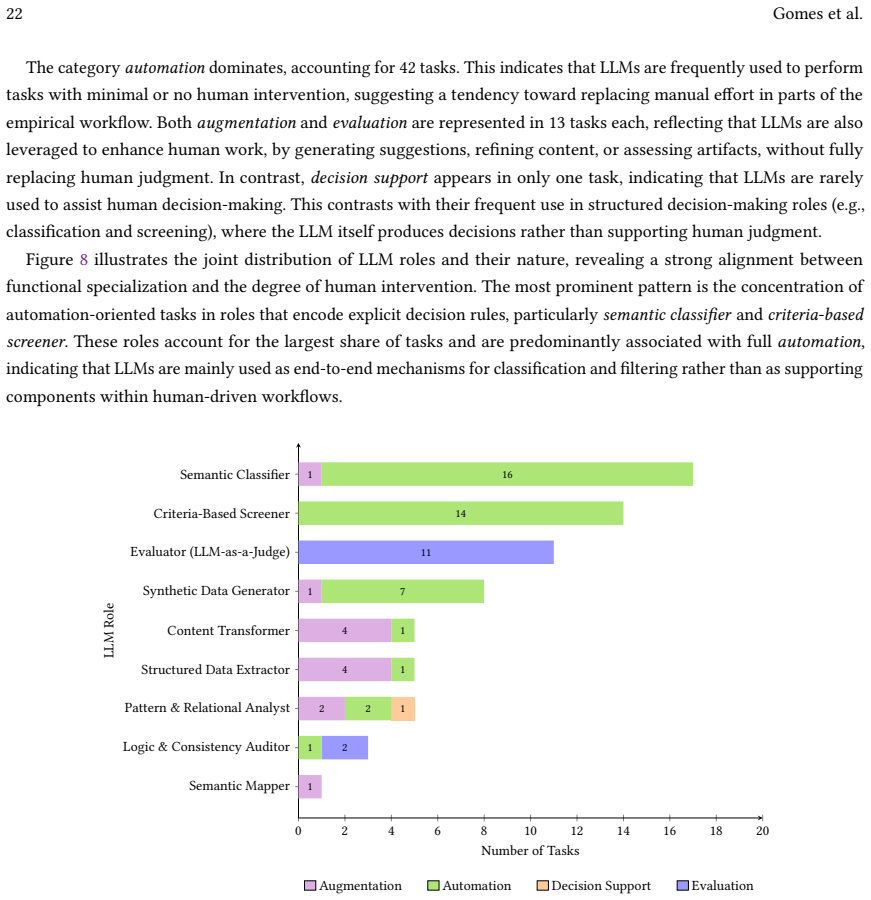
Recognition: unknown
LLM-Assisted Empirical Software Engineering: Systematic Literature Review and Research Agenda
Pith reviewed 2026-05-07 13:32 UTC · model grok-4.3
The pith
A review of 50 studies shows LLMs in empirical software engineering mainly automate data classification and filtering rather than aiding human decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through qualitative and quantitative synthesis of peer-reviewed papers from 2020 to 2025 across 12 leading software engineering venues, the review establishes that LLMs assist 69 tasks but remain concentrated in data processing and analysis phases of the empirical lifecycle. Integration patterns are largely automation-oriented, delivering efficiency and scalability benefits while exposing limitations around hallucinations, inconsistency, prompt sensitivity, and incomplete reporting of methods and parameters. The work documents limited application to decision-support activities and calls for greater transparency to address reproducibility concerns in empirical software engineering.
What carries the argument
The systematic literature review and qualitative synthesis of 50 primary studies that catalogs 69 LLM-assisted tasks and their distribution across empirical workflow phases.
If this is right
- Researchers should adopt standardized reporting of LLM prompts, parameters, and validation steps to improve reproducibility of empirical results.
- Workflow designs need to expand beyond automation in data processing toward hybrid human-LLM approaches in experiment planning and result interpretation.
- Empirical studies must develop domain-specific validation techniques to reduce hallucinations and inconsistency when processing software artifacts.
- Future work should prioritize tools and guidelines that support the complete empirical lifecycle instead of isolated phases like classification and filtering.
- The identified gaps point to the need for empirical benchmarks that compare LLM-assisted versus traditional methods on metrics such as time, accuracy, and transparency.
Where Pith is reading between the lines
- The observed automation-first pattern may appear in empirical work across other disciplines that handle large textual or code datasets, offering opportunities for shared best practices on validation.
