Recognition: unknown
Application-Aware Twin-in-the-Loop Planning for Federated Split Learning over Wireless Edge Networks
Pith reviewed 2026-05-07 14:17 UTC · model grok-4.3
The pith
TiLP uses a cross-domain digital twin to jointly plan wireless bandwidth, power, split points, compression, and participation for federated split learning, raising robotic task success by 9.5 points while meeting per-round deadlines and the
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By running candidate allocations through a digital twin that couples network, training, and task sub-twins at their native time scales, and by searching the resulting mixed continuous-discrete space with receding-horizon cross-entropy method guided by actor-critic, TiLP produces resource decisions that improve end-task success in federated split learning deployments while obeying per-round deadline, energy, and spectrum limits.
What carries the argument
The cross-domain digital twin (network sub-twin, training sub-twin, task sub-twin) placed inside receding-horizon cross-entropy method planning with actor-critic guidance, used to evaluate joint choices of bandwidth, power, split-layer placement, compression level, and terminal participation.
If this is right
- Joint optimization across wireless transmission, model training, and downstream task performance becomes feasible without repeated real-world trials.
- Per-round constraints on completion time, energy, memory, and spectrum can be met while still maximizing task success.
- Decisions that account for interactions among the three time scales outperform optimizations that treat any one axis in isolation.
Where Pith is reading between the lines
- The same twin-in-the-loop structure could be reused for other edge-AI workloads whose costs and rewards evolve at mismatched time scales, such as distributed inference or real-time control.
- If the sub-twins remain accurate when the wireless environment changes, the method reduces the number of physical experiments needed to learn good policies.
- Adding explicit uncertainty modeling inside the task sub-twin might further improve robustness when channel conditions deviate from the calibration data.
Load-bearing premise
The sub-twins inside the digital twin correctly predict how real wireless channels, training dynamics, and task outcomes will behave at each process's time scale, so that decisions chosen in simulation transfer to the physical system.
What would settle it
Apply the exact resource allocations chosen by TiLP to a physical wireless testbed running the same robotic manipulation tasks and measure whether the observed task success rate matches or exceeds the rate predicted by the twin and remains higher than the strongest single-axis baseline.
Figures




read the original abstract
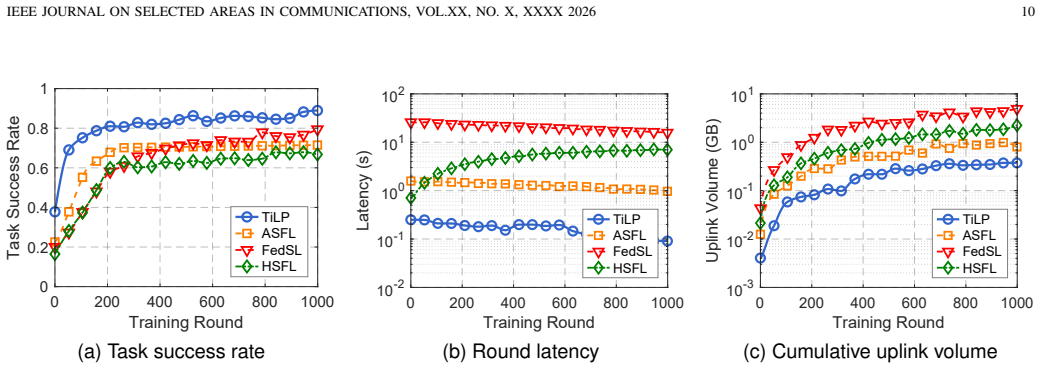
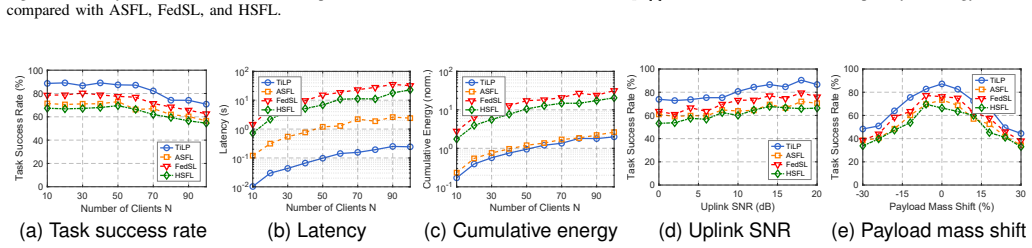
We investigate task-success-oriented resource allocation for federated split learning (FSL) at the wireless edge. In this setting, the server must jointly determine bandwidth, transmit power, split-layer placement, compression level, and terminal participation under per-round deadline, memory, and spectrum constraints. These coupled decisions affect wireless transmission, model training, and task execution, which evolve at different time scales and cannot be efficiently evaluated through repeated real-world trials. To address this challenge, we propose TiLP, a twin-in-the-loop planner that evaluates candidate decisions through a cross-domain digital twin before execution. The