Recognition: unknown
Sample Selection Using Multi-Task Autoencoders in Federated Learning with Non-IID Data
Pith reviewed 2026-05-07 16:53 UTC · model grok-4.3
The pith
Loss-based sample selection via multi-task autoencoders improves federated learning accuracy by up to 7.02% on CIFAR10 with noisy non-IID data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that loss-based sample selection using a multi-task autoencoder with OCSVM achieves accuracy improvements of up to 7.02% on CIFAR10 and 1.83% on MNIST with adaptive threshold, while a new federated SVDD loss enhances feature-based selection with additional gains up to 0.99% on CIFAR10. These gains hold across varying client counts and non-IID distributions with noise levels up to 40%.
What carries the argument
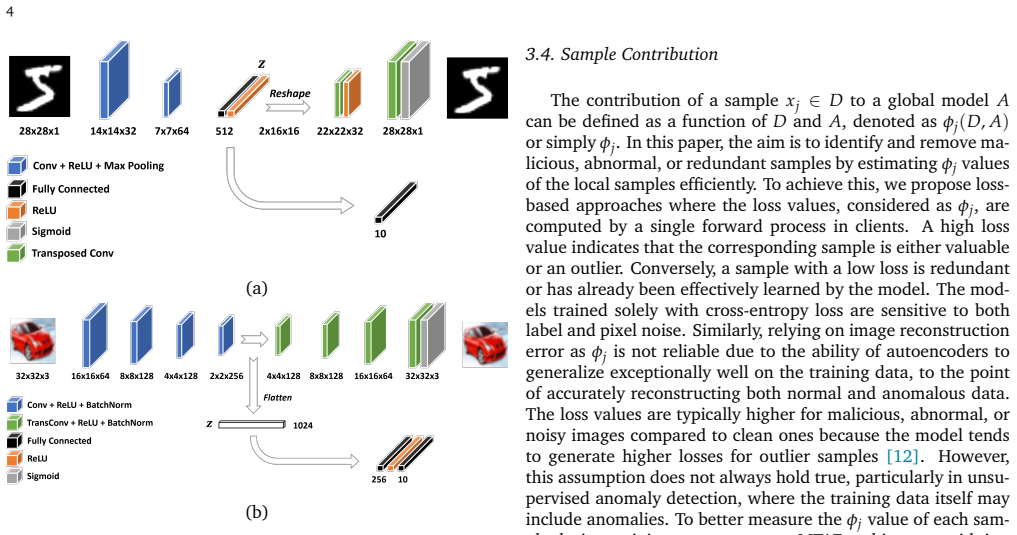
The multi-task autoencoder jointly trained for reconstruction and classification to produce loss values and feature representations that enable unsupervised outlier detection of noisy samples on clients.
If this is right
- Loss-based selection with OCSVM produces accuracy gains of up to 7.02% on CIFAR10.
- Adaptive loss threshold selection yields gains of up to 1.83% on MNIST.
- The federated SVDD loss further boosts feature-based selection by up to 0.99% on CIFAR10 with OCSVM.
- Accuracy benefits appear consistently across different client counts and noise levels up to 40%.
- Sample selection mitigates degradation from redundant, malicious, or abnormal samples in non-IID federated training.
Where Pith is reading between the lines
- The same signals could be used to reduce communication rounds by skipping training on low-value samples.
- Adapting the autoencoder tasks might allow the approach to extend to non-image data such as sensor readings.
- Malicious data poisoning could become detectable if poisoned samples consistently register as outliers.
- Pairing the method with existing privacy mechanisms would test whether selection accuracy survives added noise from privacy protections.
Load-bearing premise
The autoencoder's loss and feature outputs reliably indicate which samples are low quality, and the outlier detectors can separate noise from useful data without discarding informative examples under non-IID client distributions.
What would settle it
An experiment on a dataset where injected 'noise' actually consists of hard but informative examples would show whether accuracy falls rather than rises after selection.