- Controlled experiments that measure actual time savings and error rates when replacing manual steps with LLMs could directly test the efficiency claims while quantifying new risks.
- Including preprints and industry reports in follow-up reviews might surface faster-evolving uses of LLMs that the peer-reviewed sample misses.
- If prompt sensitivity remains a dominant limitation, targeted fine-tuning on software engineering corpora could provide a practical mitigation not yet explored in the reviewed studies.
Load-bearing premise
The 50 studies drawn from the 12 selected venues between 2020 and 2025, together with the qualitative coding, accurately reflect the full range of LLM practices in empirical software engineering.
What would settle it
A broad set of additional peer-reviewed studies published outside the 12 venues or after 2025 that show widespread LLM use for decision-support roles or full-lifecycle integration, rather than isolated automation of data tasks, would contradict the reported concentration.
Figures







read the original abstract
Context: Empirical Software Engineering (ESE) faces increasing challenges due to data scale, methodological complexity, and reproducibility concerns. Large Language Models (LLMs) have emerged as promising tools to support empirical workflows, yet their use remains fragmented, with no comprehensive synthesis to guide responsible adoption. Aims: This study analyzes how LLMs are used in ESE, examining supported tasks, phases of the empirical lifecycle, integration into workflows, reported benefits and limitations, and the extent of reproducibility-related reporting. It also identifies gaps and future research directions. Method: We conducted a systematic literature review of peer-reviewed papers (2020-2025) across 12 leading software engineering venues, resulting in 50 primary studies analyzed through qualitative and quantitative synthesis. Results: We identified 69 LLM-assisted tasks, mainly in mining software repositories and controlled experiments, focusing on classification, filtering, and evaluation. LLMs are used across multiple phases but are concentrated in data processing and analysis. Their integration is largely automation-oriented, with limited decision-support use. Benefits emphasize efficiency and scalability, while limitations include hallucinations, inconsistency, prompt sensitivity, and reproducibility issues. Reporting practices are often incomplete. Conclusion: LLM use in ESE is growing but remains automation-driven, with gaps in human-centered integration and transparency. We outline implications and research agenda for responsible use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic literature review (SLR) of peer-reviewed studies from 2020-2025 across 12 leading software engineering venues, selecting 50 primary studies on LLM use in Empirical Software Engineering (ESE). Through qualitative and quantitative synthesis, it identifies 69 LLM-assisted tasks (concentrated in mining software repositories and controlled experiments, focusing on classification, filtering, and evaluation), maps their use across empirical lifecycle phases (with concentration in data processing and analysis), characterizes integration as largely automation-oriented with limited decision-support, reports benefits (efficiency, scalability) and limitations (hallucinations, inconsistency, prompt sensitivity, reproducibility issues), notes incomplete reporting practices, and outlines a research agenda for responsible adoption.
Significance. If the SLR execution proves reproducible and exhaustive within the stated venues, the work would offer a timely consolidation of fragmented knowledge on LLM applications in ESE, providing concrete task enumerations, phase distributions, and gap identification that could guide tool development, empirical study design, and responsible integration practices. The emphasis on reproducibility concerns and the proposed agenda add practical value for the community.
major comments (1)
- [Method] Method section: The description states that an SLR was conducted across 12 venues yielding 50 primary studies but provides neither the exact Boolean search string, the full inclusion/exclusion criteria with decision rationale, the data-extraction form, nor any inter-rater reliability statistic (e.g., Cohen’s kappa or percentage agreement). These omissions make it impossible to verify the completeness of the 50-study corpus or the reproducibility of the coding that produces the headline 69-task count and the reported distributions across phases and integration styles; this directly undermines the load-bearing synthesis claims in the Results section.
minor comments (2)
- [Results] Results section: The quantitative synthesis is mentioned in the abstract and Method but receives limited explicit treatment in the reported findings; clarify what quantitative metrics (beyond task counts) were computed and how they support the phase-concentration claims.
- [Discussion] The paper would benefit from an explicit limitations subsection in the Discussion that addresses threats to validity of the SLR itself (e.g., venue selection bias, publication lag).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our systematic literature review. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Method] Method section: The description states that an SLR was conducted across 12 venues yielding 50 primary studies but provides neither the exact Boolean search string, the full inclusion/exclusion criteria with decision rationale, the data-extraction form, nor any inter-rater reliability statistic (e.g., Cohen’s kappa or percentage agreement). These omissions make it impossible to verify the completeness of the 50-study corpus or the reproducibility of the coding that produces the headline 69-task count and the reported distributions across phases and integration styles; this directly undermines the load-bearing synthesis claims in the Results section.