twin integrates network, training, and task sub-twins, with each sub-twin calibrated at the time scale of the process it models. Based on this twin, TiLP performs receding-horizon cross-entropy method planning with actor-critic guidance to search over mixed continuous-discrete decisions. Experiments on LIBERO robotic manipulation tasks over a Sionna RT-simulated wireless network show that TiLP improves task success by 9.5 percentage points over the strongest single-axis baseline, while satisfying the per-round deadline and energy budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TiLP, a twin-in-the-loop planner for joint optimization of resource allocation decisions (bandwidth, transmit power, split-layer placement, compression level, and terminal participation) in federated split learning over wireless edge networks. The planner uses a cross-domain digital twin comprising network, training, and task sub-twins, each calibrated at the appropriate time scale, to evaluate candidate decisions via receding-horizon cross-entropy method planning guided by an actor-critic model. Experiments using LIBERO robotic manipulation tasks on a Sionna RT-simulated wireless network demonstrate a 9.5 percentage point improvement in task success rate compared to the strongest single-axis baseline, while satisfying per-round deadline and energy constraints.
Significance. If the digital twin's predictions transfer to physical deployments, the work could significantly advance practical federated learning systems by incorporating task performance metrics directly into network planning, moving beyond purely communication or computation focused approaches. The use of a multi-time-scale twin and mixed continuous-discrete optimization is a promising direction for application-aware edge intelligence. However, the current evaluation remains confined to simulation, which tempers the assessed impact until transfer is demonstrated.
major comments (2)
- [Experiments] The reported 9.5 percentage point gain in task success is obtained by executing both the TiLP planning and the performance evaluation entirely within the same Sionna RT simulation environment that supplies the network sub-twin. This setup eliminates model mismatch by construction and does not test whether the optimized decisions remain superior when real wireless channels, hardware energy consumption, or task dynamics deviate from the twin's model, which is the key condition for the motivating claim of deployability in actual wireless FSL systems. (Experiments section)
- [Abstract and §3] The abstract and methods provide no details on the twin calibration procedures for the network, training, and task sub-twins, the specific hyperparameters of the receding-horizon CEM planner and actor-critic guidance, the implementation details of the baselines, or any statistical tests supporting the significance of the 9.5 pp improvement. These omissions hinder verification of the empirical claims. (Abstract and §3)
minor comments (2)
- [§2] The notation for the sub-twins (network, training, task) and decision variables could be more clearly defined and consistently used in the early sections to aid readability.
- [Figures in Experiments] Figure captions and axis labels in the experimental results could explicitly state the number of independent runs and error bars to clarify variability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and presentation of our work. We address each major comment below and will revise the manuscript accordingly to improve clarity and transparency.