Figures



read the original abstract
Federated learning is a machine learning paradigm in which multiple devices collaboratively train a model under the supervision of a central server while ensuring data privacy. However, its performance is often hindered by redundant, malicious, or abnormal samples, leading to model degradation and inefficiency. To overcome these issues, we propose novel sample selection methods for image classification, employing a multitask autoencoder to estimate sample contributions through loss and feature analysis. Our approach incorporates unsupervised outlier detection, using one-class support vector machine (OCSVM), isolation forest (IF), and adaptive loss threshold (AT) methods managed by a central server to filter noisy samples on clients. We also propose a multi-class deep support vector data description (SVDD) loss controlled by a central server to enhance feature-based sample selection. We validate our methods on CIFAR10 and MNIST datasets across varying numbers of clients, non-IID distributions, and noise levels up to 40%. The results show significant accuracy improvements with loss-based sample selection, achieving gains of up to 7.02% on CIFAR10 with OCSVM and 1.83% on MNIST with AT. Additionally, our federated SVDD loss further improves feature-based sample selection, yielding accuracy gains of up to 0.99% on CIFAR10 with OCSVM. These results show the effectiveness of our methods in improving model accuracy across various client counts and noise conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes sample selection techniques for federated learning under non-IID data using a multi-task autoencoder to assess sample quality via loss and latent features. Loss-based filtering employs central-server outlier detectors (OCSVM, isolation forest, adaptive threshold), while feature-based selection is enhanced by a federated multi-class SVDD loss. Experiments on MNIST and CIFAR-10 with varying client counts, non-IID partitions, and noise levels up to 40% report accuracy gains of up to 7.02% (CIFAR-10, OCSVM) and 1.83% (MNIST, AT), plus up to 0.99% from the SVDD component.
Significance. If the gains prove robust, the work addresses a practical barrier in federated image classification by mitigating redundant or noisy samples without data sharing. The multi-task autoencoder plus federated SVDD combination provides a concrete mechanism for quality estimation that could improve both accuracy and communication efficiency in noisy non-IID regimes.
major comments (2)
- [Experimental evaluation] Experimental evaluation: the abstract and results report concrete accuracy deltas (7.02% CIFAR-10 OCSVM, 1.83% MNIST AT) but supply no baseline comparisons, no description of how non-IID partitions were generated, and no statistical significance tests or variance across runs. These omissions are load-bearing because the central claim is that the proposed selection improves performance across non-IID and noise conditions.
- [Method and evaluation] Method and evaluation: the claim that autoencoder loss and features reliably separate noise from signal rests on the untested assumption that locally anomalous samples are always detrimental. No per-client class-balance statistics before versus after filtering are provided, leaving open whether the method removes the sole representatives of a class under extreme non-IID (single-class or highly skewed) clients, which would directly undermine the reported gains.
minor comments (2)
- [Abstract] The abstract states results hold 'across various client counts' yet does not list the specific client numbers or ranges tested.
- [Method] The federated SVDD loss is described at a high level; a compact equation or pseudocode would clarify how the central server aggregates and distributes the loss without violating privacy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, providing clarifications from the manuscript and indicating where revisions will strengthen the presentation of results.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation: the abstract and results report concrete accuracy deltas (7.02% CIFAR-10 OCSVM, 1.83% MNIST AT) but supply no baseline comparisons, no description of how non-IID partitions were generated, and no statistical significance tests or variance across runs. These omissions are load-bearing because the central claim is that the proposed selection improves performance across non-IID and noise conditions.
Authors: The manuscript does include baseline comparisons to standard FedAvg without sample selection (see Tables 2 and 3 and Section 5). Non-IID partitions are generated via Dirichlet distribution with α=0.1 as described in Section 4.1. We agree, however, that variance across runs and statistical tests are not reported. We will add standard deviations from five independent runs and paired t-test p-values for the reported gains in the revised version. revision: yes
-
Referee: [Method and evaluation] Method and evaluation: the claim that autoencoder loss and features reliably separate noise from signal rests on the untested assumption that locally anomalous samples are always detrimental. No per-client class-balance statistics before versus after filtering are provided, leaving open whether the method removes the sole representatives of a class under extreme non-IID (single-class or highly skewed) clients, which would directly undermine the reported gains.
Authors: Our experiments cover a range of non-IID regimes including high client counts and label skew, with consistent accuracy gains indicating that filtering does not remove critical samples in the tested settings. We acknowledge the value of explicit verification and will add per-client class distribution statistics (before/after filtering) for the most skewed partitions in a new subsection of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical proposal validated on benchmarks
full rationale
The paper proposes multi-task autoencoder-based sample selection methods (loss-based with OCSVM/IF/AT and feature-based with federated SVDD) for federated learning and reports accuracy gains from experiments on CIFAR-10 and MNIST under controlled non-IID and noise conditions. No mathematical derivations, first-principles predictions, or fitted parameters are presented that reduce by construction to the method's own inputs or definitions. The central claims rest on external benchmark results rather than self-referential equations or self-citation chains for uniqueness. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- adaptive loss threshold
- autoencoder training hyperparameters
axioms (2)
- domain assumption Autoencoder reconstruction loss and latent features correlate with sample usefulness for the downstream classification task.