Authors: We agree that the Method section as currently written does not contain the exact Boolean search string, the full inclusion/exclusion criteria with decision rationales, the data-extraction form, or inter-rater reliability statistics. These details are necessary for independent verification of the 50-study corpus and the qualitative coding that produced the 69-task enumeration and phase distributions. In the revised manuscript we will expand the Method section to include: (1) the precise Boolean search string applied to each venue, (2) the complete inclusion and exclusion criteria together with the rationale for each criterion, (3) a description or template of the data-extraction form, and (4) the inter-rater agreement figures (percentage agreement and/or Cohen’s kappa) obtained during screening and coding. These additions will directly support reproducibility of the synthesis claims. revision: yes
Circularity Check
No circularity: SLR synthesizes external primary studies without self-referential reduction
full rationale
The paper conducts a systematic literature review by querying 12 venues for 2020-2025 papers, selecting 50 primary studies, and performing qualitative/quantitative synthesis to enumerate 69 tasks and report phase distributions. All headline claims (task counts, concentration in mining repositories and controlled experiments, automation-oriented integration) are direct aggregates or codings from the external studies rather than any fitted parameter, self-defined quantity, or self-citation chain. No equations, ansatzes, uniqueness theorems, or renamings of known results appear; the derivation chain is therefore self-contained against the cited literature and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 12 selected software engineering venues and 2020-2025 window contain the relevant peer-reviewed literature on LLM use in ESE
- domain assumption Qualitative synthesis of reported benefits, limitations, and reproducibility practices accurately reflects the underlying studies without significant coder bias
Reference graph
Works this paper leans on
-
[1]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Associat...
-
[2]
Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chunyang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, Davide Fucci, Junda He, Christoph Treude, Marcos Kalinowski, Stefano Lambiase, Daniel Russo, Mircea Lungu, Cristina Martinez Montes, Lutz Prechelt, Paul Ralph, Rijnard van Tonder, and Stefan Wagne...
work page internal anchor Pith review arXiv 2026
-
[3]
Muneera Bano, Rashina Hoda, Didar Zowghi, and Christoph Treude. 2023. Large language models for qualitative research in software engineering: exploring opportunities and challenges.Automated Software Engg.31, 1 (Dec. 2023), 12 pages. doi:10.1007/s10515-023-00407-8
-
[4]
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency(Virtual Event, Canada)(FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. doi:10.114...
-
[5]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stef...
work page internal anchor Pith review arXiv 2022
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
-
[8]
Zadia Codabux, Fatemeh Fard, Roberto Verdecchia, Fabio Palomba, Dario Di Nucci, and Gilberto Recupito. 2024. Teaching mining software repositories. InHandbook on Teaching Empirical Software Engineering. Springer, 325–362. doi:10.1007/978-3-031-71769-7_12
-
[9]
Proebsting
Christian Collberg and Todd A. Proebsting. 2016. Repeatability in computer systems research.Commun. ACM59, 3 (Feb. 2016), 62–69. doi:10.1145/ 2812803
2016
-
[10]
Daniela S. Cruzes and Tore Dyba. 2011. Recommended Steps for Thematic Synthesis in Software Engineering. In2011 International Symposium on Empirical Software Engineering and Measurement. 275–284. doi:10.1109/ESEM.2011.36
-
[11]
Vincenzo De Martino, Joel Castaño, Fabio Palomba, Xavier Franch, and Silverio Martínez-Fernández. 2025. A Framework for Using LLMs for Repository Mining Studies in Empirical Software Engineering. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE). 6–11. doi:10.1109/WSESE66602.2025.00008
-
[12]
Steve Easterbrook, Janice Singer, Margaret-Anne Storey, and Daniela Damian. 2008.Selecting Empirical Methods for Software Engineering Research. Springer London, London, 285–311. doi:10.1007/978-1-84800-044-5_11
-
[13]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks.Proceedings of the National Academy of Sciences120, 30 (2023). doi:10.1073/pnas.2305016120
-
[14]
Victória Gomes, Delaney Selb, Fabio Palomba, Rodrigo Spinola, and David Lo. 2026. Replication Package - LLM-Assisted Empirical Software Engineering: A Systematic Literature Review. https://github.com/secentervcu/LLM-Assisted-ESE-SLR
2026
-
[15]
Ahmed E. Hassan. 2008. The road ahead for Mining Software Repositories. In2008 Frontiers of Software Maintenance. 48–57. doi:10.1109/FOSM.2008. 4659248
-
[16]
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. 2026. LLM-as-a-Judge for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Trans. Softw. Eng. Methodol.(Feb. 2026). doi:10.1145/3797276 Just Accepted
-
[17]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans. Softw. Eng. Methodol.33, 8, Article 220 (Dec. 2024), 79 pages. doi:10.1145/3695988 LLM-Assisted Empirical Software Engineering: Systematic Literat...