read point-by-point responses
-
Referee: [Experiments] The reported 9.5 percentage point gain in task success is obtained by executing both the TiLP planning and the performance evaluation entirely within the same Sionna RT simulation environment that supplies the network sub-twin. This setup eliminates model mismatch by construction and does not test whether the optimized decisions remain superior when real wireless channels, hardware energy consumption, or task dynamics deviate from the twin's model, which is the key condition for the motivating claim of deployability in actual wireless FSL systems. (Experiments section)
Authors: We acknowledge that the evaluation is performed entirely within the Sionna RT simulation, which by construction matches the network sub-twin and removes mismatch. This is standard practice in wireless systems research to isolate algorithmic contributions under controlled dynamics. We agree that transfer to physical hardware remains an open question for full deployability claims. In the revised manuscript, we will add a new subsection in the Experiments section that explicitly discusses the calibration assumptions of the digital twin, potential real-world mismatch sources (e.g., hardware-specific energy models, unmodeled channel impairments), and the limitations of simulation-only validation. We will also outline planned future work on hardware testbed validation. This revision clarifies the current scope without overstating immediate deployability. revision: partial
-
Referee: [Abstract and §3] The abstract and methods provide no details on the twin calibration procedures for the network, training, and task sub-twins, the specific hyperparameters of the receding-horizon CEM planner and actor-critic guidance, the implementation details of the baselines, or any statistical tests supporting the significance of the 9.5 pp improvement. These omissions hinder verification of the empirical claims. (Abstract and §3)
Authors: We thank the referee for identifying these omissions, which indeed limit reproducibility. In the revised manuscript, we will expand the abstract to briefly note the multi-time-scale calibration approach and planner structure. Section 3 will be augmented with dedicated paragraphs or subsections providing: (i) calibration procedures and update frequencies for each sub-twin, (ii) exact hyperparameters for the receding-horizon CEM (population size, horizon, elite ratio) and actor-critic guidance (architecture, learning rates), (iii) precise implementation details for all baselines, and (iv) statistical analysis including number of independent runs, standard deviations, and significance tests (e.g., paired t-tests) for the reported 9.5 pp gain. These additions will directly address the verification concern. revision: yes
Circularity Check
No circularity; simulation evaluation is self-contained within modeled environment
full rationale
The paper's core contribution is a receding-horizon CEM planner with actor-critic guidance that evaluates candidate resource-allocation decisions inside an integrated digital twin (network + training + task sub-twins). All reported results, including the 9.5 pp task-success improvement, are obtained by executing both the planner and the baselines inside the identical Sionna RT simulation that supplies the network sub-twin. Because the evaluation metric is computed directly from the same forward model used for planning, the comparison is internally consistent but does not constitute a prediction that reduces to its inputs by construction. No equations, fitted parameters, or self-citations are shown to create self-definitional loops, uniqueness claims imported from prior author work, or ansatzes smuggled via citation. The derivation therefore remains non-circular; any concern about transfer to physical hardware is a question of external validity rather than circular reasoning.
Axiom & Free-Parameter Ledger
invented entities (1)
-
cross-domain digital twin with network, training, and task sub-twins
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Inference-Time Budget Control for LLM Search Agents
A VOI-based controller for dual inference budgets improves multi-hop QA performance by prioritizing search actions and selectively finalizing answers.
