-
[25]
DROID-SLAM: Deep Visual SLAM for Monoc- ular, Stereo, and RGB-D Cameras,
Z. Teed and J. Deng, “DROID-SLAM: Deep Visual SLAM for Monoc- ular, Stereo, and RGB-D Cameras,”Advances in neural information processing systems, 2021
2021
-
[26]
Unidepth: Universal monocular metric depth estimation,
L. e. a. Piccinelli, “Unidepth: Universal monocular metric depth estimation,” in2024 (CVPR), 2024, pp. 10 106–10 116
2024
-
[27]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision,
R. e. a. Wang, “Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision,” in(CVPR), 2025, pp. 5261–5271
2025
-
[28]
Adaptive robust kernels for non-linear least squares problems,
N. e. a. Chebrolu, “Adaptive robust kernels for non-linear least squares problems,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2240–2247, 2021
2021
-
[29]
GeoCalib: Single-image Calibration with Geometric Optimization,
A. V . et al, “GeoCalib: Single-image Calibration with Geometric Optimization,” inECCV, 2024
2024
-
[30]
Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,
M. Hu, W. Yin, and e. a. Zhang, “Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,”IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2024
2024
-
[31]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
2023
-
[32]
Dynaslam ii: Tightly-coupled multi-object tracking and slam,
B. Bescos, C. Campos, J. D. Tard ´os, and J. Neira, “Dynaslam ii: Tightly-coupled multi-object tracking and slam,” 2020. [Online]. Available: https://arxiv.org/abs/2010.07820
-
[33]
Dld-slam: Rgb- d visual simultaneous localisation and mapping in indoor dynamic environments based on deep learning,
H. Yu, Q. Wang, C. Yan, Y . Feng, Y . Sun, and L. Li, “Dld-slam: Rgb- d visual simultaneous localisation and mapping in indoor dynamic environments based on deep learning,”Remote Sensing, vol. 16, no. 2, 2024
2024
-
[34]
V3d-slam: Robust rgb-d slam in dynamic environments with 3d semantic geometry voting,
T. Dang, K. Nguyen, and M. Huber, “V3d-slam: Robust rgb-d slam in dynamic environments with 3d semantic geometry voting,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 7847–7853
2024
-
[35]
Dgs-slam: A fast and robust rgbd slam in dynamic environments combined by geometric and semantic information,
L. Yan, X. Hu, and e. a. Zhao, “Dgs-slam: A fast and robust rgbd slam in dynamic environments combined by geometric and semantic information,”Remote Sensing, vol. 14, no. 3, p. 795, 2022
2022
-
[36]
Rodyn-slam: Robust dynamic dense rgb-d slam with neural radiance fields,
H. Jiang, Y . Xu, K. Li, J. Feng, and L. Zhang, “Rodyn-slam: Robust dynamic dense rgb-d slam with neural radiance fields,” 2024
2024
-
[37]
Dynamon: Motion-aware fast and robust camera localization for dynamic neural radiance fields,
N. Schischka and e. a. Schieber, “Dynamon: Motion-aware fast and robust camera localization for dynamic neural radiance fields,”IEEE Robotics and Automation Letters, pp. 1–8, 2024
2024
-
[38]
Conceptfusion: Open-set multimodal 3d map- ping,
e. a. Jatavallabhula, “Conceptfusion: Open-set multimodal 3d map- ping,”Robotics: Science and Systems (RSS), 2023
2023
-
[39]
Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation,
S. Hajimiri, I. Ben Ayed, and J. Dolz, “Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
2025
-
[40]
Y . Shi, M. Dong, and C. Xu, “Harnessing vision foundation models for high-performance, training-free open vocabulary segmentation,”arXiv preprint arXiv:2411.09219, 2024
-
[41]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, and e. a. Ren, “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean conference on computer vision. Springer, 2024, pp. 38–55
2024
-
[42]
Segment anything,
E. a. Alexander Kirillov, Eric Mintun, “Segment anything,” 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.