-
[18]
Samireh Jalali and Claes Wohlin. 2012. Systematic literature studies: Database searches vs. backward snowballing. InProceedings of the 2012 ACM-IEEE International Symposium on Empirical Software Engineering and Measurement. 29–38. doi:10.1145/2372251.2372257
-
[19]
Jai Kannan, Scott Barnett, Anj Simmons, Taylan Selvi, and Luis Cruz. 2024. Green Runner: A Tool for Efficient Deep Learning Component Selection. InProceedings of the IEEE/ACM 3rd International Conference on AI Engineering - Software Engineering for AI(Lisbon, Portugal)(CAIN ’24). Association for Computing Machinery, New York, NY, USA, 112–117. doi:10.1145...
-
[20]
2007.Guidelines for Performing Systematic Literature Reviews in Software Engineering
Barbara Kitchenham and Stuart Charters. 2007.Guidelines for Performing Systematic Literature Reviews in Software Engineering. EBSE Technical Report EBSE-2007-01. Keele University and Durham University. https://www.elsevier.com/__data/promis_misc/525444systematicreviewsguide.pdf
2007
-
[21]
B.A. Kitchenham, S.L. Pfleeger, L.M. Pickard, P.W. Jones, D.C. Hoaglin, K. El Emam, and J. Rosenberg. 2002. Preliminary guidelines for empirical research in software engineering.IEEE Transactions on Software Engineering28, 8 (2002), 721–734. doi:10.1109/TSE.2002.1027796
-
[22]
Kitchenham, Tore Dyba, and Magne Jorgensen
Barbara A. Kitchenham, Tore Dyba, and Magne Jorgensen. 2004. Evidence-Based Software Engineering. InProceedings of the 26th International Conference on Software Engineering (ICSE ’04). IEEE Computer Society, USA, 273–281. doi:10.1109/ICSE.2004.1317449
-
[23]
2015.Guidelines for Conducting Surveys in Software Engineering
Johan Linåker, Sardar Muhammad Sulaman, Rafael Maiani de Mello, and Martin Höst. 2015.Guidelines for Conducting Surveys in Software Engineering. Department of Computer Science, Lund University
2015
-
[24]
Satoshi Masuda, Kohichi Ono, Toshiaki Yasue, and Nobuhiro Hosokawa. 2018. A Survey of Software Quality for Machine Learning Applications. In 2018 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). 279–284. doi:10.1109/ICSTW.2018.00061
-
[25]
Erica Mourão, João Felipe Pimentel, Leonardo Murta, Marcos Kalinowski, Emilia Mendes, and Claes Wohlin. 2020. On the performance of hybrid search strategies for systematic literature reviews in software engineering.Information and Software Technology123 (2020), 106294. doi:10.1016/j.infsof.2020.106294
-
[26]
R. Parasuraman, T.B. Sheridan, and C.D. Wickens. 2000. A model for types and levels of human interaction with automation.IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans30, 3 (2000), 286–297. doi:10.1109/3468.844354
-
[27]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2025. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions.Commun. ACM68, 2 (Jan. 2025), 96–105. doi:10.1145/3610721
-
[28]
Kai Petersen, Robert Feldt, Shahid Mujtaba, and Michael Mattsson. 2008. Systematic mapping studies in software engineering. InProceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering(Italy)(EASE’08). BCS Learning & Development Ltd., Swindon, GBR, 68–77
2008
-
[29]
Lars Reimann and Günter Kniesel-Wünsche. 2024. Adaptoring: Adapter Generation to Provide an Alternative API for a Library. In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 192–203. doi:10.1109/SANER60148.2024.00027
-
[30]
Per Runeson and Martin Höst. 2009. Guidelines for conducting and reporting case study research in software engineering.Empirical Softw. Engg.14, 2 (April 2009), 131–164. doi:10.1007/s10664-008-9102-8
-
[31]
2025.The Coding Manual for Qualitative Researchers
Johnny Saldana. 2025.The Coding Manual for Qualitative Researchers(5 ed.). SAGE Publications Ltd. doi:10.4135/9781036235611
-
[32]