Reference graph
Works this paper leans on
-
[1]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, A. Singh and J. Zhu, Eds., vol. 54. PMLR, 20–22 Apr 2017, pp. 1273–1282. [...
2017
-
[2]
Split learning for health: Distributed deep learning without sharing raw patient data
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” vol. abs/1812.00564, 2018. [Online]. Available: http://arxiv.org/abs/1812.00564
work page Pith review arXiv 2018
-
[3]
SplitFed: When Federated Learning Meets Split Learning,
C. Thapa, P. C. Mahawaga Arachchige, S. Camtepe, and L. Sun, “SplitFed: When Federated Learning Meets Split Learning,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 8, pp. 8485–8493, 2022
2022
-
[4]
Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,
B. Wu, J. Huang, and Q. Duan, “Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,”IEEE Network, vol. 40, no. 2, pp. 184–191, 2025
2025
-
[5]
“X of Information
B. Wu, J. Huang, and S. Yu, ““X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Net- worked Systems,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 5307–5344, 2026
2026
-
[6]
Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,
Z. Ding, J. Huang, and J. Qi, “Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,” in2026 International Conference on Computing, Networking and Communications (ICNC), 2026, pp. 769– 774
2026
-
[7]
Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,
B. Wu, J. Huang, Q. Duan, L. Dong, and Z. Cai, “Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,”IEEE/ACM Transactions on Networking, pp. 1–1, 2025
2025
-
[8]
A Review of Continual Learning in Edge AI,
B. Wu, Z. Ding, and J. Huang, “A Review of Continual Learning in Edge AI,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6571–6588, 2026. IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL.XX, NO. X, XXXX 2026 13
2026
-
[9]
Accelerating Split Federated Learning Over Wireless Communication Networks,
C. Xu, J. Li, Y . Liu, Y . Ling, and M. Wen, “Accelerating Split Federated Learning Over Wireless Communication Networks,”IEEE Transactions on Wireless Communications, vol. 23, no. 6, pp. 5587–5599, 2024
2024
-
[10]
Hierarchical Split Federated Learning: Convergence Analysis and Sys- tem Optimization,
Z. Lin, W. Wei, Z. Chen, C.-T. Lam, X. Chen, Y . Gao, and J. Luo, “Hierarchical Split Federated Learning: Convergence Analysis and Sys- tem Optimization,”IEEE Transactions on Mobile Computing, vol. 24, no. 10, pp. 9352–9367, 2025
2025
-
[11]
Energy-Efficient Federated Learning for Edge Real-Time Vision via Joint Data, Com- putation, and Communication Design,
X. Hou, J. Wang, F. Guan, J. Du, and C. Jiang, “Energy-Efficient Federated Learning for Edge Real-Time Vision via Joint Data, Com- putation, and Communication Design,”IEEE Journal on Selected Areas in Communications, vol. 43, no. 12, pp. 4000–4014, 2025
2025
-
[12]
Federated Fine-Tuning for Pre-Trained Foundation Models Over Wireless Networks,
Z. Wang, Y . Zhou, Y . Shi, and K. B. Letaief, “Federated Fine-Tuning for Pre-Trained Foundation Models Over Wireless Networks,”IEEE Transactions on Wireless Communications, vol. 24, no. 4, pp. 3450– 3464, 2025
2025
-
[13]
Zeroth-Order Federated Fine-Tuning for Large AI Models in Resource-Constrained Wireless Networks,
T. Wang, Y . Zhou, Y . Shi, N. Cheng, and H. Zhou, “Zeroth-Order Federated Fine-Tuning for Large AI Models in Resource-Constrained Wireless Networks,”IEEE Transactions on Wireless Communications, vol. 25, pp. 12 407–12 421, 2026
2026
-
[14]
Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,
B. Wu and W. Wu, “Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,”Mathematical Problems in Engineering, vol. 2023, no. 1, p. 6350647, 2023
2023
-
[15]
Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,
B. Wu, Z. Ding, L. Ostigaard, and J. Huang, “Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,” in2025 ACM Research on Adaptive and Convergent Systems (RACS). ACM, 2025, pp. 1–8
2025
-
[16]
A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,
Z. Ding, J. Huang, Q. Duan, C. Zhang, Y . Zhao, and S. Gu, “A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,” in2025 IEEE International Performance, Computing, and Communications Conference (IPCCC), 2025, pp. 1–8