- domain assumption Outlier detectors applied to these scores will remove noise while preserving signal in non-IID partitions.
Reference graph
Works this paper leans on
-
[1]
McMahan, E
H.B. McMahan, E. Moore, D. Ramage, S. Hampson, B.A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, vol. 54 of Proceedings of Machine Learning Research, PMLR, 2017, pp. 1273–1282. URL: https://proceedings.mlr.press/v54/mcma h...
2017
-
[2]
T. Li, A.K. Sahu, A. Talwalkar, V. Smith, Federated learning: Challenges, methods, and future directions, IEEE Signal Processing Magazine 37 (3) (2020) 50–60. URL: https://doi. org/10.1109/MSP.2020.2975749
-
[3]
F. Sattler, S. Wiedemann, K.R. Müller, W. Samek, Robust and communication-efficient federated learning from non-i.i.d. data, IEEE Transactions on Neural Networks and Learning Systems 31 (9) (2020) 3400–3413. URL: https://doi.org/10.1109/TNNL S.2019.2944481
-
[4]
A. Li, L. Zhang, J. Tan, Y. Qin, J. Wang, X.Y. Li, Sample-level data selection for federated learning, in: IEEE INFOCOM 2021 - IEEE Conference on Computer Communications, 2021, pp. 1–10. URL: https://doi.org/10.1109/INFOCOM42981.2021.9488723
-
[5]
D. Novoa-Paradela, O. Fontenla-Romero, B. Guijarro-Berdiñas, D. Orellana-Cañás, A federated learning architecture for anomaly detection on the edge using deep autoencoders, in: 2023 IEEE International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), 2023, pp. 1–6. URL: https://doi.org/10.1109/WETICE57085.2023.10477 824
-
[6]
S. Li, Y. Cheng, W. Wang, Y. Liu, T. Chen, Learning to detect malicious clients for robust federated learning (2020). arXiv:2002.00211. URL: https://doi.org/10.48550/arXiv.200 2.00211
- [7]
-
[8]
J. Zhao, X. Zhu, J. Wang, J. Xiao, Efficient client contribution evaluation for horizontal federated learning, in: ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 3060–3064. URL: https: //doi.org/10.1109/ICASSP39728.2021.9413377
-
[9]
E. Ardıç, Y. Genç, Data valuation methods for federated learning, in: 2023 31st Signal Processing and Communications Applications Conference (SIU), 2023, pp. 1–4. URL: https://doi. org/10.1109/SIU59756.2023.10223784
-
[10]
K. Kea, Y. Han, T.K. Kim, Enhancing anomaly detection in distributed power systems using autoencoder-based federated learning, Plos one 18 (8) (2023) e0290337. URL: https://do i.org/10.1371/journal.pone.0290337
-
[11]
M. Nardi, L. Valerio, A. Passarella, Anomaly detection through unsupervised federated learning, in: 2022 18th International Conference on Mobility , Sensing and Networking (MSN), 2022, pp. 495–501. URL: https://doi.org/10.1109/MSN57253.2022. 00085
-
[12]
Z. Cheng, S. Wang, P. Zhang, S. Wang, X. Liu, E. Zhu, Improved autoencoder for unsupervised anomaly detection, International Journal of Intelligent Systems 36 (12) (2021) 7103–7125. URL: https://doi.org/10.1002/int.22582
-
[13]
T. Wang, J. Rausch, C. Zhang, R. Jia, D. Song, A Principled Approach to Data Valuation for Federated Learning, Springer International Publishing, Cham, 2020, pp. 153–167. URL: https: //doi.org/10.1007/978-3-030-63076-8_11
-
[14]
J. Shin, Y. Li, Y. Liu, S.J. Lee, Fedbalancer: data and pace control for efficient federated learning on heterogeneous clients, in: Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services, MobiSys ’22, Association for Computing Machinery , New York, NY, USA, 2022, p. 436–449. URL: https://doi.org/10.1145/349836...