Ekaterina Shemetova, Ivan Smirnov, Anton Alekseev, Ilya Shenbin, Alexey Rukhovich, Sergey Nikolenko, Vadim Lomshakov, and Irina Piontkovskaya
-
[33]
LAMeD: LLM-generated Annotations for Memory Leak Detection. InProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering (EASE ’25). Association for Computing Machinery, New York, NY, USA, 1024–1034. doi:10.1145/3756681.3756999
-
[34]
Ben Shneiderman. 2020. Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy.International Journal of Human–Computer Interaction 36, 6 (2020), 495–504. doi:10.1080/10447318.2020.1741118
-
[35]
Forrest Shull, Janice Singer, and Dag I. K. Sjøberg. 2008. Guide to Advanced Empirical Software Engineering. InGuide to Advanced Empirical Software Engineering. Springer. doi:10.1007/978-1-84800-044-5
-
[36]
Lukas Thode, Umar Iftikhar, and Daniel Mendez. 2025. Exploring the use of LLMs for the selection phase in systematic literature studies.Information and Software Technology184 (2025), 107757. doi:10.1016/j.infsof.2025.107757
-
[37]
Stefan Wagner, Marvin Muñoz Barón, Davide Falessi, and Sebastian Baltes. 2025. Towards Evaluation Guidelines for Empirical Studies Involving LLMs. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE)(Ottawa, ON, Canada). IEEE Press, 24–27. doi:10.1109/WSESE66602.2025.00011
-
[38]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems (New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY...
2022
-
[39]
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, Zac Kenton, Sasha Brown, Will Hawkins, Tom Stepleton, Courtney Biles, Abeba Birhane, Julia Haas, Laura Rimell, Lisa Anne Hendricks, William Isaac, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2021. Ethic...
work page internal anchor Pith review arXiv 2021
-
[40]
Claes Wohlin. 2014. Guidelines for snowballing in systematic literature studies and a replication in software engineering. InProceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering(London, England, United Kingdom)(EASE ’14). Association for Computing Machinery, New York, NY, USA, Article 38, 10 pages. doi:10.1...
-
[41]
Claes Wohlin, Marcos Kalinowski, Katia Romero Felizardo, and Emilia Mendes. 2022. Successful combination of database search and snowballing for identification of primary studies in systematic literature studies.Information and Software Technology147 (2022), 106908. doi:10.1016/j.infsof. 2022.106908 42 Gomes et al
-
[42]
2012.Experimentation in software engineering
Claes Wohlin, Per Runeson, Martin Hst, Magnus C. Ohlsson, Bjrn Regnell, and Anders Wessln. 2024.Experimentation in Software Engineering. Springer Publishing Company, Incorporated. doi:10.1007/978-3-662-69306-3
- [43]
-
[44]
URL https://doi.org/10.1038/s44387-025-00019-5
Yanbo Zhang, Sumeer A. Khan, Adnan Mahmud, Huck Yang, Alexander Lavin, Michael Levin, Jeremy Frey, Jared Dunnmon, James Evans, Alan Bundy, Saso Dzeroski, Jesper Tegner, and Hector Zenil. 2025. Exploring the role of large language models in the scientific method: from hypothesis to discovery.npj Artificial Intelligence1, 1 (2025), 14. doi:10.1038/s44387-02...
-
[45]
Thomas Zimmermann, Nachiappan Nagappan, Christian Bird, and Abram Hindle. 2012. Relating requirements to implementation via topic analysis: Do topics extracted from requirements make sense to managers and developers?. InProceedings of the 2012 IEEE International Conference on Software Maintenance (ICSM) (ICSM ’12). IEEE Computer Society, USA, 243–252. doi...
-
[46]
T. Zimmermann, P. Weibgerber, S. Diehl, and A. Zeller. 2004. Mining version histories to guide software changes. InProceedings. 26th International Conference on Software Engineering. 563–572. doi:10.1109/ICSE.2004.1317478
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.