2025
-
[17]
Securing Smart Agriculture with Communication-Efficient Federated Unlearning,
U. Pudasaini, Z. Ding, and J. Huang, “Securing Smart Agriculture with Communication-Efficient Federated Unlearning,” in2026 IEEE International Conference on High Performance Switching and Routing (HPSR). IEEE, 2026, pp. 1–8
2026
-
[18]
Digital Twin-Assisted Explainable AI for Robust Beam Prediction in mmWave MIMO Systems,
N. Khan, A. Abdallah, A. C ¸ elik, A. M. Eltawil, and S. C ¸¨oleri, “Digital Twin-Assisted Explainable AI for Robust Beam Prediction in mmWave MIMO Systems,”IEEE Transactions on Wireless Communications, vol. 25, pp. 2435–2451, 2025
2025
-
[19]
A Novel Secure Split Federated Semantic Learning Framework and its Optimization for Digital Twin Network Evolution,
S. D. Okegbile, H. Gao, and J. Cai, “A Novel Secure Split Federated Semantic Learning Framework and its Optimization for Digital Twin Network Evolution,”IEEE Transactions on Mobile Computing, vol. 25, no. 1, pp. 1302–1319, 2025
2025
-
[20]
Digital Twins for Low-Altitude UA V Networks: Cooperation and Learning,
L. Zhou, S. Leng, Y . Liu, Z. Xiong, and T. Q. S. Quek, “Digital Twins for Low-Altitude UA V Networks: Cooperation and Learning,”IEEE Transactions on Mobile Computing, vol. 25, no. 4, pp. 4839–4856, 2025
2025
-
[21]
AI-Powered Digital Twins for Robotic Control in 5G-Enabled Industrial Automation,
T. M. Ho, K. K. Nguyen, and M. Cheriet, “AI-Powered Digital Twins for Robotic Control in 5G-Enabled Industrial Automation,”IEEE Journal on Selected Areas in Communications, vol. 43, no. 10, pp. 3347–3361, 2025
2025
-
[22]
From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,
B. Wu, J. Huang, and Y . Zhao, “From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[23]
SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,
Z. Ding, B. Wu, and J. Huang, “SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[24]
Learning Latent Dynamics for Planning from Pixels,
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning Latent Dynamics for Planning from Pixels,” inProceedings of the International Conference on Machine Learning, 2019, pp. 2555–2565
2019
-
[25]
Mastering Diverse Control Tasks through World Models,
D. Hafner, J. Pa ˇsukonis, J. Ba, and T. Lillicrap, “Mastering Diverse Control Tasks through World Models,”Nature, vol. 640, pp. 647–653, 2025
2025
-
[26]
Deep Reinforce- ment Learning in a Handful of Trials using Probabilistic Dynamics Models,
K. Chua, R. Calandra, R. McAllister, and S. Levine, “Deep Reinforce- ment Learning in a Handful of Trials using Probabilistic Dynamics Models,” inAdvances in Neural Information Processing Systems, 2018, pp. 4754–4765
2018
-
[27]
When to Trust Your Model: Model-Based Policy Optimization,
M. Janner, J. Fu, M. Zhang, and S. Levine, “When to Trust Your Model: Model-Based Policy Optimization,” inAdvances in Neural Information Processing Systems, 2019, pp. 12 519–12 530
2019
-
[28]
A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,
J. Huang, B. Wu, Q. Duan, L. Dong, and S. Yu, “A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,”IEEE Transactions on Mobile Computing, pp. 1–16, 2025
2025
-
[29]
B. Wu, Z. Ding, and J. Huang, “RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge,” arXiv preprint arXiv:2604.04243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Shared Spatial Memory Through Predictive Coding,
Z. Fang, Y . Guo, J. Wang, Y . Zhang, H. An, Y . Wang, and Y . Fang, “Shared Spatial Memory Through Predictive Coding,” arXiv preprint arXiv:2511.04235, 2025
-
[31]
Task- oriented communications for visual navigation with edge-aerial collabo- ration in low altitude economy,
Z. Fang, Z. Liu, J. Wang, S. Hu, Y . Guo, Y . Deng, and Y . Fang, “Task- oriented communications for visual navigation with edge-aerial collabo- ration in low altitude economy,” inProc. IEEE Global Communications Conference (GLOBECOM), 2026
2026
-
[32]
Federated Split Learning With Improved Com- munication and Storage Efficiency,
Y . Mu and C. Shen, “Federated Split Learning With Improved Com- munication and Storage Efficiency,”IEEE Transactions on Mobile Computing, vol. 25, no. 1, pp. 272–283, 2025
2025
-
[33]