-
[15]
C.C. Chang, C.J. Lin, Libsvm: A library for support vector machines, ACM Transactions on Intelligent Systems and Technology 2 (3). URL: https://doi.org/10.1145/1961189. 1961199
-
[16]
Liu, K.M
F.T. Liu, K.M. Ting, Z.H. Zhou, Isolation forest, in: 2008 Eighth IEEE International Conference on Data Mining, 2008, pp. 413–
2008
-
[17]
URL: https://doi.org/10.1109/ICDM.2008.17
-
[18]
G. Wang, C.X. Dang, Z. Zhou, Measure contribution of participants in federated learning, in: 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2597–2604. URL: https://doi.org/10.1109/BigData47090.2019.9006179
-
[19]
Katharopoulos, F
A. Katharopoulos, F. Fleuret, Not all samples are created equal: Deep learning with importance sampling, in: Proceedings of the 35th International Conference on Machine Learning, vol. 80 of Proceedings of Machine Learning Research, PMLR, 2018, pp. 2525–2534. URL: https://proceedings.mlr.press/v80/kathar opoulos18a.html
2018
-
[20]
S.K. Shyn, D. Kim, K. Kim, Fedccea : A practical approach of client contribution evaluation for federated learning (2021). arXiv:2106.02310. URL: https://doi.org/10.48550/arXiv.2106. 02310
-
[21]
T. Tuor, S. Wang, B.J. Ko, C. Liu, K.K. Leung, Overcoming noisy and irrelevant data in federated learning, in: 2020 25th International Conference on Pattern Recognition (ICPR), 2021, pp. 5020–5027. URL: https://doi.org/10.1109/ICPR48806.20 21.9412599
- [22]
-
[23]
D.H. Tran, V.L. Nguyen, I.B.K.Y. Utama, Y.M. Jang, An improved sensor anomaly detection method in iot system using federated learning, in: 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), 2022, pp. 466–469. URL: https://doi.org/10.1109/ICUFN55119.2022.9829561
- [24]
-
[25]
S. Li, Y. Cheng, Y. Liu, W. Wang, T. Chen, Abnormal client behavior detection in federated learning (2019). arXiv:1910.09933. URL: https://doi.org/10.48550/arXiv.191 0.09933
-
[26]
P. Bhat, M.P. M M, R.M. Pai, Anomaly detection using federated learning: A performance based parameter aggregation approach, in: 2023 3rd International Conference on Intelligent Technologies (CONIT), 2023, pp. 1–6. URL: https://doi.org/10 .1109/CONIT59222.2023.10205549
-
[27]
L. Deng, The mnist database of handwritten digit images for machine learning research, IEEE Signal Processing Magazine 13 29 (6) (2012) 141–142. URL: https://doi.org/10.1109/MSP. 2012.2211477
work page doi:10.1109/msp 2012
-
[28]
Krizhevsky , G
A. Krizhevsky , G. Hinton, Learning multiple layers of features from tiny images, Tech. rep., University of Toronto (2009). URL: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR. pdf
2009
-
[29]
Netzer, T
Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A.Y. Ng, et al., Reading digits in natural images with unsupervised feature learning, in: NIPS Workshop on Deep Learning and Unsupervised Feature Learning, vol. 2011, Granada, 2011, p. 4
2011
-
[30]
P. Chrabaszcz, I. Loshchilov, F. Hutter, A downsampled variant of imagenet as an alternative to the cifar datasets (2017). arXiv:1707.08819. URL: https://doi.org/10.48550/arXiv.170 7.08819
-
[31]
G. Cohen, S. Afshar, J. Tapson, A. van Schaik, Emnist: Extending mnist to handwritten letters, in: 2017 International Joint Conference on Neural Networks (IJCNN), 2017, pp. 2921–2926. URL: https://doi.org/10.1109/IJCNN.2017.7966217
-
[32]
S. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Kone ˇcný, S. Kumar, H.B. McMahan, Adaptive federated optimization (2021). arXiv:2003.00295. URL: https://doi.org/10.48550/arX iv.2003.00295
-
[33]
C. He, S. Li, J. So, X. Zeng, M. Zhang, H. Wang, X. Wang, P. Vepakomma, A. Singh, H. Qiu, X. Zhu, J. Wang, L. Shen, P. Zhao, Y. Kang, Y. Liu, R. Raskar, Q. Yang, M. Annavaram, S. Avestimehr, Fedml: A research library and benchmark for federated machine learning (2020). arXiv:2007.13518. URL: https://doi.org/10.48550/arXiv.2007.13518
-
[34]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, Édouard Duchesnay , Scikit-learn: Machine learning in python, Journal of Machine Learning Research 12 (85) (2011) 2825–
2011
-
[35]
URL: http://jmlr.org/papers/v12/pedregosa11a.html
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.