Federated Split Learning via Low-Rank Approximation: A Communication-Efficient Approach,
H. Ao, H. Tian, W. Ni, J. Zhang, and D. Niyato, “Federated Split Learning via Low-Rank Approximation: A Communication-Efficient Approach,”IEEE Transactions on Wireless Communications, vol. 25, pp. 11 253–11 269, 2026
2026
-
[34]
Massive Dig- ital Over-the-Air Computation for Communication-Efficient Federated Edge Learning,
L. Qiao, Z. Gao, M. Boloursaz Mashhadi, and D. G ¨und¨uz, “Massive Dig- ital Over-the-Air Computation for Communication-Efficient Federated Edge Learning,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 11, pp. 3078–3094, 2024
2024
-
[35]
AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,
B. Wu, Z. Cai, W. Wu, and X. Yin, “AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,”IEEE Access, 2023
2023
-
[36]
A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,
D. Pan, B.-N. Wu, Y .-L. Sun, and Y .-P. Xu, “A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,”Sustainable Computing: In- formatics and Systems, vol. 37, p. 100827, 2023
2023
-
[37]
AdaptSFL: Adaptive Split Federated Learning in Resource-Constrained Edge Networks,
Z. Lin, G. Qu, W. Wei, X. Chen, and K. K. Leung, “AdaptSFL: Adaptive Split Federated Learning in Resource-Constrained Edge Networks,” IEEE Transactions on Networking, vol. 33, no. 6, pp. 2993–3008, 2025
2025
-
[38]
Federated Split Learning for Edge Intelli- gence in Resource-Constrained Wireless Networks,
H. Ao, H. Tian, and W. Ni, “Federated Split Learning for Edge Intelli- gence in Resource-Constrained Wireless Networks,”IEEE Transactions on Consumer Electronics, vol. 71, no. 2, pp. 4451–4463, 2025
2025
-
[39]
Communication-and-Computation Efficient Split Federated Learning in Wireless Networks: Gradient Aggregation and Resource Management,
Y . Liang, Q. Chen, R. Li, G. Zhu, M. Kaleem Awan, and H. Jiang, “Communication-and-Computation Efficient Split Federated Learning in Wireless Networks: Gradient Aggregation and Resource Management,” IEEE Transactions on Wireless Communications, vol. 25, pp. 1981– 1995, 2026
1981
-
[40]
Adaptive Bayesian Optimization for Online Bandit Model Partitioning and Resource Allocation in Split Federated Learning,
J. You, J. Yan, Z. Li, and L. Yang, “Adaptive Bayesian Optimization for Online Bandit Model Partitioning and Resource Allocation in Split Federated Learning,”IEEE Transactions on Mobile Computing, 2026
2026
-
[41]
Tackling Class Imbalance and Client Heterogeneity for Split Federated Learning in Wireless Networks,
C. Xie, Z. Chen, W. Yi, H. Shin, and A. Nallanathan, “Tackling Class Imbalance and Client Heterogeneity for Split Federated Learning in Wireless Networks,”IEEE Transactions on Wireless Communications, vol. 24, no. 6, pp. 4920–4936, 2025
2025
-
[42]
Device Sampling and Resource Optimization for Federated Learning in Cooperative Edge Networks,
S. Wang, R. Morabito, S. Hosseinalipour, M. Chiang, and C. G. Brinton, “Device Sampling and Resource Optimization for Federated Learning in Cooperative Edge Networks,”IEEE/ACM Transactions on Networking, vol. 32, no. 5, pp. 4365–4381, 2024
2024
-
[43]
Training Latency Mini- mization for Model-Splitting Allowed Federated Edge Learning,
Y . Wen, G. Zhang, K. Wang, and K. Yang, “Training Latency Mini- mization for Model-Splitting Allowed Federated Edge Learning,”IEEE Transactions on Network Science and Engineering, vol. 12, no. 3, pp. 2081–2092, 2025
2081
-
[44]
A Stochastic Geometry- Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting,
C.-C. Xing, Z. Ding, and J. Huang, “A Stochastic Geometry- Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting,”SIGAPP Appl. Comput. Rev., vol. 25, no. 4, p. 18–34, Jan
-
[45]
Available: https://doi.org/10.1145/3787594.3787596
[Online]. Available: https://doi.org/10.1145/3787594.3787596
-
[46]
Lightweight and Self-Evolving Channel Twinning: An Ensemble DMD-Assisted Approach,
Y . Cao, J. Wang, X. Shi, and W. Ni, “Lightweight and Self-Evolving Channel Twinning: An Ensemble DMD-Assisted Approach,”IEEE Transactions on Wireless Communications, vol. 24, no. 10, pp. 8072– 8085, 2025
2025
-
[47]
Digital Twin-Assisted Data-Driven Optimization for Reliable Edge Caching in Wireless Net- works,
Z. Zhang, Y . Liu, Z. Peng, M. Chen, and D. Xu, “Digital Twin-Assisted Data-Driven Optimization for Reliable Edge Caching in Wireless Net- works,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 11, pp. 3306–3320, 2024
2024
-
[48]
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems
B. Wu and J. Huang, “Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems,” arXiv preprint arXiv:2604.20745, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,
Z. Fang, S. Hu, J. Wang, Y . Deng, X. Chen, and Y . Fang, “Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,”IEEE Transactions on Networking, pp. 1–17, 2025
2025
-
[50]
R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,
Z. Fang, J. Wang, Y . Ma, Y . Tao, Y . Deng, X. Chen, and Y . Fang, “R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,”IEEE Journal on Selected Areas in Communications, 2025. IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL.XX, NO. X, XXXX 2026 14
2025
-
[51]
Personalized Federated Learning for Generative AI Empowered Digital Twin Networks,
D. Jin, Y . Xiao, Y . Li, and G. Shi, “Personalized Federated Learning for Generative AI Empowered Digital Twin Networks,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6174–6192, 2026
2026
-
[52]
Decentralized Task Offloading in Collaborative Edge Computing: A Digital Twin Assisted Multi-Agent Reinforcement Learning Approach,
X. Chen, J. Cao, R. Cao, Y . Sahni, and M. Zhang, “Decentralized Task Offloading in Collaborative Edge Computing: A Digital Twin Assisted Multi-Agent Reinforcement Learning Approach,”IEEE Transactions on Mobile Computing, vol. 25, no. 4, pp. 4776–4790, 2025
2025
-
[53]
Mobility- Aware Dependent Task Offloading in Edge Computing: A Digital Twin- Assisted Reinforcement Learning Approach,
X. Chen, J. Cao, Y . Sahni, M. Zhang, and Z. Liang, “Mobility- Aware Dependent Task Offloading in Edge Computing: A Digital Twin- Assisted Reinforcement Learning Approach,”IEEE Transactions on Mobile Computing, vol. 24, no. 4, pp. 2979–2994, 2024
2024
-
[54]
The Cross-Entropy Method for Combinatorial and Continuous Optimization,
R. Y . Rubinstein, “The Cross-Entropy Method for Combinatorial and Continuous Optimization,”Methodology and Computing in Applied Probability, vol. 1, no. 2, pp. 127–190, 1999
1999
-
[55]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,” inProceedings of the International Conference on Machine Learning, 2018, pp. 1861–1870
2018
-
[56]
Continual Reinforce- ment Learning for Digital Twin Synchronization Optimization,
H. Tong, M. Chen, J. Zhao, Y . Hu, and Z. Yang, “Continual Reinforce- ment Learning for Digital Twin Synchronization Optimization,”IEEE Transactions on Mobile Computing, vol. 24, no. 8, pp. 6843–6857, 2025
2025
-
[57]
DNN Partitioning, Task Offloading, and Resource Allocation in Dynamic Vehicular Networks: A Lyapunov-Guided Diffusion-Based Reinforcement Learning Approach,
Z. Liu, H. Du, J. Lin, Z. Gao, and L. Huang, “DNN Partitioning, Task Offloading, and Resource Allocation in Dynamic Vehicular Networks: A Lyapunov-Guided Diffusion-Based Reinforcement Learning Approach,” IEEE Transactions on Mobile Computing, vol. 24, no. 3, pp. 1945–1962, 2024
1945
-
[58]
Radio Environment Knowledge Pool for 6G Digital Twin Channel,
J. Wang, J. Zhang, Y . Zhang, Y . Sun, G. Nie, L. Shi, P. Zhang, and G. Liu, “Radio Environment Knowledge Pool for 6G Digital Twin Channel,”IEEE Communications Magazine, vol. 63, no. 5, pp. 158– 164, 2025
2025
-
[59]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,” in Advances in Neural Information Processing Systems, 2023
2023
-
[60]
Energy Efficient Federated Learning Over Wireless Communication Networks,
Z. Yang, M. Chen, W. Saad, C. S. Hong, and M. Shikh-Bahaei, “Energy Efficient Federated Learning Over Wireless Communication Networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 3, pp. 1935–1949, 2021
1935
-
[61]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1861–1870. [Online]. Availa...
2018
-
[62]
Categorical Reparameterization with Gumbel-Softmax,
E. Jang, S. Gu, and B. Poole, “Categorical Reparameterization with Gumbel-Softmax,” in5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. [Online]. Available: https://openreview.net/forum?id=rkE3y85ee
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.